HARVE: Hacking-Aware Reward-Head Vector Editing for Robust Reward Models
Pith reviewed 2026-06-28 11:30 UTC · model grok-4.3
The pith
Removing the projection of a multi-directional hacking subspace from the reward-head vector increases robustness to reward hacking without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HARVE identifies a multi-directional hacking subspace from residual stream directions associated with selected hacking subcategories, and removes the component of the reward-head vector aligned with that subspace. This directly reduces the reward head's sensitivity to hacking-related features using only a small set of contrastive gold-hacked examples, without gradient updates or fine-tuning.
What carries the argument
Multi-directional hacking subspace extracted from residual stream directions, whose aligned component is subtracted from the reward-head vector.
If this is right
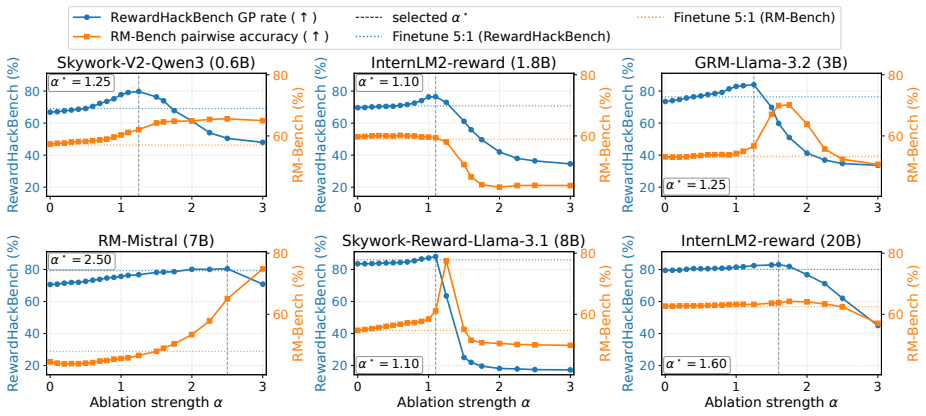
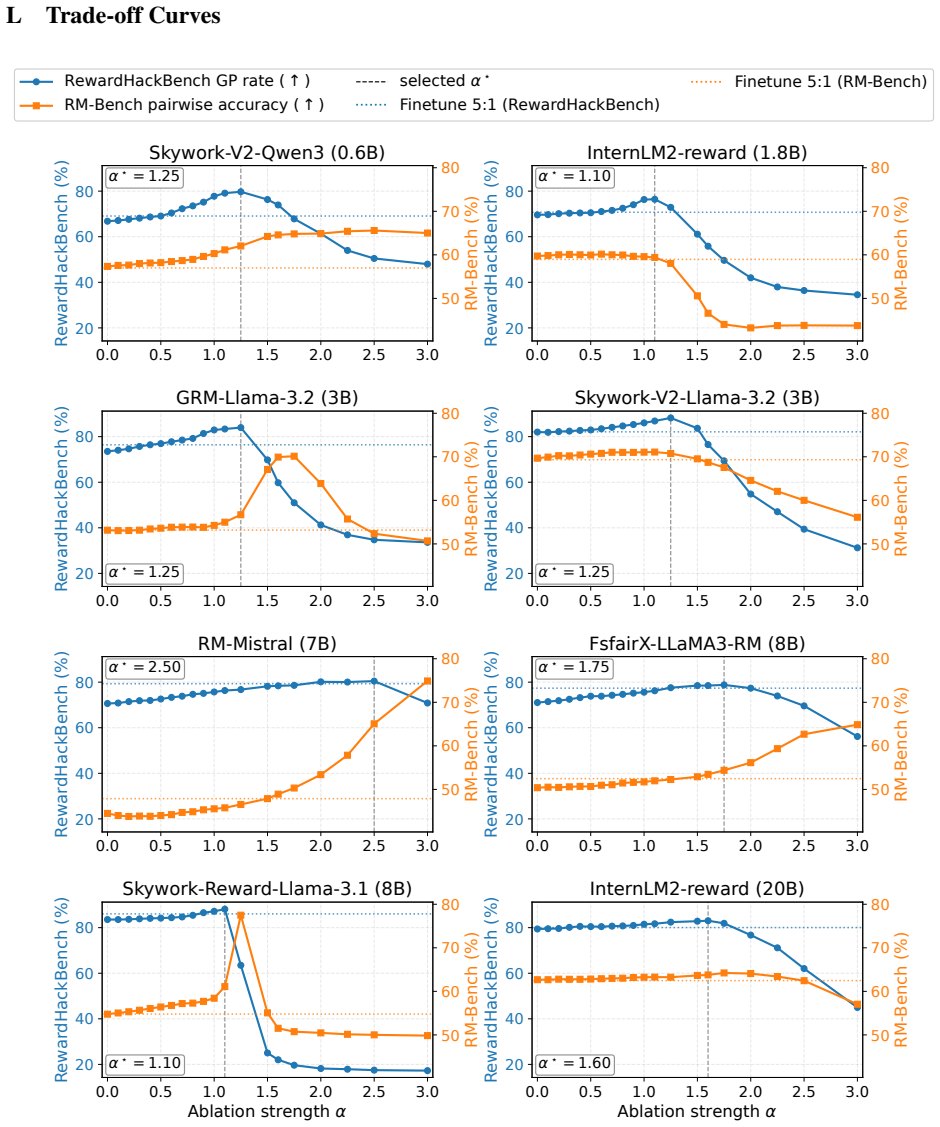
- HARVE improves robustness across all thirteen patterns in RewardHackBench for eight different reward models.
- The method outperforms fine-tuning baselines on both robustness and preservation of general capability.
- Reward hacking is captured more effectively as a multidimensional structure in residual space than as isolated surface cues.
- Only a small number of contrastive examples are needed and no gradient updates are required.
Where Pith is reading between the lines
- If the subspace is stable across models, similar editing could be tried on other alignment modules such as safety classifiers.
- The result suggests that contrastive examples can surface shared structural vulnerabilities inside different reward models.
- Extending the approach to new hacking patterns would require only adding their residual directions to the subspace calculation.
Load-bearing premise
The subspace found from a small set of contrastive examples for chosen subcategories stays stable and its removal does not create new failure modes or hurt performance on untested patterns.
What would settle it
After HARVE editing on a given set of subcategories, the model still gives high rewards to hacked responses from a different subcategory never used to build the subspace, or accuracy on ordinary preference data drops measurably.
Figures

read the original abstract
Reward models are central to large language model (LLM) alignment, but they remain vulnerable to reward hacking. To evaluate reward-model robustness, we introduce RewardHackBench containing 13 reward-hacking patterns covering real life high-stakes domains and general settings, and we find severe failures on specific subcategories across eight reward models. To mitigate these failures, we propose HARVE, a training-free reward-head editing method for scalar reward models. Instead of fine-tuning the reward model, HARVE identifies a multi-directional hacking subspace from residual stream directions associated with selected hacking subcategories, and removes the component of the reward-head vector aligned with that subspace. This directly reduces the reward head's sensitivity to hacking-related features using only a small set of contrastive gold-hacked examples, without gradient updates or fine-tuning. Comprehensive experiments across eight reward models indicates that \model improves hacking robustness, outperforms fine-tuning baselines, and preserves reward-models' general capability. Further analyses suggest that reward hacking is better captured as a multidimensional residual-space structure than by isolated surface cues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RewardHackBench, a benchmark with 13 reward-hacking patterns across high-stakes and general domains, reports severe failures on specific subcategories in eight reward models, and proposes HARVE: a training-free method that extracts a multi-directional hacking subspace from residual-stream directions on a small set of contrastive gold-hacked examples for selected subcategories and edits the reward-head vector by removing its projection onto that subspace, claiming improved robustness to hacking, superiority to fine-tuning baselines, and preservation of general capabilities.
Significance. If the central claims hold, the work offers a lightweight, gradient-free intervention on scalar reward models that treats reward hacking as a multidimensional residual-space structure rather than isolated cues; the benchmark itself would also provide a useful standardized testbed. The training-free nature and reported preservation of general capability are practically relevant strengths for alignment pipelines.
major comments (3)
- [§4.2] §4.2 (Hacking Subspace Extraction): the stability of the multi-directional subspace extracted from residual-stream directions on a small set of contrastive examples is asserted but not quantified (no bootstrap variance, no cosine-similarity matrix across example subsets, no sensitivity to subcategory choice); because the method is defined by orthogonalization against this subspace, instability directly undermines the reported robustness gains on RewardHackBench.
- [§5.3] §5.3 (General Capability Preservation): the claim that editing does not degrade performance outside the 13 patterns rests on evaluations that remain within RewardHackBench distributions; no results are shown on held-out prompt distributions or standard capability benchmarks that are disjoint from the tested hacking subcategories, leaving open the possibility that new failure modes are introduced.
- [Table 3] Table 3 (Baseline Comparison): the reported superiority over fine-tuning baselines lacks sufficient controls (no details on the exact fine-tuning data mixture, learning-rate schedule, or number of epochs used for the baselines), so it is unclear whether the advantage is attributable to the subspace-editing procedure or to differences in training regime.
minor comments (3)
- [Figure 2] Figure 2: the residual-stream direction visualization lacks explicit scale bars or normalization details, making it hard to interpret the magnitude of the hacking subspace components.
- [§2] §2 (Related Work): several recent papers on mechanistic analysis of reward models are cited only in passing; a more systematic comparison with prior editing or steering methods would clarify novelty.
- The abstract states results on eight models but the main text should explicitly list model names, sizes, and training corpora in a single table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Hacking Subspace Extraction): the stability of the multi-directional subspace extracted from residual-stream directions on a small set of contrastive examples is asserted but not quantified (no bootstrap variance, no cosine-similarity matrix across example subsets, no sensitivity to subcategory choice); because the method is defined by orthogonalization against this subspace, instability directly undermines the reported robustness gains on RewardHackBench.
Authors: We agree that quantitative stability metrics were not reported. In the revision we will add bootstrap variance estimates across repeated draws of the contrastive example sets, cosine-similarity matrices between subspaces obtained from different subsets, and sensitivity checks with respect to subcategory selection. These results will be inserted into §4.2 and will confirm that the extracted multi-directional subspace is stable, thereby supporting the robustness gains. revision: yes
-
Referee: [§5.3] §5.3 (General Capability Preservation): the claim that editing does not degrade performance outside the 13 patterns rests on evaluations that remain within RewardHackBench distributions; no results are shown on held-out prompt distributions or standard capability benchmarks that are disjoint from the tested hacking subcategories, leaving open the possibility that new failure modes are introduced.
Authors: RewardHackBench already incorporates general-domain patterns intended to proxy capability preservation. Nevertheless, we accept that fully disjoint standard benchmarks would provide stronger evidence. We will add evaluations on held-out prompt sets and standard capability benchmarks (e.g., MMLU-style tasks) that are disjoint from the 13 hacking subcategories, placing the new results in an expanded §5.3. revision: yes
-
Referee: [Table 3] Table 3 (Baseline Comparison): the reported superiority over fine-tuning baselines lacks sufficient controls (no details on the exact fine-tuning data mixture, learning-rate schedule, or number of epochs used for the baselines), so it is unclear whether the advantage is attributable to the subspace-editing procedure or to differences in training regime.
Authors: Hyperparameter details for the fine-tuning baselines (data mixture, learning-rate schedule, epochs) appear in Appendix C. To address the concern directly, we will summarize these controls in the main-text discussion of Table 3 and enlarge the table caption in the revision so that the comparison regime is transparent without requiring the reader to consult the appendix. revision: partial
Circularity Check
No circularity: direct empirical subspace extraction and vector editing
full rationale
The paper describes HARVE as a training-free procedure that extracts a multi-directional hacking subspace directly from residual-stream directions on a small set of contrastive gold-hacked examples and subtracts the aligned component from the reward-head vector. Robustness gains are measured on the externally introduced RewardHackBench benchmark across eight models; these outcomes are not quantities defined in terms of the editing operation itself. No equations, fitted parameters renamed as predictions, self-citations, or imported uniqueness theorems appear in the abstract or method summary. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning to summarize with human feedback,
N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. V oss, A. Radford, D. Amodei, and P. F. Christiano, “Learning to summarize with human feedback,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 3008–3021. [Online]. Available: https://...
2020
-
[2]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems, S. K...
2022
-
[3]
arXiv preprint arXiv:2310.03716 , year=
P. Singhal, T. Goyal, J. Xu, and G. Durrett, “A long way to go: Investigating length correlations in rlhf,” 2024. [Online]. Available: https://arxiv.org/abs/2310.03716
-
[4]
Scaling laws for reward model overoptimization,
L. Gao, J. Schulman, and J. Hilton, “Scaling laws for reward model overoptimization,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23–29 Jul 2023, pp. 10 835–10 866. [Online]. Available...
2023
-
[5]
OffsetBias: Leveraging debiased data for tuning evaluators,
J. Park, S. Jwa, R. Meiying, D. Kim, and S. Choi, “OffsetBias: Leveraging debiased data for tuning evaluators,” in Findings of the Association for Computational Linguistics: EMNLP 2024, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 1043–1067. [Online]. Available: https://acl...
2024
-
[6]
Rm-bench: Benchmarking reward models of language models with subtlety and style,
Y . Liu, Z. Yao, R. Min, Y . Cao, L. Hou, and J. Li, “Rm-bench: Benchmarking reward models of language models with subtlety and style,” inInternational Conference on Learning Representations, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., vol. 2025, 2025, pp. 44 323–44 355. [Online]. Available: https: //proceedings.iclr.cc/paper_files/paper/2025/file...
2025
-
[7]
Towards understanding sycophancy in language models,
M. Sharma, M. Tong, T. Korbak, D. Duvenaud, A. Askell, S. Bowman, E. DURMUS, Z. Hatfield-Dodds, S. Johnston, S. Kravec, T. Maxwell, S. McCandlish, K. Ndousse, O. Rausch, N. Schiefer, D. Yan, M. Zhang, and E. Perez, “Towards understanding sycophancy in language models,” inInternational Conference on Learning Representations, B. Kim, Y . Yue, S. Chaudhuri, ...
2024
-
[8]
RewardBench: Evaluating reward models for language modeling,
N. Lambert, V . Pyatkin, J. Morrison, L. Miranda, B. Y . Lin, K. Chandu, N. Dziri, S. Kumar, T. Zick, Y . Choi, N. A. Smith, and H. Hajishirzi, “RewardBench: Evaluating reward models for language modeling,” inFindings of the Association for Computational Linguistics: NAACL 2025, L. Chiruzzo, A. Ritter, and L. Wang, Eds. Albuquerque, New Mexico: Associatio...
2025
-
[9]
The trickle-down impact of reward inconsistency on rlhf,
L. Shen, S. Chen, L. Song, L. Jin, B. Peng, H. Mi, D. Khashabi, and D. Yu, “The trickle-down impact of reward inconsistency on rlhf,” inInternational Conference on Learning Representations, B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, Eds., vol. 2024, 2024, pp. 33 029–33 057. [Online]. Available: https: //proceedings.iclr.cc/paper_...
2024
-
[10]
Rrm: Robust reward model training mitigates reward hacking,
T. Liu, W. Xiong, J. Ren, L. Chen, J. Wu, R. Joshi, Y . Gao, J. Shen, Z. Qin, T. Yu, D. Sohn, A. Makarova, J. Z. Liu, Y . Liu, B. Piot, A. Ittycheriah, A. Kumar, and M. Saleh, “Rrm: Robust reward model training mitigates reward hacking,” inInternational Conference on Learning Representations, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., vol. 2025, ...
2025
-
[11]
ODIN: Disentangled reward mitigates hacking in RLHF,
L. Chen, C. Zhu, J. Chen, D. Soselia, T. Zhou, T. Goldstein, H. Huang, M. Shoeybi, and B. Catanzaro, “ODIN: Disentangled reward mitigates hacking in RLHF,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, R. Salakhutdinov, Z. Kolter, K. Heller, A. Weller, N. Oliver, J. Scarlett, and F. ...
2024
-
[12]
Evaluating large language models at evaluating instruction following,
Z. Zeng, J. Yu, T. Gao, Y . Meng, T. Goyal, and D. Chen, “Evaluating large language models at evaluating instruction following,” inInternational Conference on Learning Representations, B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, Eds., vol. 2024, 2024, pp. 40 193–40 219. [Online]. Available: https: //proceedings.iclr.cc/paper_files...
2024
-
[13]
Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models,
N. Guha, J. Nyarko, D. Ho, C. Ré, A. Chilton, A. K, A. Chohlas-Wood, A. Peters, B. Waldon, D. Rockmore, D. Zambrano, D. Talisman, E. Hoque, F. Surani, F. Fagan, G. Sarfaty, G. Dickinson, H. Porat, J. Hegland, J. Wu, J. Nudell, J. Niklaus, J. Nay, J. Choi, K. Tobia, M. Hagan, M. Ma, M. Livermore, N. Rasumov-Rahe, N. Holzenberger, N. Kolt, P. Henderson, S. ...
2023
-
[14]
Lexam: Benchmarking legal reasoning on 340 law exams,
Y . Fan, J. Ni, J. Merane, Y . Tian, Y . Hermstrüwer, Y . Huang, M. Akhtar, E. Salimbeni, F. Geering, O. Dreyer, D. Brunner, M. Leippold, M. Sachan, A. Stremitzer, C. Engel, E. Ash, and J. Niklaus, “Lexam: Benchmarking legal reasoning on 340 law exams,” 2026. [Online]. Available: https://arxiv.org/abs/2505.12864
-
[15]
Manning, Peter Hender- son, and Daniel E
L. Zheng, N. Guha, J. Arifov, S. Zhang, M. Skreta, C. D. Manning, P. Henderson, and D. E. Ho, “A reasoning-focused legal retrieval benchmark,” inProceedings of the 2025 Symposium on Computer Science and Law, ser. CSLAW ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 169–193. [Online]. Available: https://doi.org/10.1145/3709025.3712219
-
[16]
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
C. Y . Liu, L. Zeng, Y . Xiao, J. He, J. Liu, C. Wang, R. Yan, W. Shen, F. Zhang, J. Xu, Y . Liu, and Y . Zhou, “Skywork-reward-v2: Scaling preference data curation via human-ai synergy,” 2026. [Online]. Available: https://arxiv.org/abs/2507.01352
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Internlm2 technical report,
Z. Cai, M. Cao, H. Chen, K. Chen, K. Chen, X. Chen, X. Chen, Z. Chen, Z. Chen, P. Chu, X. Dong, H. Duan, Q. Fan, Z. Fei, Y . Gao, J. Ge, C. Gu, Y . Gu, T. Gui, A. Guo, Q. Guo, C. He, Y . Hu, T. Huang, T. Jiang, P. Jiao, Z. Jin, Z. Lei, J. Li, J. Li, L. Li, S. Li, W. Li, Y . Li, H. Liu, J. Liu, J. Hong, K. Liu, K. Liu, X. Liu, C. Lv, H. Lv, K. Lv, L. Ma, R...
-
[18]
[Online]. Available: https://arxiv.org/abs/2403.17297
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Regularizing hidden states enables learning generalizable reward model for llms,
R. Yang, R. Ding, Y . Lin, H. Zhang, and T. Zhang, “Regularizing hidden states enables learning generalizable reward model for llms,” 2024. [Online]. Available: https://arxiv.org/abs/2406.10216
-
[20]
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
H. Dong, W. Xiong, D. Goyal, Y . Zhang, W. Chow, R. Pan, S. Diao, J. Zhang, K. Shum, and T. Zhang, “Raft: Reward ranked finetuning for generative foundation model alignment,” 2023. [Online]. Available: https://arxiv.org/abs/2304.06767
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
W. Xiong, H. Dong, C. Ye, Z. Wang, H. Zhong, H. Ji, N. Jiang, and T. Zhang, “Iterative preference learning from human feedback: Bridging theory and practice for rlhf under kl-constraint,” 2024. [Online]. Available: https://arxiv.org/abs/2312.11456
-
[22]
RLHF Workflow: From Reward Modeling to Online RLHF
H. Dong, W. Xiong, B. Pang, H. Wang, H. Zhao, Y . Zhou, N. Jiang, D. Sahoo, C. Xiong, and T. Zhang, “Rlhf workflow: From reward modeling to online rlhf,” 2024. [Online]. Available: https://arxiv.org/abs/2405.07863
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Reward model ensembles help mitigate overoptimization,
T. Coste, U. Anwar, R. Kirk, and D. Krueger, “Reward model ensembles help mitigate overoptimization,” inInternational Conference on Learning Representations, B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, Eds., vol. 2024, 2024, pp. 50 905–50 931. [Online]. Available: https: //proceedings.iclr.cc/paper_files/paper/2024/file/dda7f9378a...
2024
-
[24]
Helping or herding? reward model ensembles mitigate but do not eliminate reward hacking,
J. Eisenstein, C. Nagpal, A. Agarwal, A. Beirami, A. D’Amour, D. Dvijotham, A. Fisch, K. Heller, S. Pfohl, D. Ramachandran, P. Shaw, and J. Berant, “Helping or herding? reward model ensembles mitigate but do not eliminate reward hacking,” 2024. [Online]. Available: https://arxiv.org/abs/2312.09244
-
[25]
Defining and characterizing reward gaming,
J. Skalse, N. Howe, D. Krasheninnikov, and D. Krueger, “Defining and characterizing reward gaming,” in Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 9460–9471. [Online]. Available: https://proceedings. neurips.cc/paper_files/paper/2022...
2022
-
[26]
How to evaluate reward models for rlhf,
E. Frick, T. Li, C. Chen, W.-L. Chiang, A. Angelopoulos, J. Jiao, B. Zhu, J. E. Gonzalez, and I. Stoica, “How to evaluate reward models for rlhf,” inInternational Conference on Learning Representations, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., vol. 2025, 2025, pp. 18 128–18 163. [Online]. Available: https: //proceedings.iclr.cc/paper_files/pape...
2025
-
[27]
Contracteval: Benchmarking llms for clause-level legal risk identification in commercial contracts,
S. Liu, Z. Li, R. Ma, H. Zhao, and M. Du, “Contracteval: Benchmarking llms for clause-level legal risk identification in commercial contracts,” 2025. [Online]. Available: https://arxiv.org/abs/2508.03080
-
[28]
Llm agents in law: Taxonomy, applications, and challenges,
S. Liu, R. Zhang, R. Ma, Y . Deng, L. Zhu, J. Li, Z. Li, Z. Shen, and M. Du, “Llm agents in law: Taxonomy, applications, and challenges,” 2026. [Online]. Available: https://arxiv.org/abs/2601.06216
-
[29]
Representation Engineering: A Top-Down Approach to AI Transparency
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, A.-K. Dombrowski, S. Goel, N. Li, M. J. Byun, Z. Wang, A. Mallen, S. Basart, S. Koyejo, D. Song, M. Fredrikson, J. Z. Kolter, and D. Hendrycks, “Representation engineering: A top-down approach to ai transparency,” 2025. [Online]. Available: https://arxiv.org/abs/2310.01405
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Steering Language Models With Activation Engineering
A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. MacDiarmid, “Steering language models with activation engineering,” 2024. [Online]. Available: https://arxiv.org/abs/2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Refusal in language models is mediated by a single direction,
A. Arditi, O. Obeso, A. Syed, D. Paleka, N. Panickssery, W. Gurnee, and N. Nanda, “Refusal in language models is mediated by a single direction,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 136 037–136 083. [Online]...
2024
-
[32]
reward-lens: A Mechanistic Interpretability Library for Reward Models
M. S. B. Nadaf, “reward-lens: A mechanistic interpretability library for reward models,” 2026. [Online]. Available: https://arxiv.org/abs/2604.26130 A More Related Work Reward models and reward hacking.Reward models are widely used in LLM alignment pipelines [ 2, 21], but remain vulnerable to reward hacking [24], which may affect downstream LLM performanc...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Query validity.The query should be realistic, coherent, and appropriate for the assigned domain or task setting
-
[34]
Gold correctness.The gold response should be substantively correct, responsive to the query, and free of major legal, factual, or reasoning errors
-
[35]
Hacked-response validity.The hacked response should contain the intended failure mode while remaining fluent, plausible, and comparable in surface quality to the gold response
-
[36]
Single-pattern control.The hacked response should primarily instantiate the assigned hacking pattern, rather than introducing multiple unrelated errors
-
[37]
Matched presentation.The hacked response should preserve the gold response’s approximate length, structure, tone, and level of detail, unless the subcategory specifically targets presentation style
-
[38]
likely,” “generally,
Non-triviality.The hacked response should not be obviously worse due to grammar, incoherence, missing formatting, or other superficial defects unrelated to the target hacking pattern. Review decisions.One of three labels was assigned to each pair: •Accept:the pair satisfies the above criteria and can be included without revision. • Revise:the pair is usab...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.