Multi-component Causal Tracing in Large Language Models
Pith reviewed 2026-06-28 11:50 UTC · model grok-4.3
The pith
A new algorithm identifies groups of LLM components that causally drive target metrics by converting discrete selection into continuous optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper presents a unified framework for multi-component causal tracing that systematically identifies the subsets of model components most critical to a desired target performance metric. This is achieved by incorporating flexible interventions applied to a wide range of desired metrics and designing an efficient algorithm that leverages soft interventions together with a carefully designed metric transformation, converting the combinatorial search problem into a continuous one that can be solved efficiently under proper constraints, thereby generating proper binary decisions for selecting components.
What carries the argument
The efficient algorithm that applies soft interventions and a metric transformation to convert combinatorial multi-component selection into continuous optimization under constraints.
If this is right
- Subsets of attention heads and MLP neurons can be traced simultaneously for their joint effect on a metric.
- The approach works with flexible interventions across a range of target metrics including accuracy and fairness.
- The continuous relaxation yields binary selection decisions that are more efficient than exhaustive search.
- Experimental results show the selected subsets have higher impact on the target metric than those found by existing baselines.
Where Pith is reading between the lines
- The same transformation could be applied to trace components that affect safety-related metrics such as refusal behavior.
- Once high-impact subsets are located, targeted fine-tuning or editing could be restricted to those components rather than the full model.
- The continuous formulation may generalize to other discrete selection problems in neural network analysis beyond transformers.
- Repeated application across different prompts could map how component importance shifts with input distribution.
Load-bearing premise
The soft interventions combined with the metric transformation accurately reflect true causal contributions without introducing bias or losing critical information from the original combinatorial structure.
What would settle it
A controlled test in which the subsets selected by the algorithm are intervened upon yet produce no measurable change in the target metric, or in which the method fails to outperform standard baselines on held-out examples.
Figures
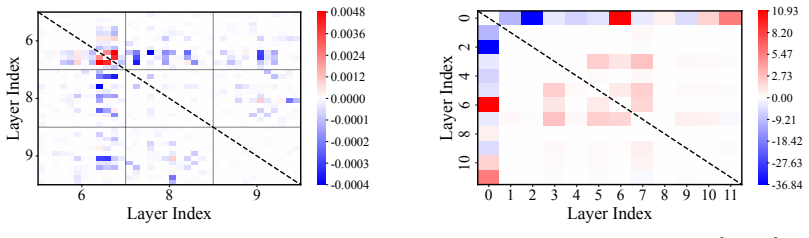
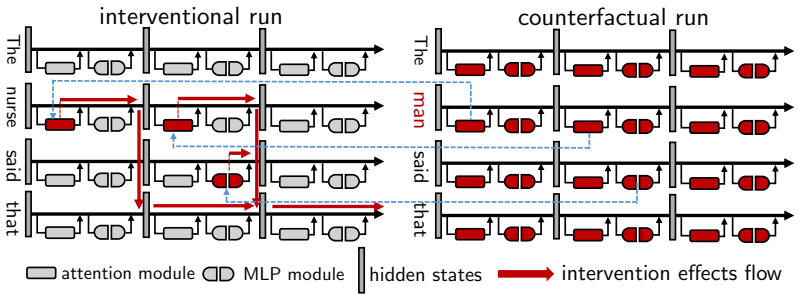
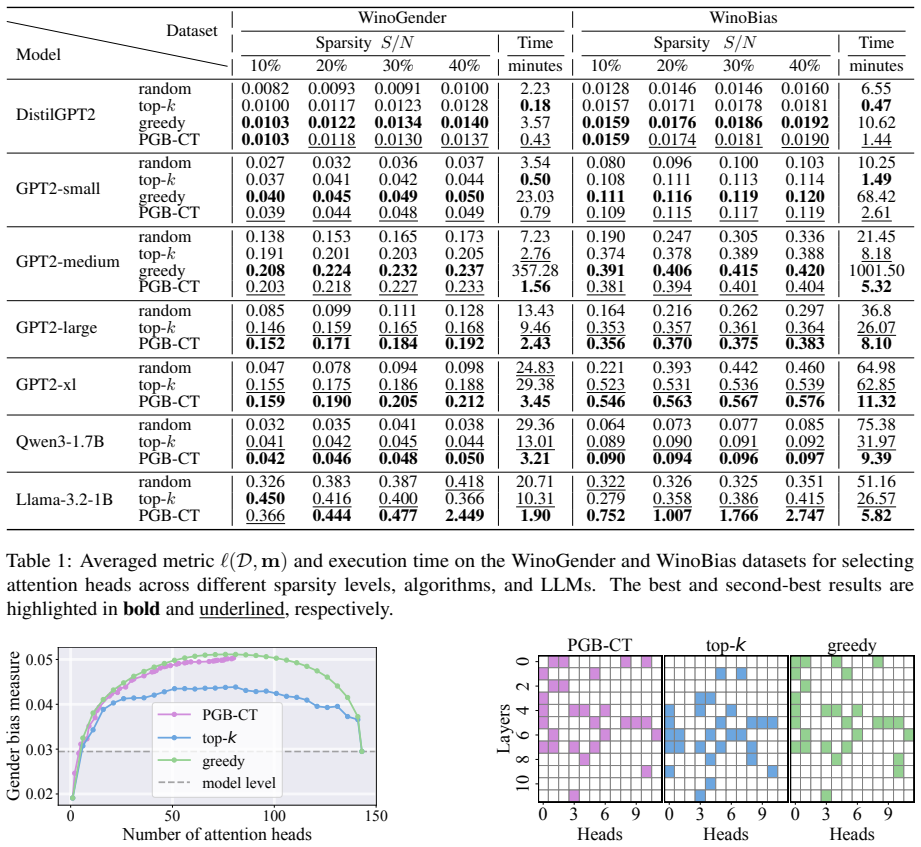
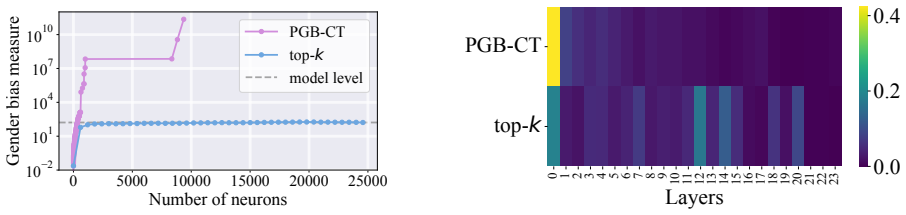
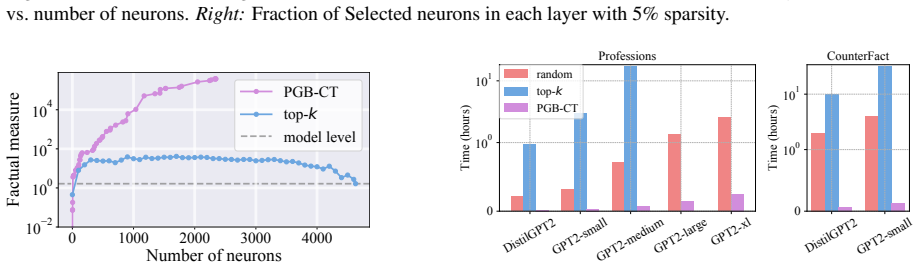
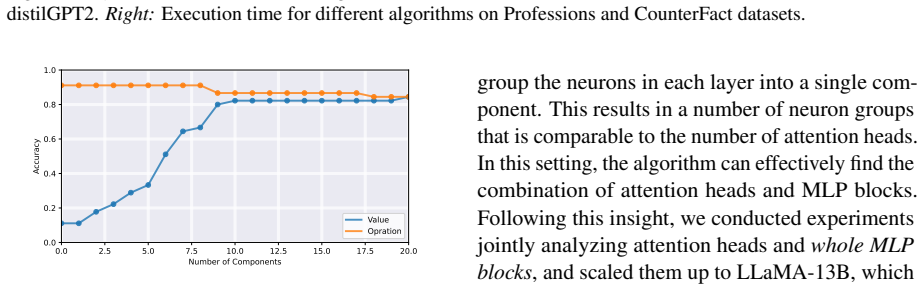
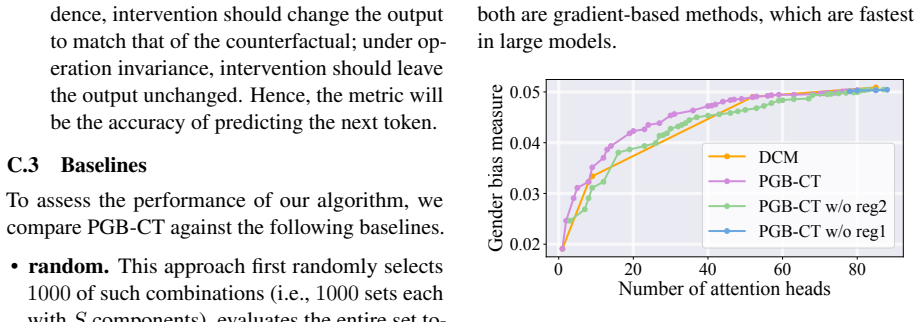
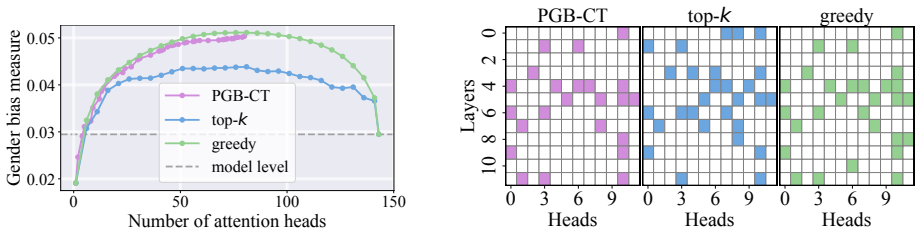
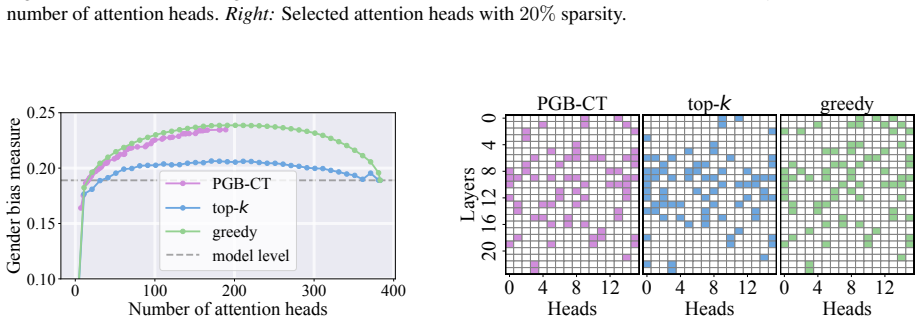
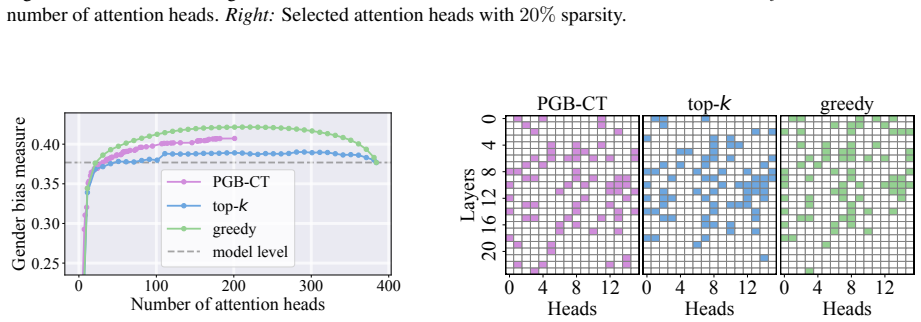
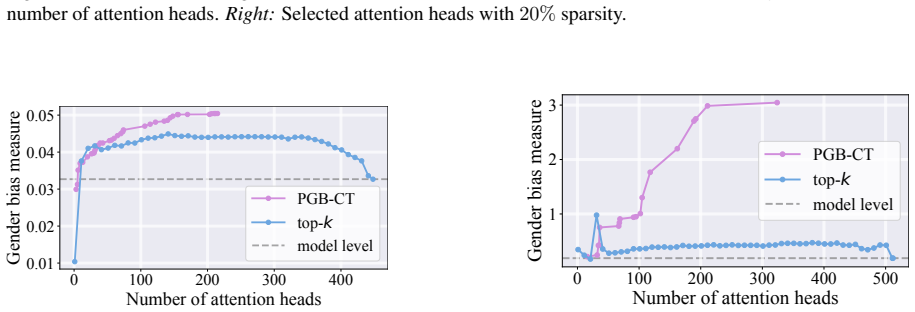
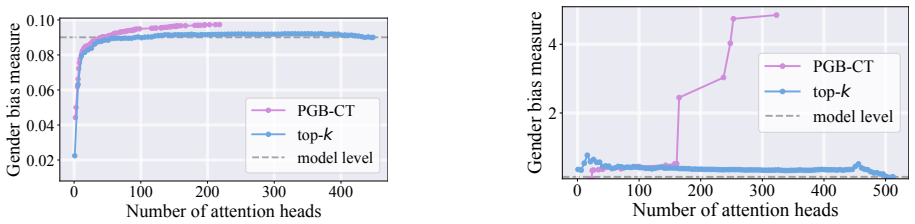
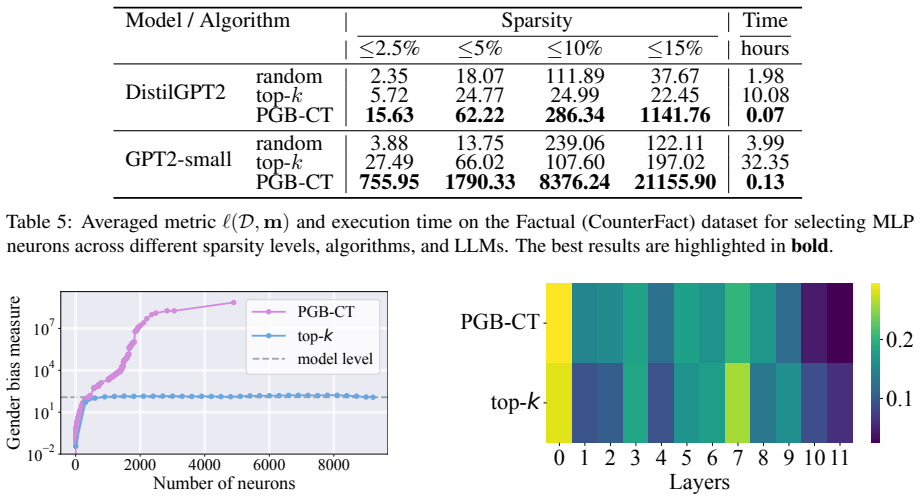
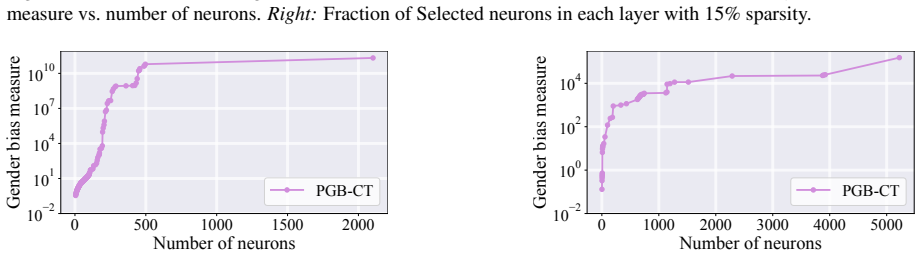
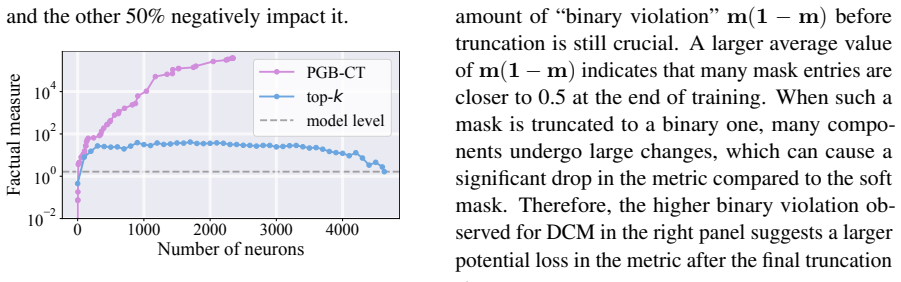
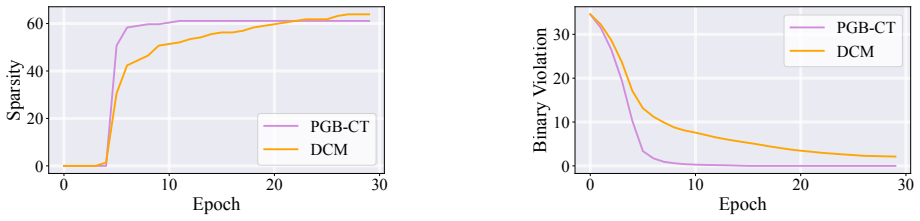
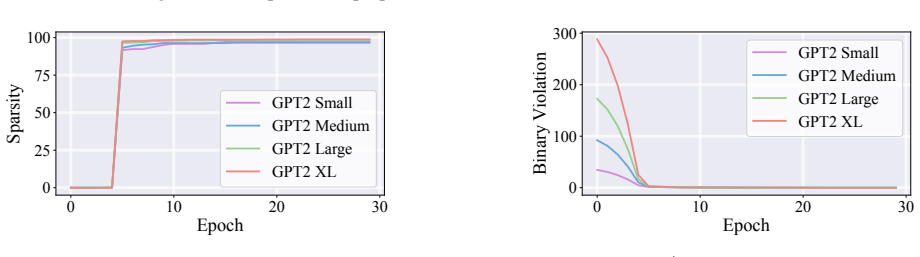
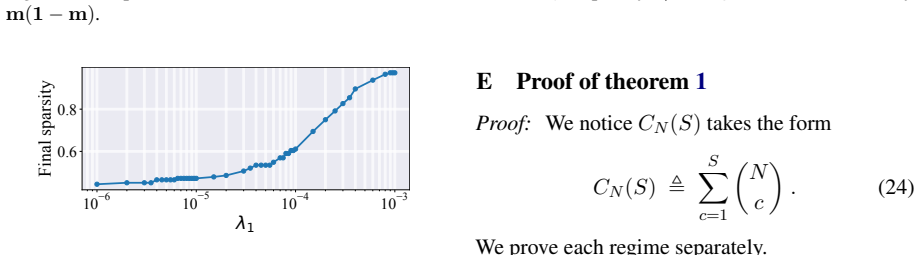
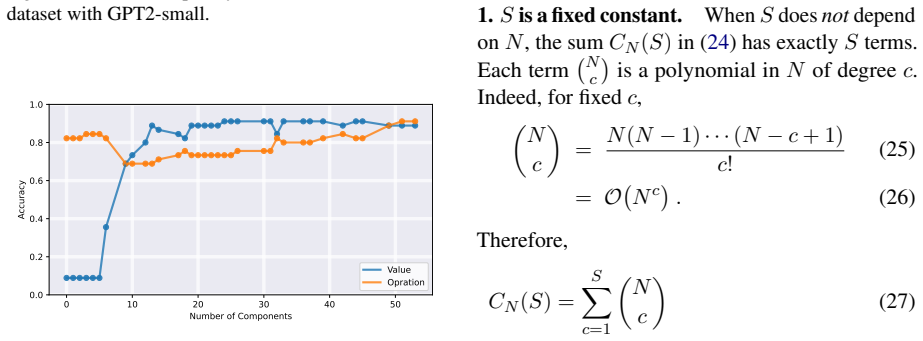
read the original abstract
Causal tracing systematically intervenes on a large language model's (LLM's) internal representations to uncover and quantify the causal pathways linking specific inputs or computations to specific metrics of interest, quantifying the LLM's behavior. Building on previous single-component or single-layer studies, this paper presents a unified framework for causally tracing multiple components simultaneously. This framework systematically identifies the subsets of components (e.g., attention heads and multi-layer perceptron neurons) most critical to a desired target performance metric (e.g., accuracy and fairness). This is achieved by incorporating flexible interventions applied to a wide range of desired metrics. To address the combinatorial complexity of the multi-component problem, an efficient algorithm is designed that leverages soft interventions and a carefully designed metric transformation, converting the combinatorial search problem into a continuous one that can be solved efficiently under proper constraints, thereby generating proper binary decisions for selecting components. Experimental results demonstrate that the proposed method efficiently identifies subsets of the model's components that have a high impact on the target metric, outperforming existing baseline approaches. Our code is available at https://github.com/ZiruiYan/multi-component-causal-tracing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a unified framework for multi-component causal tracing in LLMs. It extends single-component tracing by identifying subsets of components (attention heads, MLP neurons) most critical to target metrics (accuracy, fairness) via flexible interventions. To handle combinatorial complexity, it introduces an efficient algorithm using soft interventions and a metric transformation that converts the discrete search into a continuous optimization problem solved under constraints to yield binary component selections. Experiments claim the method efficiently finds high-impact subsets and outperforms baselines, with code released.
Significance. If the soft-intervention relaxation and metric transformation provably recover the same high-impact subsets as exhaustive hard interventions, the framework would offer a scalable extension of causal tracing to multi-component settings, enabling more systematic interpretability and editing of LLMs. Reproducibility via the linked code repository is a positive factor.
major comments (3)
- [Abstract; Method (algorithm description)] Abstract and Method section: the central efficiency claim rests on the assertion that soft interventions plus the unspecified metric transformation, 'under proper constraints,' produce binary decisions whose causal impact matches exhaustive hard interventions over the original 2^n combinatorial objective. No derivation is supplied showing that the fixed point of the relaxed objective coincides with the argmax of the discrete problem; any mismatch would render the reported subsets artifacts of the surrogate rather than true causal drivers.
- [Experiments] Experiments section: the claim of outperformance over baselines is presented without reported validation that the continuous relaxation recovers the same component subsets as brute-force hard interventions on small-scale cases (e.g., models with <10 components where 2^n enumeration is feasible). This leaves open whether the efficiency gain comes at the cost of correctness.
- [Method] Method section: the 'carefully designed metric transformation' is described only at a high level; without an explicit statement of the transformation (or its fixed-point properties), it is impossible to assess whether it introduces bias or loses information from the original combinatorial structure, as required by the weakest assumption in the reader's report.
minor comments (2)
- [Abstract] The abstract refers to 'existing baseline approaches' without naming them; a brief enumeration in the introduction or related-work section would improve clarity.
- [Method] Notation for the soft-intervention parameters and the transformed metric should be introduced with explicit symbols rather than descriptive phrases to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below and will incorporate the requested clarifications and validations into a revised manuscript.
read point-by-point responses
-
Referee: [Abstract; Method (algorithm description)] Abstract and Method section: the central efficiency claim rests on the assertion that soft interventions plus the unspecified metric transformation, 'under proper constraints,' produce binary decisions whose causal impact matches exhaustive hard interventions over the original 2^n combinatorial objective. No derivation is supplied showing that the fixed point of the relaxed objective coincides with the argmax of the discrete problem; any mismatch would render the reported subsets artifacts of the surrogate rather than true causal drivers.
Authors: We agree that the manuscript would be strengthened by an explicit derivation establishing equivalence between the relaxed continuous problem and the original discrete objective. In the revision we will add a dedicated subsection in the Method section that derives the fixed-point properties of the metric transformation under the stated constraints and proves that the binary solutions recovered by the continuous optimizer coincide with the argmax of the combinatorial objective. revision: yes
-
Referee: [Experiments] Experiments section: the claim of outperformance over baselines is presented without reported validation that the continuous relaxation recovers the same component subsets as brute-force hard interventions on small-scale cases (e.g., models with <10 components where 2^n enumeration is feasible). This leaves open whether the efficiency gain comes at the cost of correctness.
Authors: We concur that empirical verification on enumerable small instances is necessary to confirm correctness of the relaxation. The revised manuscript will include new experiments that enumerate all 2^n subsets for models with fewer than 10 components, directly compare the subsets recovered by the continuous method against the exhaustive optimum, and report agreement rates. revision: yes
-
Referee: [Method] Method section: the 'carefully designed metric transformation' is described only at a high level; without an explicit statement of the transformation (or its fixed-point properties), it is impossible to assess whether it introduces bias or loses information from the original combinatorial structure, as required by the weakest assumption in the reader's report.
Authors: The current description intentionally keeps the transformation at a high level for readability, but we recognize that an explicit formulation is required for rigorous evaluation. The revision will state the precise functional form of the metric transformation, derive its fixed-point properties, and show how the transformation preserves the ranking of component subsets from the original discrete objective. revision: yes
Circularity Check
No circularity: algorithmic relaxation presented as independent contribution
full rationale
The paper describes a new algorithmic framework that converts a combinatorial multi-component selection problem into a continuous optimization via soft interventions and a metric transformation, solved under constraints to yield binary decisions. No equations, fitted parameters, or self-citations are quoted in the provided text that would make any claimed 'high-impact subset' equivalent by construction to the input metric values or prior results. The central claim rests on the design of the relaxation and empirical outperformance versus baselines, which is an independent algorithmic assertion rather than a definitional or self-referential reduction. This is the normal case of a self-contained method paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Investigating gender bias in language models using causal mediation analysis , author=. Proc. Advances in Neural Information Processing Systems , year=
-
[2]
Locating and editing factual associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and editing factual associations in. 2022 , address=
2022
-
[3]
Meng, Kevin and Sharma, Arnab Sen and Andonian, Alex and Belinkov, Yonatan and Bau, David , title =. Proc. International Conference on Learning Representations , year = 2023, address=
2023
-
[4]
knowledge editing in language models , author=
Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models , author=. Proc. Advances in Neural Information Processing Systems , year=
-
[5]
Transformer Feed-Forward Layers Are Key-Value Memories , author=. Proc. Conference on Empirical Methods in Natural Language Processing. 2021 , month =. doi:10.18653/v1/2021.emnlp-main.446
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[6]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space , author=. Proc. Conference on Empirical Methods in Natural Language Processing. doi:10.18653/v1/2022.emnlp-main.3
-
[7]
2019 , howpublished=
Language Models are Unsupervised Multitask Learners , author=. 2019 , howpublished=
2019
-
[8]
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Cl. 2019 , url =. 1910.03771 , archivePrefix=
Pith/arXiv arXiv 2019
-
[9]
Sanh, Victor and Debut, L and Chaumond, J and Wolf, T , eprint=
-
[10]
Gender bias in neural natural language processing , author=. Logic, language, and security: Essays dedicated to Andre Scedrov on the occasion of his 65th birthday , pages=. 2020 , publisher=. doi:https://doi.org/10.1007/978-3-030-62077-6_14 , address=
-
[11]
Man is to computer programmer as woman is to homemaker? debiasing word embeddings , author=. Proc. Advances in Neural Information Processing Systems , year=
-
[12]
Gender bias in coreference resolution: Evaluation and debiasing methods , author=. Proc. Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. doi:10.18653/v1/N18-2003
-
[13]
Gender bias in coreference resolution , author=. Proc. Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. doi:10.18653/v1/N18-2002
-
[14]
What Does BERT Look at? An Analysis of BERT `s Attention
Clark, Kevin and Khandelwal, Urvashi and Levy, Omer and Manning, Christopher D. What Does BERT Look at? An Analysis of BERT `s Attention. Proc. ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. 2019
2019
-
[15]
Locating and mitigating gender bias in large language models , author=. Proc. International Conference on Intelligent Computing , year=
-
[16]
Can Editing
Chen, Canyu and Huang, Baixiang and Li, Zekun and Chen, Zhaorun and Lai, Shiyang and Xu, Xiongxiao and Gu, Jia-Chen and Gu, Jindong and Yao, Huaxiu and Xiao, Chaowei and Yan, Xifeng and Wang, William Yang and Torr, Philip and Song, Dawn and Shu, Kai , booktitle =. Can Editing. 2026 , doi =
2026
-
[17]
Causal mediation analysis for interpreting neural
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Sakenis, Simas and Huang, Jason and Singer, Yaron and Shieber, Stuart , eprint=. Causal mediation analysis for interpreting neural
-
[18]
Probabilistic and causal inference: the works of Judea Pearl , pages=
Direct and indirect effects , author=. Probabilistic and causal inference: the works of Judea Pearl , pages=. 2022 , publisher=
2022
-
[19]
Prompting large language model for machine translation: A case study , author=. Proc. International Conference on Machine Learning , year=
-
[20]
Nature Medicine , volume=
Adapted large language models can outperform medical experts in clinical text summarization , author=. Nature Medicine , volume=. 2024 , address=
2024
-
[21]
ACM Transactions on Software Engineering and Methodology , volume=
Self-planning code generation with large language models , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2024 , url=
2024
-
[22]
Science China Information Sciences , volume=
The rise and potential of large language model based agents: A survey , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[23]
Societal biases in language generation: Progress and challenges , author=. Proc. Annual Meeting of the Association for Computational Linguistics and International Joint Conference on Natural Language Processing. doi:10.18653/v1/2021.acl-long.330
-
[24]
Nature Machine Intelligence , volume=
Factuality challenges in the era of large language models and opportunities for fact-checking , author=. Nature Machine Intelligence , volume=. 2024 , publisher=
2024
-
[25]
Align is not Enough: Multimodal Universal Jailbreak Attack against Multimodal Large Language Models , year=
Wang, Youze and Hu, Wenbo and Dong, Yinpeng and Liu, Jing and Zhang, Hanwang and Hong, Richang , journal=. Align is not Enough: Multimodal Universal Jailbreak Attack against Multimodal Large Language Models , year=
-
[26]
Cunningham, Hoagy and Ewart, Aidan and Riggs, Logan and Huben, Robert and Sharkey, Lee , title =. Proc. International Conference on Learning Representations , year = 2024, month=
2024
-
[27]
2023 , month =
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , month =
2023
-
[28]
A primer on the inner workings of transformer-based language models , author=. 2024 , url=. 2405.00208 , archivePrefix=
arXiv 2024
-
[29]
2021 , url=
A mathematical framework for transformer circuits , author=. 2021 , url=
2021
-
[30]
In-context learning and induction heads , author=. 2022 , url=. 2209.11895 , archivePrefix=
Pith/arXiv arXiv 2022
-
[31]
From understanding to utilization: A survey on explainability for large language models , author=. 2024 , url =. 2401.12874 , archivePrefix=
arXiv 2024
-
[32]
A toy model of universality: Reverse engineering how networks learn group operations , author=. Proc. International Conference on Machine Learning , year=
-
[33]
Language models as knowledge bases? , author=. Proc. Conference on Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing , year=. doi:10.18653/v1/D19-1250
-
[34]
Inference-time intervention: Eliciting truthful answers from a language model , author=. Proc. Advances in Neural Information Processing Systems , year=
-
[35]
Interpretability in the wild: a circuit for indirect object identification in
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , booktitle=. Interpretability in the wild: a circuit for indirect object identification in. 2023 , address=
2023
-
[36]
Integrated Directional Gradients: Feature Interaction Attribution for Neural NLP Models
Sikdar, Sandipan and Bhattacharya, Parantapa and Heese, Kieran. Integrated Directional Gradients: Feature Interaction Attribution for Neural NLP Models. Proc. Annual Meeting of the Association for Computational Linguistics and International Joint Conference on Natural Language Processing. 2021. doi:10.18653/v1/2021.acl-long.71
-
[37]
Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection
Chen, Hanjie and Zheng, Guangtao and Ji, Yangfeng. Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection. Proc. Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.494
-
[38]
Modarressi, Ali and Fayyaz, Mohsen and Yaghoobzadeh, Yadollah and Pilehvar, Mohammad Taher. G lob E nc: Quantifying Global Token Attribution by Incorporating the Whole Encoder Layer in Transformers. Proc. Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.19
-
[39]
Discovering variable binding circuitry with desiderata , author=. Proc. International Conference on Machine Learning Workshop on Challenges in Deployable Generative AI , year=
-
[40]
Fine-tuning enhances existing mechanisms: A case study on entity tracking , author=. Proc. International Conference on Learning Representations , year=
-
[41]
Towards best practices of activation patching in language models: Metrics and methods , author=. Proc. International Conference on Learning Representations , month =. 2024 , address =
2024
-
[42]
Neural Natural Language Inference Models Partially Embed Theories of Lexical Entailment and Negation
Geiger, Atticus and Richardson, Kyle and Potts, Christopher. Neural Natural Language Inference Models Partially Embed Theories of Lexical Entailment and Negation. Proc. BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP. 2020. doi:10.18653/v1/2020.blackboxnlp-1.16
-
[43]
Inducing causal structure for interpretable neural networks , author=. Proc. International Conference on Machine Learning , year=
-
[44]
Causal abstractions of neural networks , author=. Proc. Advances in Neural Information Processing Systems , year=
-
[45]
Harvard Journal of Law & Technology , volume=
Counterfactual explanations without opening the black box: Automated decisions and the GDPR , author=. Harvard Journal of Law & Technology , volume=
-
[46]
ACM Computing Surveys , volume=
A survey of algorithmic recourse: contrastive explanations and consequential recommendations , author=. ACM Computing Surveys , volume=
-
[47]
Decomposing and editing predictions by modeling model computation , author=. Proc. International Conference on Machine Learning , year=
-
[48]
Attribution patching outperforms automated circuit discovery , author=. Proc. Advances in Neural Information Processing Systems Workshop on Attributing Model Behavior at Scale , year=
-
[49]
Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms , author=. Proc. Conference on Language Modeling , year=
-
[50]
Quantifying Context Mixing in Transformers , author=. Proc. Conference of the European Chapter of the Association for Computational Linguistics , month=. 2023 , address=
2023
-
[51]
Towards automated circuit discovery for mechanistic interpretability , author=. Proc. Advances in Neural Information Processing Systems , year=
-
[52]
Interpretability at scale: Identifying causal mechanisms in alpaca , author=. Proc. Advances in Neural Information Processing Systems , year=
-
[53]
Qwen3 technical report , author =. 2025 , url =. 2505.09388 , archivePrefix=
Pith/arXiv arXiv 2025
-
[54]
Llama 3.2: Revolutionizing edge
Llama Team, AI @ Meta , year=. Llama 3.2: Revolutionizing edge
-
[55]
Multi-Level Explanations for Generative Language Models , author=. Proc. Annual Meeting of the Association for Computational Linguistics , year=
-
[56]
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. 2302.13971 , archivePrefix=
-
[57]
, booktitle=
Louizos, Christos and Welling, Max and Kingma, Diederik P. , booktitle=. Learning Sparse Neural Networks through. 2018 , url=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.