Learning Coherent Representations: A Topological Approach to Interpretability
Pith reviewed 2026-06-28 15:41 UTC · model grok-4.3
The pith
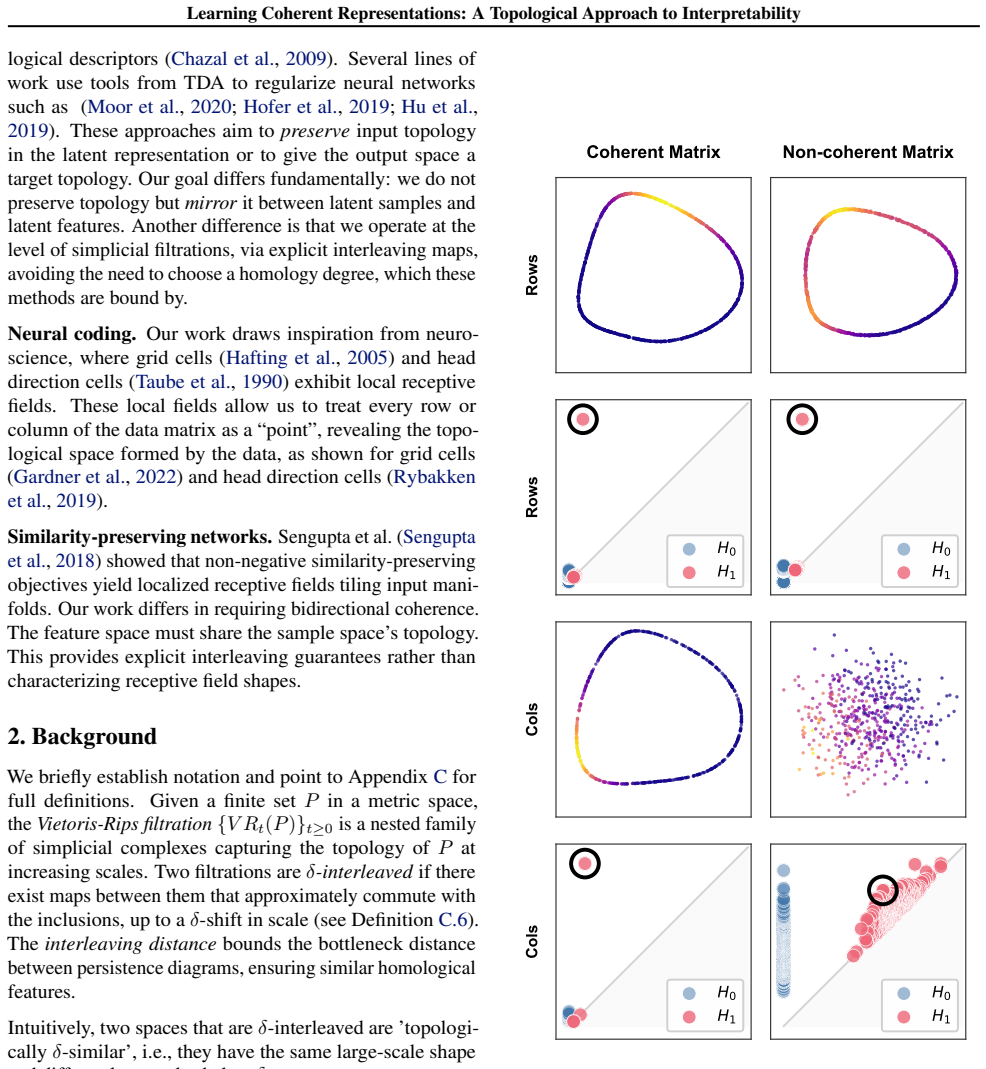
Coherent matrices induce bounded interleaving between Vietoris-Rips filtrations of samples and features, ensuring compatible topological structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
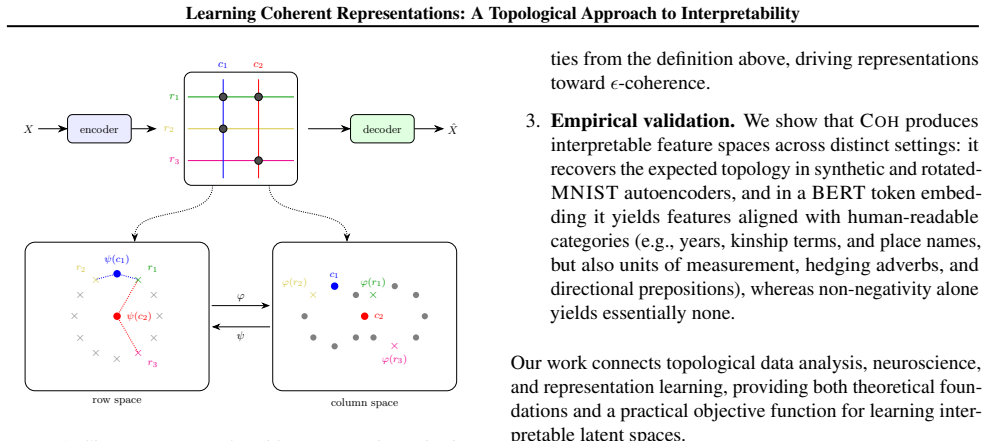
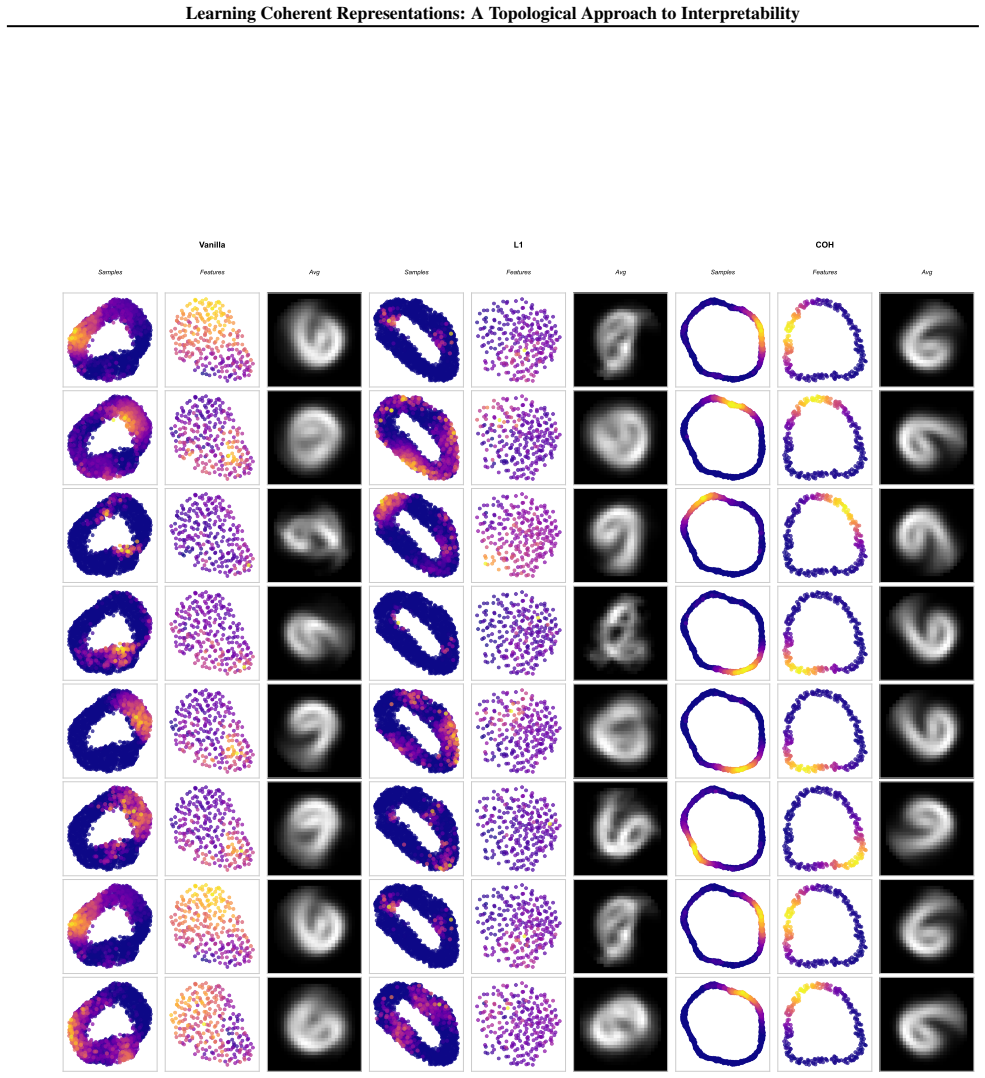
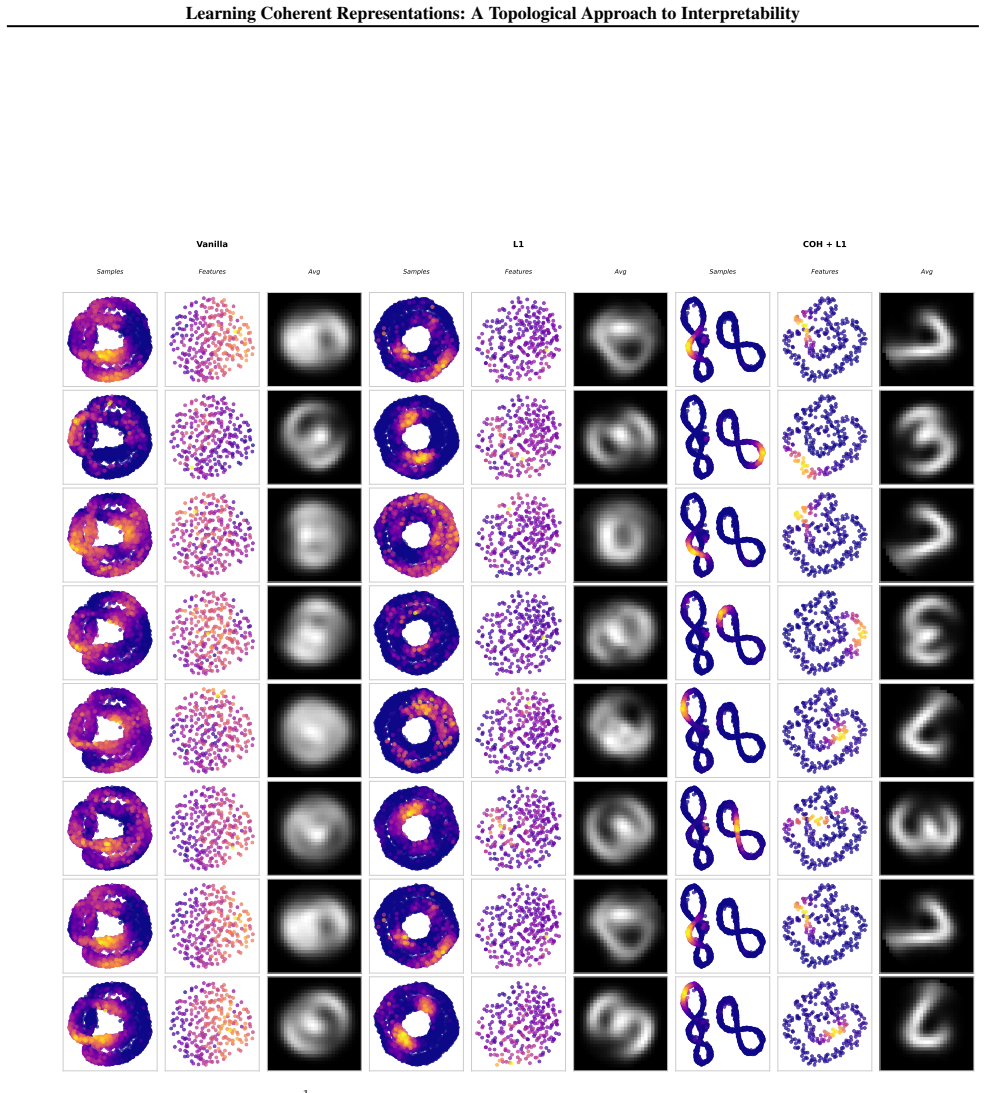
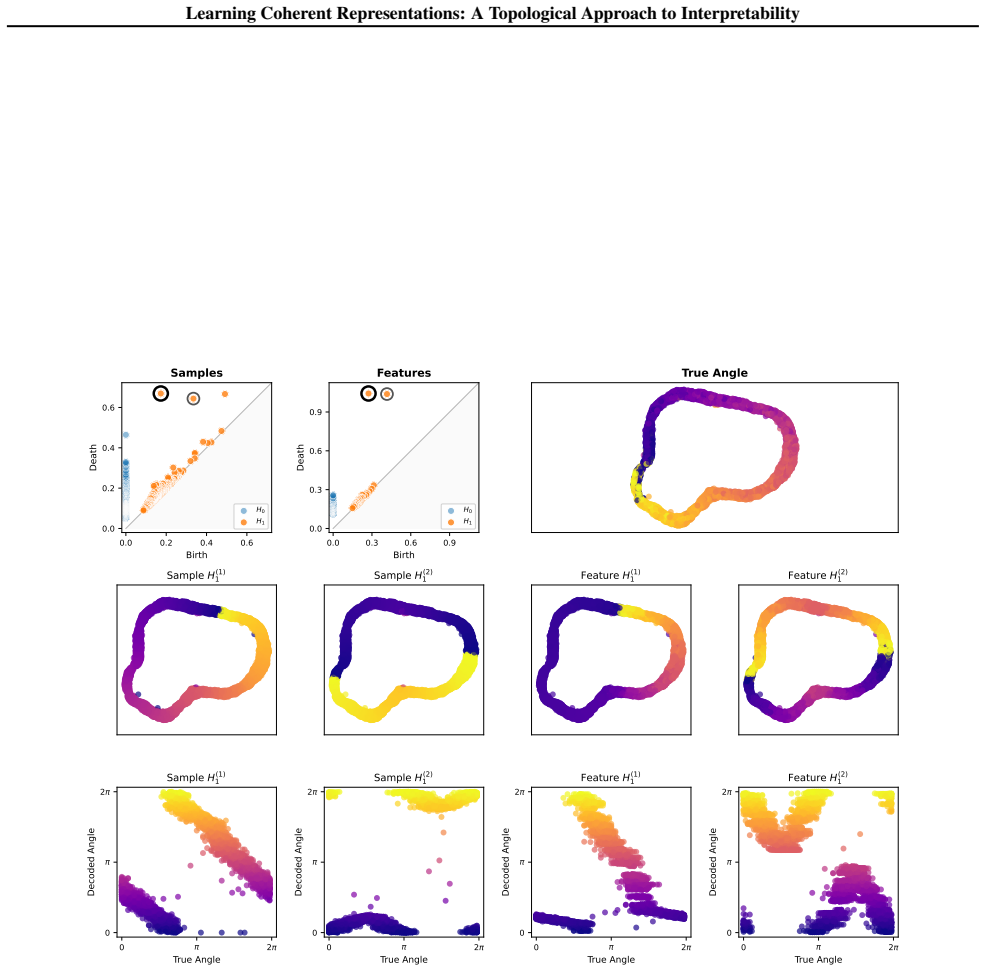
A non-negative matrix is coherent when rows attend to geometrically clustered columns and columns attend to geometrically clustered rows, with full coverage; such matrices induce a bounded interleaving between the Vietoris-Rips filtrations of the row space and column space, so that the two spaces share compatible topological structure. This constraint is enforced by minimizing the Coh objective based on Fréchet variance, which the authors apply inside auto-encoders on synthetic circle data and rotated MNIST as well as inside BERT token embeddings on language data.
What carries the argument
The coherence property of a matrix together with the Coh objective based on Fréchet variance, which together enforce geometrically clustered attendances that produce bounded interleaving of Vietoris-Rips filtrations.
If this is right
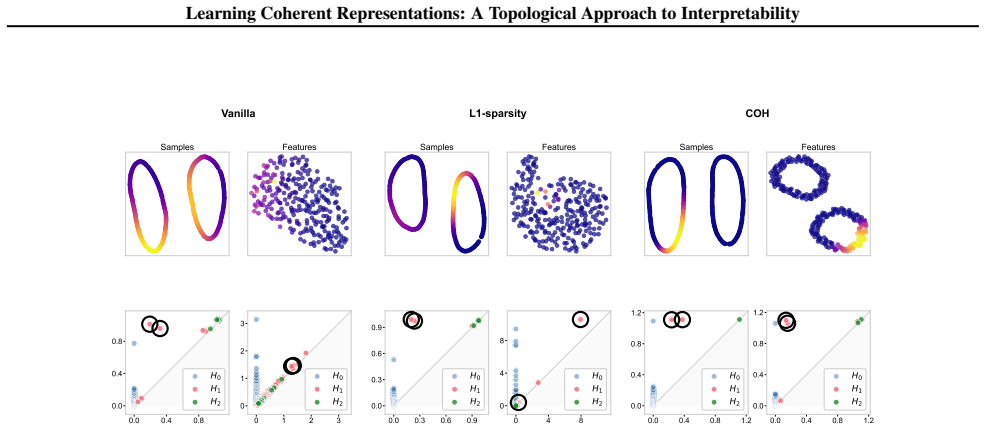
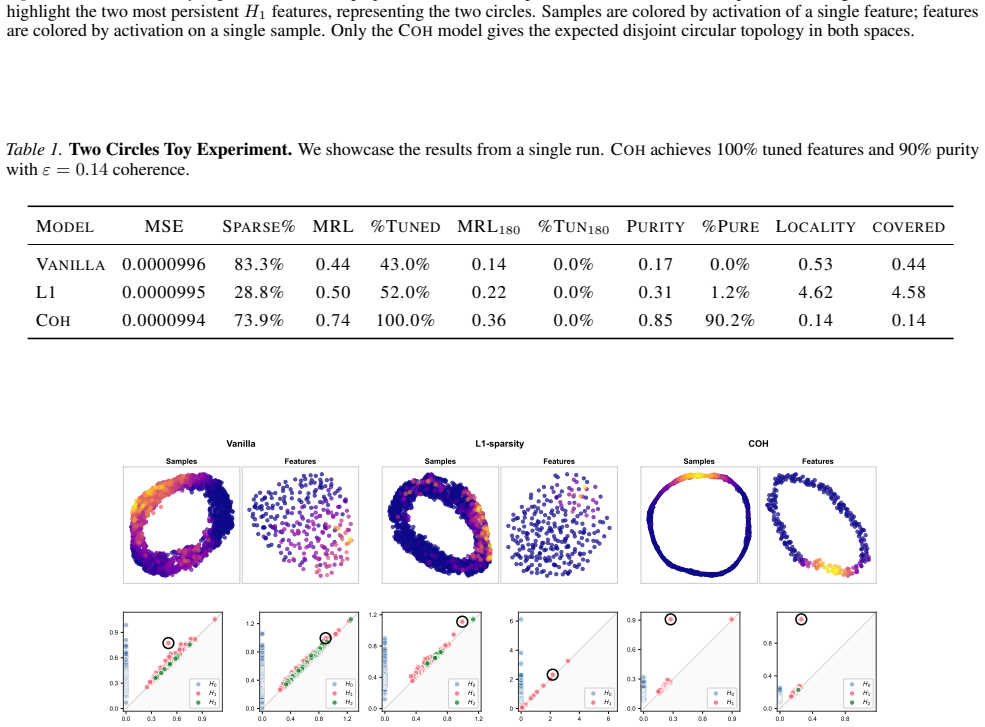
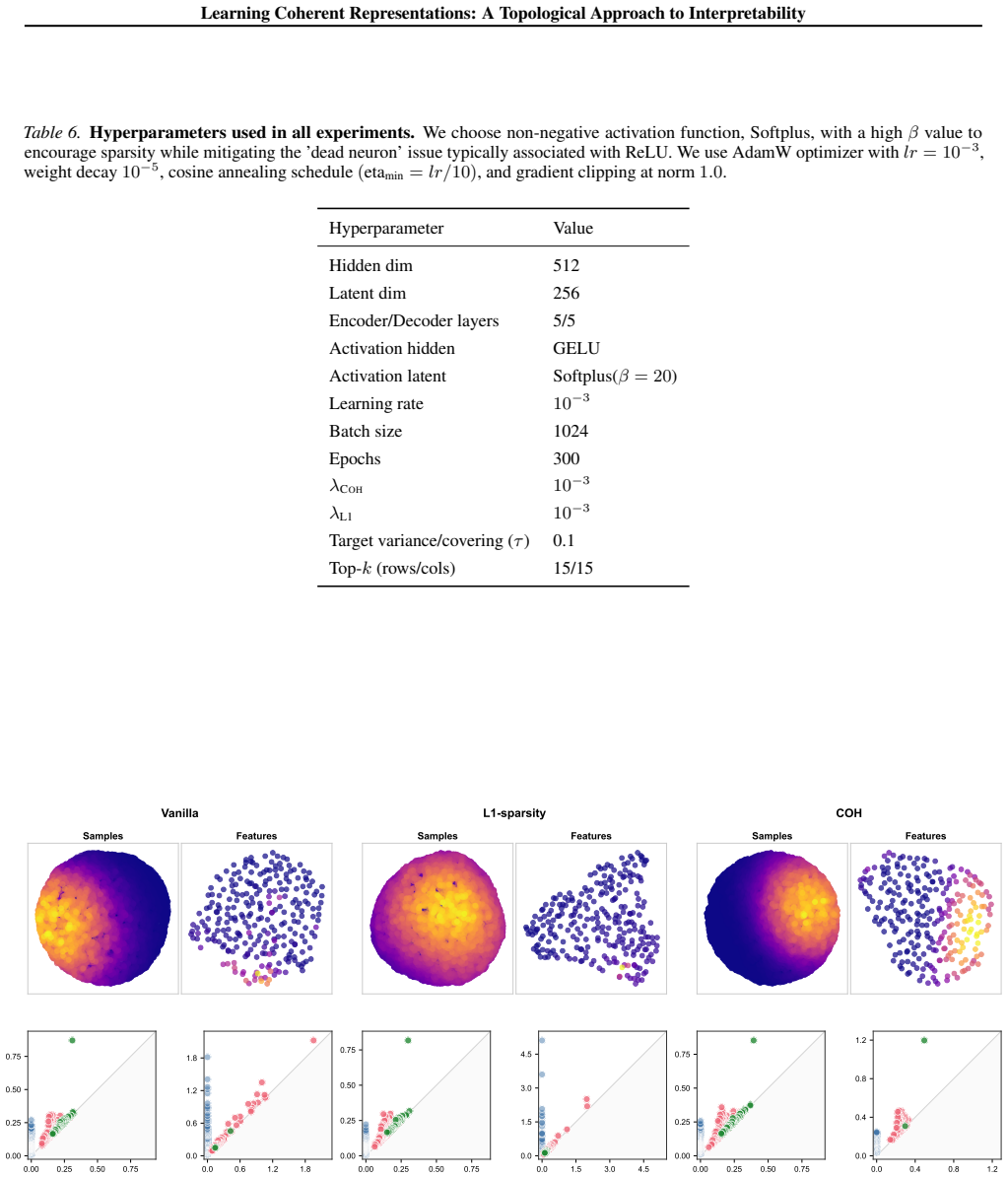
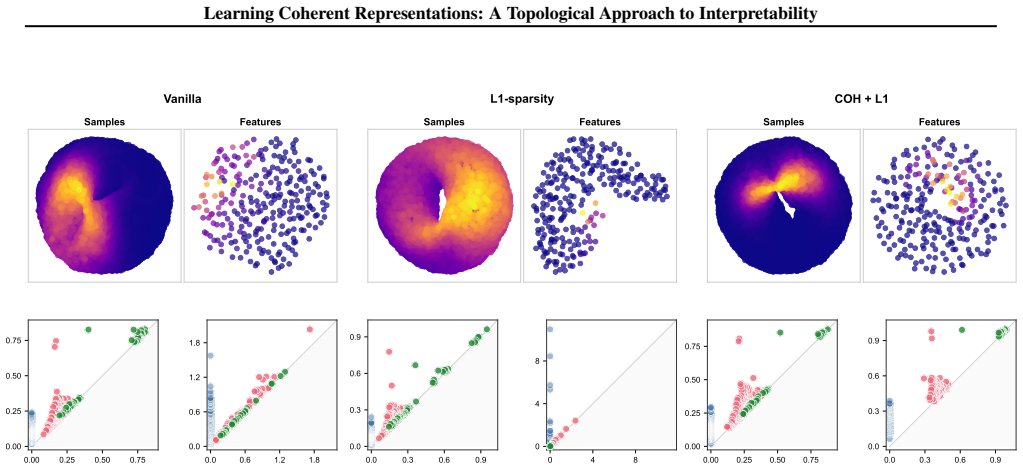
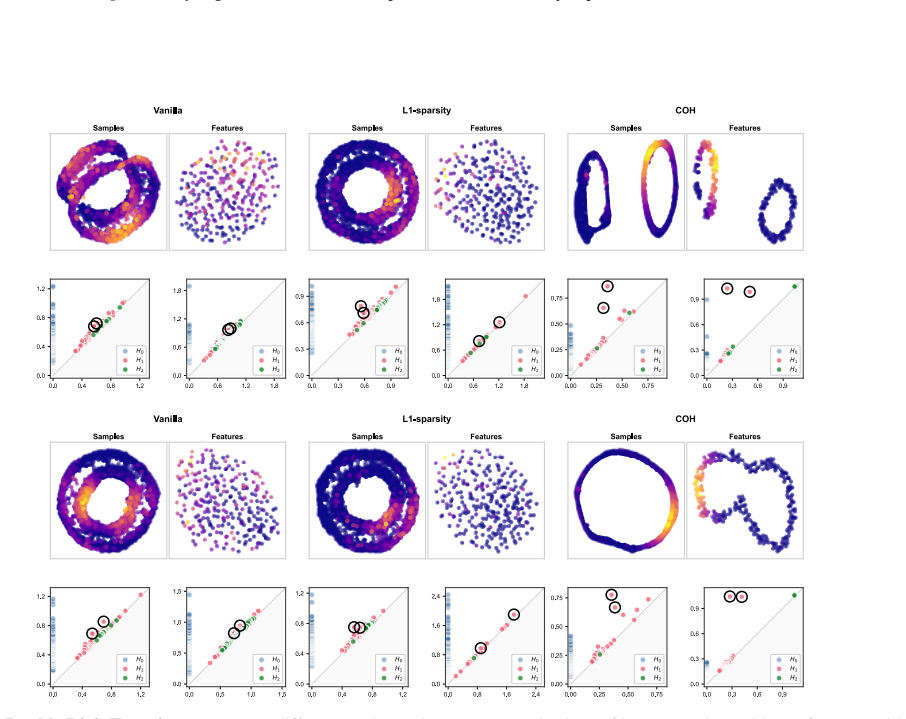
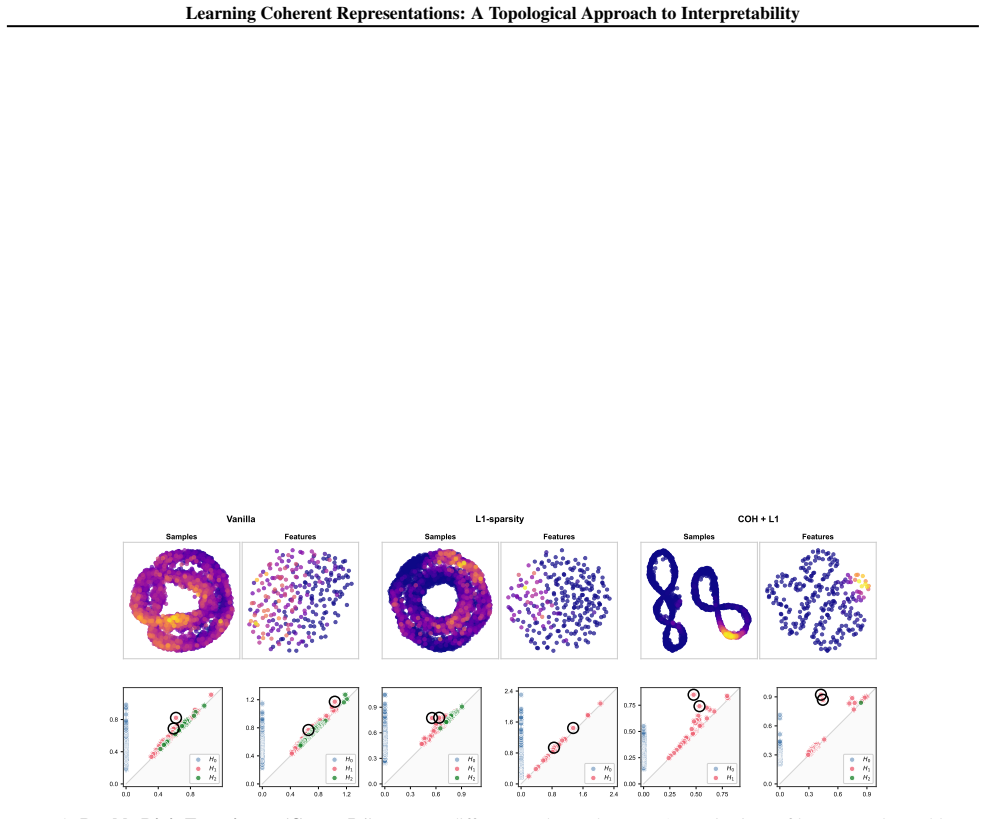
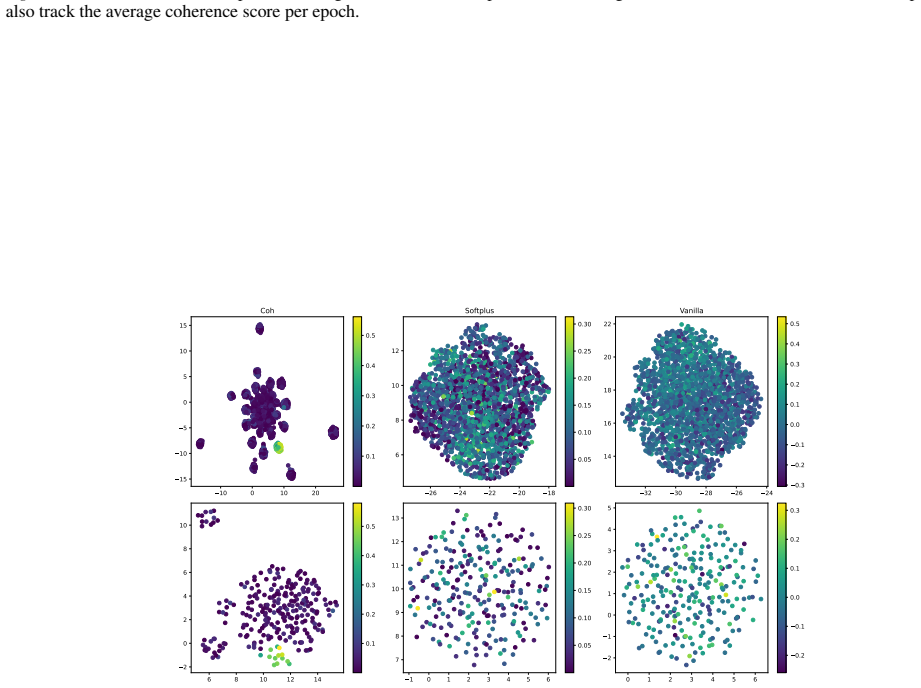
- When data lies on a circle, coherent features must tile the circle into contiguous arcs.
- Coherence supplies interpretability for both individual features and the geometry of the feature space itself.
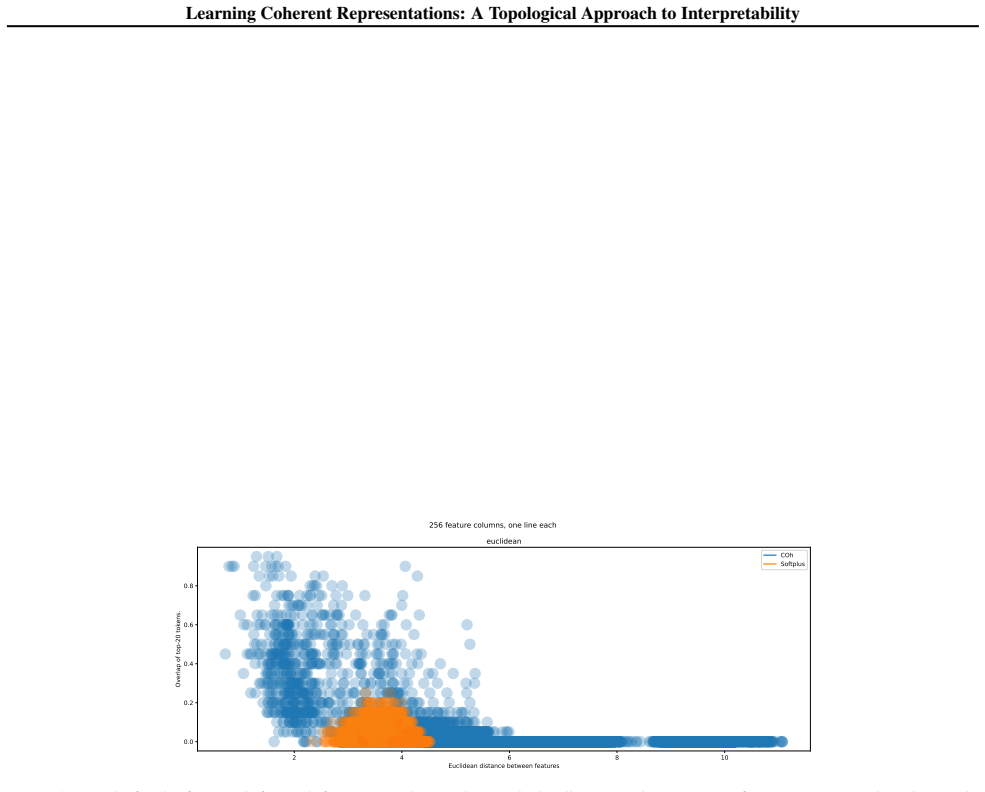
- Unlike sparsity, which only limits the number of samples per feature, coherence additionally requires that the active samples form a connected region.
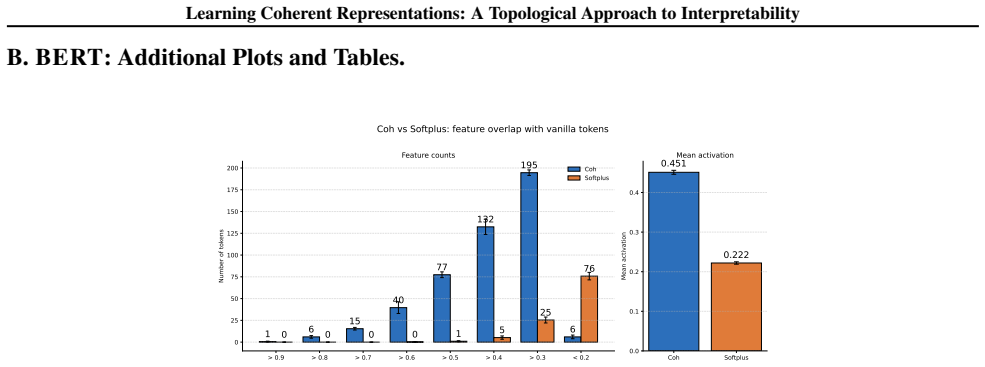
- The same coherence objective can be applied to token embeddings in language models to produce interpretable token representations.
Where Pith is reading between the lines
- The same coherence construction could be tested on data manifolds other than circles to check whether the bounded interleaving still produces human-readable features.
- Coherence might be combined with existing regularization techniques to add explicit topological constraints without requiring full manifold knowledge.
- If coherence improves interpretability on rotated MNIST, similar gains could appear in other rotation-equivariant or manifold-structured vision tasks.
- The brain-inspired motivation suggests that coherence regularizers might be useful for modeling place or grid cells in artificial systems, though the paper does not test this.
Load-bearing premise
That the geometric coherence produced by the Coh objective will yield features that are meaningfully interpretable to humans on real data distributions rather than merely satisfying the abstract geometric definition.
What would settle it
Training an auto-encoder with the Coh objective on points sampled from a circle and finding that the learned features fail to form contiguous arcs.
Figures





read the original abstract
Deep neural networks learn representations where individual features often lack interpretable meaning; a single neuron may activate for scattered, unrelated inputs. We introduce coherence, a geometric property inspired by neural coding in the brain, where neurons like grid cells and head direction cells respond to contiguous regions of state space. A non-negative matrix is coherent if each row (sample) attends to geometrically clustered columns (features) and vice versa, and in addition every sample is well described by some feature and every feature is needed by some sample. We prove that coherent matrices induce a bounded interleaving between the Vietoris-Rips filtrations of samples and features, guaranteeing that both spaces share compatible topological structure. This geometric constraint facilitates interpretability. For example, if data lies on a circle, coherent features must tile that circle into contiguous arcs. We introduce Coh, a differentiable objective function based on Fr\'echet variance that enforces coherence during training. Unlike sparsity, which bounds how many samples a feature activates on, coherence bounds which samples, requiring geometric connectivity rather than only rarity. This yields not just interpretable features but an interpretable feature space. We validate Coh in an auto-encoder using synthetic and rotated MNIST datasets and in a token embedding of BERT using language data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines coherence as a geometric property of non-negative matrices requiring bidirectional clustering of rows (samples) to columns (features) and vice versa, plus coverage conditions ensuring every sample is described by some feature and every feature is used by some sample. It proves that any matrix satisfying this definition induces a bounded interleaving between the Vietoris-Rips filtrations on the sample space and feature space. The paper introduces the differentiable Coh objective, based on Fréchet variance, to enforce coherence during training, contrasts it with sparsity, and validates the approach in an autoencoder on synthetic and rotated MNIST data as well as in BERT token embeddings on language data.
Significance. If the central claim holds, the work supplies a parameter-free topological guarantee that links a geometric matrix property directly to compatible persistent homology between dual spaces, providing a rigorous alternative to sparsity for interpretability. The proof is presented as a direct consequence of the coherence definition with no evident additional assumptions or fitted quantities, which strengthens the contribution. Experiments illustrate the objective's effect on feature geometry, though quantitative measures of improved human interpretability are not reported.
minor comments (3)
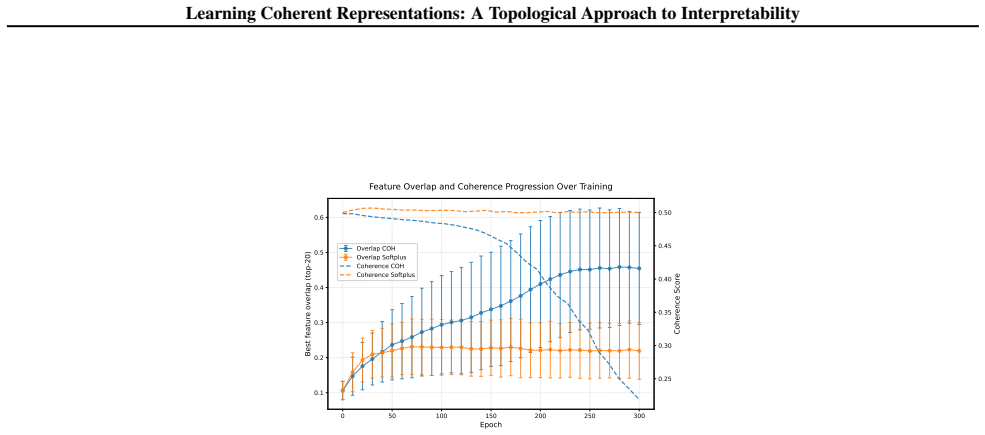
- [§4] §4 (experiments): the rotated MNIST and BERT results would benefit from explicit comparison metrics (e.g., human annotation agreement or downstream task performance) to substantiate the interpretability claim beyond qualitative examples.
- [§3] The definition of the Coh objective in terms of Fréchet variance is introduced without an explicit equation number; adding one would improve traceability to the coherence conditions.
- [Figure 2] Figure captions for the synthetic circle example could more clearly annotate the interleaving bound value derived in the proof.
Simulated Author's Rebuttal
We thank the referee for their accurate summary of the manuscript and for the positive evaluation of its significance. The recommendation of minor revision is noted. However, the report contains no specific major comments to address.
Circularity Check
No significant circularity identified
full rationale
The paper defines coherence as a geometric property on non-negative matrices (bidirectional clustering plus coverage). It then proves that any matrix meeting this definition induces a bounded interleaving between the Vietoris-Rips filtrations of its row and column spaces. This is presented as a direct mathematical consequence of the definition itself, with no reduction to fitted parameters, self-citations, or ansatzes. The Coh objective is introduced separately as a differentiable loss to encourage the property during training; its empirical success is an independent question. No load-bearing self-citation chains, self-definitional steps, or renamed known results appear in the abstract or described claims. The derivation chain is therefore self-contained against external topological benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coherent matrices induce a bounded interleaving between Vietoris-Rips filtrations of samples and features
invented entities (1)
-
coherence property
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gardner and Erik Hermansen and Marius Pachitariu and Yoram Burak and Nils A
Richard J. Gardner and Erik Hermansen and Marius Pachitariu and Yoram Burak and Nils A. Baas and Benjamin A. Dunn and May-Britt Moser and Edvard I. Moser , title =. Nature , year =
-
[2]
Vin de Silva and Dmitriy Morozov and Mikael Vejdemo-Johansson , title =. Discrete. 2011 , volume =. doi:10.1007/s00454-011-9344-x , url =
-
[3]
C. H. Dowker , journal =. Homology Groups of Relations , urldate =
-
[4]
Proximity of Persistence Modules and Their Diagrams , booktitle =
Chazal, Fr. Proximity of Persistence Modules and Their Diagrams , booktitle =. 2009 , location =. doi:10.1145/1542362.1542407 , note =
-
[5]
Distill , year =
Olah, Chris and Cammarata, Nick and Schubert, Ludwig and Goh, Gabriel and Petrov, Michael and Carter, Shan , title =. Distill , year =
-
[6]
Bronstein and Joan Bruna and Taco Cohen and Petar Velickovic , title =
Michael M. Bronstein and Joan Bruna and Taco Cohen and Petar Velickovic , title =. CoRR , volume =. 2021 , url =. 2104.13478 , timestamp =
Pith/arXiv arXiv 2021
-
[7]
, title =
Carlsson, Gunnar E. , title =. Bulletin of the American Mathematical Society , volume =. 2009 , doi =
2009
-
[8]
Topology-Preserving Deep Image Segmentation , url =
Hu, Xiaoling and Li, Fuxin and Samaras, Dimitris and Chen, Chao , booktitle =. Topology-Preserving Deep Image Segmentation , url =
-
[9]
Manifold-tiling Localized Receptive Fields are Optimal in Similarity-preserving Neural Networks , url =
Sengupta, Anirvan and Pehlevan, Cengiz and Tepper, Mariano and Genkin, Alexander and Chklovskii, Dmitri , booktitle =. Manifold-tiling Localized Receptive Fields are Optimal in Similarity-preserving Neural Networks , url =
-
[10]
Proceedings of the 36th International Conference on Machine Learning , pages =
Connectivity-Optimized Representation Learning via Persistent Homology , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[11]
Perea and Luis Scoccola and Christopher J
Jose A. Perea and Luis Scoccola and Christopher J. Tralie , title =. 2023 , publisher =
2023
-
[12]
Lee and Haim Sompolinsky , title =
Uri Cohen and SueYeon Chung and Daniel D. Lee and Haim Sompolinsky , title =. Nature Communications , year =
-
[13]
Neural Computation , year =
Erik Rybakken and Nils Baas and Benjamin Dunn , title =. Neural Computation , year =
-
[14]
C. H. Dowker , title =. Annals of Mathematics , year =
-
[15]
Topological methods , booktitle =
Anders Bj. Topological methods , booktitle =. 1996 , editor =
1996
-
[16]
Algebraic Topology , author =. 1994 , publisher =. doi:10.1007/978-1-4684-9322-1 , note =
-
[17]
Tralie, Christopher and Saul, Nathaniel and Bar-On, Rann , title =. 2018 , publisher =. doi:10.21105/joss.00925 , url =
-
[18]
ICML , year=
Topological autoencoders , author=. ICML , year=
-
[19]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[20]
Higgins, Irina and others , booktitle=. -
-
[21]
ICML , year=
Emergence of separable manifolds in deep language representations , author=. ICML , year=
-
[22]
Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
Hoagy Cunningham and Aidan Ewart and Logan Riggs and Robert Huben and Lee Sharkey , title =. Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =
-
[23]
Olshausen and David J
Bruno A. Olshausen and David J. Field , title =. Nature , year =
-
[24]
Moser , title =
Torkel Hafting and Marianne Fyhn and Sturla Molden and May-Britt Moser and Edvard I. Moser , title =. Nature , year =
-
[25]
Taube and Robert U
Jeffrey S. Taube and Robert U. Muller and James B. Ranck Jr. , title =. Journal of Neuroscience , year =
-
[26]
McInnes, Leland and Healy, John and Saul, Nathaniel and Großberger, Lukas , title =. 2018 , publisher =. doi:10.21105/joss.00861 , url =
-
[27]
Ripser: efficient computation of
Bauer, Ulrich , journal=. Ripser: efficient computation of. 2021 , publisher=
2021
-
[28]
arXiv preprint arXiv:2209.10652 , year=
Toy models of superposition , author=. arXiv preprint arXiv:2209.10652 , year=
-
[29]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[30]
International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. International Conference on Learning Representations , year=
-
[31]
Topological methods , booktitle =
Bj. Topological methods , booktitle =
-
[32]
Mediterranean Journal of Mathematics , volume =
Brun, Morten and Salbu, Lars-Arne , title =. Mediterranean Journal of Mathematics , volume =
-
[33]
Brun, Morten and Grinberg, Darij , title =. 2407.15454 , archiveprefix =
- [34]
-
[35]
A functorial
Chowdhury, Samir and M. A functorial. Journal of Applied and Computational Topology , volume =
-
[36]
Rips complexes as nerves and a functorial
Virk,. Rips complexes as nerves and a functorial. Mediterranean Journal of Mathematics , volume =
-
[37]
Journal of Applied and Computational Topology , volume =
Robinson, Michael , title =. Journal of Applied and Computational Topology , volume =
-
[38]
Persistence stability for geometric complexes , journal =
Chazal, Fr. Persistence stability for geometric complexes , journal =
-
[39]
Publications Math
Segal, Graeme , title =. Publications Math
-
[40]
, title =
Dugger, Daniel and Isaksen, Daniel C. , title =. Mathematische Zeitschrift , volume =
-
[41]
Vaupel, Melvin and Dunn, Benjamin , title =. 2310.11529 , archiveprefix =
-
[42]
2026 , howpublished =
Anthropic , title =. 2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.