A Negative Result on Cross-Model Activation Transfer in a Pythia Multi-Hop Setting
Pith reviewed 2026-06-28 09:51 UTC · model grok-4.3
The pith
A linear translation aligns activations between Pythia models at high similarity, but injecting them does not improve the receiver's multi-hop reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
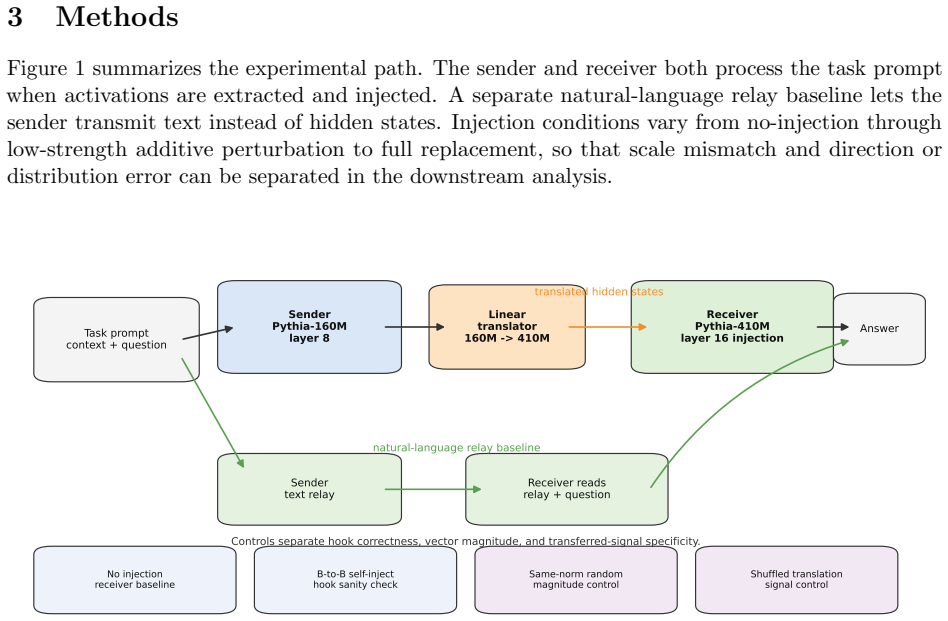
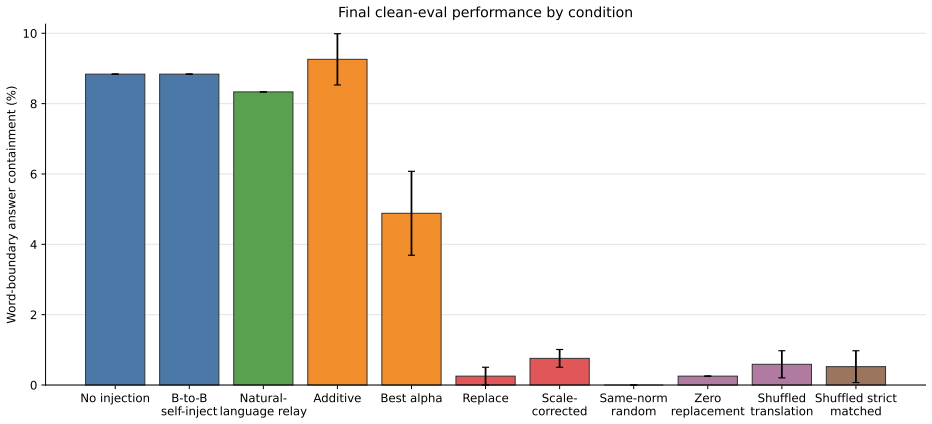
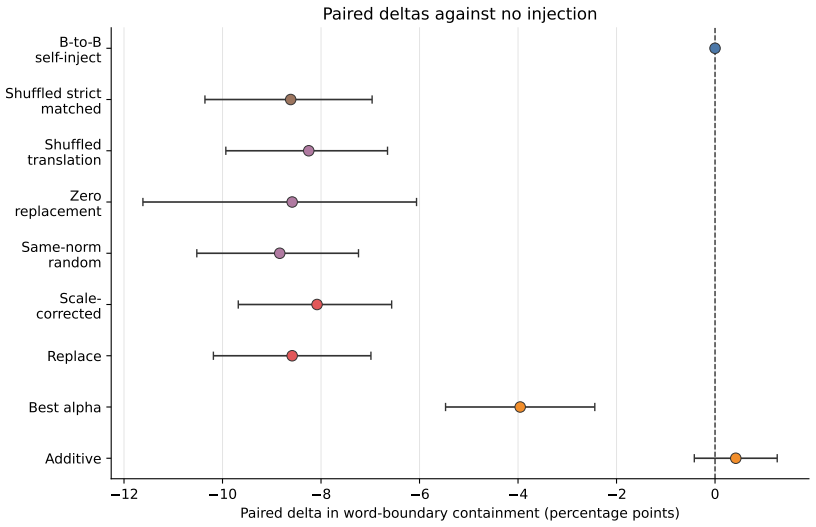
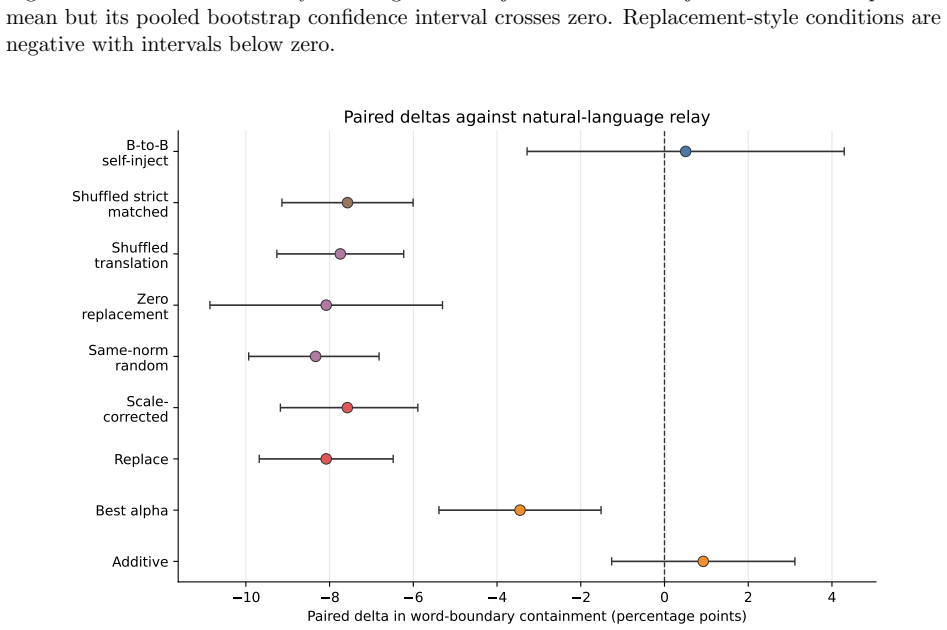
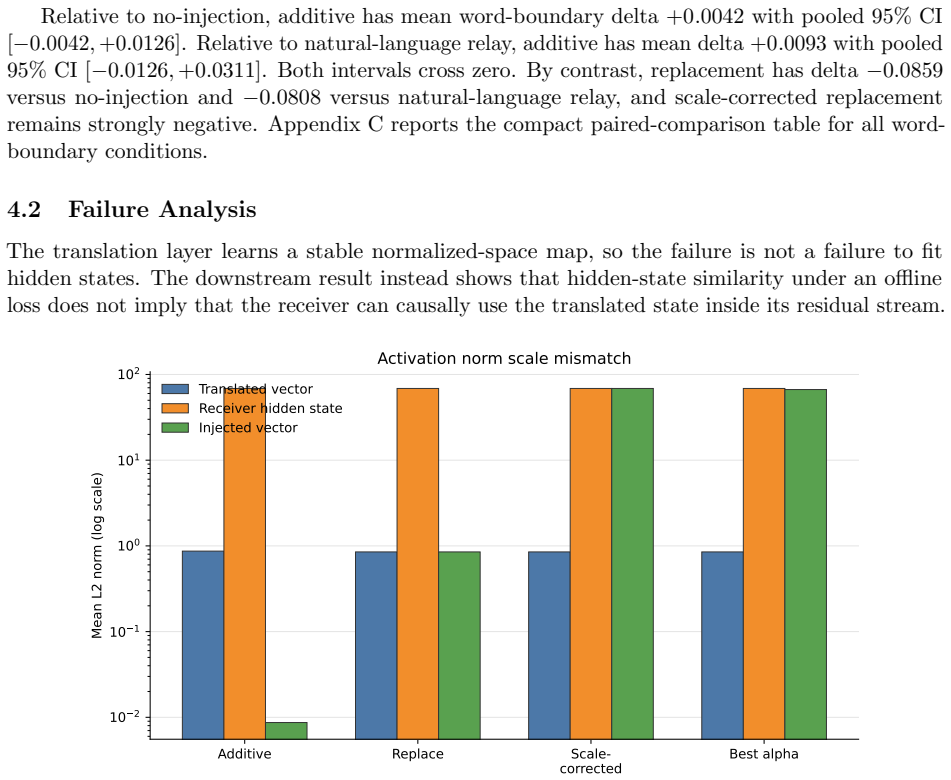
In this controlled Pythia-160M to Pythia-410M multi-hop reasoning setting, a linear translation layer learns a strong normalized-space map between sender and receiver hidden states, with normalized cosine similarity near 0.97 across seeds. However, when the translated activations are injected into the receiver at inference time, they do not improve downstream answering. Low-strength additive injection remains near the no-injection baseline, with confidence intervals that cross zero. Replacement-style injection is consistently destructive, and rescaling translated vectors to the receiver hidden-state norm does not rescue performance.
What carries the argument
The post-hoc linear translation layer that produces a normalized-space map between sender and receiver hidden states for potential inference-time injection.
If this is right
- Offline representational alignment via linear map is not sufficient for useful causal communication inside the receiver.
- Replacement-style injection is consistently destructive to performance.
- Low-strength additive injection stays near the no-injection baseline.
- Rescaling translated vectors to receiver hidden-state norm does not rescue performance.
Where Pith is reading between the lines
- Activation transfer between models may require joint training of the interface rather than a post-hoc linear bridge.
- Independently trained models may not share compatible internal representations for direct activation exchange even when a linear map exists.
- Alternative interfaces such as non-linear translators or different injection strategies could be tested to see if they enable the channel.
Load-bearing premise
That a post-hoc linear translation layer plus injection at inference time constitutes a valid test of whether an activation-mediated channel can transmit useful intermediate reasoning states.
What would settle it
A statistically significant improvement in multi-hop answering accuracy when translated activations are injected compared to the no-injection baseline.
Figures
read the original abstract
Recent work shows that language models can transmit behavioural traits through hidden signals in generated data during training. We ask whether a different activation-mediated channel is viable: can one language model communicate a useful intermediate reasoning state to another at inference time through a post-hoc linear activation bridge, rather than through a textual or structured-token relay? We test this question in a controlled Pythia-160M to Pythia-410M multi-hop reasoning setting. A linear translation layer learns a strong normalized-space map between sender and receiver hidden states, with normalized cosine similarity near 0.97 across seeds. However, when the translated activations are injected into the receiver at inference time, they do not improve downstream answering. Low-strength additive injection remains near the no-injection baseline, with confidence intervals that cross zero. Replacement-style injection is consistently destructive, and rescaling translated vectors to the receiver hidden-state norm does not rescue performance. The result is therefore a scoped negative result: in this setting, offline representational alignment is not sufficient for useful causal communication inside the receiver.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a scoped negative result on cross-model activation transfer: in a Pythia-160M to Pythia-410M multi-hop reasoning setting, a post-hoc linear translation layer achieves high normalized cosine similarity (~0.97) between sender and receiver hidden states, yet injecting the translated activations at inference time (additive or replacement) fails to improve downstream task performance over the no-injection baseline, with low-strength additive injections yielding confidence intervals that cross zero.
Significance. If the result holds after addressing the points below, it supplies concrete empirical evidence (normalized cosine 0.97, CIs crossing zero) that offline representational alignment via a linear map is insufficient for useful causal communication of intermediate reasoning states through activation injection. This is a useful negative finding for the emerging literature on activation-mediated model interfaces, as it distinguishes high alignment from functional transfer and may steer future work toward joint training or different interfaces rather than post-hoc bridges.
major comments (1)
- [Abstract / experimental setup] The interpretation of the negative injection result as evidence that 'offline representational alignment is not sufficient for useful causal communication' would be strengthened by an intervention inside the sender (e.g., activation patching or mean ablation on the layers whose states are being translated) demonstrating that those particular directions are causally relevant to multi-hop performance. Without such a check, the high alignment could be on non-causal features, rendering the injection failure uninformative about whether an activation channel could transmit useful states. (Abstract and experimental setup sections.)
minor comments (3)
- Provide the exact layer indices and token positions used for activation extraction and injection, as well as dataset size and multi-hop question statistics, to allow replication and assessment of whether the negative result is robust to these choices.
- Clarify how the 'low-strength' additive injection scale was chosen and how the reported confidence intervals were computed (bootstrap? multiple seeds?).
- The abstract states that rescaling to receiver norm 'does not rescue performance'; a brief quantitative comparison of the rescaled vs. unscaled injection results would be helpful.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on strengthening the causal interpretation. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract / experimental setup] The interpretation of the negative injection result as evidence that 'offline representational alignment is not sufficient for useful causal communication' would be strengthened by an intervention inside the sender (e.g., activation patching or mean ablation on the layers whose states are being translated) demonstrating that those particular directions are causally relevant to multi-hop performance. Without such a check, the high alignment could be on non-causal features, rendering the injection failure uninformative about whether an activation channel could transmit useful states. (Abstract and experimental setup sections.)
Authors: We agree that an explicit sender-side causal intervention (activation patching or mean ablation on the relevant layers) would strengthen the claim that the aligned directions carry task-relevant information. The current experiments compute normalized cosine similarity on the actual hidden states produced while the sender executes the multi-hop task, but do not verify that those specific directions are causally implicated in performance. The negative injection result is therefore best read as showing that this particular post-hoc linear bridge fails to produce downstream gains, rather than a general demonstration that offline alignment cannot support causal communication. We will revise the abstract and the experimental-setup section to qualify the conclusion accordingly and to list the absence of sender interventions as a limitation. This is a partial revision. revision: partial
Circularity Check
Empirical negative result on activation injection is self-contained with no circular reduction
full rationale
The paper fits a linear translation layer to maximize normalized cosine similarity between sender and receiver hidden states (reported ~0.97), then performs an independent downstream test of whether additive or replacement injection of the translated activations improves multi-hop answering accuracy relative to no-injection baseline. This performance comparison does not reduce by construction to the fitted alignment metric or to any self-citation; the negative outcome (confidence intervals crossing zero) is an empirical observation outside the fitting objective. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the provided text. The derivation chain is therefore an ordinary empirical intervention study.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear translation layer weights
axioms (1)
- domain assumption A linear map is sufficient to test whether representational alignment enables causal transfer of reasoning states.
Reference graph
Works this paper leans on
-
[1]
Revisiting model stitching to compare neural representations, 2021
Yamini Bansal, Preetum Nakkiran, and Boaz Barak. Revisiting model stitching to compare neural representations, 2021. URLhttps://arxiv.org/abs/2106.07682
arXiv 2021
-
[2]
Eliciting latent predictions from transformers with the tuned lens, 2023
Nora Belrose, Igor Ostrovsky, Lev McKinney, Zach Furman, Logan Smith, Danny Halawi, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens, 2023. URLhttps://arxiv.org/abs/2303.08112
Pith/arXiv arXiv 2023
-
[3]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar Van Der Wal. Pythia: A suite for analyzing large language models across training and scaling. InProceedings of the 40th International ...
2023
-
[4]
Transferring linear features across language models with model stitching
Alan Chen, Jack Merullo, Alessandro Stolfo, and Ellie Pavlick. Transferring linear features across language models with model stitching. InAdvances in Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=Qvvy0X63Fv. Spotlight
2025
-
[5]
Language models transmit behavioural traits through hidden signals in data.Nature, 652:615–620, 2026
Alex Cloud, Minh Le, James Chua, Jan Betley, Anna Sztyber-Betley, S¨ oren Mindermann, Jacob Hilton, Samuel Marks, and Owain Evans. Language models transmit behavioural traits through hidden signals in data.Nature, 652:615–620, 2026. doi: 10.1038/s41586-026-10319-8. URLhttps://doi.org/10.1038/s41586-026-10319-8. 14
-
[6]
Analyzing transformers in embedding space
Guy Dar, Mor Geva, Ankit Gupta, and Jonathan Berant. Analyzing transformers in embedding space. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 16124–16170. Association for Computational Linguistics, 2023. doi: 10.18653/ v1/2023.acl-long.893. URLhttps://aclanthology.org/2023.acl-long.893/
2023
-
[7]
AlphaEdit: Null-space constrained knowledge editing for language models
Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Jie Shi, Xiang Wang, Xiangnan He, and Tat-Seng Chua. AlphaEdit: Null-space constrained knowledge editing for language models. InInternational Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=HvSytvg3Jh. Outstanding Paper Award
2025
-
[8]
Adriano Hernandez, Rumen Dangovski, Peter Y. Lu, and Marin Soljacic. Model stitching: Looking for functional similarity between representations, 2023. URL https://arxiv.org/ abs/2303.11277
arXiv 2023
-
[9]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3519–3529. PMLR, 2019. URLhttps://proceedings.mlr.press/v97/kornblith19a.html
2019
-
[10]
Deep Residual Learning for Image Recognition
Karel Lenc and Andrea Vedaldi. Understanding image representations by measuring their equivariance and equivalence. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition, pages 991–999, 2015. doi: 10.1109/CVPR. 2015.7298701. URL https://openaccess.thecvf.com/content_cvpr_2015/html/Lenc_ Understanding_Image_Representations_2015_...
-
[11]
Locating and editing factual associations in gpt, 2022
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt, 2022. URLhttps://arxiv.org/abs/2202.05262
Pith/arXiv arXiv 2022
-
[12]
Mass- editing memory in a transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass- editing memory in a transformer. InInternational Conference on Learning Representations,
-
[13]
URLhttps://openreview.net/forum?id=MkbcAHIYgyS
-
[14]
In-context learning and induction heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
2022
-
[15]
To forget or not? towards practical knowledge unlearning for large language models
Bozhong Tian, Xiaozhuan Liang, Siyuan Cheng, Qingbin Liu, Mengru Wang, Dianbo Sui, Xi Chen, Huajun Chen, and Ningyu Zhang. To forget or not? towards practical knowledge unlearning for large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, 2024. URL https://aclanthology.org/2024.findings-emnlp. 82/
2024
-
[16]
Vazquez, Ulisse Mini, and Monte MacDiarmid
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering, 2023. URLhttps://arxiv.org/abs/2308.10248. 15
Pith/arXiv arXiv 2023
-
[17]
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small, 2022
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small, 2022. URLhttps://arxiv.org/abs/2211.00593
Pith/arXiv arXiv 2022
-
[18]
Towards best practices of activation patching in language models: Metrics and methods, 2023
Fred Zhang and Neel Nanda. Towards best practices of activation patching in language models: Metrics and methods, 2023. URLhttps://arxiv.org/abs/2309.16042
Pith/arXiv arXiv 2023
-
[19]
OneEdit: A neural-symbolic collaboratively knowledge editing system
Ningyu Zhang, Zekun Xi, Yujie Luo, Peng Wang, Bozhong Tian, Yunzhi Yao, Jintian Zhang, Shumin Deng, Mengshu Sun, Lei Liang, Zhiqiang Zhang, Xiaowei Zhu, Jun Zhou, and Huajun Chen. OneEdit: A neural-symbolic collaboratively knowledge editing system. InLLM+KG Workshop at VLDB 2024, 2024. URL https://vldb.org/workshops/2024/proceedings/ LLM+KG/LLM+KG-2.pdf
2024
-
[20]
Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to a...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.