EntSQL: A Benchmark for Grounding Text-to-SQL in Long-Context Enterprise Knowledge
Pith reviewed 2026-06-28 10:26 UTC · model grok-4.3
The pith
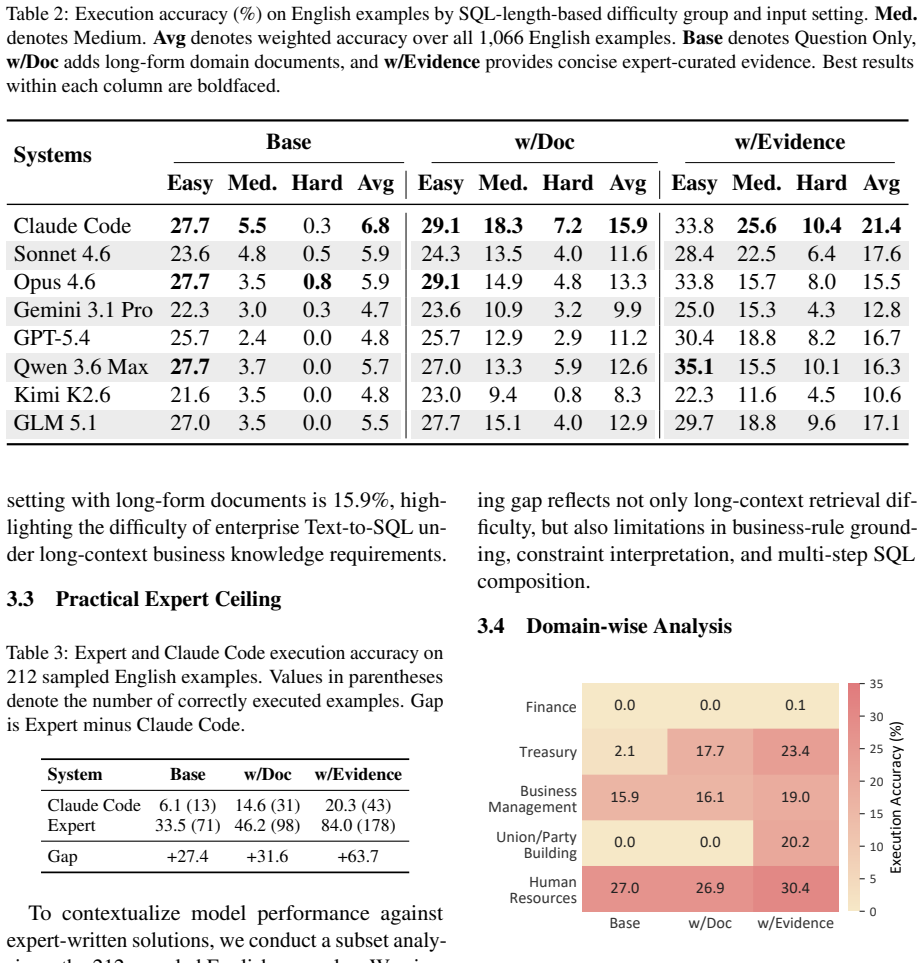
Text-to-SQL systems reach only 15.9 percent accuracy when grounding queries in long enterprise documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
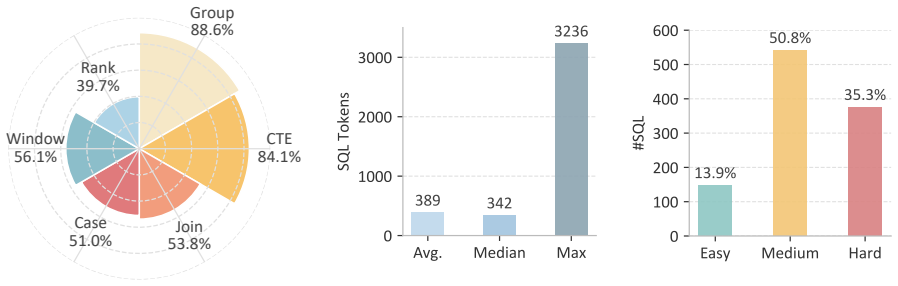
EntSQL supplies 1,066 semantic examples that pair natural-language questions with both database schemas and long proprietary documents, requiring models to extract and apply enterprise-specific knowledge to produce correct SQL; the best system reaches 15.9 percent on English inputs even when the documents are provided.
What carries the argument
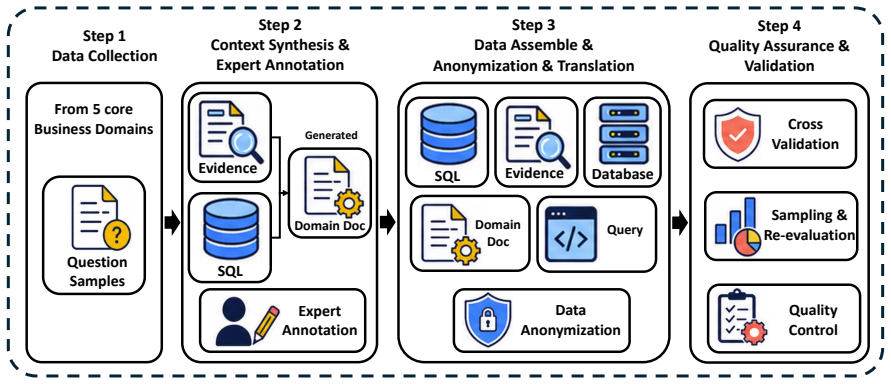
The EntSQL benchmark of long-context proprietary documents aligned with questions and schemas for enterprise Text-to-SQL evaluation.
If this is right
- Enterprise Text-to-SQL requires mechanisms to incorporate and apply long private documents beyond schema information alone.
- Standard benchmarks such as Spider do not capture the additional grounding demands of business rules and conventions.
- Performance remains low even with document access, showing that long-context reasoning must improve for realistic SQL generation.
- Complex SQL structures combined with domain rules increase the difficulty of correct query production.
Where Pith is reading between the lines
- Systems improved on EntSQL could allow non-technical staff to query company databases while respecting internal conventions without exposing all documents during training.
- The same grounding problem is likely to appear in other specialized query domains that rely on proprietary rule sets.
- Low scores indicate that current models do not reliably translate organizational conventions into query logic even when the source text is supplied.
Load-bearing premise
The 1,066 examples and their alignment with real enterprise documents accurately represent the private business knowledge and conventions that actual Text-to-SQL systems must handle.
What would settle it
A system that scores substantially above 15.9 percent on the English EntSQL set when given the long-form documents and schemas.
Figures

read the original abstract
Text-to-SQL enables natural language access to databases, and recent LLMs have substantially advanced its capabilities. Existing benchmarks such as Spider, BIRD, and Spider~2.0 evaluate schema generalization, large-scale databases, and realistic workflows, but largely overlook enterprise scenarios where SQL generation depends on private business knowledge, such as internal metrics, reporting conventions, and organizational rules. We introduce EntSQL, an enterprise-oriented Text-to-SQL benchmark for evaluating long-context grounding over proprietary business documents. EntSQL contains 1,066 aligned Chinese-English semantic examples across five business domains, with most examples requiring domain knowledge beyond the question and schema and involving complex SQL structures. On English inputs, the best evaluated system reaches only 15.9\% when long-form documents are provided, highlighting the difficulty of grounding SQL generation in enterprise knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EntSQL, a benchmark with 1,066 aligned Chinese-English examples across five business domains designed to evaluate Text-to-SQL systems on grounding SQL generation in long-context proprietary enterprise documents containing private metrics, reporting conventions, and organizational rules. It reports that the best evaluated system reaches only 15.9% accuracy on English inputs even when long-form documents are provided, arguing this demonstrates the difficulty of the task.
Significance. If the benchmark examples are representative of real enterprise knowledge, the result would usefully quantify a gap in long-context grounding for Text-to-SQL and motivate work on private-document integration. The bilingual construction is a positive feature for cross-lingual evaluation, but the paper's impact hinges on whether the 1,066 instances reflect actual proprietary business conventions rather than benchmark artifacts.
major comments (2)
- [Abstract and benchmark-construction section] Abstract and benchmark-construction section: the central claim that 15.9% performance demonstrates the difficulty of grounding SQL in enterprise knowledge requires that the 1,066 examples accurately reflect private business metrics, reporting conventions, and organizational rules. The manuscript provides no details on how the five domains were selected, how documents were sourced and aligned to queries, or whether any external validation against live enterprise usage occurred; without these, the low score cannot be interpreted as evidence of a general enterprise challenge rather than a benchmark-specific artifact.
- [Evaluation section] Evaluation section: the reported 15.9% figure is presented without error analysis, per-domain breakdown, or stratification by required knowledge type or SQL complexity. This omission is load-bearing because it prevents readers from determining which aspects of enterprise grounding (e.g., metric definitions versus organizational rules) drive the failures.
minor comments (1)
- [Abstract] The abstract states that 'most examples' require domain knowledge beyond the question and schema but does not quantify this fraction or provide a table summarizing knowledge requirements per domain.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and benchmark-construction section] Abstract and benchmark-construction section: the central claim that 15.9% performance demonstrates the difficulty of grounding SQL in enterprise knowledge requires that the 1,066 examples accurately reflect private business metrics, reporting conventions, and organizational rules. The manuscript provides no details on how the five domains were selected, how documents were sourced and aligned to queries, or whether any external validation against live enterprise usage occurred; without these, the low score cannot be interpreted as evidence of a general enterprise challenge rather than a benchmark-specific artifact.
Authors: We agree that additional details on benchmark construction are needed to support the central claim. The five domains were chosen to represent common enterprise areas (finance, sales, human resources, operations, and supply chain) based on prevalence in real business settings and availability of internal documentation. Documents were sourced from anonymized proprietary repositories and aligned to queries through a multi-stage process involving domain experts who verified that each example requires private knowledge (metrics, conventions, or rules) not inferable from the schema or question alone. While confidentiality prevents naming specific organizations or releasing full documents, we will expand the benchmark-construction section with a high-level description of the selection criteria, alignment methodology, and internal validation steps performed by business analysts. This revision will allow readers to better evaluate representativeness without compromising proprietary information. revision: yes
-
Referee: [Evaluation section] Evaluation section: the reported 15.9% figure is presented without error analysis, per-domain breakdown, or stratification by required knowledge type or SQL complexity. This omission is load-bearing because it prevents readers from determining which aspects of enterprise grounding (e.g., metric definitions versus organizational rules) drive the failures.
Authors: We acknowledge that the current evaluation section lacks the requested breakdowns and analysis. In the revised manuscript we will add a dedicated error analysis subsection that categorizes model failures according to the type of enterprise knowledge required (metric definitions, reporting conventions, organizational rules) and SQL complexity. We will also report per-domain accuracy figures and, to the extent the data permits, stratify results by knowledge type. These additions will clarify which grounding challenges contribute most to the observed performance gap. revision: yes
Circularity Check
No circularity: benchmark construction and reported results are independent of internal fitting or self-referential derivation.
full rationale
The paper introduces EntSQL as a new dataset of 1,066 examples and reports empirical performance numbers (e.g., 15.9%) obtained by evaluating external systems on that dataset. No equations, parameter fittings, predictions, or uniqueness theorems are present that reduce to the paper's own inputs by construction. The central claim rests on external model runs rather than any self-citation chain or ansatz smuggling, satisfying the criteria for a self-contained benchmark presentation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected business documents and questions represent typical private enterprise knowledge that SQL generation must incorporate.
Reference graph
Works this paper leans on
-
[1]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Seq2sql: Generating structured queries from natural language using reinforcement learning , author=. arXiv preprint arXiv:1709.00103 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
SQLNet: Generating Structured Queries From Natural Language Without Reinforcement Learning
Sqlnet: Generating structured queries from natural language without reinforcement learning , author=. arXiv preprint arXiv:1711.04436 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Towards complex text-to-sql in cross-domain database with intermediate representation , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[4]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Rat-sql: Relation-aware schema encoding and linking for text-to-sql parsers , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[5]
Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
Bridging textual and tabular data for cross-domain text-to-SQL semantic parsing , author=. Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
2020
-
[6]
Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
SmBoP: Semi-autoregressive bottom-up semantic parsing , author=. Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
2021
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Resdsql: Decoupling schema linking and skeleton parsing for text-to-sql , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[8]
arXiv preprint arXiv:2308.15363 , year=
Text-to-sql empowered by large language models: A benchmark evaluation , author=. arXiv preprint arXiv:2308.15363 , year=
-
[9]
arXiv preprint arXiv:2307.07306 , year=
C3: Zero-shot text-to-sql with chatgpt , author=. arXiv preprint arXiv:2307.07306 , year=
-
[10]
Advances in neural information processing systems , volume=
Din-sql: Decomposed in-context learning of text-to-sql with self-correction , author=. Advances in neural information processing systems , volume=
-
[11]
CHESS: Contextual Harnessing for Efficient SQL Synthesis
Chess: Contextual harnessing for efficient sql synthesis , author=. arXiv preprint arXiv:2405.16755 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Mac-sql: A multi-agent collaborative framework for text-to-sql , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[13]
arXiv preprint arXiv:2411.00073 , year=
Rsl-sql: Robust schema linking in text-to-sql generation , author=. arXiv preprint arXiv:2411.00073 , year=
-
[14]
arXiv preprint arXiv:2506.18951 , year=
SWE-SQL: Illuminating LLM Pathways to Solve User SQL Issues in Real-World Applications , author=. arXiv preprint arXiv:2506.18951 , year=
-
[15]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[16]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Sparc: Cross-domain semantic parsing in context , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[17]
Cosql: A conversational text-to-sql challenge towards cross-domain natural language interfaces to databases , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[18]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
DuSQL: A large-scale and pragmatic Chinese text-to-SQL dataset , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[19]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Exploring underexplored limitations of cross-domain text-to-sql generalization , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[20]
KaggleDBQA: Realistic evaluation of text-to-SQL parsers , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[21]
spider: A diagnostic evaluation benchmark towards text-to-sql robustness , author=
Dr. spider: A diagnostic evaluation benchmark towards text-to-sql robustness , author=. arXiv preprint arXiv:2301.08881 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Nan Huo and Xiaohan Xu and Jinyang Li and Per Jacobsson and Shipei Lin and Bowen Qin and Binyuan Hui and Xiaolong Li and Ge Qu and Shuzheng Si and Linheng Han and Edward Alexander and Xintong Zhu and Rui Qin and Ruihan Yu and Yiyao Jin and Feige Zhou and Weihao Zhong and Yun Chen and Hongyu Liu and Chenhao Ma and Fatma Ozcan and Yannis Papakonstantinou an...
-
[24]
arXiv preprint arXiv:2411.07763 , year=
Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows , author=. arXiv preprint arXiv:2411.07763 , year=
-
[25]
IEEE Transactions on Knowledge and Data Engineering , year=
A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going? , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[26]
Introduction to Agentic Coding , author=
-
[27]
2026 , month=
Introducing Claude Sonnet 4.6 , author=. 2026 , month=
2026
-
[28]
2026 , month=
Introducing GPT-5.4 , author=. 2026 , month=
2026
-
[29]
2026 , month=
Gemini 3.1 Pro: A smarter model for your most complex tasks , author=. 2026 , month=
2026
-
[30]
2026 , month=
Kimi K2.6: Advancing Open-Source Coding and Agentic Capabilities , author=. 2026 , month=
2026
-
[31]
GLM-5: from Vibe Coding to Agentic Engineering
Glm-5: from vibe coding to agentic engineering , author=. arXiv preprint arXiv:2602.15763 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.