DeskCraft: Benchmarking Desktop Agents on Professional Workflows and Human-in-the-Loop Collaboration
Pith reviewed 2026-06-28 10:31 UTC · model grok-4.3
The pith
A benchmark for desktop agents finds top models succeed on fewer than one-third of long-horizon creative tasks even with human input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
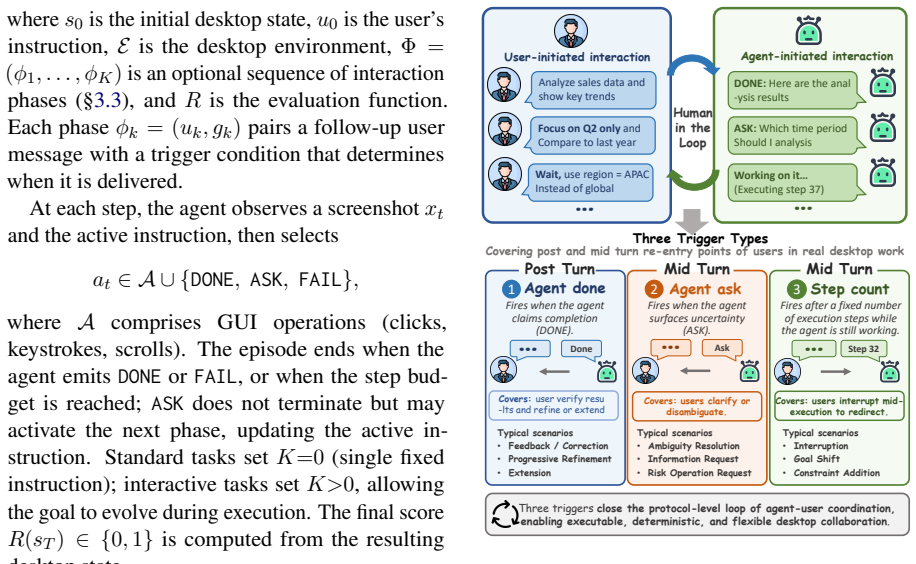
DeskCraft organizes tasks into a multilevel difficulty taxonomy with long-horizon examples requiring over 50 execution steps across design, video, audio, and 3D software, while formalizing human-agent collaboration through an interaction protocol that covers mid-turn exchanges for clarification under uncertainty and post-turn feedback after task completion.
What carries the argument
The interaction protocol that spans mid-turn agent-initiated clarification and user interruption plus post-turn user feedback, together with the multilevel difficulty taxonomy for workflows over 50 steps.
If this is right
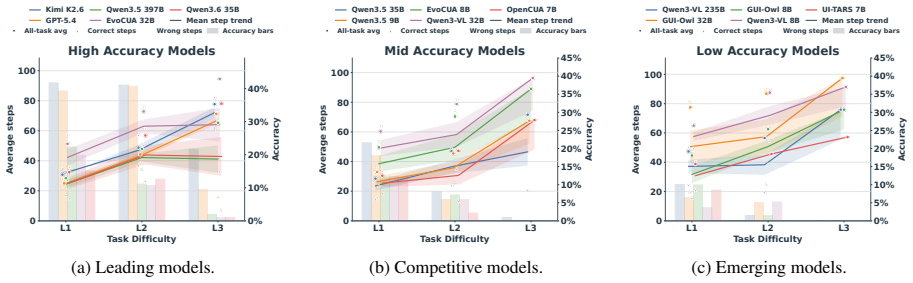
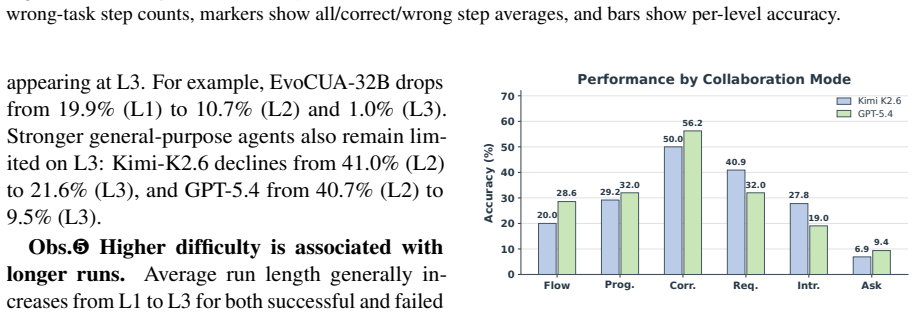
- Current agents show persistent shortfalls in delivering complete long-horizon workflows.
- Proactive clarification under uncertainty remains a frequent failure mode.
- The benchmark supplies a standardized testbed for measuring progress on interactive desktop tasks.
- Results indicate that human-in-the-loop coordination is essential for practical use in professional settings.
Where Pith is reading between the lines
- The performance numbers suggest that simply increasing model scale may not close the gap without new mechanisms for sustained interaction and uncertainty handling.
- The benchmark could be extended to additional software domains to test whether the observed limitations are general.
- Real deployment of such agents would likely require built-in support for repeated mid-task adjustments rather than one-shot execution.
Load-bearing premise
The tasks, software environments, and interaction protocol accurately capture the structure and collaboration patterns of real-world long-horizon professional desktop workflows.
What would settle it
A new agent achieving markedly higher success rates, such as above 60 percent, on the same 538 tasks under the defined interaction protocol would challenge the reported performance gaps.
Figures



read the original abstract
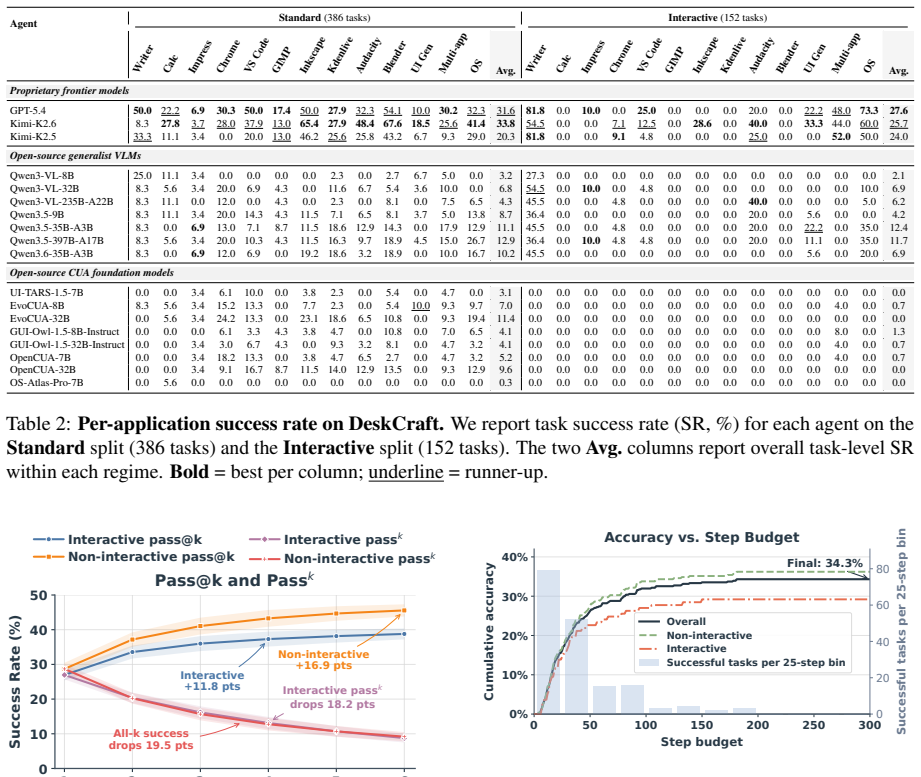
Real-world professional desktop workflows in specialized creative and engineering software unfold over long horizons and often require human-in-the-loop coordination, where agents proactively seek necessary information and users provide additional instructions, clarifications, feedback, or corrections as the task progresses. Yet existing desktop GUI benchmarks mostly reduce this setting to short, simplified tasks with all user instructions provided upfront. To address this issue, we introduce DeskCraft, a desktop GUI benchmark targeting long horizon creative and engineering workflows and proactive human-agent collaboration. DeskCraft organizes tasks into a multilevel difficulty taxonomy, with long horizon tasks requiring over 50 execution steps, and covers professional creative software across design, video, audio, and 3D creation. Furthermore, DeskCraft formalizes human-agent collaboration into an interaction protocol covering mid-turn and post-turn exchanges. Mid-turn interaction captures both agent-initiated clarification under uncertainty and user-initiated interruption during execution, while post-turn interaction accommodates user-driven feedback after the agent signals completion, together spanning the full space of realistic collaboration patterns. We evaluate 18 proprietary and open source agents on 538 tasks and find that GPT-5.4 reaches 31.6% on standard tasks and 27.6% on interactive tasks. Further analyses reveal persistent failures in long horizon workflow delivery and proactive clarification. We will open-source all evaluation codes, tasks, and data at https://github.com/mrwwk/DeskCraft.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DeskCraft, a benchmark for desktop GUI agents focused on long-horizon professional workflows in creative and engineering software (design, video, audio, 3D) that require over 50 steps. It formalizes human-in-the-loop collaboration via an interaction protocol with mid-turn (agent clarification or user interruption) and post-turn (user feedback after completion) exchanges. The authors evaluate 18 proprietary and open-source agents across 538 tasks organized by a multilevel difficulty taxonomy, reporting that GPT-5.4 achieves 31.6% success on standard tasks and 27.6% on interactive tasks, while identifying persistent failures in long-horizon delivery and proactive clarification. All evaluation code, tasks, and data will be open-sourced.
Significance. If the tasks and protocol accurately reflect real professional desktop workflows, DeskCraft would provide a more realistic evaluation setting than prior short-horizon GUI benchmarks, highlighting gaps in current agents and guiding future work on long-horizon planning and collaboration. The explicit commitment to open-sourcing code, tasks, and data is a clear strength that supports reproducibility and community extension.
minor comments (3)
- [§3] §3 (Task Construction): While the multilevel taxonomy and >50-step horizon are described, a brief table or paragraph quantifying the distribution of tasks across software categories (design/video/audio/3D) and difficulty levels would help readers assess coverage balance.
- [§4.2] §4.2 (Interaction Protocol): The mid-turn and post-turn definitions are clear, but adding one concrete example trace (agent action, clarification request, user response) would improve readability for readers unfamiliar with the protocol.
- [§5] §5 (Results): The failure analyses mention long-horizon and clarification issues; including a per-difficulty-level breakdown (e.g., success rates for level-3 vs. level-1 tasks) would strengthen the claim that long-horizon delivery remains a bottleneck.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of DeskCraft, the recognition of its potential value over prior short-horizon benchmarks, and the recommendation for minor revision. We appreciate the emphasis on open-sourcing as a strength for reproducibility.
Circularity Check
No significant circularity: empirical benchmark with direct measurements
full rationale
The paper introduces DeskCraft as a new benchmark for desktop agents, defines tasks and interaction protocols, then reports direct empirical success rates (e.g., 31.6% and 27.6%) from running 18 agents on 538 tasks. No equations, fitted parameters, derivations, or predictions appear; the central claims are measurements scoped to the supplied task definitions and released code. No self-citation chains or ansatzes underpin the results. This matches the default expectation of a non-circular empirical benchmark paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The selected tasks and software environments represent typical long-horizon professional workflows in creative and engineering domains.
- domain assumption The formalized mid-turn and post-turn interaction protocol spans the full space of realistic human-agent collaboration patterns.
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dil- lon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, and 1 others. 2024. Windows agent arena: Evalu- ating multi-modal os agents at scale.arXiv preprint arXiv:2409.08264. Xiang Deng, Jeff Da, Edwin Pan, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Swe-bench pro: Can ai agents solve long- horizon software engineering tasks?arXiv preprint arXiv:2509.16941. Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI conference on Human Factors in Computing Systems, pages 159– 166. Hongrui Jia, Jitong Liao, Xi Zhang, Haiyang Xu, Tian- bao Xie, Chaoya Jiang, Ming Yan,...
work page internal anchor Pith review Pith/arXiv arXiv 1999
-
[3]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom
Veriweb: Verifiable long-chain web bench- mark for agentic information-seeking.arXiv preprint arXiv:2508.04026. Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2024. Gaia: a benchmark for general ai assistants. InInternational Conference on Learning Representations, volume 2024, pages 9025–9049. Shravan Nayak, Xiangru Ji...
-
[4]
InInternational Conference on Learning Representations, volume 2025, pages 5090– 5108
Os-atlas: Foundation action model for gen- eralist gui agents. InInternational Conference on Learning Representations, volume 2025, pages 5090– 5108. Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, and 1 others
2025
-
[5]
5: Multi-platform fundamental gui agents , author=
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Frank Fangzheng Xu, Yufan Song, Boxuan Li, Yux- uan Tang, Kritanjali Jain, Mengxue Bao, Zora Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, and 1 oth- ers. 2026a. Theagentcompany: benchmarking llm agent...
-
[6]
Do not use overly precise technical terms unless your persona is a professional user
Speak like a real user. Do not use overly precise technical terms unless your persona is a professional user
-
[7]
Use the screenshot to judge whether the AI assistant has completed the current requirement
-
[8]
Next Phase Goal
If a "Next Phase Goal" is provided above, naturally ask for that requirement next. Do not invent new requests on your own
-
[9]
If the current phase is complete and there is no next phase goal, indicate that the whole task is finished and do not add any new requests
-
[10]
Keep the conversation natural and coherent, like a real person chatting with an AI assistant
-
[11]
If the task context is in Chinese, reply in Chinese; if it is in English, reply in English
Your`message`should follow the language implied by the scenario and current instruction. If the task context is in Chinese, reply in Chinese; if it is in English, reply in English
-
[12]
In normal cases, always set`action`to `new_instruction`
-
[13]
If the AI assistant has not completed the current phase, keep the interaction in the same phase: set `phase_complete`to false and use`message`to restate or correct the current requirement
-
[14]
If the AI assistant has completed the current phase and there is a next phase goal, set`phase_complete`to true and use`message`to naturally express that next phase goal
-
[15]
In that case, use`clarify`and set`phase_complete` to true
If the current phase expects the AI assistant to ask the user a question, answer that question directly and naturally. In that case, use`clarify`and set`phase_complete` to true
-
[16]
If the AI assistant explicitly asks the user a question unexpectedly, you may use`clarify`, and in that case `phase_complete`must be false. ## Output Format You must output valid JSON with the following fields: { "action": "new_instruction" or "clarify", "message": "What you want to say to the AI assistant", "phase_complete": true or false, "reason": "Whe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.