AI Assistance for Discretionary Work: Increasing Feedback Provision in Higher Education
Pith reviewed 2026-06-28 08:52 UTC · model grok-4.3
The pith
AI-generated feedback drafts increase the share of student submissions receiving comments by 10.8 percentage points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
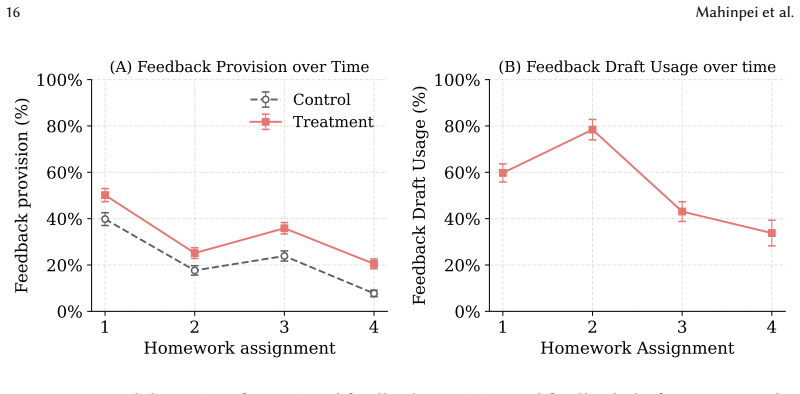
In the randomized experiment, student submissions assigned to the AI-draft condition received feedback 10.8 percentage points more often and the feedback was 39.8 characters longer on average, with no reduction in student-perceived usefulness or time spent per character written; the authors conclude that the drafts served as scaffolds that reduced initiation costs rather than replacing human work.
What carries the argument
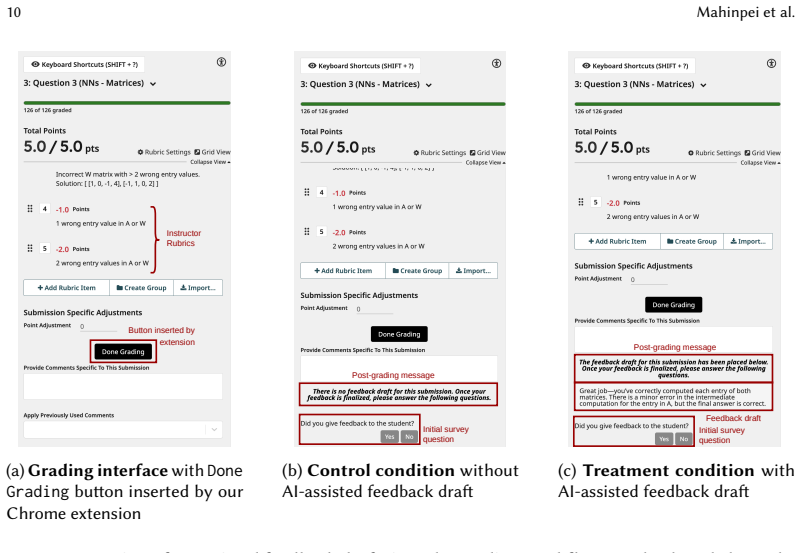
AI-generated draft feedback provided to TAs after they grade, which TAs may adopt, edit, or discard at their discretion.
If this is right
- AI assistance can raise completion rates for discretionary tasks without reducing the quality of the final output.
- Human users retain control because they decide whether and how to use the drafts.
- The increase occurs mainly through more frequent initiation of the task rather than through faster completion of each instance.
- The same pattern may apply to other optional but beneficial professional activities where people intend to act but often do not.
Where Pith is reading between the lines
- Similar draft-based assistance could be tested in settings outside education such as code review or performance evaluations where feedback is discretionary.
- Longer-term studies could check whether repeated exposure to drafts changes TAs' own writing habits or reduces the need for assistance over time.
- The design leaves open whether the benefit depends on the quality or style of the specific AI model used to generate the drafts.
Load-bearing premise
The measured rise in feedback occurs because the drafts lower the cost of starting the writing task rather than because of unmeasured differences between the TAs in the two groups or because of features unique to the machine-learning course.
What would settle it
A replication in a different course or with a different AI model that produces no statistically significant increase in feedback rates or lengths would indicate that the effect is not generalizable beyond the tested setting.
Figures

read the original abstract
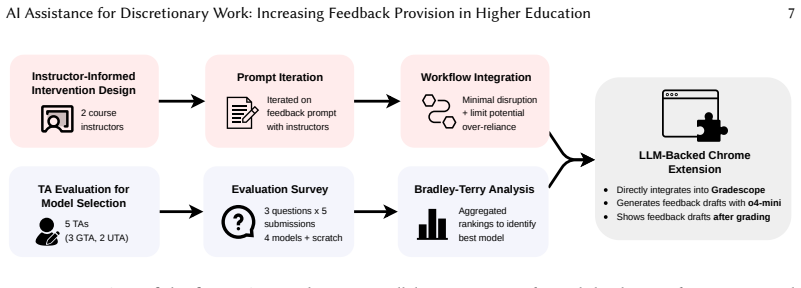
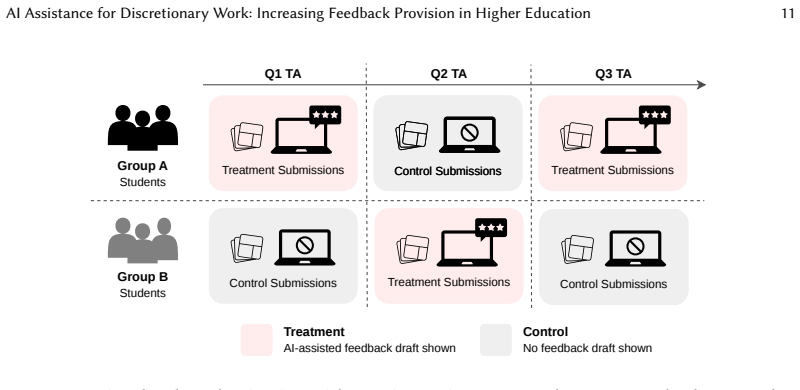
AI systems increasingly shape human workflows by generating intermediate artifacts that users can adopt, revise, or ignore. While prior work has shown that AI assistance can improve the efficiency and accuracy of required tasks, less is known about whether it can increase participation in discretionary but beneficial work that users often intend to perform but frequently skip. We study this question in the context of personalized feedback provision in higher education, a pedagogically valuable but often optional practice. We conduct a mixed-methods study combining a randomized field experiment and qualitative interviews in a 300-level machine learning course with n=11 teaching assistants (TAs) and n=88 students. Student submissions were randomly assigned to either (1) a treatment condition where TAs received AI-assisted feedback drafts after grading or (2) a control condition without drafts. TAs remained fully in control and could use, edit, or ignore drafts at their discretion. We find that AI-assisted feedback significantly increases feedback provision (+10.8 percentage points, SE=1.1, p<0.001) and feedback length (+39.8 chars, SE=3.45, p<0.001) without negatively affecting student usefulness ratings or reducing time per character. Qualitative findings suggest that AI-assisted drafts function as editable scaffolds that lower barriers to initiating feedback rather than reducing overall effort. Our findings highlight AI's promise for discretionary but beneficial tasks: increasing work that might otherwise go undone while preserving human control over final outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a mixed-methods study (randomized field experiment plus qualitative interviews) in a 300-level machine learning course (n=11 TAs, n=88 students). Student submissions were randomly assigned to a treatment condition in which TAs received AI-generated feedback drafts after grading or to a control condition without drafts; TAs retained full discretion to use, edit, or ignore the drafts. The central empirical claims are that the AI drafts increase the probability of feedback provision by 10.8 percentage points (SE=1.1, p<0.001) and increase feedback length by 39.8 characters (SE=3.45, p<0.001), with no detectable negative effects on student-rated usefulness or time per character. Qualitative interviews interpret the drafts as editable scaffolds that lower initiation costs rather than substitute for effort.
Significance. If the reported effects hold, the work supplies field-experimental evidence that AI assistance can raise completion rates for discretionary but pedagogically valuable tasks while preserving human control over final outputs. The submission-level randomization, pre-registered-style reporting of effect sizes with SEs and p-values, and alignment between quantitative and qualitative results are notable strengths that support causal attribution to the availability of drafts. The findings are relevant to workflow design in education and other domains where beneficial optional work is frequently omitted.
minor comments (2)
- [Methods] The description of the randomization procedure (submission-level assignment) is clear, but a brief statement confirming that the randomization was performed after grading but before draft generation would eliminate any residual ambiguity about timing.
- [Qualitative Findings] The qualitative section would benefit from one additional sentence explicitly linking the interview themes back to the quantitative outcome measures (e.g., initiation barrier vs. effort reduction).
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, accurate summary of the study design and findings, and recommendation to accept. We appreciate the recognition of the submission-level randomization, pre-registered-style reporting, and alignment between quantitative and qualitative evidence.
Circularity Check
No circularity: empirical RCT results with no derivation chain
full rationale
The paper reports causal effects from a randomized field experiment (student submissions assigned to AI-draft vs. control) and qualitative interviews. Central claims are direct measurements (+10.8 pp feedback provision, +39.8 chars length) against an external control group, with randomization balancing confounders. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The derivation chain is absent; results are externally falsifiable via the experiment design itself.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Random assignment produces comparable treatment and control groups on average.
- domain assumption Feedback provision and length are measured consistently across conditions.
Reference graph
Works this paper leans on
-
[1]
Faria Ahmed, Nabila Bouali, and Marion Gerhold. 2024. Teaching Assistants as Assessors: An Experience-Based Narrative. InProceedings of the 16th International Conference on Computer Supported Education (CSEDU). SCITEPRESS – Science and Technology Publications, 315–323
2024
-
[2]
2014.The Invisible Work of Nurses: Hospitals, Organisation and Healthcare(1 ed.)
Davina Allen. 2014.The Invisible Work of Nurses: Hospitals, Organisation and Healthcare(1 ed.). Routledge. https: //doi.org/10.4324/9781315857794
-
[3]
Saleema Amershi, Maya Cakmak, William Bradley Knox, and Todd Kulesza. 2014. Power to the people: The role of humans in interactive machine learning.AI magazine35, 4 (2014), 105–120
2014
-
[4]
Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz
Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N. Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz. 2019. Guidelines for Human-AI Interaction. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland Uk) (CHI ’19). Associa...
-
[5]
John W. Budd. 2016.2. The Eye Sees What the Mind Knows: The Conceptual Foundations of Invisible Work. University of California Press, Berkeley, 28–46. https://doi.org/doi:10.1525/9780520961630-004
-
[6]
Julia Cambre, Scott Klemmer, and Chinmay Kulkarni. 2018. Juxtapeer: Comparative Peer Review Yields Higher Quality Feedback and Promotes Deeper Reflection. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems(Montreal QC, Canada)(CHI ’18). Association for Computing Machinery, New York, NY, USA, 1–13. https://doi.org/10.1145/317357...
-
[7]
Yulu Cui, Weimiao He, Xingke Du, Manlin Zeng, and Dongping Liu. 2025. The Impact of AI Writing Assistants on Academic Writing Performance:.International Journal of Distance Education Technologies23, 1 (2025). https: //doi.org/10.4018/IJDET.391326
-
[8]
Arlene Kaplan Daniels. 1987. Invisible Work.Social Problems34, 5 (1987), 403–415. https://doi.org/10.2307/800538
-
[9]
Marjorie L. DeVault. 2014. Mapping Invisible Work: Conceptual Tools for Social Justice Projects.Sociological Forum29, 4 (2014), 775–790. http://www.jstor.org/stable/43654145
arXiv 2014
-
[10]
Susan R. Doe, Katherine J. Gingerich, and Tara L. Richards. 2013. An Evaluation of Grading and Instructional Feedback Skills of Graduate Teaching Assistants in Introductory Psychology.Teaching of Psychology40, 4 (2013), 274–280. https://doi.org/10.1177/0098628313501039
-
[11]
Mica R Endsley. 2018. Automation and situation awareness. InAutomation and human performance. CRC Press, 163–181
2018
-
[12]
Juan Escalante, Austin Pack, and Alex Barrett. 2023. AI-generated feedback on writing: insights into efficacy and ENL student preference.International Journal of Educational Technology in Higher Education20, 1 (2023), 57. https: //doi.org/10.1186/s41239-023-00425-2
-
[13]
Emily Faulconer, John Griffith, and Amy Gruss. 2022. The impact of positive feedback on student outcomes and perceptions.Assessment & Evaluation in Higher Education47, 2 (2022), 259–268. https://doi.org/10.1080/02602938. 2021.1910140
-
[14]
Damien S. Fleur, Max Marshall, Miguel Pieters, Natasa Brouwer, Gerrit Oomens, Angelos Konstantinidis, Koos Winnips, Sylvia Moes, Wouter van den Bos, Bert Bredeweg, and Erwin A. van Vliet. 2023. IguideME: Supporting Self-Regulated Learning and Academic Achievement with Personalized Peer-Comparison Feedback in Higher Education.Journal of Learning Analytics1...
-
[15]
Anupriya Sharma Ghai, Vandna Rawat, Vishan Kumar Gupta, and Kapil Ghai. 2024. Artificial Intelligence in System and Software Engineering for Auto Code Generation. In2024 International Conference on Electrical Electronics and Computing Technologies (ICEECT), Vol. 1. 1–5. https://doi.org/10.1109/ICEECT61758.2024.10738945
-
[16]
Evelyn Nakano Glenn. 2000. Creating a Caring Society.Contemporary Sociology29, 1 (2000), 84–94. https://doi.org/10. 2307/2654934
2000
-
[17]
Jonathan Grudin. 1988. Why CSCW applications fail: problems in the design and evaluationof organizational interfaces. InProceedings of the 1988 ACM Conference on Computer-Supported Cooperative Work(Portland, Oregon, USA)(CSCW ’88). Association for Computing Machinery, New York, NY, USA, 85–93. https://doi.org/10.1145/62266.62273
-
[18]
Ashish Gurung, Jionghao Lin, Jordan Gutterman, Danielle R Thomas, Alex Houk, Shivang Gupta, Emma Brunskill, Lee Branstetter, Vincent Aleven, and Kenneth Koedinger. 2025. Human Tutoring Improves the Impact of AI Tutor Use on Learning Outcomes. InArtificial Intelligence in Education: 26th International Conference, AIED 2025, Palermo, Italy, July 22–26, 2025...
-
[19]
John Hattie and Helen Timperley. 2007. The Power of Feedback.Review of Educational Research77, 1 (2007), 81–112. https://doi.org/10.3102/003465430298487
-
[20]
Erin Hatton. 2017. Mechanisms of Invisibility: Rethinking the Concept of Invisible Work.Work, Employment and Society31, 2 (2017), 336–351. 22 Mahinpei et al
2017
-
[21]
Michael Henderson, Tracii Ryan, and Michael Phillips. 2019. The challenges of feedback in higher education.Assessment & Evaluation in Higher Education44, 8 (2019), 1237–1252. https://doi.org/10.1080/02602938.2019.1599815
-
[22]
Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Pittsburgh, Pennsylvania, USA)(CHI ’99). Association for Computing Machinery, New York, NY, USA, 159–166. https://doi.org/10.1145/302979.303030
-
[23]
Lucas Jasper Jacobsen and Kira Elena Weber. 2025. The Promises and Pitfalls of Large Language Models as Feedback Providers: A Study of Prompt Engineering and the Quality of AI-Driven Feedback.AI6, 2 (2025). https://doi.org/10. 3390/ai6020035
2025
-
[24]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of Hallucination in Natural Language Generation.ACM Comput. Surv.55, 12, Article 248 (March 2023), 38 pages. https://doi.org/10.1145/3571730
-
[25]
Qinjin Jia, Jialin Cui, Ruijie Xi, Chengyuan Liu, Parvez Rashid, Ruochi Li, and Edward Gehringer. 2024. On Assessing the Faithfulness of LLM-Generated Feedback on Student Assignments. InProceedings of the 17th International Conference on Educational Data Mining. International Educational Data Mining Society, 491–499. https://doi.org/10.5281/zenodo. 12729868
-
[26]
Briese, Marius Jacobs, Niclas Dern, Niels Glodny, Simon Jacobs, and Samuel Leßmann
Annette Kinder, Fiona J. Briese, Marius Jacobs, Niclas Dern, Niels Glodny, Simon Jacobs, and Samuel Leßmann. 2025. Effects of adaptive feedback generated by a large language model: A case study in teacher education.Computers and Education: Artificial Intelligence8 (2025), 100349. https://doi.org/10.1016/j.caeai.2024.100349
-
[27]
Yong Ming Kow and Waikuen Cheng. 2018. Complimenting Invisible Work: Identifying Hidden Employee Contributions through a Voluntary, Positive, and Open Work Review System.Proc. ACM Hum.-Comput. Interact.2, CSCW, Article 96 (Nov. 2018), 22 pages. https://doi.org/10.1145/3274365
-
[28]
Robert E. Kraut, Paul Resnick, Sara Kiesler, Moira Burke, Yan Chen, Niki Kittur, Joseph Konstan, Yuqing Ren, and John Riedl. 2012.Building Successful Online Communities: Evidence-Based Social Design. The MIT Press. https: //doi.org/10.7551/mitpress/8472.001.0001
-
[29]
John D Lee and Katrina A See. 2004. Trust in automation: Designing for appropriate reliance.Human factors46, 1 (2004), 50–80
2004
-
[30]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013/
2004
-
[31]
Xinyi Lu, Kexin Phyllis Ju, Mitchell Dudley, Larissa Sano, and Xu Wang. 2026. AI-Mediated Feedback Improves Student Revisions: A Randomized Trial with FeedbackWriter in a Large Undergraduate Course. arXiv:2602.16820 [cs.HC] https://arxiv.org/abs/2602.16820
arXiv 2026
-
[32]
Romina Mahinpei, Sofiia Druchyna, and Xinran Bi. 2026. CNPE: A Framework of Challenges & Needs in Proof Education. InProceedings of the 57th ACM Technical Symposium on Computer Science Education V.2(USA). Association for Computing Machinery, New York, NY, USA, 1435–1436. https://doi.org/10.1145/3770761.3777193
-
[33]
Romina Mahinpei, Sofiia Druchyna, and Manoel Horta Ribeiro. 2026. When LLMs Help – and Hurt – Teaching Assistants in Proof-Based Courses. arXiv:2602.23635 [cs.HC] https://arxiv.org/abs/2602.23635
arXiv 2026
-
[34]
Luke Mandouit and John Hattie. 2023. Revisiting “The Power of Feedback” from the perspective of the learner.Learning and Instruction84 (2023), 101718. https://doi.org/10.1016/j.learninstruc.2022.101718
-
[35]
John Meluso, Amanda Casari, Katie McLaughlin, and Milo Z Trujillo. 2025. Invisible Labor in Open Source Software Ecosystems.Proc. ACM Hum.-Comput. Interact.9, 7, Article CSCW236 (Oct. 2025), 32 pages. https://doi.org/10.1145/ 3757417
2025
-
[36]
Liebenow, Marlene Steinbach, Andrea Horbach, and Johanna Fleckenstein
Jennifer Meyer, Thorben Jansen, Ronja Schiller, Lucas W. Liebenow, Marlene Steinbach, Andrea Horbach, and Johanna Fleckenstein. 2024. Using LLMs to bring evidence-based feedback into the classroom: AI-generated feedback increases secondary students’ text revision, motivation, and positive emotions.Computers and Education: Artificial Intelligence6 (2024), ...
-
[37]
Salvatore Milano, Joshua A. McGrane, and Sabina Leonelli. 2023. Large language models challenge the future of higher education.Nature Machine Intelligence5 (2023), 333–334. https://doi.org/10.1038/s42256-023-00644-2
-
[38]
Susanne Narciss. 2008. Feedback Strategies for Interactive Learning Tasks. InHandbook of Research on Educational Communications and Technology(3rd ed.), J. M. Spector, M. D. Merrill, J. J. G. van Merrienboer, and M. P. Driscoll (Eds.). Taylor & Francis/Routledge, 125–144
2008
-
[39]
Susanne Narciss, Sergey Sosnovsky, Lenka Schnaubert, Eric Andrès, Anja Eichelmann, George Goguadze, and Erica Melis. 2014. Exploring feedback and student characteristics relevant for personalizing feedback strategies.Computers & Education71 (2014), 56–76. https://doi.org/10.1016/j.compedu.2013.09.011
-
[40]
Nicol and Debra Macfarlane-Dick
David J. Nicol and Debra Macfarlane-Dick. 2006. Formative assessment and self-regulated learning: a model and seven principles of good feedback practice.Studies in Higher Education31, 2 (2006), 199–218. https://doi.org/10.1080/ 03075070600572090 AI Assistance for Discretionary Work: Increasing Feedback Provision in Higher Education 23
2006
-
[41]
Shakked Noy and Whitney Zhang. 2023. Experimental evidence on the productivity effects of generative artificial intelligence.Science381, 6654 (2023), 187–192. https://doi.org/10.1126/science.adh2586
-
[42]
1988.Organizational citizenship behavior: The good soldier syndrome.Lexington books/DC heath and com
Dennis W Organ. 1988.Organizational citizenship behavior: The good soldier syndrome.Lexington books/DC heath and com
1988
-
[43]
Kritish Pahi, Shiplu Hawlader, Eric Hicks, Alina Zaman, and Vinhthuy Phan. 2024. Enhancing active learning through collaboration between human teachers and generative AI.Computers and Education Open6 (2024), 100183. https://doi.org/10.1016/j.caeo.2024.100183
-
[44]
R. Parasuraman, T.B. Sheridan, and C.D. Wickens. 2000. A model for types and levels of human interaction with automation.IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans30, 3 (2000), 286–297. https://doi.org/10.1109/3468.844354
-
[45]
Catherine Paterson, Nathan Paterson, William Jackson, and Fiona Work. 2020. What are students’ needs and preferences for academic feedback in higher education? A systematic review.Nurse Education Today85 (2020), 104236. https: //doi.org/10.1016/j.nedt.2019.104236
-
[46]
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot. arXiv:2302.06590 [cs.SE] https://arxiv.org/abs/2302.06590
Pith/arXiv arXiv 2023
-
[47]
Kjeld Schmidt and Liam Bannon. 1992. Taking CSCW seriously: Supporting articulation work.Computer supported cooperative work (CSCW)1, 1 (1992), 7–40. https://doi.org/10.1007/BF00752449
-
[48]
2012.Digital Labor: The Internet As Playground and Factory
Trebor Scholz (Ed.). 2012.Digital Labor: The Internet As Playground and Factory. Taylor & Francis Group
2012
-
[49]
Paschal Sheeran and Thomas L Webb. 2016. The intention–behavior gap.Social and personality psychology compass 10, 9 (2016), 503–518
2016
-
[50]
Ben Shneiderman. 2020. Human-Centered Artificial Intelligence: Reliable, Safe & Trustworthy.arXiv preprint arXiv:2002.04087(2020). https://arxiv.org/abs/2002.04087
arXiv 2020
-
[51]
Valerie J. Shute. 2008. Focus on Formative Feedback.Review of Educational Research78, 1 (2008), 153–189. https: //doi.org/10.3102/0034654307313795
-
[52]
Susan Leigh Star and Anselm Strauss. 1999. Layers of silence, arenas of voice: The ecology of visible and invisible work.Computer supported cooperative work (CSCW)8, 1 (1999), 9–30. https://doi.org/10.1023/A:1008651105359
-
[53]
1987.Plans and situated actions: The problem of human-machine communication
Lucille Alice Suchman. 1987.Plans and situated actions: The problem of human-machine communication. Cambridge university press
1987
-
[54]
Danielle R Thomas, Jionghao Lin, Erin Gatz, Ashish Gurung, Shivang Gupta, Kole Norberg, Stephen E Fancsali, Vincent Aleven, Lee Branstetter, Emma Brunskill, and Kenneth R Koedinger. 2024. Improving Student Learning with Hybrid Human-AI Tutoring: A Three-Study Quasi-Experimental Investigation. InProceedings of the 14th Learning Analytics and Knowledge Conf...
-
[55]
Carlos Toxtli, Siddharth Suri, and Saiph Savage. 2021. Quantifying the Invisible Labor in Crowd Work.Proc. ACM Hum.-Comput. Interact.5, CSCW2, Article 319 (Oct. 2021), 26 pages. https://doi.org/10.1145/3476060
-
[56]
Maya Usher. 2025. Generative AI vs. instructor vs. peer assessments: a comparison of grading and feedback in higher education.Assessment & Evaluation in Higher Education50, 6 (2025), 912–927. https://doi.org/10.1080/02602938.2025. 2487495
-
[57]
Rose E. Wang, Ana T. Ribeiro, Carly D. Robinson, Susanna Loeb, and Dora Demszky. 2025. Tutor CoPilot: A Human-AI Approach for Scaling Real-Time Expertise. arXiv:2410.03017 [cs.CL] https://arxiv.org/abs/2410.03017
arXiv 2025
-
[58]
Shen Wang, Tianlong Xu, Hang Li, Chaoli Zhang, Joleen Liang, Jiliang Tang, Philip S. Yu, and Qingsong Wen. 2024. Large Language Models for Education: A Survey and Outlook. arXiv:2403.18105 [cs.CL] https://arxiv.org/abs/2403.18105
arXiv 2024
-
[59]
Lixiang Yan, Lele Sha, Linxuan Zhao, Yuheng Li, Roberto Martinez-Maldonado, Guanliang Chen, Xinyu Li, Yueqiao Jin, and Dragan Gašević. 2024. Practical and ethical challenges of large language models in education: A systematic scoping review.British Journal of Educational Technology55, 1 (2024), 90–112. https://doi.org/10.1111/bjet.13370
-
[60]
Qian Yang, Aaron Steinfeld, Carolyn Rosé, and John Zimmerman. 2020. Re-examining Whether, Why, and How Human-AI Interaction Is Uniquely Difficult to Design. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–13. https://doi.org/10.1145/331383...
-
[61]
Jean-Gabriel Young, Amanda Casari, Katie McLaughlin, Milo Z Trujillo, Laurent Hébert-Dufresne, and James P Bagrow. 2021. Which contributions count? Analysis of attribution in open source. In2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR). IEEE, 242–253
2021
-
[62]
Padilla, Jeffrey Caterino, Ping Zhang, and Dakuo Wang
Shao Zhang, Jianing Yu, Xuhai Xu, Changchang Yin, Yuxuan Lu, Bingsheng Yao, Melanie Tory, Lace M. Padilla, Jeffrey Caterino, Ping Zhang, and Dakuo Wang. 2024. Rethinking Human-AI Collaboration in Complex Medical Decision Making: A Case Study in Sepsis Diagnosis. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, U...
-
[63]
Alice Li, Andrew Rice, Devon Rifkin, Shawn Simister, Ganesh Sittampalam, and Edward Aftandilian
Albert Ziegler, Eirini Kalliamvakou, X. Alice Li, Andrew Rice, Devon Rifkin, Shawn Simister, Ganesh Sittampalam, and Edward Aftandilian. 2024. Measuring GitHub Copilot’s Impact on Productivity.Commun. ACM67, 3 (Feb. 2024), 54–63. https://doi.org/10.1145/3633453
-
[64]
Nikolas Zöller, Julian Berger, Irving Lin, Nathan Fu, Jayanth Komarneni, Gioele Barabucci, Kyle Laskowski, Victor Shia, Benjamin Harack, Eugene A. Chu, Vito Trianni, Ralf H. J. M. Kurvers, and Stefan M. Herzog. 2025. Human–AI collectives most accurately diagnose clinical vignettes.Proceedings of the National Academy of Sciences122, 24 (2025), e2426153122....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.