MemoGen: Can Past Experience Improve Future Text-to-Image Generation?
Pith reviewed 2026-06-28 10:46 UTC · model grok-4.3
The pith
Storing and reusing experience from past generations lets text-to-image models improve on complex prompts without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MemoGen is a training-free framework that augments any image generator with an agentic evolution layer. For each task the agent infers visual requirements, retrieves evidence when needed, translates it into generation constraints, evaluates the output, and stores task understanding, reference choices, visual feedback, successful strategies, and failure lessons as experience memory. Across evolution rounds the agent retrieves relevant stored experience to improve new generations, selectively repairing previously failed cases while preserving successful ones.
What carries the argument
Experience memory, which records inferred visual requirements, chosen references, evaluations, successful strategies, and failure lessons so the agent can retrieve and apply them to future similar tasks.
If this is right
- An open-source backbone reaches higher scores than proprietary systems on WISE and Mind-Bench after only two rounds.
- The system improves failed cases from earlier rounds while leaving successful generations unchanged.
- Continual improvement occurs through memory retrieval alone, with no parameter updates to the generator.
- The approach directly addresses prompts that need implicit constraints, relational reasoning, or external knowledge.
Where Pith is reading between the lines
- The same memory-retrieval pattern could be added to other generative models such as video or 3-D synthesis.
- If memory entries grow large, compression or relevance-ranking rules would become necessary to keep retrieval accurate.
- One could measure whether the stored lessons remain useful when the generator backbone itself is swapped for a newer model.
- The framework suggests a route to test-time adaptation that avoids the cost of periodic full retraining.
Load-bearing premise
The agent can reliably infer visual requirements, judge image quality, and extract transferable strategies and lessons without introducing systematic errors or needing human correction.
What would settle it
A controlled test on the same benchmarks where performance after two or more evolution rounds is no better than the first round or where the agent repeatedly selects harmful memory entries for similar prompts.
Figures


read the original abstract
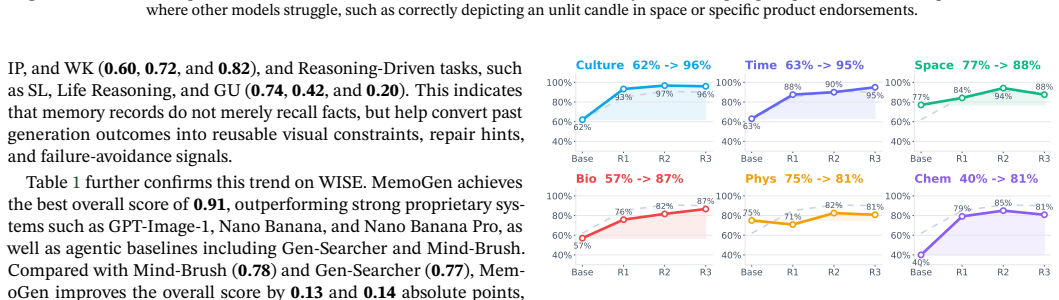
Modern text-to-image models have achieved strong visual synthesis, yet remain unreliable when prompts require implicit visual constraints, relational reasoning, or external knowledge. Existing retrieval-augmented and agentic generation methods mitigate this issue by acquiring external knowledge, references, or refined prompts for the current request, yet they typically treat each generation as an isolated episode and do not systematically preserve past successes or failures for future use. In this work, we ask whether a text-to-image system can continually improve from its own generation experience without updating the underlying generator. We propose MemoGen, a training-free framework that augments existing image generators with an agentic evolution layer. For each task, MemoGen explicitly infers visual requirements, retrieves external evidence and references when necessary, translates them into executable generation constraints, evaluates the generated result, and stores task understanding, reference choices, visual feedback, successful strategies, and failure lessons as reusable experience memory. Across evolution rounds, the agent retrieves relevant experience to improve similar future generations, selectively repairing previously failed cases while preserving successful ones, thereby enabling test-time self-evolution without parameter updates. Extensive experiments on knowledge-intensive and reasoning-oriented benchmarks demonstrate the effectiveness of this paradigm: after only two evolution rounds, MemoGen built upon the open-source Qwen-Image backbone surpasses strong proprietary systems such as Nano Banana Pro and GPT-Image-1 on WISE and Mind-Bench, showing that explicit experience memory can serve as a powerful continual learning signal for reliable text-to-image generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MemoGen, a training-free agentic framework that augments text-to-image generators with an evolution layer. For each task the agent infers visual requirements, retrieves references, translates them into constraints, evaluates the output, and stores task understanding, strategies, and failure lessons as reusable experience memory. Across rounds the memory is retrieved to improve similar future generations. The central empirical claim is that after only two evolution rounds the Qwen-Image backbone augmented by MemoGen surpasses proprietary systems (Nano Banana Pro, GPT-Image-1) on the WISE and Mind-Bench benchmarks.
Significance. If the reported gains are robustly supported by detailed experimental protocols, the work would be significant: it demonstrates that explicit, reusable experience memory can serve as a continual-learning signal for T2I models without any parameter updates, addressing a recognized weakness of current generators on relational, knowledge-intensive, and constraint-heavy prompts.
major comments (2)
- [Abstract / §3–4] Abstract (and §3–4, per the described pipeline): the headline result—that two evolution rounds suffice to surpass proprietary models—rests on the unverified assumption that the agent produces reliable scalar/textual evaluations and extracts transferable lessons. No mechanism, prompt template, inter-annotator agreement, or correlation study with human judgments on relational/knowledge-intensive prompts is supplied; if LLM-based evaluation correlates poorly, retrieved memories will reinforce rather than correct errors, rendering the evolution loop non-functional.
- [Abstract] Abstract: the claim of surpassing Nano Banana Pro and GPT-Image-1 on WISE and Mind-Bench after two rounds is presented without any description of evaluation procedure, exact metrics, data splits, number of runs, or statistical significance testing. This information is load-bearing for the central empirical claim and must be supplied before the result can be assessed.
minor comments (1)
- The abstract refers to “extensive experiments” but supplies no table or figure numbers; the full manuscript should include a dedicated results section with per-benchmark breakdowns and ablations on the memory-retrieval and evaluation components.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the evaluation procedures and empirical claims. We address each point below and will revise the manuscript to supply the requested details on mechanisms, prompts, and experimental protocols.
read point-by-point responses
-
Referee: [Abstract / §3–4] Abstract (and §3–4, per the described pipeline): the headline result—that two evolution rounds suffice to surpass proprietary models—rests on the unverified assumption that the agent produces reliable scalar/textual evaluations and extracts transferable lessons. No mechanism, prompt template, inter-annotator agreement, or correlation study with human judgments on relational/knowledge-intensive prompts is supplied; if LLM-based evaluation correlates poorly, retrieved memories will reinforce rather than correct errors, rendering the evolution loop non-functional.
Authors: We agree that the manuscript would benefit from explicit documentation of the evaluation mechanism. MemoGen's agent employs LLM-based scoring and lesson extraction via structured prompts that output both scalar scores and textual feedback; these prompts were omitted from the initial submission. In revision we will include the full prompt templates in an appendix and add a correlation study with human judgments on 50 relational/knowledge-intensive prompts, reporting agreement statistics. This directly addresses the risk of error reinforcement. revision: yes
-
Referee: [Abstract] Abstract: the claim of surpassing Nano Banana Pro and GPT-Image-1 on WISE and Mind-Bench after two rounds is presented without any description of evaluation procedure, exact metrics, data splits, number of runs, or statistical significance testing. This information is load-bearing for the central empirical claim and must be supplied before the result can be assessed.
Authors: We acknowledge that the abstract and experimental section lack these protocol details. The reported results follow the official WISE and Mind-Bench evaluation pipelines using their published metrics; experiments were run three times with different random seeds, and we will report means, standard deviations, and statistical significance (paired t-tests) in the revised manuscript. Data splits are exactly those released with the benchmarks. revision: yes
Circularity Check
No circularity: empirical framework without derivations or self-referential reductions
full rationale
The paper describes MemoGen as a training-free agentic framework that infers requirements, evaluates outputs, stores memories, and retrieves them across rounds to improve generations on benchmarks like WISE and Mind-Bench. No equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or self-citations appear in the provided text. The central result is an empirical claim of improvement after two rounds on an open-source backbone, which does not reduce to its own inputs by construction and remains independent of any internal derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing text-to-image generators can be prompted and evaluated by an external agent without internal parameter changes.
invented entities (1)
-
Experience memory store
no independent evidence
Reference graph
Works this paper leans on
-
[1]
WIT:Wikipedia-basedimagetextdatasetformultimodal multilingualmachinelearning
K. Srinivasan, K. Raman, J. Chen, M. Bendersky, and M. Na- jork,“WIT:Wikipedia-basedimagetextdatasetformultimodal multilingualmachinelearning”,inProceedingsofthe44thInter- nationalACMSIGIRConferenceonResearchandDevelopment inInformationRetrieval,2021,pp.2443–2449
2021
-
[2]
Re-imagen: Retrieval- augmented text-to-image generator.arXiv preprint arXiv:2209.14491, 2022
W. Chen, H. Hu, C. Saharia, and W. W. Cohen, “Re-imagen: Retrieval-augmentedtext-to-imagegenerator”,arXivpreprint arXiv:2209.14491,2022
-
[3]
Traininglanguagemodelstofollowinstruc- tionswithhumanfeedback
L.Ouyangetal.,“Traininglanguagemodelstofollowinstruc- tionswithhumanfeedback”,Advancesinneuralinformation processingsystems,vol.35,pp.27730–27744,2022
2022
-
[4]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Om- mer,High-resolutionimagesynthesiswithlatentdiffusionmodels, 2022
2022
-
[5]
Saharia et al.,Photorealistic text-to-image diffusion models withdeeplanguageunderstanding,2022
C. Saharia et al.,Photorealistic text-to-image diffusion models withdeeplanguageunderstanding,2022
2022
-
[6]
kNN-Diffusion:Imagegenerationvialarge- scaleretrieval
S.Sheyninetal.,“kNN-Diffusion:Imagegenerationvialarge- scaleretrieval”,arXivpreprintarXiv:2204.02849,2022
-
[7]
J.Yuetal.,Scalingautoregressivemodelsforcontent-richtext-to- imagegeneration,2022
2022
-
[8]
J.Betkeretal.,Improvingimagegenerationwithbettercaptions, https://cdn.openai.com/papers/dall-e-3.pdf, Accessed: 2026-05-21,2023
2026
-
[9]
Bernstein,Generative agents: Interactive simulacra of human behavior,2023
J.S.Park,J.C.O’Brien,C.J.Cai,M.R.Morris,P.Liang,andM.S. Bernstein,Generative agents: Interactive simulacra of human behavior,2023
2023
-
[10]
D.Podelletal.,Sdxl:Improvinglatentdiffusionmodelsforhigh- resolutionimagesynthesis,2023
2023
-
[11]
Reflexion: Language Agents with Verbal Reinforcement Learning
N.Shinn,F.Cassano,A.Gopinath,K.Narasimhan,andS.Yao, “Reflexion:Languageagentswithverbalreinforcementlearn- ing”,arXivpreprintarXiv:2303.11366,2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G.Wangetal.,“Voyager:Anopen-endedembodiedagentwith largelanguagemodels”,arXivpreprintarXiv:2305.16291,2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Retrieval-augmentedmultimodallanguage modeling
M.Yasunagaetal.,“Retrieval-augmentedmultimodallanguage modeling”,inInternationalConferenceonMachineLearning, 2023
2023
-
[14]
H.Ye,J.Zhang,S.Liu,X.Han,andW.Yang,Ip-adapter:Text compatible image prompt adapter for text-to-image diffusion models,2023
2023
-
[15]
L.Zhang,A.Rao,andM.Agrawala,Addingconditionalcontrol totext-to-imagediffusionmodels,2023
2023
-
[16]
Black Forest Labs,FLUX.1, https://github.com/black-forest- labs/flux,Accessed:2026-05-21,2024
2026
-
[17]
Sato: Stable text-to-motion framework
W. Chen et al., “Sato: Stable text-to-motion framework”, in Proceedingsofthe32ndACMInternationalConferenceonMulti- media,2024,pp.6989–6997.doi:10.1145/3664647.3681034
-
[18]
Y.Liangetal.,Richhumanfeedbackfortext-to-imagegeneration, 2024
2024
-
[19]
Mou et al.,T2i-adapter: Learning adapters to dig out more controllableabilityfortext-to-imagediffusionmodels,2024
C. Mou et al.,T2i-adapter: Learning adapters to dig out more controllableabilityfortext-to-imagediffusionmodels,2024
2024
-
[20]
StabilityAI,Stablediffusion3.5large,https://stability.ai/news- updates/introducing-stable-diffusion-3-5,Accessed:2026-05- 21,2024
2026
-
[21]
co/stabilityai/stable-diffusion-3.5-medium,Accessed:2026-05- 21,2024
StabilityAI,Stablediffusion3.5medium,https://huggingface. co/stabilityai/stable-diffusion-3.5-medium,Accessed:2026-05- 21,2024
2026
-
[22]
Z.Wang,A.Li,Z.Li,andX.Liu,Genartist:Multimodalllmas anagentforunifiedimagegenerationandediting,2024
2024
-
[23]
Yang et al.,Idea2img: Iterative self-refinement with gpt- 4v(ision)forautomaticimagedesignandgeneration,2024
Z. Yang et al.,Idea2img: Iterative self-refinement with gpt- 4v(ision)forautomaticimagedesignandgeneration,2024
2024
-
[24]
BlackForestLabs,FLUX.1Kontext,https://bfl.ai/models/flux- kontext,Accessed:2026-05-21,May2025
2026
-
[25]
BlackForestLabs,FLUX.2[max],https://bfl.ai/blog,Accessed: 2026-05-21,Dec.2025
2026
-
[26]
BlackForestLabs,FLUX.2[pro],https://bfl.ai/blog,Accessed: 2026-05-21,Nov.2025
2026
-
[27]
Black Forest Labs and Krea AI,FLUX.1 Krea, https://bfl.ai/ blog/flux-1-krea-dev,Accessed:2026-05-21,2025
2026
-
[28]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
H.Caietal.,“Z-Image:Anefficientimagegenerationfounda- tion model with single-stream diffusion transformer”,arXiv preprintarXiv:2511.22699,2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
C.-Y.Chen,M.Shi,G.Zhang,andH.Shi,T2i-copilot:Atraining- freemulti-agenttext-to-imagesystemforenhancedpromptinter- pretationandinteractivegeneration,2025
2025
-
[30]
Ant:Adaptiveneuraltemporal-awaretext-to- motionmodel
W.Chenetal.,“Ant:Adaptiveneuraltemporal-awaretext-to- motionmodel”,inProceedingsofthe33rdACMInternational ConferenceonMultimedia,2025,pp.9852–9861.doi:10.1145/ 3746027.3755168
-
[31]
Chen et al.,Free-t2m:Robusttext-to-motiongenerationfor humanoidrobotsviafrequency-domain,2025
W. Chen et al.,Free-t2m:Robusttext-to-motiongenerationfor humanoidrobotsviafrequency-domain,2025
2025
-
[32]
Emerging Properties in Unified Multimodal Pretraining
C. Deng et al., “Emerging properties in unified multimodal pretraining”,arXivpreprintarXiv:2505.14683,2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
GoogleDeepMind,Gemini3proimage:Nanobananapro,https: //deepmind.google/models/gemini-image/pro/, Accessed: 2026-05-21,2025
2026
-
[34]
Google DeepMind,Gemini image: Nano banana, https:// deepmind.google/models/gemini-image/, Accessed: 2026- 05-21,2025
2026
-
[35]
arXiv preprint arXiv:2512.05112 (2025)
D.Jiangetal.,“DraCo:DraftasCoTfortext-to-imagepreview andrareconceptgeneration”,arXivpreprintarXiv:2512.05112, 2025
-
[36]
M.Ningetal.,Dctdiff:Intriguingpropertiesofimagegenerative modelinginthedctspace,2025
2025
-
[37]
Y.Niuetal.,WISE:Aworldknowledge-informedsemanticeval- uationfortext-to-imagegeneration,2025
2025
-
[38]
OpenAI,GPTImage1.5, https://platform.openai.com/docs/ models/gpt-image-1.5,Accessed:2026-05-21,Dec.2025
2026
-
[39]
OpenAI,GPT-5.5, https://openai.com/index/gpt-5-5/, Ac- cessed:2026-06-02,2025
2026
-
[40]
OpenAI,Introducingourlatestimagegenerationmodelintheapi, https://openai.com/index/image-generation-api/,Accessed: 2026-05-21,Apr.2025
2026
-
[41]
Serper,SerperAPI,https://serper.dev/,Accessed:2026-06-02, 2025
2026
-
[42]
B.Tian,W.Chen,Z.Li,S.Lai,J.Wu,andY.Yue,Text2weight: Bridging natural language and neural network weight spaces, https://doi.org/10.1145/3746027.3755441,2025
-
[43]
X.Wanetal.,Maestro:Self-improvingtext-to-imagegeneration viaagentorchestration,2025
2025
-
[44]
C. Wu et al., “Qwen-image technical report”,arXiv preprint arXiv:2508.02324,2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Echo-4o: Harnessing the power of GPT-4o syn- theticimagesforimprovedimagegeneration
J. Ye et al., “Echo-4o: Harnessing the power of GPT-4o syn- theticimagesforimprovedimagegeneration”,arXivpreprint arXiv:2508.09987,2025
-
[46]
10–11 MemoGen: Can Past Experience Improve Future Text-to-Image Generation?
S.Chenetal.,Genevolve:Self-evolvingimagegenerationagents viatool-orchestratedvisualexperiencedistillation,2026. 10–11 MemoGen: Can Past Experience Improve Future Text-to-Image Generation?
2026
-
[47]
Towards betterevaluationmetricsfortext-to-motiongeneration
W.Chen,H.Jia,K.Yu,S.Lai,L.Wang,andY.Yue,“Towards betterevaluationmetricsfortext-to-motiongeneration”,inThe SecondInternationalWorkshoponTransformativeInsightsin MultifacetedEvaluationatTheWebConference2026,2026
2026
-
[48]
Gen-Searcher: Reinforcing Agentic Search for Image Generation
K. Feng et al., “Gen-searcher: Reinforcing agentic search for imagegeneration”,arXivpreprintarXiv:2603.28767,2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Mind-Brush: Integrating agentic cognitive search and reasoning into image generation
J. He et al., “Mind-Brush: Integrating agentic cognitive search and reasoning into image generation”,arXiv preprint arXiv:2602.01756,2026
-
[50]
He et al.,Gems: Agent-native multimodal generation with memoryandskills,2026
Z. He et al.,Gems: Agent-native multimodal generation with memoryandskills,2026
2026
-
[51]
Genagent: Scaling text-to-image gener- ation via agentic multimodal reasoning
K. Jiang et al., “Genagent: Scaling text-to-image gener- ation via agentic multimodal reasoning”,arXiv preprint arXiv:2601.18543,2026
-
[52]
Kou et al.,Think-then-generate: Reasoning-aware text-to- imagediffusionwithllmencoders,2026
S. Kou et al.,Think-then-generate: Reasoning-aware text-to- imagediffusionwithllmencoders,2026
2026
-
[53]
H. Li, W. Chen, L. Wang, S. Liang, H. Jia, and Y. Yue,Oracle noise:Fastersemanticsphericalalignmentforinterpretablelatent optimization,2026
2026
-
[54]
H.Lietal.,Deltascorematters!spatialadaptivemultiguidance indiffusionmodels,2026
2026
-
[55]
S. Mun, S. Cho, and C. Kim,Epic: Efficient predicate-guided inference-timecontrolforcompositionaltext-to-imagegeneration, 2026
2026
-
[56]
H.Wang,C.Wei,W.Ren,J.Liu,F.Lin,andW.Chen,Rational- rewards:Reasoningrewardsscalevisualgenerationbothtraining andtesttime,2026
2026
-
[57]
S.Wu,M.Sun,W.Wang,Y.Wang,andJ.Liu,Visualprompter: Semantic-awarepromptoptimizationwithvisualfeedbackfor text-to-imagesynthesis,2026
2026
-
[58]
Zhang et al.,Rewardharness: Self-evolving agentic post- training,2026
Y. Zhang et al.,Rewardharness: Self-evolving agentic post- training,2026. 11–11
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.