Beyond "To whom it may concern": Tailoring Machine Translation to Audience and Intent
Pith reviewed 2026-06-28 10:20 UTC · model grok-4.3
The pith
Explicit instructions enable LLMs to tailor machine translations to audience, tone, and intent, with gains over few-shot examples or context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
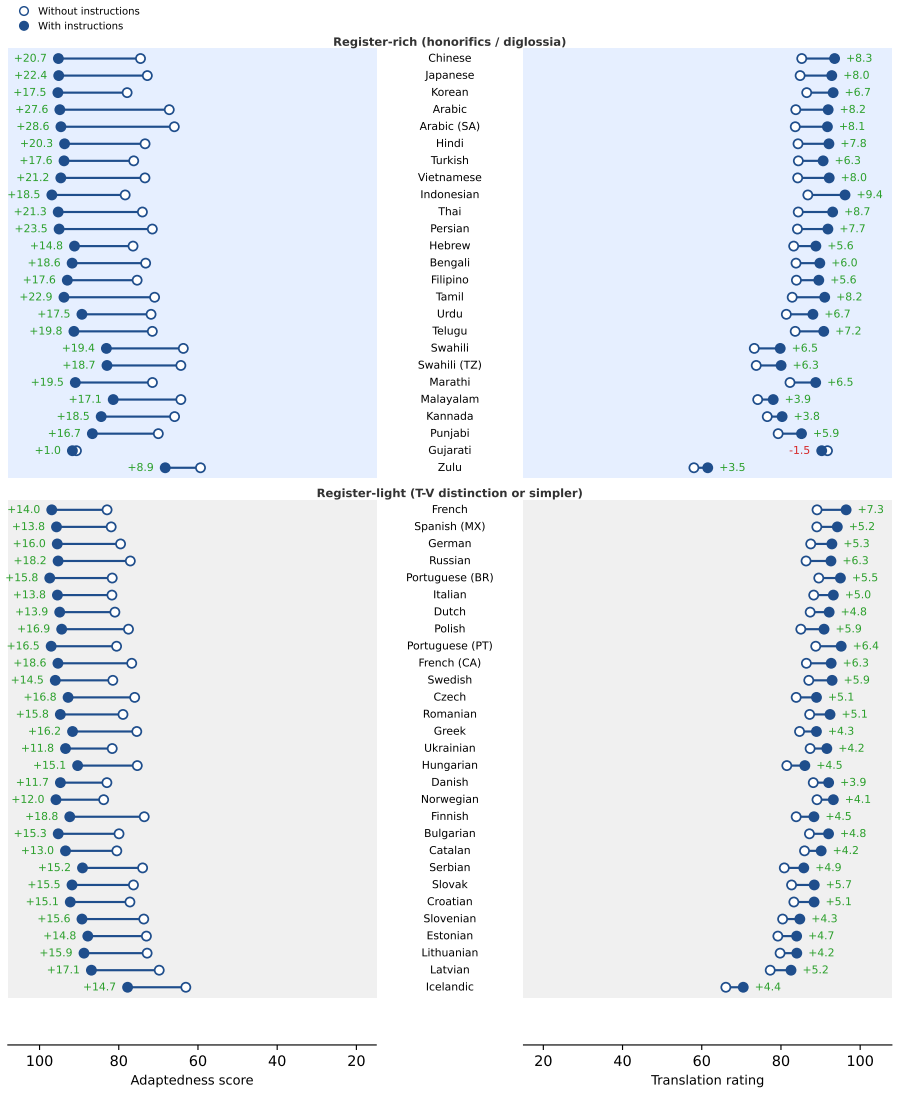
Purpose-adapted machine translation is a measurable capability of large language models. Supplying explicit instructions that name the target audience, tone, and intent produces substantially more adapted translations than treating the task as a fixed source-to-target mapping. This advantage holds across 50 languages and eight domains, exceeds the benefit obtained from semantically matched few-shot examples or paragraph-level context, and is largest on informal domains, with larger models, and in higher-resource languages. Traditional metrics do not track adaptation quality and frequently penalize adapted outputs. Models can also self-generate instructions from document context, closing up t
What carries the argument
Explicit instructions specifying audience, tone, and communicative intent supplied together with the source text.
If this is right
- Adaptedness gains are larger on informal domains such as conversation and social media than on formal domains.
- Larger model sizes and higher-resource languages obtain bigger improvements from explicit instructions.
- Instructions produce higher adaptedness than semantically matched few-shot examples or paragraph-level context.
- Self-generated instructions from surrounding document context recover up to 80 percent of the adaptedness benefit of curated instructions.
Where Pith is reading between the lines
- Interfaces for translation tools could prompt users for audience and intent details as a default step.
- New evaluation benchmarks focused on adaptedness would be needed to avoid under-valuing purpose-aware outputs.
- Professional domains such as marketing or legal translation could integrate purpose specification to reduce post-editing effort.
- The same instruction-based approach might apply to other text-generation tasks where reader expectations vary.
Load-bearing premise
The human or automatic judgments used to score adaptedness reliably reflect communicative success rather than annotator bias or mismatch with actual reader needs across the tested languages and domains.
What would settle it
A controlled user study in which readers complete a task using the paper's adapted translations versus non-adapted baselines and show no measurable difference in comprehension, engagement, or error rate.
Figures






read the original abstract
Translation quality depends on purpose: the same source text demands different translations depending on audience, tone, and communicative intent. Yet MT models and metrics treat translation as a fixed mapping from source to target. LLMs enable users to explicitly specify purpose alongside source text, yet this capability has not been evaluated at scale. We introduce a systematic evaluation of purpose-driven MT across 50 languages, 5 model sizes and 8 text domains. We find that (1) explicit instructions substantially improve translation adaptedness, with larger gains on informal domains (conversation, social media), for larger model sizes and for higher-resource languages; (2) instructions outperform semantically-matched few-shot examples and paragraph-level context; (3) traditional MT metrics fail to capture adaptation quality, often penalizing adapted translations; (4) when curated instructions are unavailable, models can self-generate them from surrounding document context, closing up to 80% of the adaptedness gap to curated instructions. Our results establish that purpose-adapted MT is a viable and measurable capability of LLMs, while highlighting the need for purpose-aware metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates purpose-driven machine translation with LLMs by providing explicit instructions on audience, tone, and intent. It conducts a large-scale study across 50 languages, 5 model sizes, and 8 domains, claiming that (1) explicit instructions improve adaptedness more than few-shot examples or paragraph context, with larger gains for informal domains, larger models, and high-resource languages; (2) standard MT metrics often penalize well-adapted outputs; and (3) models can self-generate instructions from document context, closing up to 80% of the gap to curated instructions.
Significance. If the adaptedness measurements prove reliable, the work demonstrates a scalable capability for context-sensitive MT that aligns better with real communicative needs than fixed-reference approaches. The breadth of the evaluation (50 languages, multiple domains and sizes) provides useful empirical grounding, and the observation that conventional metrics can penalize adaptations is a constructive signal for future metric research. The self-generation result further suggests practical deployment paths when expert instructions are unavailable.
major comments (2)
- [§4–5] Evaluation protocol (§4–5): The central claims rest on judgments of 'adaptedness,' yet the manuscript provides insufficient detail on the exact rating protocol, number of annotators per item, inter-annotator agreement, or statistical significance tests for the reported gains. This information is load-bearing because any systematic bias in the judgments would directly affect the comparative claims about instructions versus few-shot or context.
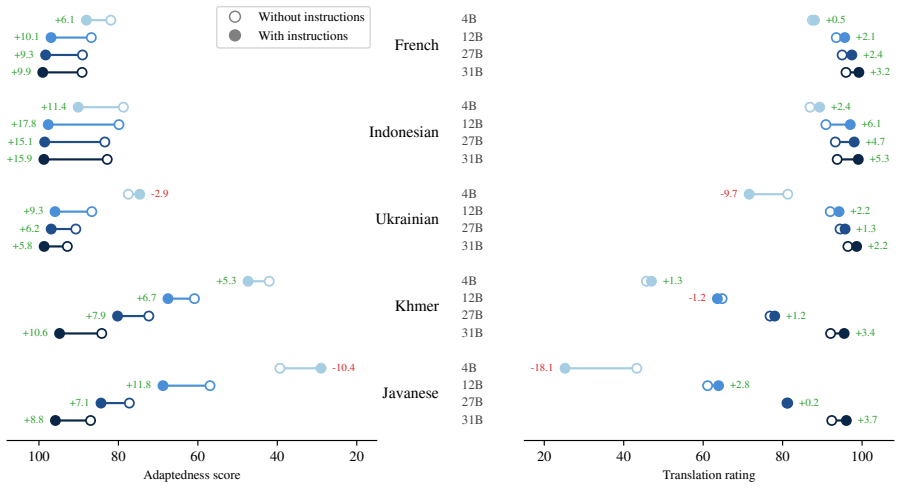
- [Table 2 or equivalent] Results on metric mismatch (Table 2 or equivalent): The claim that traditional metrics 'often penalize' adapted translations requires the actual correlation or delta values between adaptedness scores and BLEU/COMET/etc. to be shown with confidence intervals; without these numbers the assertion remains directional and hard to quantify for the 50-language setting.
minor comments (2)
- [Abstract and §5] The abstract states directional findings without effect sizes; the main text should ensure every key comparison (instructions vs. few-shot, self-generated vs. curated) is accompanied by a compact table of mean adaptedness scores and significance markers.
- [§6] Clarify whether the 80% gap-closure figure is an average across all languages/domains or a selected subset; report the per-condition breakdown.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will incorporate clarifications and additional quantitative results in the revised version to strengthen the presentation of the evaluation protocol and metric analyses.
read point-by-point responses
-
Referee: [§4–5] Evaluation protocol (§4–5): The central claims rest on judgments of 'adaptedness,' yet the manuscript provides insufficient detail on the exact rating protocol, number of annotators per item, inter-annotator agreement, or statistical significance tests for the reported gains. This information is load-bearing because any systematic bias in the judgments would directly affect the comparative claims about instructions versus few-shot or context.
Authors: We agree that the current description of the human evaluation protocol in §4–5 lacks sufficient detail for full reproducibility and assessment of reliability. In the revision we will expand this section to specify: the exact 5-point adaptedness rating scale and annotator instructions; that each item was rated by three independent annotators; Krippendorff’s alpha values for inter-annotator agreement (reported per domain and overall); and the statistical tests used (paired t-tests with Bonferroni correction) together with p-values for the key comparisons between instruction, few-shot, and context conditions. revision: yes
-
Referee: [Table 2 or equivalent] Results on metric mismatch (Table 2 or equivalent): The claim that traditional metrics 'often penalize' adapted translations requires the actual correlation or delta values between adaptedness scores and BLEU/COMET/etc. to be shown with confidence intervals; without these numbers the assertion remains directional and hard to quantify for the 50-language setting.
Authors: We accept that the metric-mismatch claim would be stronger with explicit quantitative support. We will add a dedicated subsection (or expanded Table 2) that reports, across all 50 languages and 8 domains: (i) Pearson and Spearman correlations between human adaptedness scores and each automatic metric (BLEU, COMET, etc.), and (ii) mean deltas in metric scores between adapted and baseline outputs, each accompanied by 95% bootstrap confidence intervals. These numbers will directly quantify the extent and consistency of the penalization effect. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is a large-scale empirical evaluation of instruction-driven MT adaptation across 50 languages, 8 domains and multiple model sizes. It reports comparative results on adaptedness using human and automatic judgments, with no equations, parameter fitting, derivations or self-referential definitions present. All load-bearing claims rest on external measurements rather than reducing to inputs by construction. No self-citation chains or ansatzes are invoked to justify core results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pierre Andrews, Mikel Artetxe, Mariano Coria Meglioli, Marta R. Costa-juss \`a , Joe Chuang, David Dale, Mark Duppenthaler, Nathanial Paul Ekberg, Cynthia Gao, Daniel Edward Licht, Jean Maillard, Alexandre Mourachko, Christophe Ropers, Safiyyah Saleem, Eduardo S \'a nchez, Ioannis Tsiamas, Arina Turkatenko, Albert Ventayol-Boada, and Shireen Yates. 2025. ...
-
[2]
Marine Carpuat, Omri Asscher, Kalika Bali, Luisa Bentivogli, Fr \'e d \'e ric Blain, Lynne Bowker, Monojit Choudhury, Hal Daum \'e III, Kevin Duh, Ge Gao, Alvin Grissom II, Marzena Karpinska, Elaine C. Khoong, William D. Lewis, Andr \'e F. T. Martins, Mary Nurminen, Douglas W. Oard, Maja Popovic, Michel Simard, and Fran c ois Yvon. 2025. https://doi.org/1...
-
[3]
Keita, Sudhamoy DebBarma, Ali Kuzhuget, David Anugraha, and 5 others
Isaac Caswell, Elizabeth Nielsen, Jiaming Luo, Colin Cherry, Geza Kovacs, Hadar Shemtov, Partha Talukdar, Dinesh Tewari, Baba Mamadi Diane, Djibrila Diane, Solo Farabado Ciss \'e , Koulako Moussa Doumbouya, Edoardo Ferrante, Alessandro Guasoni, Christopher Homan, Mamadou K. Keita, Sudhamoy DebBarma, Ali Kuzhuget, David Anugraha, and 5 others. 2025. https:...
-
[4]
Ritvik Choudhary, Rem Hida, Masaki Hamada, Hayato Futami, and Toshiyuki Sekiya. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1324 Exploring context strategies in LLM s for discourse-aware machine translation . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 24382--24391, Suzhou, China. Association for Computational...
-
[5]
Daniel Deutsch, Eleftheria Briakou, Isaac Rayburn Caswell, Mara Finkelstein, Rebecca Galor, Juraj Juraska, Geza Kovacs, Alison Lui, Ricardo Rei, Jason Riesa, Shruti Rijhwani, Parker Riley, Elizabeth Salesky, Firas Trabelsi, Stephanie Winkler, Biao Zhang, and Markus Freitag. 2025. https://doi.org/10.18653/v1/2025.findings-acl.634 WMT 24++: Expanding the la...
-
[6]
Gemini Team . 2025. Gemini 3 flash. https://deepmind.google/models/gemini/flash/. Google DeepMind
2025
-
[7]
Gemma Team . 2025. https://arxiv.org/abs/2503.19786 Gemma 3 technical report . Preprint, arXiv:2503.19786
Pith/arXiv arXiv 2025
-
[8]
Naman Goyal, Cynthia Gao, Vishrav Chaudhary, Peng-Jen Chen, Guillaume Wenzek, Da Ju, Sanjana Krishnan, Marc ' Aurelio Ranzato, Francisco Guzm \'a n, and Angela Fan. 2022. https://doi.org/10.1162/tacl_a_00474 The F lores-101 evaluation benchmark for low-resource and multilingual machine translation . Transactions of the Association for Computational Lingui...
-
[9]
and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr \'e F
Nuno M. Guerreiro, Ricardo Rei, Daan van Stigt, Luisa Coheur, Pierre Colombo, and Andr \'e F. T. Martins. 2024. https://doi.org/10.1162/tacl_a_00683 x COMET : Transparent machine translation evaluation through fine-grained error detection . Transactions of the Association for Computational Linguistics, 12:979--995
-
[10]
Sui He. 2024. https://aclanthology.org/2024.eamt-1.27/ Prompting C hat GPT for translation: A comparative analysis of translation brief and persona prompts . In Proceedings of the 25th Annual Conference of the European Association for Machine Translation (Volume 1), pages 316--326, Sheffield, UK. European Association for Machine Translation (EAMT)
2024
-
[11]
Juliane House. 2015. Translation Quality Assessment: Past and Present. Routledge, London
2015
-
[12]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. https://arxiv.org/abs/2106.09685 Lora: Low-rank adaptation of large language models . Preprint, arXiv:2106.09685
Pith/arXiv arXiv 2021
-
[13]
Yuchen Eleanor Jiang, Tianyu Liu, Shuming Ma, Dongdong Zhang, Mrinmaya Sachan, and Ryan Cotterell. 2023. https://doi.org/10.18653/v1/2023.acl-long.435 Discourse-centric evaluation of document-level machine translation with a new densely annotated parallel corpus of novels . In Proceedings of the 61st Annual Meeting of the Association for Computational Lin...
-
[14]
Juraj Juraska, Daniel Deutsch, Mara Finkelstein, and Markus Freitag. 2024. https://doi.org/10.18653/v1/2024.wmt-1.35 M etric X -24: The G oogle submission to the WMT 2024 metrics shared task . In Proceedings of the Ninth Conference on Machine Translation, pages 492--504, Miami, Florida, USA. Association for Computational Linguistics
-
[15]
Yoko Kayano and Saku Sugawara. 2025. https://doi.org/10.18653/v1/2025.wmt-1.7 Specification-aware machine translation and evaluation for purpose alignment . In Proceedings of the Tenth Conference on Machine Translation, pages 113--141, Suzhou, China. Association for Computational Linguistics
-
[16]
Tom Kocmi, Vil \'e m Zouhar, Eleftherios Avramidis, Roman Grundkiewicz, Marzena Karpinska, Maja Popovi \'c , Mrinmaya Sachan, and Mariya Shmatova. 2024. https://doi.org/10.18653/v1/2024.wmt-1.131 Error span annotation: A balanced approach for human evaluation of machine translation . In Proceedings of the Ninth Conference on Machine Translation, pages 144...
-
[17]
Alon Lavie, Greg Hanneman, Sweta Agrawal, Diptesh Kanojia, Chi-Kiu Lo, Vil \'e m Zouhar, Frederic Blain, Chrysoula Zerva, Eleftherios Avramidis, Sourabh Deoghare, Archchana Sindhujan, Jiayi Wang, David Ifeoluwa Adelani, Brian Thompson, Tom Kocmi, Markus Freitag, and Daniel Deutsch. 2025. https://doi.org/10.18653/v1/2025.wmt-1.24 Findings of the WMT 25 sha...
-
[18]
Sinuo Liu, Chenyang Lyu, Minghao Wu, Longyue Wang, Weihua Luo, Kaifu Zhang, and Zifu Shang. 2025. https://arxiv.org/abs/2503.10351 New trends for modern machine translation with large reasoning models . Preprint, arXiv:2503.10351
arXiv 2025
-
[19]
Bolei Ma, Yuting Li, Wei Zhou, Ziwei Gong, Yang Janet Liu, Katja Jasinskaja, Annemarie Friedrich, Julia Hirschberg, Frauke Kreuter, and Barbara Plank. 2025. https://doi.org/10.18653/v1/2025.acl-long.425 Pragmatics in the era of large language models: A survey on datasets, evaluation, opportunities and challenges . In Proceedings of the 63rd Annual Meeting...
-
[20]
Raphael Merx, Ad \'e rito Jos \'e Guterres Correia, Hanna Suominen, and Ekaterina Vylomova. 2025 a . https://doi.org/10.18653/v1/2025.loresmt-1.7 Low-resource machine translation: what for? who for? an observational study on a dedicated tetun language translation service . In Proceedings of the Eighth Workshop on Technologies for Machine Translation of Lo...
-
[21]
Raphael Merx, Hanna Suominen, Trevor Cohn, and Ekaterina Vylomova. 2025 b . https://doi.org/10.18653/v1/2025.wmt-1.8 O pen WHO : A document-level parallel corpus for health translation in low-resource languages . In Proceedings of the Tenth Conference on Machine Translation, pages 142--160, Suzhou, China. Association for Computational Linguistics
-
[22]
NLLB Team , Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, and 20 others. 2022. https://arxiv.org/abs/2207.04672 No languag...
Pith/arXiv arXiv 2022
-
[23]
Christiane Nord. 1994. https://aclanthology.org/1994.eamt-1.3/ The importance of functional markers in (human) translation . In Machine Translation and Translation Theory, Hildesheim, Germany. Mouton de Gruyter
1994
-
[24]
Maja Popovi \'c . 2015. https://doi.org/10.18653/v1/W15-3049 chr F : character n-gram F -score for automatic MT evaluation . In Proceedings of the Tenth Workshop on Statistical Machine Translation, pages 392--395, Lisbon, Portugal. Association for Computational Linguistics
-
[25]
Qwen Team . 2026. https://qwen.ai/blog?id=qwen3.5 Qwen3.5 . Blog post, 16 February 2026
2026
-
[26]
Hala Sharkas. 2025. https://doi.org/10.24093/awejtls/vol9no2.9 Exploring the role of translation brief elements in prompts to large language models . Arab World English Journal For Translation and Literary Studies, 9(2):139--153
-
[27]
Yirong Sun, Dawei Zhu, Yanjun Chen, Erjia Xiao, Xinghao Chen, and Xiaoyu Shen. 2025. https://arxiv.org/abs/2410.20941 Fine-grained and multi-dimensional metrics for document-level machine translation . Preprint, arXiv:2410.20941
arXiv 2025
-
[28]
Longyue Wang, Chenyang Lyu, Tianbo Ji, Zhirui Zhang, Dian Yu, Shuming Shi, and Zhaopeng Tu. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.1036 Document-level machine translation with large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 16646--16661, Singapore. Association for Computat...
-
[29]
Di Wu, Seth Aycock, and Christof Monz. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1031 Please translate again: Two simple experiments on whether human-like reasoning helps translation . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20424--20440, Suzhou, China. Association for Computational Linguistics
-
[30]
Masaru Yamada. 2023. https://aclanthology.org/2023.mtsummit-users.19/ Optimizing machine translation through prompt engineering: An investigation into C hat GPT ' s customizability . In Proceedings of Machine Translation Summit XIX, Vol. 2: Users Track, pages 195--204, Macau SAR, China. Asia-Pacific Association for Machine Translation
2023
-
[31]
Zekun Yuan, Yangfan Ye, Xiaocheng Feng, Baohang Li, Qichen Hong, Yunfei Lu, Dandan Tu, and Bing Qin. 2026. https://arxiv.org/abs/2604.24361 Culture-aware machine translation in large language models: Benchmarking and investigation . Preprint, arXiv:2604.24361
Pith/arXiv arXiv 2026
-
[32]
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, and Lei Li. 2024. https://doi.org/10.18653/v1/2024.findings-naacl.176 Multilingual machine translation with large language models: Empirical results and analysis . In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2765--2781, Mexico ...
-
[33]
Vil \'e m Zouhar, Pinzhen Chen, Tsz Kin Lam, Nikita Moghe, and Barry Haddow. 2024. https://doi.org/10.18653/v1/2024.wmt-1.121 Pitfalls and outlooks in using COMET . In Proceedings of the Ninth Conference on Machine Translation, pages 1272--1288, Miami, Florida, USA. Association for Computational Linguistics
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.