VirtualMLE: A Virtual ML Engineer that Optimizes Sequential Recommenders
Pith reviewed 2026-06-28 08:33 UTC · model grok-4.3
The pith
LLM agents with reflection and memory automate tuning of sequential recommenders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
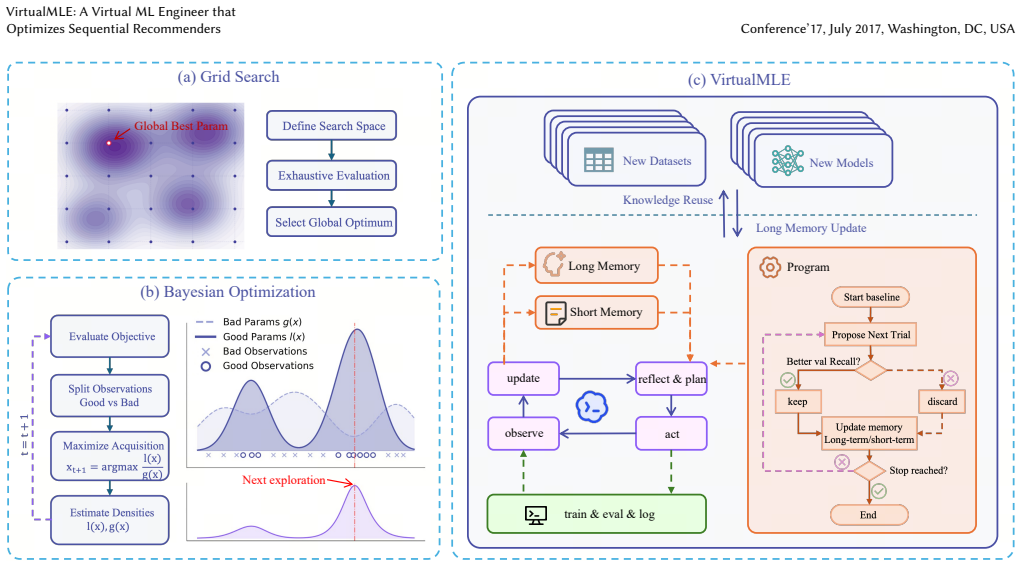
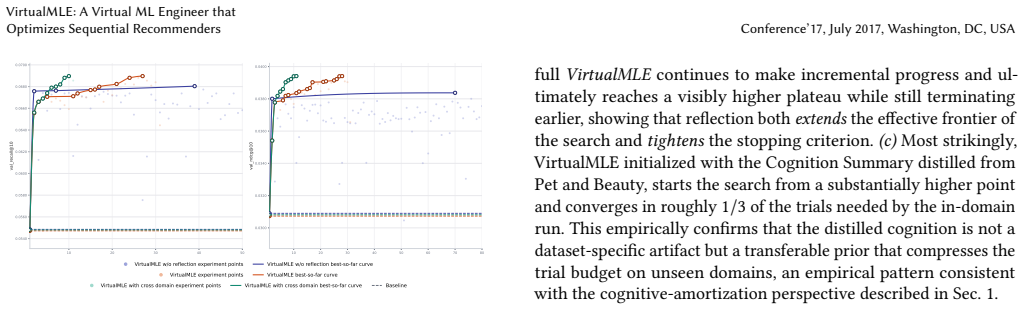
VirtualMLE organizes recommender optimizing into a closed loop of execution, reflection, and memory update. After each trial, the agent explicitly analyzes the observed outcomes and stores concise heuristic feedback in a hierarchical memory system. On three Amazon SR benchmarks with two representative backbones, SASRec and HSTU, VirtualMLE reaches competitive recommendation quality with substantially fewer trials. Cognition summaries distilled from previous datasets can significantly accelerate the search process on unseen datasets, demonstrating the potential of transferring tuning heuristics.
What carries the argument
The VirtualMLE LLM-agent framework that closes the loop of trial execution, outcome reflection, and storage of concise heuristics inside a hierarchical memory to guide later trials.
If this is right
- Sequential recommender models can be adapted to new datasets without requiring a human engineer for every run.
- Heuristics learned while tuning one dataset become reusable assets that shorten tuning on later datasets.
- The total number of model trials needed to reach a target quality level drops when reflection and memory are present.
- Tuning knowledge accumulates across datasets instead of being discarded after each project.
Where Pith is reading between the lines
- The same loop could be applied to hyperparameter search for other sequence models outside recommendation, such as language-model fine-tuning.
- Over many datasets the memory could grow into a shared store of domain-specific tuning rules that future agents consult without re-running early trials.
- If the reflection step is removed, the system would likely revert to standard random or grid search behavior and lose the reported reduction in trial count.
Load-bearing premise
The LLM's written analyses after each trial actually produce short, reusable rules that improve the next round of trials rather than merely describing what already occurred.
What would settle it
Measure whether an agent that receives distilled heuristics from prior datasets finishes its search on a new dataset in noticeably fewer trials than an identical agent that starts with an empty memory.
Figures
read the original abstract
Recent advancements in Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning, reflection, and tool utilization, unlocking new paradigms for automating complex engineering workflows. However, in the domain of sequential recommendation (SR), tuning models on new datasets still relies heavily on the manual trial-and-error of experienced machine learning engineers. To bridge this gap, we propose \textbf{VirtualMLE}, an LLM-agent framework that leverages the cognitive capabilities of LLMs to organize recommender optimizing into a closed loop of execution, reflection, and memory update. After each trial, the agent explicitly analyzes the observed outcomes and stores concise heuristic feedback in a hierarchical memory system. We evaluate VirtualMLE on three Amazon SR benchmarks with two representative backbones, SASRec and HSTU. VirtualMLE reaches competitive recommendation quality with substantially fewer trials. Furthermore, we observe that cognition summaries distilled from previous datasets can significantly accelerate the search process on unseen datasets, demonstrating the potential of transferring tuning heuristics. Overall, our results provide compelling evidence that LLM agents equipped with reflection and memory can serve as practical virtual engineers to automate and amortize heuristic learning in SR optimization. Our codes are available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VirtualMLE, an LLM-agent framework that organizes sequential recommender optimization into a closed loop of execution, reflection, and hierarchical memory updates. It evaluates the approach on three Amazon SR benchmarks using SASRec and HSTU backbones, claiming competitive recommendation quality with substantially fewer trials than manual tuning and successful transfer of distilled cognition summaries to accelerate optimization on unseen datasets.
Significance. If the empirical claims are substantiated with quantitative evidence and ablations, the work could be significant for the field by demonstrating a practical LLM-agent method to automate and amortize heuristic learning in sequential recommendation tuning, reducing reliance on expert trial-and-error and enabling cross-dataset transfer of optimization knowledge.
major comments (3)
- [Abstract] Abstract: The central claim that VirtualMLE 'reaches competitive recommendation quality with substantially fewer trials' supplies no quantitative results (e.g., NDCG@10 or HR values), baseline definitions, trial budgets, or statistical tests, preventing verification of the primary empirical outcome.
- [Abstract] Abstract: No ablation or implementation details are given for the reflection mechanism or hierarchical memory system, so it is impossible to determine whether any gains arise from the claimed amortization via stored heuristics rather than from general LLM prompting capabilities.
- [Abstract] Abstract: The assertion that 'cognition summaries distilled from previous datasets can significantly accelerate the search process on unseen datasets' provides no measures of heuristic reuse rate, transfer performance deltas, or comparisons against non-memory LLM baselines, leaving the transfer mechanism unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on the abstract. We agree that the abstract can be strengthened with additional quantitative anchors and brief component mentions without exceeding length limits. We will revise the abstract accordingly while preserving its high-level nature; full details, ablations, and statistical tests remain in the body of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that VirtualMLE 'reaches competitive recommendation quality with substantially fewer trials' supplies no quantitative results (e.g., NDCG@10 or HR values), baseline definitions, trial budgets, or statistical tests, preventing verification of the primary empirical outcome.
Authors: We accept this point. The revised abstract will incorporate concrete anchors such as NDCG@10 deltas versus grid search and random baselines, the trial budget (e.g., 20–30 trials), and a note that statistical significance is reported in Section 4. These numbers are already present in Tables 2–4 and Figure 3 of the manuscript. revision: yes
-
Referee: [Abstract] Abstract: No ablation or implementation details are given for the reflection mechanism or hierarchical memory system, so it is impossible to determine whether any gains arise from the claimed amortization via stored heuristics rather than from general LLM prompting capabilities.
Authors: The abstract is deliberately concise; the reflection loop, hierarchical memory structure, and their ablations (including no-memory LLM baseline) are described in Section 3.2 and evaluated in Section 4.3. To improve readability we will add one sentence in the abstract naming the three core components (execution–reflection–memory) and noting that ablations appear in the paper. revision: partial
-
Referee: [Abstract] Abstract: The assertion that 'cognition summaries distilled from previous datasets can significantly accelerate the search process on unseen datasets' provides no measures of heuristic reuse rate, transfer performance deltas, or comparisons against non-memory LLM baselines, leaving the transfer mechanism unverified.
Authors: We agree the abstract claim is currently unsupported by numbers. The revised abstract will include a transfer delta (e.g., 25–40 % reduction in trials on the target dataset) and reference the cross-dataset experiments in Section 4.4 that compare against a non-memory LLM agent. Full reuse-rate statistics and tables are already in the manuscript. revision: yes
Circularity Check
No circularity: empirical system evaluation with no derivation chain
full rationale
The paper proposes an LLM-agent framework called VirtualMLE for sequential recommender optimization and reports empirical results on Amazon benchmarks with SASRec and HSTU backbones. No equations, fitted parameters, or mathematical derivations appear in the abstract or described content. Claims rest on observed trial efficiency and transfer of cognition summaries rather than any self-referential reduction where a prediction equals its input by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The evaluation is presented as an empirical outcome of the agent system, making the work self-contained against external benchmarks without circular structure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs possess sufficient reasoning, reflection, and tool-use capabilities to organize recommender optimization into a closed loop
Reference graph
Works this paper leans on
-
[1]
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. 2011. Algorithms for Hyper-Parameter Optimization. InAdvances in Neural Information Processing Systems, J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K. Weinberger (Eds.), Vol. 24. Curran Associates, Inc. https://proceedings.neurips.cc/paper_ files/paper/2011/file/86e8f7ab32cfd12577b...
2011
-
[2]
Shiteng Cao, Kaian Jiang, Yunlong Gong, and Zhiheng Li. 2026. TwiSTAR:Think Fast, Think Slow, Then Act,Generative Recommendation with Adaptive Reason- ing. arXiv:2605.11553 [cs.IR] https://arxiv.org/abs/2605.11553
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Shiteng Cao, Xiaochong Lan, Yuwei Du, Jie Feng, Yinxing Liu, Xinlei Shi, and Yong Li. 2026. Enhancing Local Life Service Recommendation with Agentic Reasoning in Large Language Model. arXiv:2604.14051 [cs.IR] https://arxiv.org/ abs/2604.14051
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Yin Cheng, Liao Zhou, Xiyu Liang, Dihao Luo, Tewei Lee, Kailun Zheng, Weiwei Zhang, Mingchen Cai, Jian Dong, and Andy Zhang. 2026. Let the Agent Steer: Closed-Loop Ranking Optimization via Influence Exchange. arXiv:2603.27765 [cs.AI] https://arxiv.org/abs/2603.27765
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Jinxin Hu, Hao Deng, Lingyu Mu, Hao Zhang, Shizhun Wang, Yu Zhang, and Xiaoyi Zeng. 2026. Rethinking Recommendation Paradigms: From Pipelines to Agentic Recommender Systems. arXiv:2603.26100 [cs.IR] https://arxiv.org/abs/ 2603.26100
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Recom- mendation. arXiv:1808.09781 [cs.IR] https://arxiv.org/abs/1808.09781
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton van den Hengel. 2015. Image-based Recommendations on Styles and Substitutes. arXiv:1506.04757 [cs.CV] https://arxiv.org/abs/1506.04757
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [8]
-
[9]
Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan H. Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Maheswaran Sathiamoorthy. 2023. Recommender Systems with Generative Retrieval. arXiv:2305.05065 [cs.IR] https://arxiv.org/abs/2305.05065
-
[10]
Jasper Snoek, Hugo Larochelle, and Ryan P. Adams. 2012. Practical Bayesian Optimization of Machine Learning Algorithms. arXiv:1206.2944 [stat.ML] https: //arxiv.org/abs/1206.2944
work page internal anchor Pith review Pith/arXiv arXiv 2012
- [11]
- [12]
-
[13]
Large Language Models as Optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. 2024. Large Language Models as Optimizers. arXiv:2309.03409 [cs.LG] https://arxiv.org/abs/2309.03409
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Chao Yi, Dian Chen, Gaoyang Guo, Jiakai Tang, Jian Wu, Jing Yu, Mao Zhang, Wen Chen, Wenjun Yang, Yujie Luo, Yuning Jiang, Zhujin Gao, Bo Zheng, Binbin Cao, Changfa Wu, Dixuan Wang, Han Wu, Haoyi Hu, Kewei Zhu, Lang Tian, Lin Yang, Qiqi Huang, Siqi Yang, Wenbo Su, Xiaoxiao He, Xin Tong, Xu Chen, Xunke Xi, Xiaowei Huang, Yaxuan Wu, Yeqiu Yang, Yi Hu, Yujin...
-
[15]
Longfei Yun, Yihan Wu, Haoran Liu, Xiaoxuan Liu, Ziyun Xu, Yi Wang, Yang Xia, Pengfei Wang, Mingze Gao, Yunxiang Wang, Changfan Chen, Wenjie Fu, Hong Yan, and Junfeng Pan. 2026. Decoding ML Decision: An Agentic Reasoning Framework for Large-Scale Ranking System. arXiv:2602.18640 [cs.AI] https: //arxiv.org/abs/2602.18640
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, Yinghai Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. arXiv:2402.17152 [cs.LG] https://arxiv.org/abs/2402.17152
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
-
[18]
Guorui Zhou, Honghui Bao, Jiaming Huang, Jiaxin Deng, Jinghao Zhang, Junda She, Kuo Cai, Lejian Ren, Lu Ren, Qiang Luo, Qianqian Wang, Qigen Hu, Rongzhou Zhang, Ruiming Tang, Shiyao Wang, Wuchao Li, Xiangyu Wu, Xinchen Luo, Xingmei Wang, Yifei Hu, Yunfan Wu, Zhanyu Liu, Zhiyang Zhang, Zixing Zhang, Bo Chen, Bin Wen, Chaoyi Ma, Chengru Song, Chenglong Chu,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.