SMAC: Spatial-Modal Joint Modeling and Adaptive Representation Collapse for Multimodal Object Tracking
Pith reviewed 2026-06-28 08:13 UTC · model grok-4.3
The pith
A spatial-modal fusion backbone with adaptive representation collapse improves multimodal multi-object tracking under complex illumination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
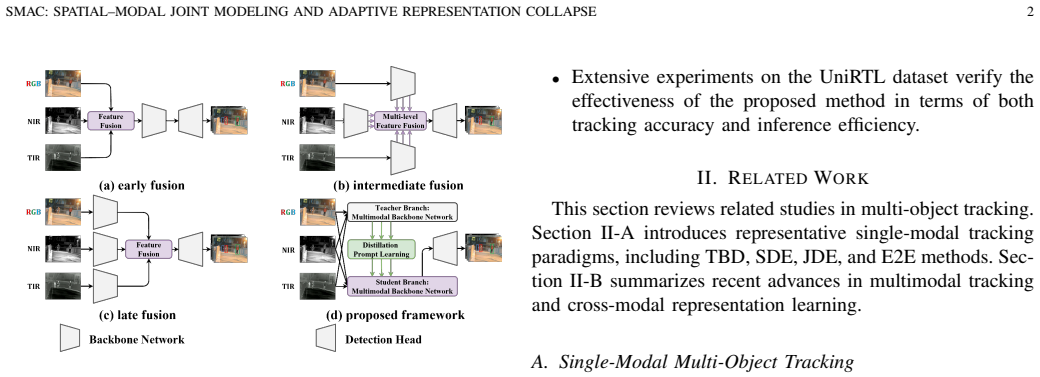
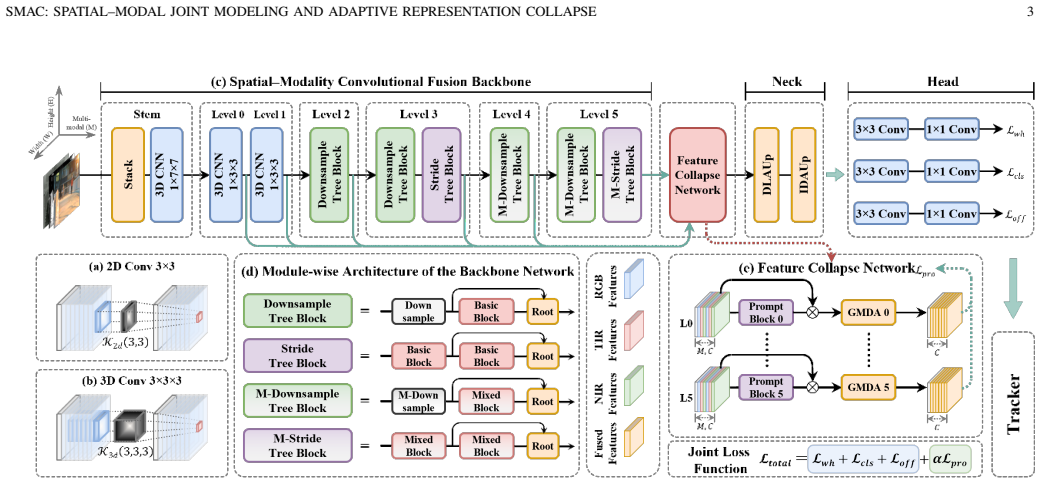
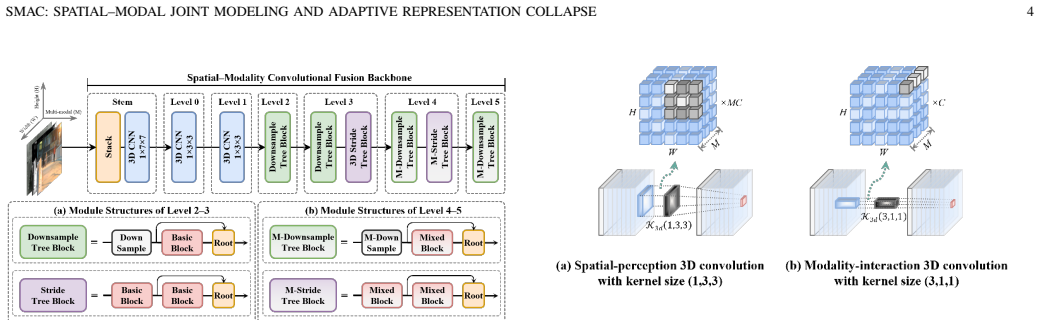
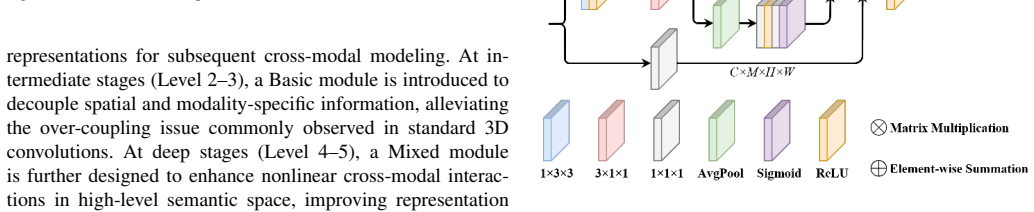
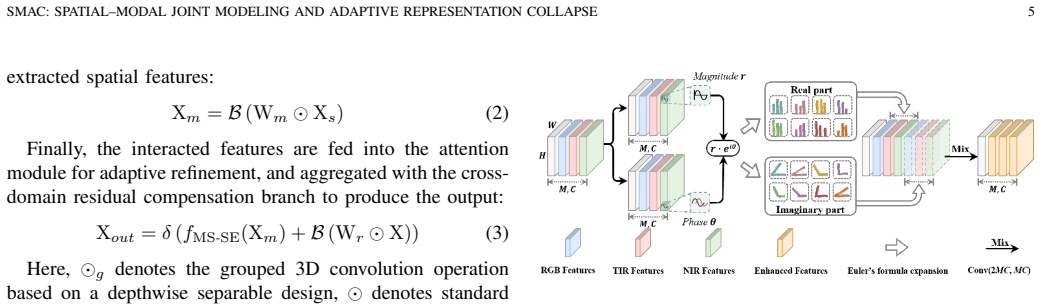
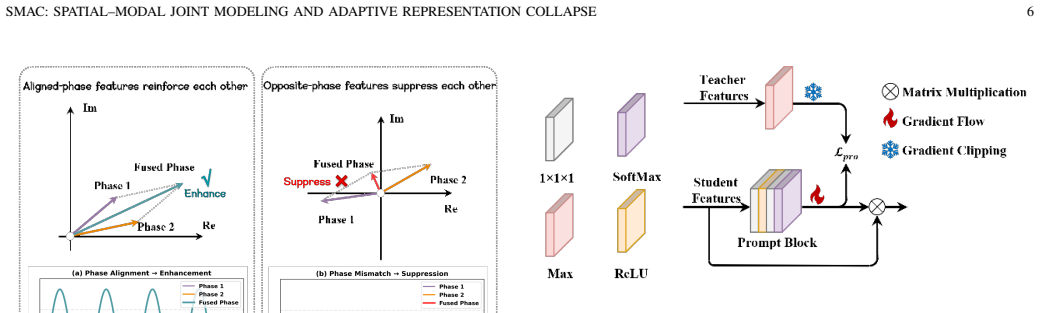
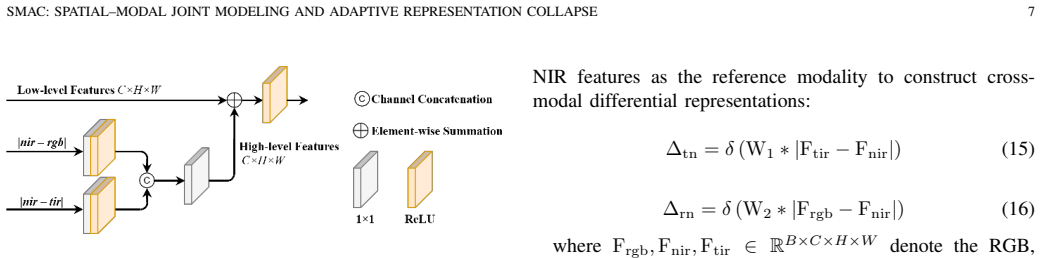
The authors establish that a spatial-modal fusion backbone—Basic modules performing spatial feature extraction and modal interaction via decoupled 3D convolution, Mixed modules modeling nonlinear cross-modal correlations through amplitude-phase decomposition—combined with a representation collapse network where Distillation Prompt Guidance generates dynamic modal weights under teacher supervision and Global Modal Difference Aggregation preserves discriminative information, enables adaptive multimodal fusion that outperforms several state-of-the-art methods on the UniRTL dataset.
What carries the argument
The spatial-modal convolution fusion and distillation-prompt-based multimodal MOT framework, where the DPG module produces dynamic weights and the GMDA module retains information during adaptive representation collapse.
If this is right
- Multimodal trackers can achieve higher accuracy through dynamic modal weighting generated under teacher supervision.
- Representation collapse can preserve discriminative cross-modal information while reducing the drawbacks of fixed fusion strategies.
- The method maintains favorable inference efficiency alongside improved tracking metrics on RNT modality.
- Public release of code and models enables direct reproduction and extension of the reported results.
Where Pith is reading between the lines
- The same adaptive collapse approach could apply to other multimodal tasks such as detection or segmentation under varying conditions.
- Reducing reliance on hand-tuned fusion weights might lower the engineering effort needed when adding new sensor modalities.
- Testing the modules on datasets with different sensor combinations would reveal whether the performance gains hold outside the original modality set.
Load-bearing premise
The UniRTL dataset and its modalities represent complex real-world illumination conditions, and the DPG and GMDA modules produce adaptive weights that generalize beyond the reported experiments.
What would settle it
Running the tracker on a separate multimodal dataset containing illumination conditions absent from UniRTL and observing that its HOTA and MOTA scores no longer exceed those of prior state-of-the-art methods.
Figures






read the original abstract
Multimodal multi-object tracking (MOT) under complex illumination remains challenging due to insufficient joint modeling of spatial and modal features and the limited adaptability of fixed fusion strategies. To address these issues, this paper proposes a spatial-modal convolution fusion and distillation-prompt-based multimodal MOT framework. A spatial-modal fusion backbone is first constructed, where a Basic module performs spatial feature extraction and modal interaction via decoupled 3D convolution, while a Mixed module models nonlinear cross-modal correlations through amplitude-phase decomposition. In addition, a representation collapse network is designed for adaptive multimodal fusion. A Distillation Prompt Guidance (DPG) module generates dynamic modal weights under teacher supervision, and a Global Modal Difference Aggregation (GMDA) module preserves discriminative information during multimodal representation collapse. Extensive experiments on the UniRTL dataset demonstrate the effectiveness of the proposed method. The proposed tracker achieves 63.31 HOTA and 79.21 MOTA on the RNT modality, outperforming several state-of-the-art methods while maintaining favorable inference efficiency. The source code and pretrained models are publicly available at https://github.com/QitaiSun/SMAC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SMAC, a multimodal multi-object tracking framework consisting of a spatial-modal fusion backbone (Basic module with decoupled 3D convolution for spatial extraction and modal interaction; Mixed module with amplitude-phase decomposition for nonlinear cross-modal correlations) and a representation collapse network (DPG module for dynamic modal weights under teacher supervision; GMDA module for preserving discriminative information). It reports that the method achieves 63.31 HOTA and 79.21 MOTA on the RNT modality of the UniRTL dataset, outperforming several SOTA trackers while maintaining favorable inference efficiency, and releases code and pretrained models publicly.
Significance. If the performance claims hold under scrutiny, the work offers a concrete approach to adaptive multimodal fusion for illumination-challenged tracking. The public release of code and models is a clear strength that supports reproducibility and allows direct verification of the reported numbers.
major comments (2)
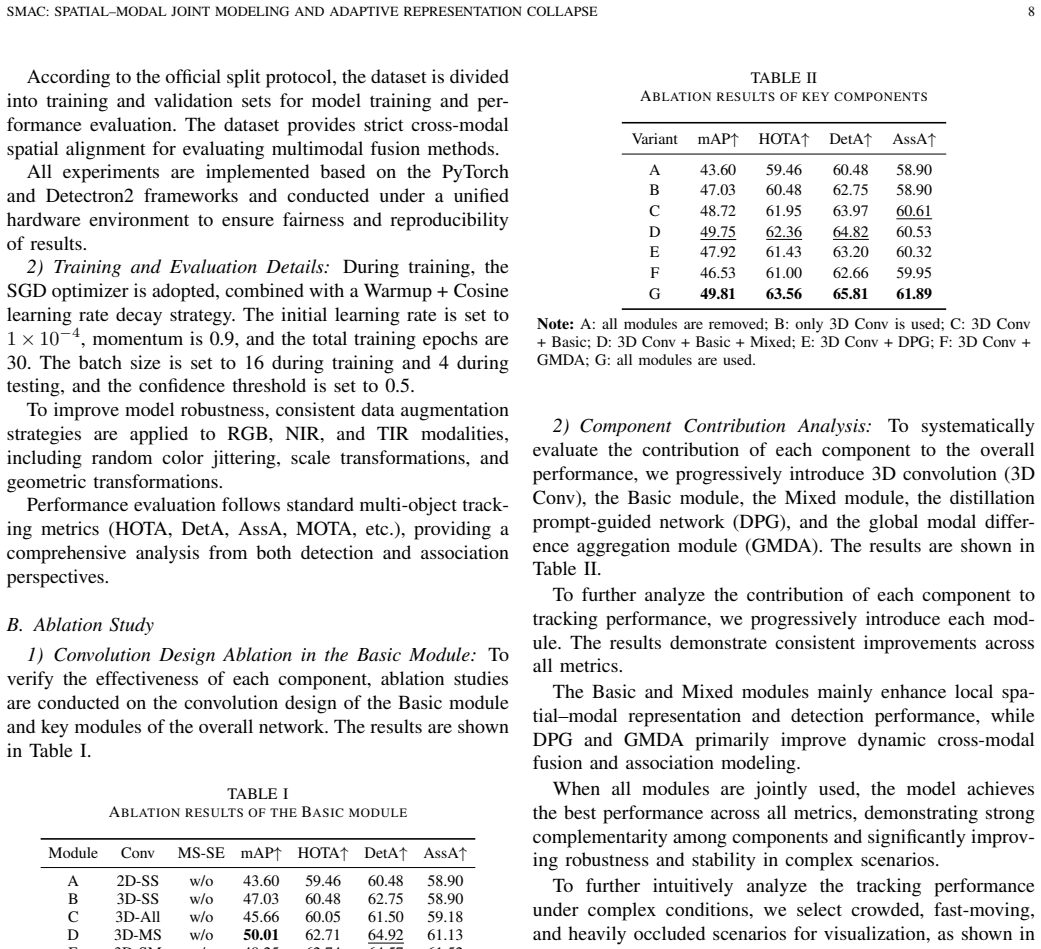
- [Experiments section] Experiments section: The central performance claims (63.31 HOTA / 79.21 MOTA on RNT) are presented as single aggregate values with no ablation studies on the DPG or GMDA modules, no error bars, and no details on run count or statistical significance. This is load-bearing because the abstract attributes superiority specifically to the adaptive representation collapse, yet without module-level ablations it is impossible to rule out that gains arise from hyperparameter choices or baseline components.
- [Method section (DPG/GMDA)] Method section (DPG/GMDA): The description of how the Distillation Prompt Guidance module generates dynamic weights and how the Global Modal Difference Aggregation module prevents loss of discriminative information during collapse lacks the explicit loss formulations, weight computation equations, or training protocol. These details are required to assess whether the claimed adaptability is realized in the implementation.
minor comments (1)
- [Abstract] The abstract states 'favorable inference efficiency' but provides no concrete metrics (FPS, parameter count, or comparison table); adding these numbers would strengthen the efficiency claim without altering the central result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate the suggested improvements in the revised version.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: The central performance claims (63.31 HOTA / 79.21 MOTA on RNT) are presented as single aggregate values with no ablation studies on the DPG or GMDA modules, no error bars, and no details on run count or statistical significance. This is load-bearing because the abstract attributes superiority specifically to the adaptive representation collapse, yet without module-level ablations it is impossible to rule out that gains arise from hyperparameter choices or baseline components.
Authors: We agree that the absence of module-level ablations on DPG and GMDA, along with missing statistical details such as error bars, run counts, and significance testing, limits the ability to attribute gains specifically to the adaptive collapse components. In the revised manuscript, we will add dedicated ablation studies isolating the contributions of DPG and GMDA, report results averaged over multiple independent runs with standard deviations as error bars, and include details on the number of runs performed along with any statistical analysis. revision: yes
-
Referee: [Method section (DPG/GMDA)] Method section (DPG/GMDA): The description of how the Distillation Prompt Guidance module generates dynamic weights and how the Global Modal Difference Aggregation module prevents loss of discriminative information during collapse lacks the explicit loss formulations, weight computation equations, or training protocol. These details are required to assess whether the claimed adaptability is realized in the implementation.
Authors: We acknowledge that the current method descriptions for DPG and GMDA are high-level and omit explicit mathematical formulations. In the revision, we will expand the method section to include the precise loss functions used in DPG for generating dynamic modal weights under teacher supervision, the equations for weight computation and modal interaction, the formulation of the GMDA module for preserving discriminative information, and the complete training protocol including hyperparameters and optimization details. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical multimodal MOT architecture (spatial-modal fusion backbone with Basic/Mixed modules, DPG and GMDA for adaptive fusion) and reports measured performance (63.31 HOTA / 79.21 MOTA on RNT modality of UniRTL). No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. Claims rest on experimental results and public code release rather than any self-referential reduction; the work is self-contained as a standard empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fairmot: On the fairness of detection and re-identification in multiple object tracking,
Y . Zhang, C. Wang, X. Wang, W. Zeng, and W. Liu, “Fairmot: On the fairness of detection and re-identification in multiple object tracking,” Int. J. Comput. Vision, vol. 129, no. 11, p. 3069–3087, Nov. 2021. [Online]. Available: https://doi.org/10.1007/s11263-021-01513-4
-
[2]
Bytetrack: Multi-object tracking by associating every de- tection box,
Y . Zhang, P. Sun, Y . Jiang, D. Yu, F. Weng, Z. Yuan, P. Luo, W. Liu, and X. Wang, “Bytetrack: Multi-object tracking by associating every de- tection box,” inComputer Vision – ECCV 2022, S. Avidan, G. Brostow, M. Ciss´e, G. M. Farinella, and T. Hassner, Eds. Cham: Springer Nature Switzerland, 2022, pp. 1–21
2022
-
[3]
Motrv2: Bootstrapping end-to-end multi-object tracking by pretrained object detectors,
Y . Zhang, T. Wang, and X. Zhang, “Motrv2: Bootstrapping end-to-end multi-object tracking by pretrained object detectors,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 22 056–22 065
2023
-
[5]
Simple online and realtime tracking,
A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” in2016 IEEE International Conference on Image Processing (ICIP), 2016, pp. 3464–3468
2016
-
[6]
wb ≡1 recovers the uniform variant
P. Bergmann, T. Meinhardt, and L. Leal-Taixe, “Tracking without bells and whistles,” in2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, Oct. 2019, p. 941–951. [Online]. Available: http://dx.doi.org/10.1109/ICCV .2019.00103
-
[7]
Observation- centric sort: Rethinking sort for robust multi-object tracking,
J. Cao, J. Pang, X. Weng, R. Khirodkar, and K. Kitani, “Observation- centric sort: Rethinking sort for robust multi-object tracking,” 2023. [Online]. Available: https://arxiv.org/abs/2203.14360
arXiv 2023
-
[8]
Poi: Multiple object tracking with high performance detection and appearance feature,
F. Yu, W. Li, Q. Li, Y . Liu, X. Shi, and J. Yan, “Poi: Multiple object tracking with high performance detection and appearance feature,”
-
[9]
Available: https://arxiv.org/abs/1610.06136
[Online]. Available: https://arxiv.org/abs/1610.06136
-
[10]
Simple online and realtime tracking with a deep association metric,
N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime tracking with a deep association metric,” in2017 IEEE International Conference on Image Processing (ICIP). IEEE Press, 2017, p. 3645–3649. [Online]. Available: https://doi.org/10.1109/ICIP.2017. 8296962
-
[11]
Quasi-dense similarity learning for multiple object tracking,
J. Pang, L. Qiu, X. Li, H. Chen, Q. Li, T. Darrell, and F. Yu, “Quasi-dense similarity learning for multiple object tracking,” 2021. [Online]. Available: https://arxiv.org/abs/2006.06664
arXiv 2021
-
[12]
BoT-SORT: Ro- bust Associations Multi-Pedestrian Tracking,
N. Aharon, R. Orfaig, and B.-Z. Bobrovsky, “BoT-SORT: Ro- bust Associations Multi-Pedestrian Tracking,”arXiv e-prints, p. arXiv:2206.14651, Jun. 2022
arXiv 2022
-
[13]
Strong- sort: Make deepsort great again,
Y . Du, Z. Zhao, Y . Song, Y . Zhao, F. Su, T. Gong, and H. Meng, “Strong- sort: Make deepsort great again,”IEEE Transactions on Multimedia, vol. 25, pp. 8725–8737, 2023
2023
-
[14]
Hybrid-sort: Weak cues matter for online multi-object tracking,
M. Yang, G. Han, B. Yan, W. Zhang, J. Qi, H. Lu, and D. Wang, “Hybrid-sort: Weak cues matter for online multi-object tracking,” 2024. [Online]. Available: https://arxiv.org/abs/2308.00783
arXiv 2024
-
[15]
Towards real-time multi-object tracking,
Z. Wang, L. Zheng, Y . Liu, Y . Li, and S. Wang, “Towards real-time multi-object tracking,” 2020. [Online]. Available: https: //arxiv.org/abs/1909.12605
arXiv 2020
-
[16]
Tracking objects as points,
X. Zhou, V . Koltun, and P. Kr ¨ahenb¨uhl, “Tracking objects as points,”
-
[17]
Available: https://arxiv.org/abs/2004.01177
[Online]. Available: https://arxiv.org/abs/2004.01177
arXiv 2004
-
[18]
Rethinking the competition between detection and reid in multi-object tracking,
C. Liang, Z. Zhang, X. Zhou, B. Li, S. Zhu, and W. Hu, “Rethinking the competition between detection and reid in multi-object tracking,”IEEE transactions on image processing : a publication of the IEEE Signal Processing Society, vol. PP, 04 2022
2022
-
[19]
Relationtrack: Relation-aware multiple object tracking with decoupled representation,
E. Yu, Z. Li, S. Han, and H. Wang, “Relationtrack: Relation-aware multiple object tracking with decoupled representation,” 2021. [Online]. Available: https://arxiv.org/abs/2105.04322
arXiv 2021
-
[20]
Transtrack: Multiple object tracking with transformer,
P. Sun, J. Cao, Y . Jiang, R. Zhang, E. Xie, Z. Yuan, C. Wang, and P. Luo, “Transtrack: Multiple object tracking with transformer,” 2021. [Online]. Available: https://arxiv.org/abs/2012.15460
arXiv 2021
-
[21]
Transmot: Spatial-temporal graph transformer for multiple object tracking,
P. Chu, J. Wang, Q. You, H. Ling, and Z. Liu, “Transmot: Spatial-temporal graph transformer for multiple object tracking,” 2021. [Online]. Available: https://arxiv.org/abs/2104.00194
arXiv 2021
-
[22]
Track- former: Multi-object tracking with transformers,
T. Meinhardt, A. Kirillov, L. Leal-Taix ´e, and C. Feichtenhofer, “Track- former: Multi-object tracking with transformers,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 8834–8844
2022
-
[23]
Motr: End-to-end multiple-object tracking with transformer,
F. Zeng, B. Dong, Y . Zhang, T. Wang, X. Zhang, and Y . Wei, “Motr: End-to-end multiple-object tracking with transformer,” 2022. [Online]. Available: https://arxiv.org/abs/2105.03247
arXiv 2022
-
[24]
Memotr: Long-term memory-augmented transformer for multi-object tracking,
R. Gao and L. Wang, “Memotr: Long-term memory-augmented transformer for multi-object tracking,” 2024. [Online]. Available: https://arxiv.org/abs/2307.15700
arXiv 2024
-
[25]
CO-MOT: Boosting end-to-end transformer-based multi-object tracking via coopetition label assignment and shadow sets,
F. yan, W. Luo, Y . Zhong, Y . Gan, and L. Ma, “CO-MOT: Boosting end-to-end transformer-based multi-object tracking via coopetition label assignment and shadow sets,” 2024. [Online]. Available: https://openreview.net/forum?id=WLgbjzKJkk
2024
-
[26]
R. Gao, J. Qi, and L. Wang, “ Multiple Object Tracking as ID Prediction ,” in2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Los Alamitos, CA, USA: IEEE Computer Society, Jun. 2025, pp. 27 883–27 893. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/CVPR52734.2025.02596
-
[27]
Mtmmc: A large-scale real-world multi-modal camera tracking benchmark,
S. Woo, K. Park, I. Shin, M. Kim, and I. S. Kweon, “Mtmmc: A large-scale real-world multi-modal camera tracking benchmark,” 2024. [Online]. Available: https://arxiv.org/abs/2403.20225
arXiv 2024
-
[28]
Heterogeneous graph transformer for multiple tiny object tracking in rgb-t videos,
Q. Xu, L. Wang, W. Sheng, Y . Wang, C. Xiao, C. Ma, and W. An, “Heterogeneous graph transformer for multiple tiny object tracking in rgb-t videos,” 2024. [Online]. Available: https://arxiv.org/abs/2412. 10861
2024
-
[29]
Unirtl: A universal rgbt and low-light benchmark for object tracking,
L. Zhang, L. Wang, Y . Wu, M. Chen, D. Zheng, L. Cao, B. Zeng, and Y . Cai, “Unirtl: A universal rgbt and low-light benchmark for object tracking,”Pattern Recognition, vol. 158, p. 110984, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0031320324007350
2025
-
[30]
Visible-thermal multiple object tracking: Large-scale video dataset and progressive fusion approach,
Y . Zhu, Q. Wang, C. Li, J. Tang, and Z. Huang, “Visible-thermal multiple object tracking: Large-scale video dataset and progressive fusion approach,” 2024. [Online]. Available: https://arxiv.org/abs/2408.00969
arXiv 2024
-
[31]
Multi-stage cross-modality feature interaction for rgb-thermal multi-object tracking,
J. Ma, H. Luo, S. Niu, P. Zhao, Y . Liu, Y . Wei, and J. Zhang, “Multi-stage cross-modality feature interaction for rgb-thermal multi-object tracking,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 2, pp. 2449–2463, 2026
2026
-
[32]
Multi-modal decouple and recouple network for robust 3d object detection,
R. Ding, Z. Kuang, Y . Ji, M. Yang, X. Zheng, and G. Hua, “Multi-modal decouple and recouple network for robust 3d object detection,” 2026. [Online]. Available: https://arxiv.org/abs/2603.07486
arXiv 2026
-
[33]
Plpfusion: Plane-line-pixel fully sparse fusion for robust multi-modal 3d object detection,
J. Hou, H. Song, J. Li, Y . Lin, T. Huang, J. He, X. He, and J. Yang, “Plpfusion: Plane-line-pixel fully sparse fusion for robust multi-modal 3d object detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 5, pp. 5759–5775, 2026
2026
-
[34]
Pvf- dectnet: Multi-modal 3d detection network based on perspective-voxel fusion,
K. Wang, T. Zhou, Z. Zhang, T. Chen, and J. Chen, “Pvf- dectnet: Multi-modal 3d detection network based on perspective-voxel fusion,”Engineering Applications of Artificial Intelligence, vol. 120, p. 105951, 2023. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0952197623001355
2023
-
[35]
Sd2-reid: A semantic-stylistic decoupled distillation framework for robust multi-modal object re-identification,
Y . Yan, M. Gao, Y . Bai, X. Chen, B. Sun, H. Sun, and S. Chen, “Sd2-reid: A semantic-stylistic decoupled distillation framework for robust multi-modal object re-identification,”Neural Networks, vol. 198, p. 108719, 2026. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0893608026001814
2026
-
[36]
An image patch is a wave: Phase-aware vision mlp,
Y . Tang, K. Han, J. Guo, C. Xu, Y . Li, C. Xu, and Y . Wang, “An image patch is a wave: Phase-aware vision mlp,” 2022. [Online]. Available: https://arxiv.org/abs/2111.12294
arXiv 2022
-
[37]
Do different tracking tasks require different appearance models?
Z. Wang, H. Zhao, Y .-L. Li, S. Wang, P. H. S. Torr, and L. Bertinetto, “Do different tracking tasks require different appearance models?”
-
[38]
Available: https://arxiv.org/abs/2107.02156
[Online]. Available: https://arxiv.org/abs/2107.02156
-
[39]
Towards grand unification of object tracking,
B. Yan, Y . Jiang, P. Sun, D. Wang, Z. Yuan, P. Luo, and H. Lu, “Towards grand unification of object tracking,” 2022. [Online]. Available: https://arxiv.org/abs/2207.07078
arXiv 2022
-
[40]
Tracking and segmenting anything in any modality,
T. Zhang, Q. Zhang, G. Ding, and J. Han, “Tracking and segmenting anything in any modality,” 2025. [Online]. Available: https://arxiv.org/abs/2511.19475
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.