ImageAuditor: Membership Inference Attack against Image-based Retrieval-Augmented Generation
Pith reviewed 2026-06-28 10:00 UTC · model grok-4.3
The pith
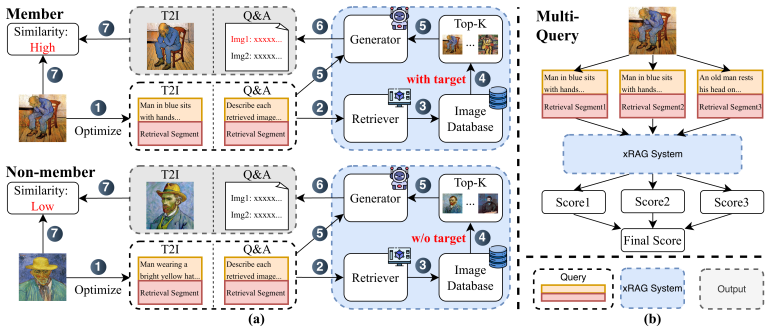
ImageAuditor enables membership inference on image-based retrieval-augmented generation by splitting each query into a retrieval segment and an extraction segment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ImageAuditor decomposes each attack query into a retrieval segment and an extraction segment. Reward-Guided Policy Optimization updates a stochastic policy from reward-ranked candidates to navigate the cross-modal embedding landscape and admits finite-sample optimality guarantees. Distribution analysis of the membership score guides the co-design of prompting strategy and scoring rule for both text-to-image and question-answering tasks. Aggregating signals across queries with K-means clustering produces reliable membership decisions.
What carries the argument
Decomposition of attack queries into a retrieval segment handled by Reward-Guided Policy Optimization and an extraction segment shaped by the distribution of membership scores.
If this is right
- Copyright holders gain a practical way to audit whether a given image appears in the external database of an IRAG system.
- The attack applies equally to text-to-image generation and to question-answering tasks that rely on retrieved images.
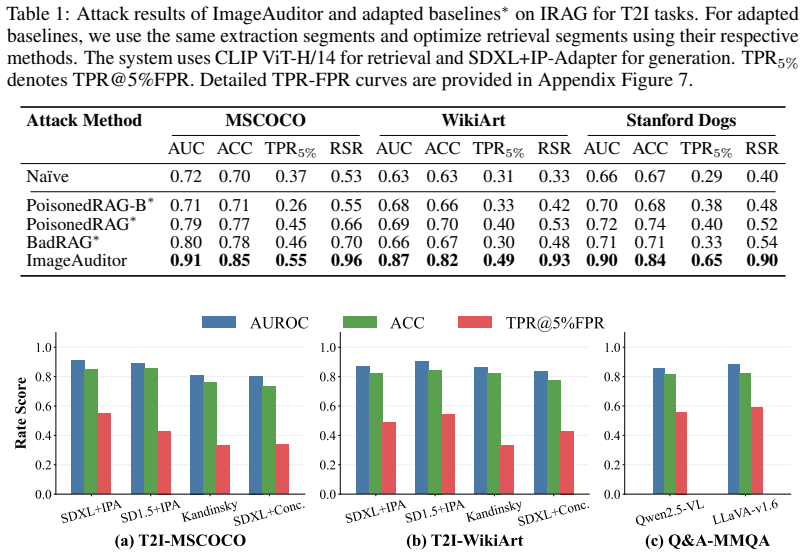
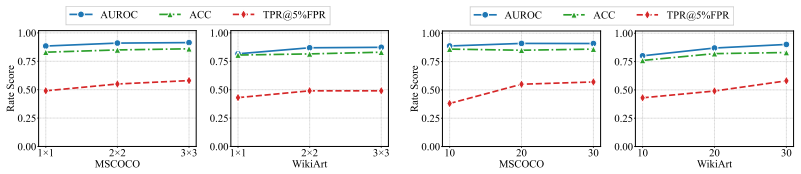
- Four queries per image suffice for AUROC above 80 percent across varied IRAG configurations.
- K-means clustering on the collected scores improves decision reliability over single-query judgments.
Where Pith is reading between the lines
- If the attack succeeds at scale, database operators may need to add visible watermarks or access logs that copyright holders can check directly.
- The same split-query pattern could be tested on other multimodal retrieval systems that combine text prompts with non-text data.
- Defenses could target the policy optimization step by making reward signals from generated images less informative about database contents.
Load-bearing premise
That separating retrieval from extraction and guiding the first part with ranked rewards can overcome the inability of text queries to locate specific images in a cross-modal database.
What would settle it
Measuring whether AUROC falls to chance level when the attack is run against an IRAG system whose retrieval model has been modified so that no text query can surface the target image even when it is present in the database.
Figures





read the original abstract
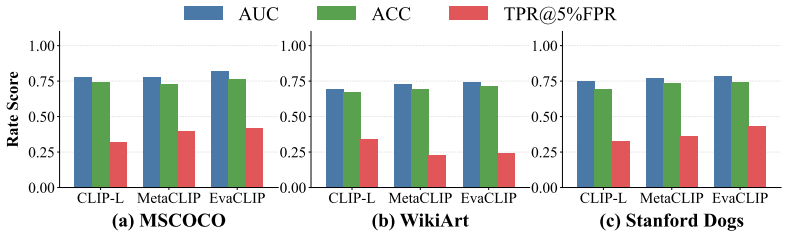
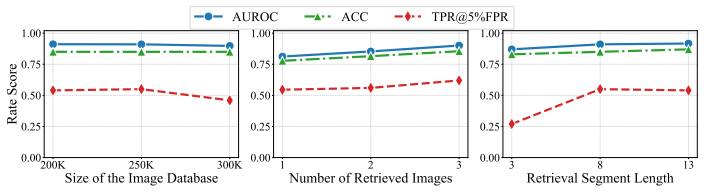
Image-based Retrieval-Augmented Generation (IRAG) conditions a frozen generator on reference images retrieved from an external database, supporting both text-to-image (T2I) and question answering (Q&A) tasks. Because these databases are opaque and web-scraped, copyright holders need ways to audit whether specific images appear in them. While prior work employs membership inference attacks (MIAs) to audit uni-modal, text-based RAG, they fail to transfer to IRAG due to two key challenges. First, cross-modal retrieval: text-RAG MIAs force retrieval of the target passage by injecting its content into the query, which is unavailable in IRAG since images cannot be embedded into text queries; even accurate image captions fail to bridge the modality gap. Second, discriminative signal extraction: text-RAG MIAs extract membership signals by prompting the generator to answer multiple questions over the target passage, whereas T2I generators in IRAG produce images rather than follow Q&A commands. To fill this gap, we introduce the first MIA tailored to IRAG, ImageAuditor, which decomposes each attack query into a retrieval segment and an extraction segment, enabling dedicated optimization for each challenge. For retrieval, we propose Reward-Guided Policy Optimization (RGPO), which updates a stochastic policy from reward-ranked candidates to navigate the cross-modal embedding landscape and admits finite-sample optimality guarantees to balance exploration and exploitation. For extraction, we analyze the distribution of the MIA score to guide the co-design of the prompting strategy and scoring rule, and derive task-specific instantiations for T2I and Q&A tasks. We aggregate signals across queries via K-means clustering for reliable membership decisions. Across various IRAG systems, ImageAuditor exceeds 80% AUROC with only four queries per audited image and remains robust across diverse settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ImageAuditor, the first membership inference attack tailored to Image-based Retrieval-Augmented Generation (IRAG) systems that support both T2I and Q&A tasks. It decomposes each attack query into a retrieval segment and an extraction segment to address the cross-modal retrieval barrier (images cannot be directly injected into text queries) and the lack of Q&A capability in T2I generators. Retrieval is handled via Reward-Guided Policy Optimization (RGPO), which updates a stochastic policy from reward-ranked candidates and is claimed to admit finite-sample optimality guarantees. Extraction uses distribution analysis of the MIA score to co-design prompting and scoring rules, with task-specific instantiations. Signals are aggregated via K-means clustering. The central empirical claim is that ImageAuditor exceeds 80% AUROC across various IRAG systems using only four queries per audited image and remains robust in diverse settings.
Significance. If the reported AUROC results and the finite-sample optimality guarantees for RGPO hold under the experimental conditions, the work supplies a practical auditing tool for copyright holders to detect membership of specific images in opaque, web-scraped IRAG databases. This directly extends prior text-only RAG MIAs to the multimodal setting and supplies an explicit methodological decomposition plus optimality analysis that prior attacks lack.
major comments (2)
- [Abstract (RGPO description)] The abstract states that RGPO 'admits finite-sample optimality guarantees to balance exploration and exploitation,' yet the provided text supplies neither the theorem statement nor the proof sketch. Because this guarantee is invoked to justify the retrieval-stage design, the central claim that the decomposition overcomes the cross-modal barrier rests on an unverified optimality result.
- [Abstract (empirical claim)] The performance claim (>80% AUROC with four queries) is load-bearing for the paper's contribution, but the abstract supplies no information on the number of IRAG systems tested, the choice of baselines (e.g., adapted text-RAG MIAs or random retrieval), dataset statistics, or ablation of the RGPO versus distribution-guided components. Without these, it is impossible to assess whether the reported numbers demonstrate that the proposed decomposition actually surmounts the two stated challenges.
minor comments (2)
- Define the precise form of the reward function used inside RGPO and state how it is estimated from the generator outputs.
- Clarify how the K-means clustering step converts per-query scores into a final membership decision and whether the number of clusters is fixed or data-dependent.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract (RGPO description)] The abstract states that RGPO 'admits finite-sample optimality guarantees to balance exploration and exploitation,' yet the provided text supplies neither the theorem statement nor the proof sketch. Because this guarantee is invoked to justify the retrieval-stage design, the central claim that the decomposition overcomes the cross-modal barrier rests on an unverified optimality result.
Authors: We agree that the abstract invokes the finite-sample optimality guarantees without including an explicit theorem statement or proof sketch. The manuscript derives the RGPO procedure in Section 3 but presents the optimality analysis only at a high level. We will add a concise theorem statement together with a proof sketch to the main text (or appendix) in the revision so that the retrieval-stage justification is fully substantiated. revision: yes
-
Referee: [Abstract (empirical claim)] The performance claim (>80% AUROC with four queries) is load-bearing for the paper's contribution, but the abstract supplies no information on the number of IRAG systems tested, the choice of baselines (e.g., adapted text-RAG MIAs or random retrieval), dataset statistics, or ablation of the RGPO versus distribution-guided components. Without these, it is impossible to assess whether the reported numbers demonstrate that the proposed decomposition actually surmounts the two stated challenges.
Authors: Abstract length constraints preclude exhaustive experimental metadata. The full manuscript already reports the number of IRAG systems, baselines (including adapted text-RAG MIAs and random retrieval), dataset statistics, and RGPO ablations in Section 4 and the associated tables. To improve clarity we will revise the abstract to state the number of systems evaluated and to point readers to the detailed experimental section. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper presents ImageAuditor as a new MIA decomposed into RGPO for retrieval and distribution-guided prompting for extraction, with claims of finite-sample optimality and task-specific scoring. No equations, fitted parameters, or self-citations are visible in the provided text that reduce any prediction or result to its own inputs by construction. The method is described as addressing gaps in prior (non-self) work, and the central performance claim (>80% AUROC with 4 queries) is positioned as an empirical outcome rather than a definitional or fitted tautology. This is the expected non-finding for a methods paper without visible self-referential derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Membership inference attacks from first principles
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles. In2022 IEEE symposium on security and privacy (SP), pages 1897–1914. IEEE, 2022
1914
-
[2]
Phantom: General trigger attacks on retrieval augmented language generation
Harsh Chaudhari, Giorgio Severi, John Abascal, Matthew Jagielski, Christopher A Choquette- Choo, Milad Nasr, Cristina Nita-Rotaru, and Alina Oprea. Phantom: General trigger attacks on retrieval augmented language generation. 2024
2024
-
[3]
Tianyu Chen, Jian Lou, and Wenjie Wang. Safeguarding multimodal knowledge copyright in the rag-as-a-service environment.arXiv preprint arXiv:2506.10030, 2025
-
[4]
Murag: Multimodal retrieval-augmented generator for open question answering over images and text
Wenhu Chen, Hexiang Hu, Xi Chen, Pat Verga, and William Cohen. Murag: Multimodal retrieval-augmented generator for open question answering over images and text. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5558– 5570, 2022
2022
-
[5]
Re-imagen: Retrieval- augmented text-to-image generator.arXiv preprint arXiv:2209.14491, 2022
Wenhu Chen, Hexiang Hu, Chitwan Saharia, and William W Cohen. Re-imagen: Retrieval- augmented text-to-image generator.arXiv preprint arXiv:2209.14491, 2022
-
[6]
Zhanpeng Chen, Chengjin Xu, Yiyan Qi, and Jian Guo. Mllm is a strong reranker: Ad- vancing multimodal retrieval-augmented generation via knowledge-enhanced reranking and noise-injected training.arXiv preprint arXiv:2407.21439, 2024
-
[7]
Novel datasets for fine-grained image categorization
E Dataset. Novel datasets for fine-grained image categorization. InFirst workshop on fine grained visual categorization, CVPR. Citeseer. Citeseer. Citeseer, volume 5, page 2. Citeseer, 2011
2011
-
[8]
Rlprompt: Optimizing discrete text prompts with rein- forcement learning
Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric Xing, and Zhiting Hu. Rlprompt: Optimizing discrete text prompts with rein- forcement learning. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3369–3391, 2022
2022
-
[9]
Hotflip: White-box adversarial examples for text classification
Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. Hotflip: White-box adversarial examples for text classification. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 31–36, 2018
2018
-
[10]
Runpeng Geng, Yanting Wang, Ying Chen, and Jinyuan Jia. Unic-rag: Universal knowledge corruption attacks to retrieval-augmented generation.arXiv preprint arXiv:2508.18652, 2025
-
[11]
Qiyuan He and Angela Yao. Conceptrol: Concept control of zero-shot personalized image generation.arXiv preprint arXiv:2503.06568, 2025
-
[12]
Towards{Label-Only}membership inference attack against pre-trained large language models
Yu He, Boheng Li, Liu Liu, Zhongjie Ba, Wei Dong, Yiming Li, Zhan Qin, Kui Ren, and Chun Chen. Towards{Label-Only}membership inference attack against pre-trained large language models. In34th USENIX Security Symposium (USENIX Security 25), pages 1609–1628, 2025
2025
-
[13]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Tatsuki Koga, Ruihan Wu, Zhiyuan Zhang, and Kamalika Chaudhuri. Privacy-preserving retrieval-augmented generation with differential privacy.arXiv preprint arXiv:2412.04697, 2024. 10
-
[15]
3d object representations for fine- grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine- grained categorization. InProceedings of the IEEE international conference on computer vision workshops, pages 554–561, 2013
2013
-
[16]
Generating is believing: Membership inference attacks against retrieval-augmented generation
Yuying Li, Gaoyang Liu, Chen Wang, and Yang Yang. Generating is believing: Membership inference attacks against retrieval-augmented generation. InICASSP 2025-2025 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[17]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[18]
Retrieval augmented visual question answering with outside knowledge
Weizhe Lin and Bill Byrne. Retrieval augmented visual question answering with outside knowledge. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 11238–11254, 2022
2022
-
[19]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[20]
Mask-based membership inference attacks for retrieval-augmented generation
Mingrui Liu, Sixiao Zhang, and Cheng Long. Mask-based membership inference attacks for retrieval-augmented generation. InProceedings of the ACM on Web Conference 2025, pages 2894–2907, 2025
2025
-
[21]
Ziyuan Luo, Yangyi Zhao, Ka Chun Cheung, Simon See, and Renjie Wan. Imagesentinel: Protecting visual datasets from unauthorized retrieval-augmented image generation.arXiv preprint arXiv:2510.12119, 2025
-
[22]
Realrag: Retrieval-augmented realistic image generation via self-reflective contrastive learning
Yuanhuiyi Lyu, Xu Zheng, Lutao Jiang, Yibo Yan, Xin Zou, Huiyu Zhou, Linfeng Zhang, and Xuming Hu. Realrag: Retrieval-augmented realistic image generation via self-reflective contrastive learning. InInternational Conference on Machine Learning, pages 41772–41790. PMLR, 2025
2025
-
[23]
Riddle me this! stealthy membership inference for retrieval-augmented genera- tion
Ali Naseh, Yuefeng Peng, Anshuman Suri, Harsh Chaudhari, Alina Oprea, and Amir Houmansadr. Riddle me this! stealthy membership inference for retrieval-augmented genera- tion. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 1245–1259, 2025
2025
-
[24]
Yan Pang and Tianhao Wang. Black-box membership inference attacks against fine-tuned diffusion models.arXiv preprint arXiv:2312.08207, 2023
-
[25]
Wiki art gallery, inc.: A case for critical thinking.Issues in Accounting Education, 26(3):593–608, 2011
Fred Phillips and Brandy Mackintosh. Wiki art gallery, inc.: A case for critical thinking.Issues in Accounting Education, 26(3):593–608, 2011
2011
-
[26]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[28]
Kandinsky: an improved text-to-image synthesis with image prior and latent diffusion
Anton Razzhigaev, Arseniy Shakhmatov, Anastasia Maltseva, Vladimir Arkhipkin, Igor Pavlov, Ilya Ryabov, Angelina Kuts, Alexander Panchenko, Andrey Kuznetsov, and Denis Dimitrov. Kandinsky: an improved text-to-image synthesis with image prior and latent diffusion. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Sy...
2023
-
[29]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 11
2022
-
[30]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
2015
-
[31]
Rotem Shalev-Arkushin, Rinon Gal, Amit H Bermano, and Ohad Fried. Imagerag: Dynamic image retrieval for reference-guided image generation.arXiv preprint arXiv:2502.09411, 2025
-
[32]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
2017
-
[33]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Alon Talmor, Ori Yoran, Amnon Catav, Dan Lahav, Yizhong Wang, Akari Asai, Gabriel Ilharco, Hannaneh Hajishirzi, and Jonathan Berant. Multimodalqa: Complex question answering over text, tables and images.arXiv preprint arXiv:2104.06039, 2021
-
[35]
Joint-gcg: Unified gradient-based poisoning attacks on retrieval-augmented generation systems
Haowei Wang, Rupeng Zhang, Junjie Wang, Mingyang Li, Yuekai Huang, Dandan Wang, and Qing Wang. Joint-gcg: Unified gradient-based poisoning attacks on retrieval-augmented generation systems. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 35793–35801, 2026
2026
-
[36]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang- Wen Li, Gargi Ghosh, Luke Zettlemoyer, and Christoph Feichtenhofer. Demystifying clip data. arXiv preprint arXiv:2309.16671, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Jiaqi Xue, Mengxin Zheng, Yebowen Hu, Fei Liu, Xun Chen, and Qian Lou. Badrag: Identifying vulnerabilities in retrieval augmented generation of large language models.arXiv preprint arXiv:2406.00083, 2024
-
[40]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Learning to sample effective and diverse prompts for text-to-image generation
Taeyoung Yun, Dinghuai Zhang, Jinkyoo Park, and Ling Pan. Learning to sample effective and diverse prompts for text-to-image generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23625–23635, 2025
2025
-
[42]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Please describe the retrieved images
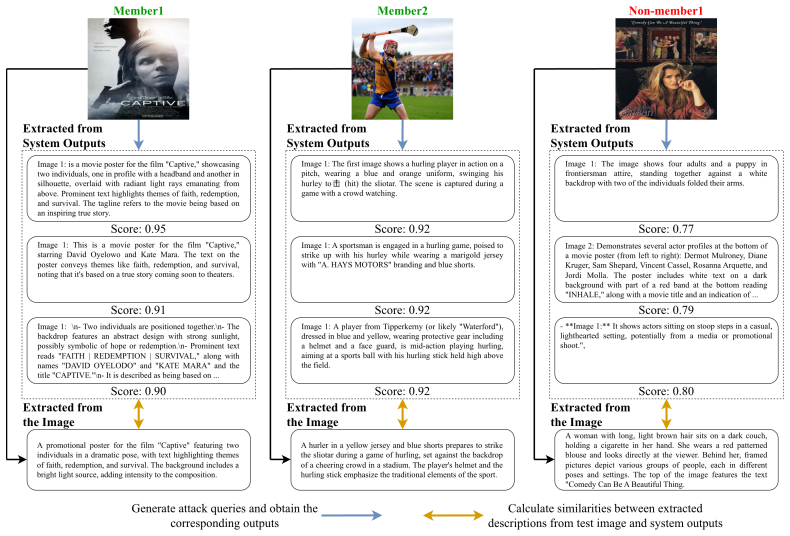
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. {PoisonedRAG}: Knowledge corruption attacks to {Retrieval-Augmented} generation of large language models. In34th USENIX Security Symposium (USENIX Security 25), pages 3827–3844, 2025. 12 A Proofs A.1 Proof of Theorem 3.1 We prove the theorem for β= 1 . β <1 introduces additional approximation error but...
2025
-
[44]
in ablation studies.(3) WikiArt[ 25] contains 81,444 paintings spanning 27 styles and 45 genres 16 Table 4: Main results of ImageAuditor on IRAG for Q&A tasks. Following the literature [ 6], the system uses CLIP ViT-L/14-336 for retrieval and Qwen2.5-VL-7B-Instruct for generation. All methods share the same extraction segment (“Describe each retrieved ima...
-
[45]
Format as ‘Image 1:’, ‘Image 2:’, etc
Extraction Segment in the Q&A Setting Describe each retrieved image. Format as ‘Image 1:’, ‘Image 2:’, etc. Prompt for Details Extraction in the Q&A Setting You are an image captioning system. Given an input image, write one detailed natural caption. Requirements: • Describe visible objects, text, scene, attributes, and layout when helpful. • Stay faithfu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.