SEA-Embedding: Open and Reproducible Text Embeddings for Southeast Asia
Pith reviewed 2026-06-28 10:46 UTC · model grok-4.3
The pith
SEA-Embedding delivers an open, reproducible pipeline that trains competitive text embeddings for Southeast Asian languages using only public data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
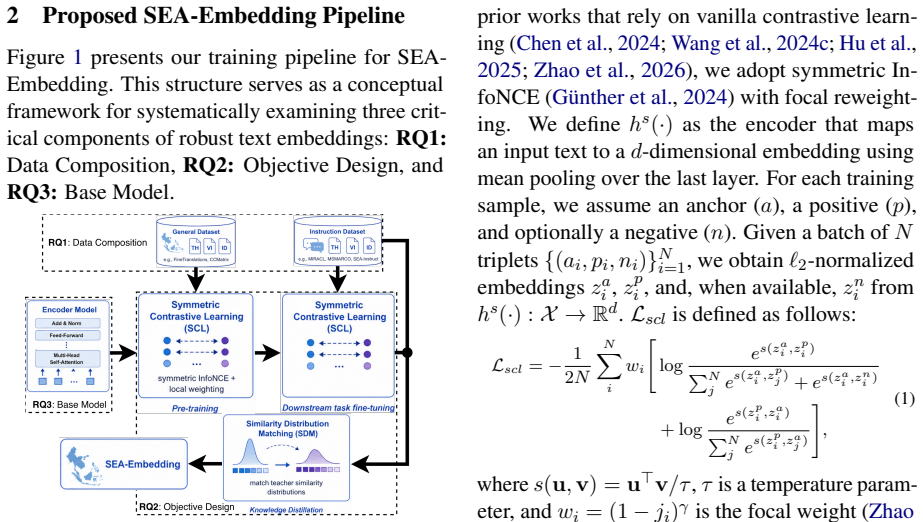
We present SEA-Embedding, a fully open and reproducible text-embedding pipeline for Southeast Asian languages trained only on publicly available data, and use it to study three core factors of robust embedding design: data composition, training objective, and base encoder initialization. SEA-Embedding achieves state-of-the-art results on SEA-BED while enabling systematic and reproducible analysis of robust text embeddings for the region.
What carries the argument
The SEA-Embedding training pipeline, which isolates and measures the separate contributions of data composition, training objective, and base encoder initialization to embedding robustness.
If this is right
- Researchers can now replicate the exact training choices that produced the reported SEA-BED gains.
- Varying data mix, loss function, and starting encoder independently shows which factor most improves robustness for the target languages.
- Future models for the region can start from the released weights and data rather than closed resources.
- The same controlled comparison framework can be applied to test new public datasets as they become available.
Where Pith is reading between the lines
- The same public-data approach could be tested on other low-resource language families to check whether closed-data advantages are language-specific.
- If the three factors interact differently across language families, the pipeline offers a ready template for repeating the ablation study elsewhere.
- Releasing the full training code and data lists lowers the barrier for groups without access to proprietary corpora to contribute embedding improvements.
Load-bearing premise
Publicly available data alone is enough to produce embeddings that match or exceed the performance of models trained on closed datasets for Southeast Asian languages.
What would settle it
Re-running the SEA-Embedding pipeline on the same public data and finding that it falls short of the reported state-of-the-art scores on SEA-BED.
Figures
read the original abstract
Text embeddings are fundamental to many downstream applications, making robustness important for real-world NLP. However, most recent state-of-the-art embedding models are not reproducible because they rely on closed or undisclosed training data, and they remain insufficiently robust for Southeast Asian languages. We present SEA-Embedding, a fully open and reproducible text-embedding pipeline for Southeast Asian languages trained only on publicly available data, and use it to study three core factors of robust embedding design: data composition, training objective, and base encoder initialization. SEA-Embedding achieves state-of-the-art results on SEA-BED while enabling systematic and reproducible analysis of robust text embeddings for the region.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SEA-Embedding, a fully open and reproducible text-embedding pipeline for Southeast Asian languages trained exclusively on publicly available data. It claims state-of-the-art results on the SEA-BED benchmark and uses the open pipeline to systematically analyze the impact of data composition, training objective, and base encoder initialization on embedding robustness for the region.
Significance. If the reported results hold, the work is significant for addressing the reproducibility crisis in embedding models by releasing a fully open pipeline and public resources. This enables verifiable and extensible research on Southeast Asian languages, a historically under-served area. The explicit focus on systematic study of design factors, supported by open code and data, is a clear strength that directly mitigates the non-reproducibility problem highlighted in the abstract.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work and for recommending minor revision. We appreciate the recognition of the manuscript's contributions to reproducibility and systematic analysis for Southeast Asian language embeddings.
Circularity Check
No significant circularity
full rationale
The paper's central claim rests on an empirical training pipeline using only publicly available data, followed by evaluation on the SEA-BED benchmark and ablation studies over data composition, objective, and initialization. No equations, derivations, or load-bearing steps are described that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The work is structured as an open reproduction effort, with results presented as outcomes of the described training rather than presupposed by the method itself. This is the standard non-circular case for an empirical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MTEB : Massive Text Embedding Benchmark
Muennighoff, Niklas and Tazi, Nouamane and Magne, Loic and Reimers, Nils. MTEB : Massive Text Embedding Benchmark. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2023. doi:10.18653/v1/2023.eacl-main.148
-
[6]
The Thirteenth International Conference on Learning Representations , year=
Kenneth Enevoldsen and Isaac Chung and Imene Kerboua and M. The Thirteenth International Conference on Learning Representations , year=
-
[8]
2018 , eprint=
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset , author=. 2018 , eprint=
2018
-
[9]
2025 , eprint=
SEA-BED: Southeast Asia Embedding Benchmark , author=. 2025 , eprint=
2025
-
[11]
A o E : Angle-optimized Embeddings for Semantic Textual Similarity
Li, Xianming and Li, Jing. A o E : Angle-optimized Embeddings for Semantic Textual Similarity. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.101
-
[12]
2024 , eprint=
Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents , author=. 2024 , eprint=
2024
-
[13]
Unsupervised Cross-lingual Representation Learning at Scale
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
-
[14]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Hu, Junjie and Ruder, Sebastian and Siddhant, Aditya and Neubig, Graham and Firat, Orhan and Johnson, Melvin , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
2020
-
[15]
2025 , eprint=
mmBERT: A Modern Multilingual Encoder with Annealed Language Learning , author=. 2025 , eprint=
2025
-
[16]
2025 , url=
EmbeddingGemma: Powerful and Lightweight Text Representations , author=. 2025 , url=
2025
-
[17]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[18]
2024 , eprint=
jina-embeddings-v3: Multilingual Embeddings With Task LoRA , author=. 2024 , eprint=
2024
-
[19]
Hugging Face repository , howpublished =
FineTranslations , author=. Hugging Face repository , howpublished =. 2026 , publisher =
2026
-
[21]
2023 , eprint=
Towards General Text Embeddings with Multi-stage Contrastive Learning , author=. 2023 , eprint=
2023
-
[22]
The Thirteenth International Conference on Learning Representations , year=
Generative Representational Instruction Tuning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
2024 , eprint=
Multilingual E5 Text Embeddings: A Technical Report , author=. 2024 , eprint=
2024
-
[24]
2025 , eprint=
KaLM-Embedding: Superior Training Data Brings A Stronger Embedding Model , author=. 2025 , eprint=
2025
-
[25]
2026 , eprint=
jina-embeddings-v5-text: Task-Targeted Embedding Distillation , author=. 2026 , eprint=
2026
-
[26]
2025 , eprint=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. 2025 , eprint=
2025
-
[27]
Xinping Zhao and Xinshuo Hu and Zifei Shan and Shouzheng Huang and Yao Zhou and Xin Zhang and Zetian Sun and zhenyu liu and Dongfang Li and Xinyuan Wei and Youcheng Pan and Yang Xiang and Meishan Zhang and Haofen Wang and Jun Yu and Baotian Hu and Min Zhang , booktitle=. Ka. 2026 , url=
2026
-
[28]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[29]
2024 , eprint=
Text Embeddings by Weakly-Supervised Contrastive Pre-training , author=. 2024 , eprint=
2024
-
[31]
Mohammad Kalim Akram, Saba Sturua, Nastia Havriushenko, Quentin Herreros, Michael Günther, Maximilian Werk, and Han Xiao. 2026. https://arxiv.org/abs/2602.15547 jina-embeddings-v5-text: Task-targeted embedding distillation . Preprint, arXiv:2602.15547
Pith/arXiv arXiv 2026
-
[32]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.137 M 3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation . In Findings of the Association for Computational Linguistics: ACL 2024, pages 2318--2335, Bangkok,...
-
[33]
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, M \'a rton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemi \'n ski, Genta Indra Winata, Saba Sturua, Saiteja Utpala, Mathieu Ciancone, Marion Schaeffer, Diganta Misra, Shreeya Dhakal, Jonathan Rystr m, Roman Solomatin, \"O mer Veysel C a g atan, and 63 others. 2025. https://openre...
2025
-
[34]
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.552 S im CSE : Simple contrastive learning of sentence embeddings . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894--6910, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics
-
[35]
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, and Han Xiao. 2024. https://arxiv.org/abs/2310.19923 Jina embeddings 2: 8192-token general-purpose text embeddings for long documents . Preprint, arXiv:2310.19923
arXiv 2024
-
[36]
Xinshuo Hu, Zifei Shan, Xinping Zhao, Zetian Sun, Zhenyu Liu, Dongfang Li, Shaolin Ye, Xinyuan Wei, Qian Chen, Baotian Hu, Haofen Wang, Jun Yu, and Min Zhang. 2025. https://arxiv.org/abs/2501.01028 Kalm-embedding: Superior training data brings a stronger embedding model . Preprint, arXiv:2501.01028
arXiv 2025
-
[37]
Guilherme Penedo, Hynek Kydl \' c ek, Amir Hossein Kargaran, and Leandro von Werra. 2026. Finetranslations. https://huggingface.co/datasets/HuggingFaceFW/finetranslations
2026
-
[38]
Wuttikorn Ponwitayarat, Raymond Ng, Jann Railey Montalan, Thura Aung, Jian Gang Ngui, Yosephine Susanto, William Tjhi, Panuthep Tasawong, Erik Cambria, Ekapol Chuangsuwanich, Sarana Nutanong, and Peerat Limkonchotiwat. 2025. https://arxiv.org/abs/2508.12243 Sea-bed: Southeast asia embedding benchmark . Preprint, arXiv:2508.12243
Pith/arXiv arXiv 2025
-
[39]
Nils Reimers and Iryna Gurevych. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.365 Making monolingual sentence embeddings multilingual using knowledge distillation . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4512--4525, Online. Association for Computational Linguistics
-
[40]
Henrique* Schechter Vera, Sahil* Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, Daniel Cer, Alice Lisak, Min Choi, Lucas Gonzalez, Omar Sanseviero, Glenn Cameron, Ian Ballantyne, Kat Black, Kaifeng Chen, and 69 others. 2025. https://arxiv.org/abs/2509.20354 Embeddinggemma: Powerful and...
Pith/arXiv arXiv 2025
-
[41]
Holger Schwenk, Guillaume Wenzek, Sergey Edunov, Edouard Grave, Armand Joulin, and Angela Fan. 2021. https://doi.org/10.18653/v1/2021.acl-long.507 CCM atrix: Mining billions of high-quality parallel sentences on the web . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference ...
-
[42]
Shivalika Singh, Angelika Romanou, Cl \'e mentine Fourrier, David Ifeoluwa Adelani, Jian Gang Ngui, Daniel Vila-Suero, Peerat Limkonchotiwat, Kelly Marchisio, Wei Qi Leong, Yosephine Susanto, Raymond Ng, Shayne Longpre, Sebastian Ruder, Wei-Yin Ko, Antoine Bosselut, Alice Oh, Andre Martins, Leshem Choshen, Daphne Ippolito, and 4 others. 2025. https://doi....
-
[43]
Yosephine Susanto, Adithya Venkatadri Hulagadri, Jann Railey Montalan, Jian Gang Ngui, Xianbin Yong, Wei Qi Leong, Hamsawardhini Rengarajan, Peerat Limkonchotiwat, Yifan Mai, and William Chandra Tjhi. 2025. https://doi.org/10.18653/v1/2025.findings-acl.636 SEA - HELM : S outheast A sian holistic evaluation of language models . In Findings of the Associati...
-
[44]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2024 a . https://arxiv.org/abs/2212.03533 Text embeddings by weakly-supervised contrastive pre-training . Preprint, arXiv:2212.03533
Pith/arXiv arXiv 2024
-
[45]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024 b . https://doi.org/10.18653/v1/2024.acl-long.642 Improving text embeddings with large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11897--11916, Bangkok, Thailand. Associatio...
-
[46]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024 c . https://arxiv.org/abs/2402.05672 Multilingual e5 text embeddings: A technical report . Preprint, arXiv:2402.05672
Pith/arXiv arXiv 2024
-
[47]
Xinyu Zhang, Nandan Thakur, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo, Xiaoguang Li, Qun Liu, Mehdi Rezagholizadeh, and Jimmy Lin. 2023. https://doi.org/10.1162/tacl_a_00595 MIRACL : A multilingual retrieval dataset covering 18 diverse languages . Transactions of the Association for Computational Linguistics, 11:1114--1131
-
[48]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. https://arxiv.org/abs/2506.05176 Qwen3 embedding: Advancing text embedding and reranking through foundation models . Preprint, arXiv:2506.05176
Pith/arXiv arXiv 2025
-
[49]
Xinping Zhao, Xinshuo Hu, Zifei Shan, Shouzheng Huang, Yao Zhou, Xin Zhang, Zetian Sun, zhenyu liu, Dongfang Li, Xinyuan Wei, Youcheng Pan, Yang Xiang, Meishan Zhang, Haofen Wang, Jun Yu, Baotian Hu, and Min Zhang. 2026. https://openreview.net/forum?id=Y7qzhvWhcz Ka LM -embedding-v2: Superior training techniques and data inspire a versatile embedding mode...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.