See, Infer, Intervene: Proactive World Modeling for Goal-Oriented Social Intelligence
Pith reviewed 2026-06-28 10:23 UTC · model grok-4.3
The pith
Customer states modeled by purchasing phases and psychological fields let a world model select retail interventions more accurately than direct video baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
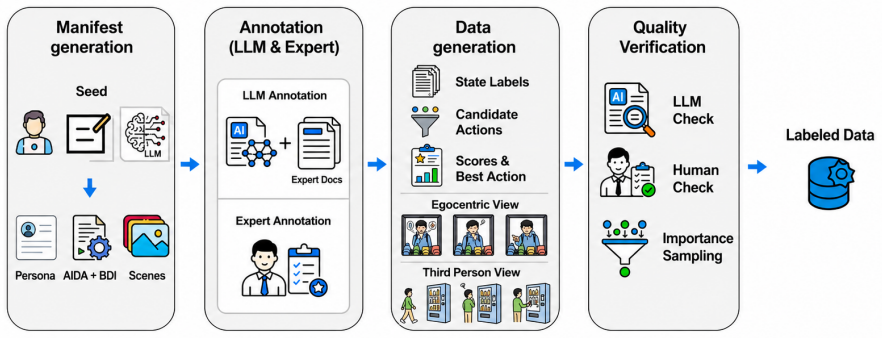
The Proactive Intent World Model represents customer state with AIDA purchasing phases and BDI psychological fields, predicts action-conditioned intent transitions, and selects from five response classes. Conditioned on ground-truth customer state it achieves 0.641 macro F1 on 30 held-out target videos, outperforming a zero-shot Qwen2.5-VL-7B baseline and ablations without balanced action supervision, while end-to-end video-only selection falls to 0.295 below the balanced random baseline of 0.414.
What carries the argument
The Proactive Intent World Model (PIWM) that encodes latent customer intent via AIDA phases and BDI fields to predict transitions and choose interventions.
If this is right
- PIWM with ground-truth state outperforms the zero-shot vision-language baseline and training variants that lack balanced action supervision.
- End-to-end video-only action selection yields 0.295 macro F1, below the five-class balanced random baseline.
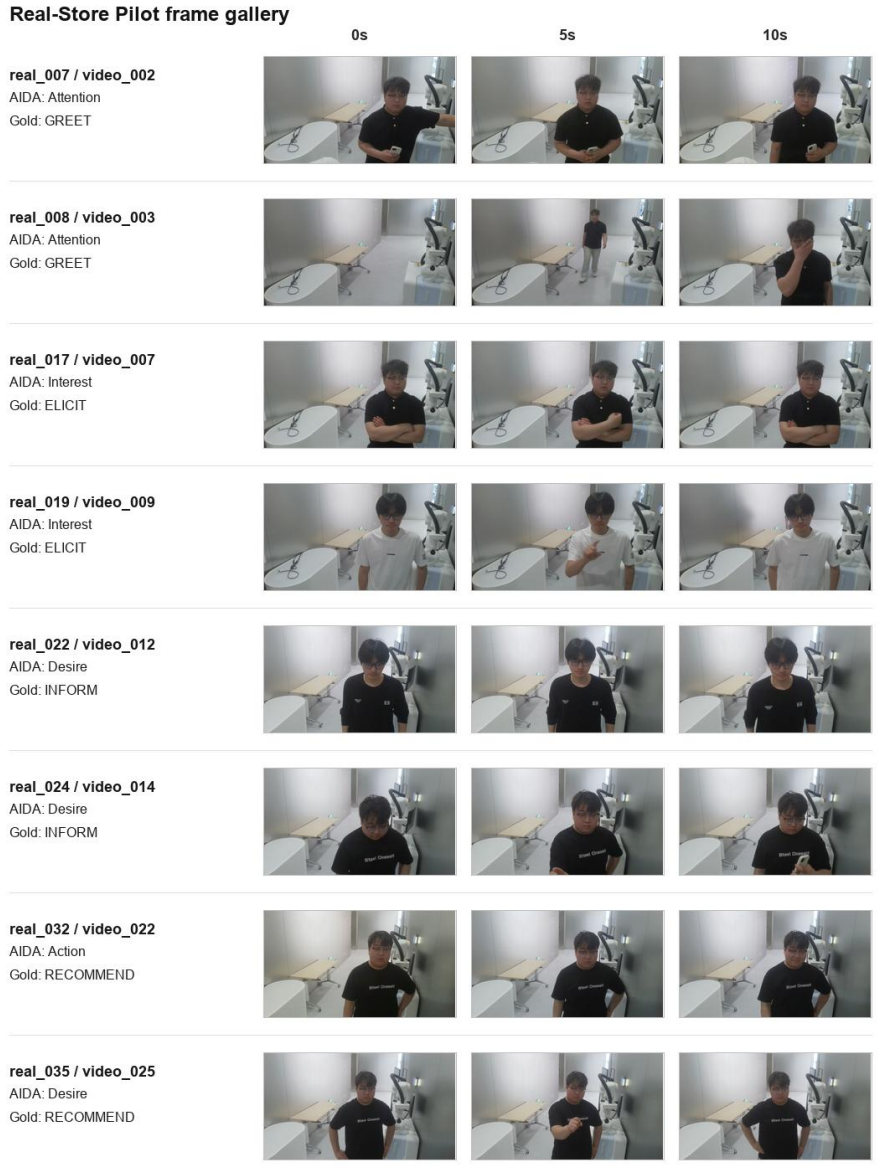
- A staged real-store pilot reaches 0.579 action macro F1 on 20 fully annotated videos.
- The GuidanceSalesBench benchmark supplies state manifests, pre-interaction videos, candidate responses, action-conditioned outcomes, and best-action labels.
Where Pith is reading between the lines
- If video-based inference of AIDA and BDI states improves, the performance gap between ground-truth and end-to-end settings could close.
- The same state-transition modeling could be tested in other goal-directed social settings such as healthcare intake or classroom tutoring.
- The additional index-labeled videos released from the pilot could be used to measure progress on the video-to-state subproblem independently.
Load-bearing premise
Accurate customer states consisting of AIDA phases and BDI fields can be obtained from video at deployment time.
What would settle it
An end-to-end video-only run of the model on the 30 held-out videos that yields macro F1 above the 0.414 random baseline would show that video-to-state grounding is not the dominant bottleneck.
Figures



read the original abstract
Multimodal retail agents should not only recognize what a customer is doing, but also decide whether and how to assist before an explicit request is made. We study this setting through the See--Infer--Intervene (SII) framework, where a device must see pre-interaction behavior, infer latent customer intent, and act by selecting an appropriate service intervention or choosing to wait. We instantiate SII with the Proactive Intent World Model (PIWM), which represents customer state with AIDA (Attention, Interest, Desire, Action) purchasing phases and BDI (belief, desire, intention) psychological fields, predicts action-conditioned intent transitions, and selects from five response classes: Greet, Elicit, Inform, Recommend, and Hold. We further construct GuidanceSalesBench, a smart-retail benchmark containing state manifests, pre-interaction videos, candidate responses, action-conditioned outcomes, and best-action labels. When conditioned on ground-truth customer state to isolate action selection, PIWM achieves 0.641 macro F1 on 30 held-out target videos, outperforming a zero-shot Qwen2.5-VL-7B baseline and training variants without balanced action supervision; end-to-end video-only selection drops to 0.295, below the 5-class balanced random baseline of 0.414, identifying video-to-state grounding as the dominant deployment-time bottleneck. A preliminary staged real-store pilot (recorded with paid participants performing scripted customer behaviors) reaches 0.579 action macro F1 on 20 fully annotated videos, with 10 additional accessible videos released with index-level labels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the See-Infer-Intervene (SII) framework instantiated via the Proactive Intent World Model (PIWM), which uses AIDA purchasing phases and BDI psychological fields to represent customer state, predict action-conditioned transitions, and select from five intervention classes (Greet, Elicit, Inform, Recommend, Hold). It introduces GuidanceSalesBench containing state manifests, videos, responses, and labels, and reports that PIWM achieves 0.641 macro F1 on 30 held-out videos when conditioned on ground-truth state (outperforming a zero-shot Qwen2.5-VL-7B baseline), while end-to-end video-only performance drops to 0.295 (below the 0.414 balanced random baseline); a small real-store pilot reaches 0.579 F1.
Significance. If the video-to-state grounding component can be made reliable, the SII/PIWM approach would provide a concrete, psychologically grounded model for proactive multimodal agents in retail settings, with the benchmark enabling reproducible evaluation of intent transitions and intervention policies. The explicit identification of the grounding bottleneck is a useful negative result, but the current numbers primarily demonstrate the difficulty of the inference step rather than a deployable solution.
major comments (2)
- [Abstract] Abstract: The headline result of 0.641 macro F1 is obtained only under oracle ground-truth AIDA/BDI state conditioning to isolate action selection; the paper's own end-to-end video-only result of 0.295 falls below the 5-class balanced random baseline of 0.414, directly undermining the claim that PIWM enables proactive, video-driven intervention at deployment time.
- [Abstract] Abstract and benchmark description: No details are provided on how the 30-video held-out split was constructed or whether it avoids leakage between state manifests and video content; without this, it is impossible to assess whether the reported gap between oracle and video-only conditions reflects a true generalization failure or an artifact of benchmark construction.
minor comments (2)
- [Abstract] The abstract mentions a preliminary staged pilot on 20 videos but provides no comparison to the benchmark results or details on how scripted behaviors map to the AIDA/BDI annotations.
- The five response classes are listed but the paper does not specify the exact decision procedure or loss used to train the action-selection head when ground-truth state is available.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where the abstract and benchmark description require greater precision to avoid misinterpretation of the results. We address each point below and will revise the manuscript to strengthen clarity while preserving the paper's core findings on the grounding bottleneck.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result of 0.641 macro F1 is obtained only under oracle ground-truth AIDA/BDI state conditioning to isolate action selection; the paper's own end-to-end video-only result of 0.295 falls below the 5-class balanced random baseline of 0.414, directly undermining the claim that PIWM enables proactive, video-driven intervention at deployment time.
Authors: We agree that the abstract's emphasis on the oracle result could lead readers to overstate deployability. The manuscript already reports the end-to-end drop to 0.295 (below the 0.414 baseline) and explicitly frames it as evidence that video-to-state grounding is the dominant bottleneck. The 0.641 figure isolates the action-selection component to demonstrate that the intervention policy itself is viable when state is known. To prevent any ambiguity, we will revise the abstract to lead with both results and their implications for deployment. revision: yes
-
Referee: [Abstract] Abstract and benchmark description: No details are provided on how the 30-video held-out split was constructed or whether it avoids leakage between state manifests and video content; without this, it is impossible to assess whether the reported gap between oracle and video-only conditions reflects a true generalization failure or an artifact of benchmark construction.
Authors: We acknowledge the omission of split-construction details. The 30-video held-out set was formed by partitioning on distinct customer scenarios and video recordings with no shared content or state-manifest overlap between partitions; state manifests were generated from separate annotations to minimize leakage. We will add an explicit subsection describing the split criteria, leakage safeguards, and scenario diversity in the revised benchmark section. revision: yes
Circularity Check
No circularity; framework applies established AIDA/BDI models to empirical benchmark evaluation
full rationale
The paper instantiates SII/PIWM using pre-existing AIDA purchasing phases and BDI psychological fields, constructs GuidanceSalesBench with state manifests and best-action labels, and reports macro F1 on held-out videos (0.641 with ground-truth state, 0.295 end-to-end). No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the explicit performance drop when removing the oracle state confirms the evaluation is not self-referential. The derivation chain consists of standard model application plus benchmark construction and measurement, with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AIDA purchasing phases and BDI psychological fields provide a sufficient representation of latent customer intent for intervention selection
invented entities (3)
-
See-Infer-Intervene (SII) framework
no independent evidence
-
Proactive Intent World Model (PIWM)
no independent evidence
-
GuidanceSalesBench
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025. https://arxiv.org/abs/2502.13923 Qwen2.5-vl technical report . Preprint, arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Brian P Bailey, Joseph A Konstan, and John V Carlis. 2000. Measuring the effects of interruptions on task performance in the user interface. In Smc 2000 conference proceedings. 2000 ieee international conference on systems, man and cybernetics.'cybernetics evolving to systems, humans, organizations, and their complex interactions'(cat. no. 0, volume 2, pa...
2000
-
[4]
Brian P Bailey, Joseph A Konstan, and John V Carlis. 2001. The effects of interruptions on task performance, annoyance, and anxiety in the user interface. In Interact, volume 1, pages 593--601
2001
-
[5]
Thomas E Barry. 1987. The development of the hierarchy of effects: An historical perspective. Current issues and Research in Advertising, 10(1-2):251--295
1987
-
[6]
Shuxian Bi, Wenjie Wang, Hang Pan, Fuli Feng, and Xiangnan He. 2024. Proactive recommendation with iterative preference guidance. In Companion Proceedings of the ACM Web Conference 2024, pages 871--874
2024
-
[8]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, and 1 others. 2023. https://arxiv.org/abs/2307.15818 Rt-2: Vision-language-action models transfer web knowledge to robotic control . In Conference on Robot Learning
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems, pages 159--166
1999
-
[15]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024. Video-llava: Learning united visual representation by alignment before projection. In Proceedings of the 2024 conference on empirical methods in natural language processing, pages 5971--5984
2024
-
[16]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. 2024. Video-chatgpt: Towards detailed video understanding via large vision and language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585--12602
2024
-
[17]
Leena Mathur, Paul Pu Liang, and Louis-Philippe Morency. 2024. Advancing social intelligence in ai agents: Technical challenges and open questions. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20541--20560
2024
-
[18]
David G Novick and Stephen Sutton. 1997. What is mixed-initiative interaction. In Proceedings of the AAAI spring symposium on computational models for mixed initiative interaction, volume 2, page 12
1997
-
[19]
Neil Rabinowitz, Frank Perbet, Francis Song, Chiyuan Zhang, SM Ali Eslami, and Matthew Botvinick. 2018. Machine theory of mind. In International conference on machine learning, pages 4218--4227. PMLR
2018
-
[20]
Anand S Rao, Michael P Georgeff, and 1 others. 1995. Bdi agents: from theory to practice. In Icmas, volume 95, pages 312--319
1995
-
[22]
Bharat Singh, Tim K Marks, Michael Jones, Oncel Tuzel, and Ming Shao. 2016. A multi-stream bi-directional recurrent neural network for fine-grained action detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1961--1970
2016
-
[24]
Cen Yan, Jun Bai, Yanmeng Wang, Wenge Rong, Yuanxin Ouyang, and Zhang Xiong. 2023. Goal-oriented conditional variational autoencoders for proactive and knowledge-aware conversational recommender system. Computer Speech & Language, 79:101468
2023
-
[25]
Bufang Yang, Lilin Xu, Liekang Zeng, Kaiwei Liu, Siyang Jiang, Wenrui Lu, Hongkai Chen, Xiaofan Jiang, Guoliang Xing, and Zhenyu Yan. 2025. Contextagent: Context-aware proactive llm agents with open-world sensory perceptions. Advances in Neural Information Processing Systems, 38:167509--167543
2025
- [26]
-
[29]
arXiv preprint arXiv:2305.02750 , year=
A survey on proactive dialogue systems: Problems, methods, and prospects , author=. arXiv preprint arXiv:2305.02750 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Contextagent: Context-aware proactive llm agents with open-world sensory perceptions , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Companion Proceedings of the ACM Web Conference 2024 , pages=
Proactive recommendation with iterative preference guidance , author=. Companion Proceedings of the ACM Web Conference 2024 , pages=
2024
-
[32]
Computer Speech & Language , volume=
Goal-oriented conditional variational autoencoders for proactive and knowledge-aware conversational recommender system , author=. Computer Speech & Language , volume=. 2023 , publisher=
2023
-
[33]
World models , author=. arXiv preprint arXiv:1803.10122 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Dream to Control: Learning Behaviors by Latent Imagination
Dream to control: Learning behaviors by latent imagination , author=. arXiv preprint arXiv:1912.01603 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[35]
World Action Models: The Next Frontier in Embodied AI
World Action Models: The Next Frontier in Embodied AI , author=. arXiv preprint arXiv:2605.12090 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
World Action Models are Zero-shot Policies
World action models are zero-shot policies , author=. arXiv preprint arXiv:2602.15922 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Current issues and Research in Advertising , volume=
The development of the hierarchy of effects: An historical perspective , author=. Current issues and Research in Advertising , volume=. 1987 , publisher=
1987
-
[38]
, author=
BDI agents: from theory to practice. , author=. Icmas , volume=
-
[39]
Proceedings of the AAAI spring symposium on computational models for mixed initiative interaction , volume=
What is mixed-initiative interaction , author=. Proceedings of the AAAI spring symposium on computational models for mixed initiative interaction , volume=
-
[40]
Smc 2000 conference proceedings
Measuring the effects of interruptions on task performance in the user interface , author=. Smc 2000 conference proceedings. 2000 ieee international conference on systems, man and cybernetics.'cybernetics evolving to systems, humans, organizations, and their complex interactions'(cat. no. 0 , volume=. 2000 , organization=
2000
-
[41]
PRISM: A Multi-View Multi-Capability Retail Video Dataset for Embodied Vision-Language Models , author=. arXiv preprint arXiv:2603.29281 , year=
-
[42]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
A multi-stream bi-directional recurrent neural network for fine-grained action detection , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[43]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[44]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Video-llava: Learning united visual representation by alignment before projection , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[45]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Video-chatgpt: Towards detailed video understanding via large vision and language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Do as i can, not as i say: Grounding language in robotic affordances , author=. arXiv preprint arXiv:2204.01691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
International conference on machine learning , pages=
Machine theory of mind , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[49]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Advancing social intelligence in ai agents: Technical challenges and open questions , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[50]
Proceedings of the SIGCHI conference on Human Factors in Computing Systems , pages=
Principles of mixed-initiative user interfaces , author=. Proceedings of the SIGCHI conference on Human Factors in Computing Systems , pages=
-
[51]
, author=
The Effects of Interruptions on Task Performance, Annoyance, and Anxiety in the User Interface. , author=. Interact , volume=
-
[52]
Conference on Robot Learning , year =
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control , author =. Conference on Robot Learning , year =
-
[53]
OpenVLA: An Open-Source Vision-Language-Action Model
OpenVLA: An Open-Source Vision-Language-Action Model , author =. arXiv preprint arXiv:2406.09246 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
_0 : A Vision-Language-Action Flow Model for General Robot Control , author =. arXiv preprint arXiv:2410.24164 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Advances in Neural Information Processing Systems , year =
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author =. Advances in Neural Information Processing Systems , year =
-
[56]
arXiv preprint arXiv:2410.20745 , year =
Shopping MMLU: A Massive Multi-Task Online Shopping Benchmark for Large Language Models , author =. arXiv preprint arXiv:2410.20745 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.