Operationalizing Cyber Attack Prediction: A Gap-Prioritized Framework with Dataset and Model Selection Guidelines
Pith reviewed 2026-06-28 09:55 UTC · model grok-4.3
The pith
A gap-prioritization framework ranks dataset obsolescence and adversarial robustness as the top barriers to operational cyber attack prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
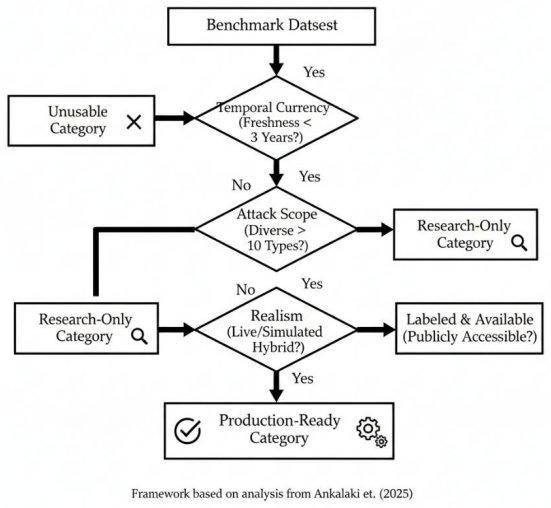
The central claim is that a gap-prioritization framework, which scores five implementation hurdles on detection impact, implementation cost, and remediation time, reveals temporal dataset obsolescence and inadequate adversarial robustness as the highest-priority gaps in AI-driven cyber attack prediction, while real-time model interpretability represents the most cost-effective improvement path for resource-limited settings. Supported by the review of 150+ benchmarks and 200+ studies, the framework yields a dataset quality assessment that classifies 45 benchmarks into production-ready, research-only, and unusable categories together with a practical implementation roadmap.
What carries the argument
The gap-prioritization framework that evaluates the five hurdles—temporal dataset obsolescence, narrow attack scope, real-time model interpretability, inadequate adversarial robustness, and privacy/ethical concerns—by scoring each on detection impact, implementation cost, and remediation time.
If this is right
- Fixing temporal dataset obsolescence will produce the largest gains in sustained detection performance.
- Resource-constrained teams achieve faster returns by addressing model interpretability before adversarial robustness.
- The classification of 45 benchmarks into production-ready, research-only, and unusable categories allows direct selection of data suitable for live systems.
- The implementation roadmap translates the ranked gaps into sequenced steps that reduce the gap between research and production cyber defense.
Where Pith is reading between the lines
- The same three-criteria scoring approach could be applied to gap analysis in other AI security domains such as fraud detection or malware classification.
- Pilot deployments that measure actual remediation times against the framework's estimates would provide empirical calibration of the prioritization scores.
- Linking the dataset quality categories to existing cybersecurity certification processes could speed adoption of the recommended benchmarks.
Load-bearing premise
The 150+ datasets and 200+ studies reviewed form a representative sample of the field and the three evaluation criteria correctly capture what matters most for operational deployment.
What would settle it
An operational deployment study that tracks real-world failure modes and finds narrow attack scope or privacy concerns produce more system failures than dataset obsolescence or lack of adversarial robustness.
Figures
read the original abstract
While AI and machine learning for cyber attack prediction have advanced, a critical gap persists between theoretical research and practical operational deployment. Building on Ankalaki et al. (2025), this paper provides a comprehensive analysis of 150+ benchmark datasets and 200+ studies to identify and prioritize five implementation hurdles: (1) temporal dataset obsolescence, (2) narrow attack scope, (3) real-time model interpretability, (4) inadequate adversarial robustness, and (5) privacy/ethical concerns. We introduce a novel gap-prioritization framework that evaluates these limitations based on detection impact, implementation cost, and remediation time. Our analysis identifies dataset obsolescence and adversarial robustness as the highest-priority gaps, while highlighting model interpretability as the most cost-effective path for resource-constrained environments. To bridge the research-practice divide, we provide a practical implementation roadmap and a dataset quality assessment framework that classifies 45 benchmarks into production-ready, research-only, and unusable categories. This work translates academic findings into actionable decision-support tools for robust, production-oriented AI-driven cyber defense.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a gap between theoretical AI/ML cyber attack prediction research and operational deployment can be addressed via a novel prioritization framework. Based on a review of 150+ datasets and 200+ studies, it identifies five hurdles (temporal dataset obsolescence, narrow attack scope, real-time model interpretability, inadequate adversarial robustness, privacy/ethical concerns) and ranks them using three criteria (detection impact, implementation cost, remediation time). Dataset obsolescence and adversarial robustness are deemed highest priority while interpretability is the most cost-effective for resource-constrained settings. The work supplies a dataset quality assessment framework classifying 45 benchmarks into production-ready/research-only/unusable categories plus an implementation roadmap, building on Ankalaki et al. (2025).
Significance. If the review sample is representative and the three criteria validly reflect deployment realities, the framework and benchmark classification could offer practitioners concrete decision-support tools for selecting datasets and models, helping translate academic results into production cyber defense. The explicit categorization of 45 benchmarks and the roadmap are practical strengths that go beyond pure literature summary.
major comments (2)
- [Abstract and framework description] The central prioritization of gaps (dataset obsolescence and adversarial robustness as highest) rests on the claim of having reviewed a representative sample of 150+ datasets and 200+ studies, yet no search protocol, databases, keywords, date range, or inclusion/exclusion criteria are stated anywhere in the manuscript. Without this, it is impossible to verify representativeness or rule out post-hoc selection, directly undermining the gap-ranking results.
- [Gap-prioritization framework] The three evaluation criteria (detection impact, implementation cost, remediation time) are introduced and applied to classify gaps and recommend interpretability as most cost-effective, but the manuscript provides no justification, validation against operational data, or sensitivity analysis showing why these three (rather than, e.g., false-positive cost or regulatory compliance) best capture deployment priorities. This choice is load-bearing for the final recommendations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of transparency and methodological rigor. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and framework description] The central prioritization of gaps (dataset obsolescence and adversarial robustness as highest) rests on the claim of having reviewed a representative sample of 150+ datasets and 200+ studies, yet no search protocol, databases, keywords, date range, or inclusion/exclusion criteria are stated anywhere in the manuscript. Without this, it is impossible to verify representativeness or rule out post-hoc selection, directly undermining the gap-ranking results.
Authors: We agree that the absence of an explicit search protocol, including databases consulted, keywords, date range, and inclusion/exclusion criteria, is a limitation that prevents independent verification of the sample's representativeness. The manuscript currently states the totals reviewed but does not detail the systematic process. In the revised version, we will add a new subsection (likely in Section 3 or as an appendix) that fully documents the review methodology: search strings, sources (IEEE Xplore, ACM DL, arXiv, Google Scholar), temporal bounds, and selection criteria. This addition will directly address the concern and allow readers to assess potential selection bias. revision: yes
-
Referee: [Gap-prioritization framework] The three evaluation criteria (detection impact, implementation cost, remediation time) are introduced and applied to classify gaps and recommend interpretability as most cost-effective, but the manuscript provides no justification, validation against operational data, or sensitivity analysis showing why these three (rather than, e.g., false-positive cost or regulatory compliance) best capture deployment priorities. This choice is load-bearing for the final recommendations.
Authors: We acknowledge that the manuscript introduces the three criteria without providing explicit justification for their selection over alternatives, nor does it include validation against real-world operational datasets or sensitivity analysis. While the criteria were chosen to reflect core deployment trade-offs discussed in cybersecurity literature, this rationale is not articulated in the current text. In revision, we will expand the framework section to include: (1) a literature-based justification for the three criteria, (2) discussion of why alternatives such as false-positive cost were not primary, and (3) a brief sensitivity analysis showing how rankings change under plausible alternative weightings. This will make the prioritization more robust and transparent. revision: yes
Circularity Check
No significant circularity; standard literature review with author-defined but externally applied criteria
full rationale
The paper conducts a literature review of 150+ datasets and 200+ studies, introduces a gap-prioritization framework using three explicit criteria (detection impact, implementation cost, remediation time), and applies it to classify gaps and 45 benchmarks. No equations, fitted parameters, or predictions reduce to inputs by construction. The framework is defined first and then used to evaluate external literature; conclusions follow from that application rather than tautological redefinition. The single citation to Ankalaki et al. (2025) is not load-bearing for the prioritization logic. This matches the default expectation of a non-circular review paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ankalaki, S., Atmakuri, A. R., Pallavi, M., Hukkeri, G. S., Jan, T., & Naik, G. R. (2025). Cyber attack prediction: From traditional machine learning to generative artificial intelligence. IEEE Access, 13, 44662-44706. https://doi.org/10.1109/ACCESS.2025.3547433 Butler, J. (2022). Cryptocurrency and blockchain technology in financial crime. Journal of Fin...
-
[2]
Wasserman, S., & Faust, K. (1994). Social network analysis: Methods and applications . Cambridge University Press. https://doi.org/10.1017/CBO9780511815478
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.