ScoreStop: Gradient-based early stopping using functional score tests
Pith reviewed 2026-06-28 12:14 UTC · model grok-4.3
The pith
A functional score test on validation gradients decides when to stop gradient boosting by testing if the current model is the population risk minimizer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ScoreStop formulates early stopping as a functional score test of the hypothesis that the current predictor is the population risk minimizer. The test statistic is computed from validation data gradients, is scale-invariant with respect to the update direction, and possesses a known asymptotic distribution under the null hypothesis. The construction extends to implicit losses like LambdaRank and losses defined via influence functions like Cox regression.
What carries the argument
Functional score test statistic computed on validation gradients, which tests optimality and is invariant to update scale.
If this is right
- Stopping rules no longer require choosing a patience period whose scale has no direct statistical interpretation.
- The same stopping rule applies without modification to boosting with implicit or user-specified loss functions.
- Overfitting prevention is cast as a formal hypothesis test on gradients rather than a heuristic threshold on loss values.
- Validation data informs stopping through gradient information instead of direct loss evaluation.
Where Pith is reading between the lines
- The method could be adapted to iterative optimizers other than gradient boosting on trees.
- If the asymptotic approximation holds in moderate sample sizes, the rule may reduce sensitivity to validation noise compared with loss-based stopping.
- Because the construction already incorporates influence functions for certain losses, it may combine naturally with robustness or sensitivity checks in applied modeling.
Load-bearing premise
The functional score test statistic has the claimed known asymptotic distribution under the null hypothesis that the current predictor is the population risk minimizer for the iterative updates and loss functions in gradient boosting.
What would settle it
Running ScoreStop on synthetic data generated so that the boosting procedure has already reached the true population minimizer, then checking at each step whether the observed test statistic distribution matches the claimed asymptotic distribution under the null.
Figures

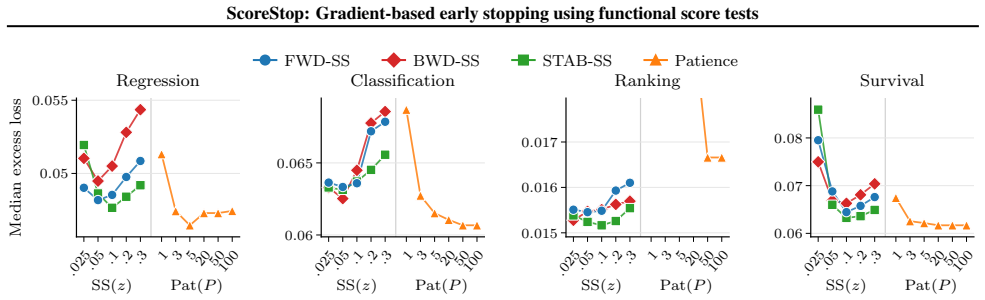
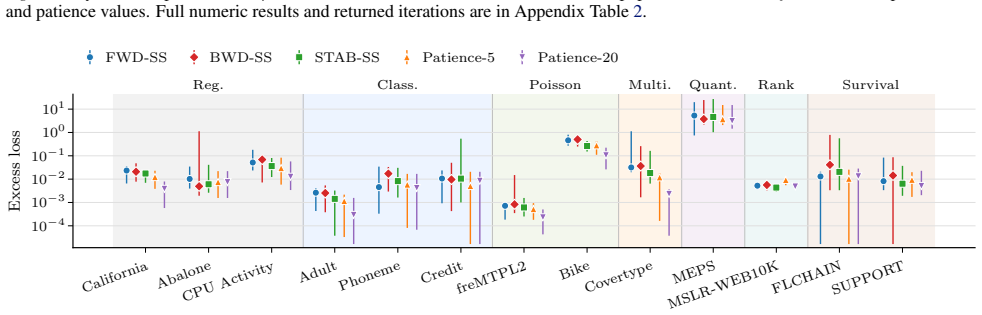
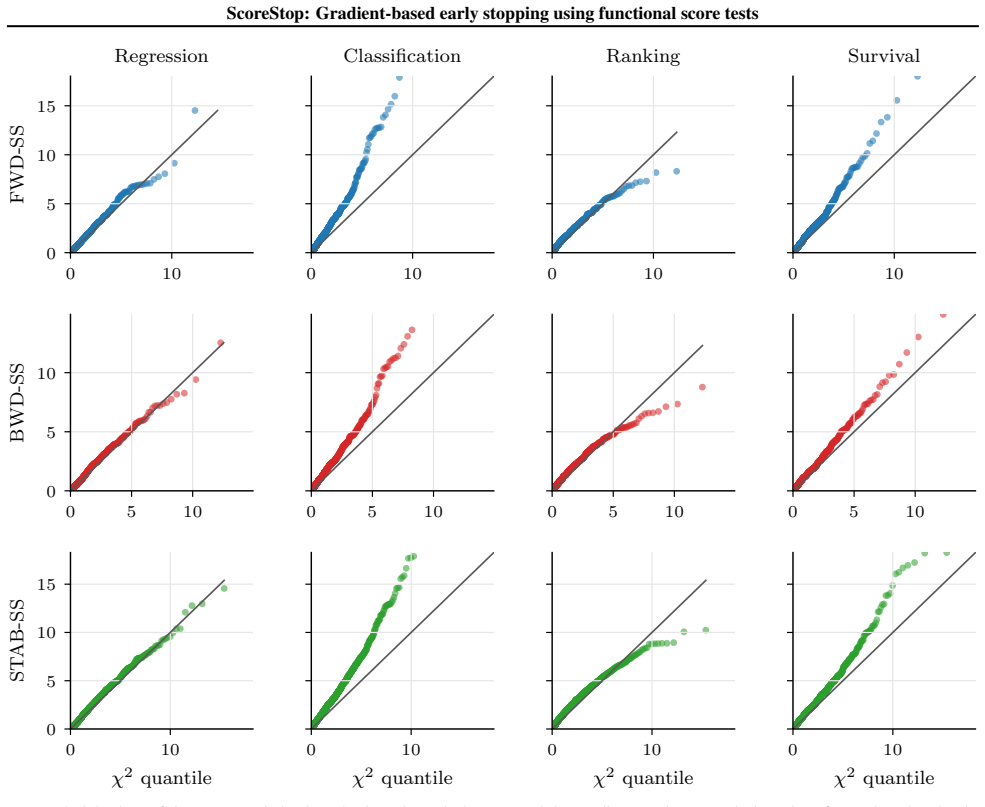
read the original abstract
Gradient boosted decision trees require a stopping rule to avoid overfitting. The standard rule monitors a validation loss and stops if the loss fails to improve for a fixed patience period. However, the patience parameter has no interpretable scale and validation losses can be noisy or implicitly defined by a user-specified gradient. We propose ScoreStop, a gradient-based early-stopping rule that casts the stopping decision at each iteration as a test of the null hypothesis that the current predictor is the population risk minimizer. We use a functional score test, computed on validation data, with a statistic that is scale-invariant in the update direction, with a known asymptotic distribution under the null. Because our test uses gradients rather than loss values, the same construction applies to implicit losses such as LambdaRank, and data-dependent losses such as Cox regression via influence functions. In synthetic experiments and real-data benchmarks, we show that ScoreStop is competitive with loss-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ScoreStop, a gradient-based early-stopping rule for gradient boosted decision trees. It casts each stopping decision as a functional score test (computed on validation gradients) of the null that the current predictor is the population risk minimizer. The test statistic is scale-invariant in the update direction and asserted to have a known asymptotic distribution under the null. The construction extends to implicit losses (e.g., LambdaRank) and data-dependent losses (e.g., Cox via influence functions). Synthetic and real-data experiments indicate competitiveness with standard validation-loss monitoring.
Significance. If the claimed asymptotic distribution is valid under iterative boosting updates, the work supplies a statistically interpretable, patience-free stopping rule that applies where explicit validation losses are unavailable or noisy. This would be a useful addition to the gradient-boosting toolkit, particularly for ranking and survival-analysis losses.
major comments (2)
- [§3] §3 (Method/Theory): The central claim rests on the functional score test statistic (computed from validation gradients) possessing a known asymptotic distribution under the null that the current predictor equals the population risk minimizer. Standard score-test asymptotics assume a fixed model or i.i.d. sampling; the manuscript must supply a derivation or regularity conditions showing that the distribution is unaffected by the sequential, data-dependent updates inherent to boosting iterations. This is load-bearing for the stopping rule.
- [§5] §5 (Experiments): The synthetic and real-data benchmarks report competitiveness with loss-based methods, yet no error bars, standard errors across runs, or statistical tests for performance differences are described. Without these, it is impossible to determine whether observed differences are reliable or merely within noise.
minor comments (1)
- The abstract states the statistic is 'scale-invariant in the update direction' but does not preview the precise normalization; a brief equation or sentence in the introduction would aid readers unfamiliar with functional score tests.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the theoretical foundations and experimental presentation of ScoreStop. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method/Theory): The central claim rests on the functional score test statistic (computed from validation gradients) possessing a known asymptotic distribution under the null that the current predictor equals the population risk minimizer. Standard score-test asymptotics assume a fixed model or i.i.d. sampling; the manuscript must supply a derivation or regularity conditions showing that the distribution is unaffected by the sequential, data-dependent updates inherent to boosting iterations. This is load-bearing for the stopping rule.
Authors: We agree that additional justification is needed to establish the asymptotic distribution in the context of sequential boosting updates. The manuscript applies the functional score test at each iteration treating the current predictor as fixed, but to rigorously handle the data-dependent nature of prior iterations, we will include a detailed derivation in the revised version. This will specify regularity conditions, such as bounded learning rates and appropriate mixing conditions on the validation data, under which the standard score test asymptotics continue to hold. revision: yes
-
Referee: [§5] §5 (Experiments): The synthetic and real-data benchmarks report competitiveness with loss-based methods, yet no error bars, standard errors across runs, or statistical tests for performance differences are described. Without these, it is impossible to determine whether observed differences are reliable or merely within noise.
Authors: We acknowledge this limitation in the experimental section. In the revised manuscript, we will report results averaged over multiple independent runs with standard error bars. Additionally, we will include statistical significance tests comparing ScoreStop to the baseline methods to better substantiate the competitiveness claims. revision: yes
Circularity Check
No circularity: ScoreStop applies standard functional score test theory to gradients without self-referential reduction
full rationale
The paper defines ScoreStop by casting early stopping as a hypothesis test of whether the current predictor equals the population risk minimizer, using a functional score test on validation gradients whose statistic is scale-invariant and has a claimed known asymptotic null distribution. No equation in the abstract or description shows the test statistic or its distribution being fitted to the stopping decision, defined in terms of the stopping rule itself, or reduced to a self-citation chain. The extension to implicit losses (LambdaRank) and data-dependent losses (Cox via influence functions) is presented as a direct application of the same construction, not a redefinition that forces the result. The derivation therefore remains self-contained as an application of external statistical theory rather than a tautology or fitted-input prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The functional score test statistic has a known asymptotic distribution under the null hypothesis that the current predictor is the population risk minimizer.
Reference graph
Works this paper leans on
-
[1]
MEPS HC-233 : 2021 full year consolidated data file, 2023
Agency for Healthcare Research and Quality . MEPS HC-233 : 2021 full year consolidated data file, 2023. Medical Expenditure Panel Survey (MEPS)
2021
-
[2]
Andrews, D. W. K. Asymptotic results for generalized Wald tests. Econometric Theory, 3 0 (3): 0 348--358, June 1987. doi:10.1017/s0266466600010434
-
[3]
Aolaritei, L. and Jordan, M. I. Stopping rules for stochastic gradient descent via anytime-valid confidence sequences. arXiv:2512.13123, 2025
arXiv 2025
-
[4]
B \"u hlmann, P. and Hothorn, T. Boosting algorithms: Regularization, prediction and model fitting. Statistical Science, 22 0 (4): 0 477--505, November 2007. doi:10.1214/07-sts242
-
[5]
B \"u hlmann, P. and Yu, B. Boosting with the L_2 loss: Regression and classification. Journal of the American Statistical Association, 98 0 (462): 0 324--339, June 2003. doi:10.1198/016214503000125
-
[6]
Burges, C. J. C. From RankNet to LambdaRank to LambdaMART : An overview. Technical Report MSR-TR-2010-82, Microsoft Research, June 2010
2010
-
[7]
Burges, C. J. C., Ragno, R., and Le, Q. V. Learning to rank with nonsmooth cost functions. In Advances in Neural Information Processing Systems, volume 19. MIT Press, 2006
2006
-
[8]
Wald tests when restrictions are locally singular
Dufour, J.-M., Renault, E., and Zinde-Walsh, V. Wald tests when restrictions are locally singular. The Annals of Statistics, 53 0 (2): 0 457--476, April 2025. doi:10.1214/24-aos2398
-
[9]
Friedman, J. H. Greedy function approximation: A gradient boosting machine. The Annals of Statistics, 29 0 (5): 0 1189--1232, October 2001. doi:10.1214/aos/1013203451
-
[10]
The Annals of Statistics , author =
Friedman, J. H., Hastie, T., and Tibshirani, R. Additive logistic regression: A statistical view of boosting. The Annals of Statistics, 28 0 (2): 0 337--407, April 2000. doi:10.1214/aos/1016218223
-
[11]
Train faster, generalize better: Stability of stochastic gradient descent
Hardt, M., Recht, B., and Singer, Y. Train faster, generalize better: Stability of stochastic gradient descent. In Proceedings of The 33 rd International Conference on Machine Learning , volume 48, pp.\ 1225--1234, 2016
2016
-
[12]
Efficient error models for fault-tolerant architectures and the Pauli twirling approximation
Hines, O., Dukes, O., Diaz-Ordaz, K., and Vansteelandt, S. Demystifying statistical learning based on efficient influence functions. The American Statistician, 76 0 (3): 0 292--304, February 2022. doi:10.1080/00031305.2021.2021984
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/00031305.2021.2021984 2022
-
[13]
The generalization of Student 's ratio
Hotelling, H. The generalization of Student 's ratio. The Annals of Mathematical Statistics, 2 0 (3): 0 360--378, August 1931. doi:10.1214/aoms/1177732979
-
[14]
Howard, S. R., Ramdas, A., McAuliffe, J., and Sekhon, J. Time-uniform, nonparametric, nonasymptotic confidence sequences. The Annals of Statistics, 49 0 (2): 0 1055--1080, April 2021. doi:10.1214/20-aos1991
-
[15]
Inference on function-valued parameters using a restricted score test
Hudson, A., Carone, M., and Shojaie, A. Inference on function-valued parameters using a restricted score test. Journal of the Royal Statistical Society Series B: Statistical Methodology, 00: 0 1--24, 2026. doi:10.1093/rssssb/qkag043
-
[16]
LightGBM : A highly efficient gradient boosting decision tree
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., and Liu, T.-Y. LightGBM : A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[17]
Early stopping without a validation set
Mahsereci, M., Balles, L., Lassner, C., and Hennig, P. Early stopping without a validation set. arXiv:1703.09580, 2017
Pith/arXiv arXiv 2017
-
[18]
L., and Frean, M
Mason, L., Baxter, J., Bartlett, P. L., and Frean, M. Boosting algorithms as gradient descent. Advances in Neural Information Processing Systems, 12, 2000
2000
-
[19]
and Liu, T.-Y
Qin, T. and Liu, T.-Y. Introducing LETOR 4.0 datasets. Technical Report MSR-TR-2010-68, Microsoft Research, 2010
2010
-
[20]
Game-theoretic statistics and safe anytime-valid inference
Ramdas, A., Gr \" u nwald, P., Vovk, V., and Shafer, G. Game-theoretic statistics and safe anytime-valid inference. Statistical Science, 38 0 (4): 0 576--601, November 2023. doi:10.1214/23-sts894
-
[21]
Rao, C. R. Large sample tests of statistical hypotheses concerning several parameters with applications to problems of estimation. Mathematical Proceedings of the Cambridge Philosophical Society, 44 0 (1): 0 50--57, January 1948. doi:10.1017/s0305004100023987
-
[22]
J., and Yu, B
Raskutti, G., Wainwright, M. J., and Yu, B. Early stopping and non-parametric regression: An optimal data-dependent stopping rule. Journal of Machine Learning Research, 15 0 (11): 0 335--366, 2014
2014
-
[23]
The state of boosting
Ridgeway, G. The state of boosting. In Computing Science and Statistics, volume 31, pp.\ 172--181, 1999
1999
-
[24]
Shah, R. D. and Peters, J. The hardness of conditional independence testing and the generalised covariance measure. The Annals of Statistics, 48 0 (3), June 2020. doi:10.1214/19-aos1857
-
[25]
Towards e-value based stopping rules for Bayesian deep ensembles
Sommer, E., Schulte, R., Deubner, S., Kobialka, J., and R \"u gamer, D. Towards e-value based stopping rules for Bayesian deep ensembles. In OPTIMAL @ AISTATS 2026: Workshop on Optimisation and Post-Bayesian Inference in Machine Learning , Tangier, Morocco, May 2026
2026
-
[26]
Semiparametric theory and missing data
Tsiatis, A. Semiparametric theory and missing data. Springer Series in Statistics. Springer New York, 2006. doi:10.1007/0-387-37345-4
-
[27]
A researcher's guide to empirical risk minimization
van der Laan, L. A researcher's guide to empirical risk minimization. arXiv:2602.21501, 2026
arXiv 2026
-
[28]
Vanschoren, J., van Rijn, J. N., Bischl, B., and Torgo, L. OpenML : Networked science in machine learning. ACM SIGKDD Explorations Newsletter, 15 0 (2): 0 49--60, June 2014. doi:10.1145/2641190.2641198
-
[29]
Wei, Y., Yang, F., and Wainwright, M. J. Early stopping for kernel boosting algorithms: A general analysis with localized complexities. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[30]
Wilks, S. S. The large-sample distribution of the likelihood ratio for testing composite hypotheses. The Annals of Mathematical Statistics, 9 0 (1): 0 60--62, March 1938. doi:10.1214/aoms/1177732360
-
[31]
On early stopping in gradient descent learning
Yao, Y., Rosasco, L., and Caponnetto, A. On early stopping in gradient descent learning. Constructive Approximation, 26 0 (2): 0 289--315, April 2007. doi:10.1007/s00365-006-0663-2
-
[32]
Zhang, T. and Yu, B. Boosting with early stopping: Convergence and consistency. The Annals of Statistics, 33 0 (4): 0 1538--1579, August 2005. doi:10.1214/009053605000000255
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.