Topology-Aware Gaussian Graph Repair for Robust Graph Neural Networks
Pith reviewed 2026-06-28 11:32 UTC · model grok-4.3
The pith
A sparse Gaussian kernel on node features plus residual topology correction repairs imperfect graphs so standard GNNs regain accuracy without architecture changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
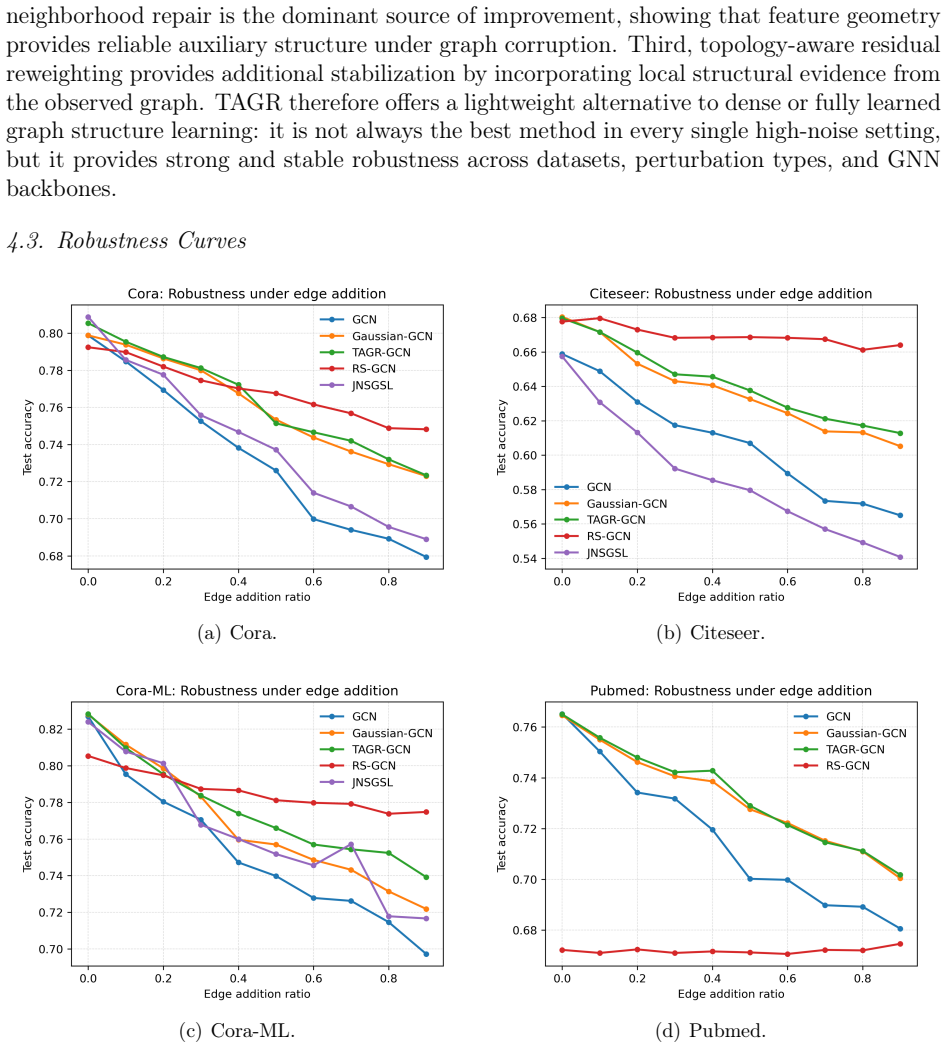
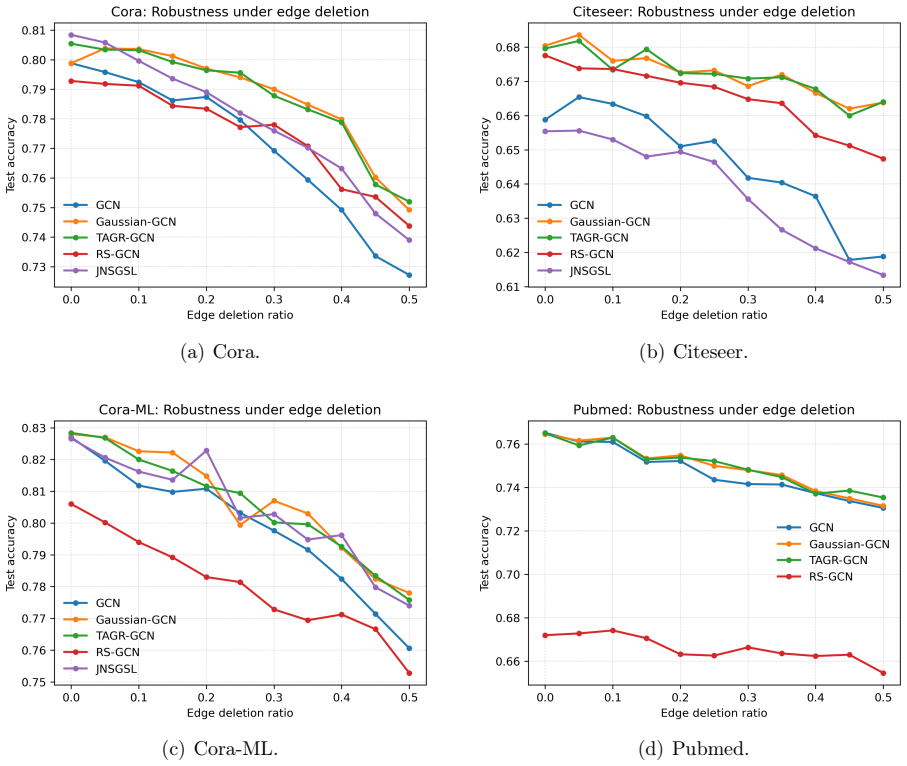
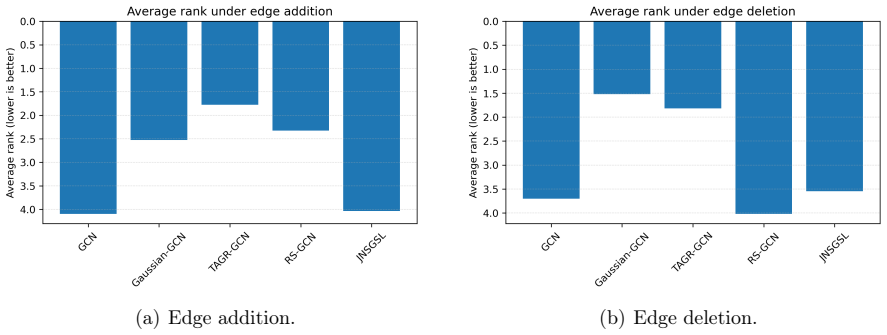
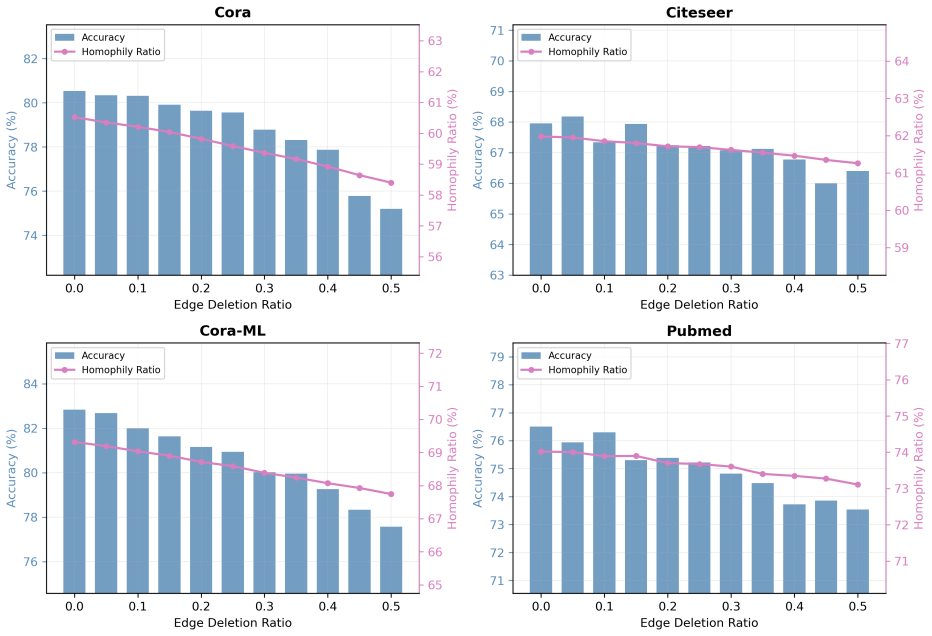
Topology-Aware Gaussian Repair builds a sparse feature-neighborhood graph with an adaptive Gaussian kernel on node features, then adds a topology-aware residual correction to the observed adjacency that preserves and reweights edges according to local consistency, producing a repaired graph that raises downstream GNN accuracy on noisy or incomplete inputs.
What carries the argument
Adaptive Gaussian kernel that adds edges between feature-similar nodes, combined with a residual correction term that adjusts the original topology based on feature and structural agreement.
If this is right
- The repaired graph can be used directly with any standard GNN architecture.
- The Gaussian feature-neighborhood component supplies the primary robustness improvement.
- The residual correction term improves stability specifically when many edges are missing.
- No dense adjacency matrix or additional training objectives are required.
Where Pith is reading between the lines
- The same repair step could be inserted before other graph tasks such as link prediction or graph classification.
- Performance on very large or time-varying graphs remains untested and would require checking whether the kernel computation scales linearly.
- The method could be combined with existing noise-robust training losses to test additive gains.
Load-bearing premise
An adaptive Gaussian kernel on node features combined with a topology-aware residual correction produces a repaired graph that yields higher downstream GNN accuracy without new optimization complexity or architecture changes.
What would settle it
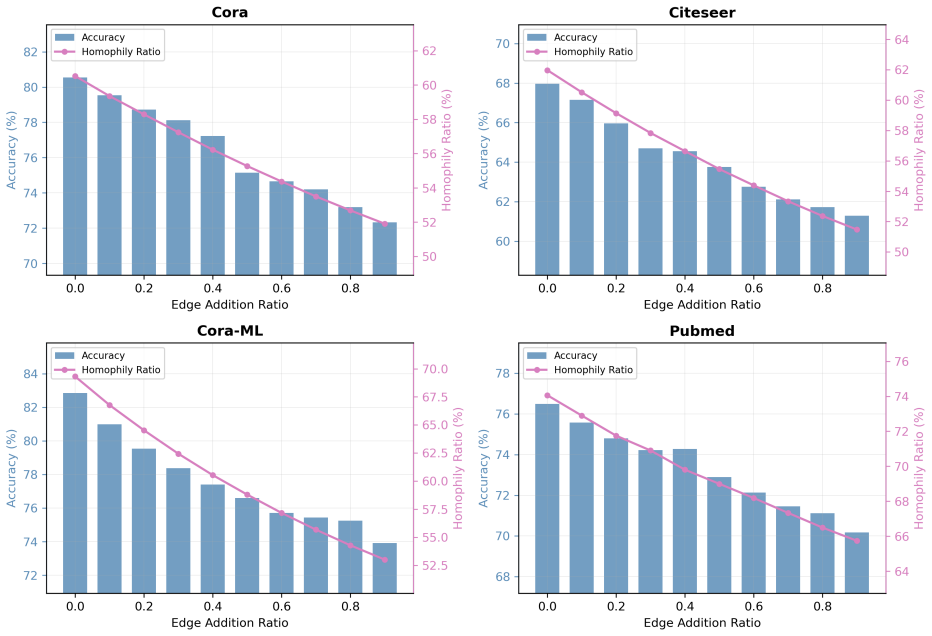
On a standard citation network with 20 percent added random edges or 20 percent removed edges, measure whether the repaired graph produces higher node-classification accuracy than the original graph and than competing edge-removal or structure-learning baselines; failure to exceed both would falsify the robustness claim.
Figures
read the original abstract
Graph neural networks have achieved strong performance on graph-structured data, but their effectiveness depends heavily on the quality of the observed graph. In real applications, graph topology is often imperfect: noisy edges may connect unrelated nodes, while missing edges may prevent useful information from being propagated. Existing robust graph learning methods mainly address this problem by removing suspicious edges or by learning a new graph structure during training. However, edge removal alone cannot recover missing connections, and graph structure learning may introduce additional optimization complexity. In this paper, we propose Topology-Aware Gaussian Repair (TAGR), a simple graph repair framework for robust message passing in graph neural networks. Instead of learning a dense adjacency matrix, TAGR constructs a sparse feature-neighborhood graph using an adaptive Gaussian kernel and combines it with a topology-aware residual correction of the observed graph. The Gaussian repair component introduces auxiliary edges between feature-similar nodes, while the residual correction preserves and reweights the original topology according to local feature and structural consistency. The repaired graph can be used directly with standard graph neural networks without changing their architectures. Extensive experiments on benchmark citation networks show that TAGR improves the robustness of GNNs under both noisy-edge and missing-edge settings. The analysis further show that Gaussian feature-neighborhood repair provides the main robustness gain, while topology-aware residual correction improves stability when the observed graph is incomplete. These results suggest that effective graph robustness can be achieved through lightweight sparse graph repair rather than dense graph structure learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
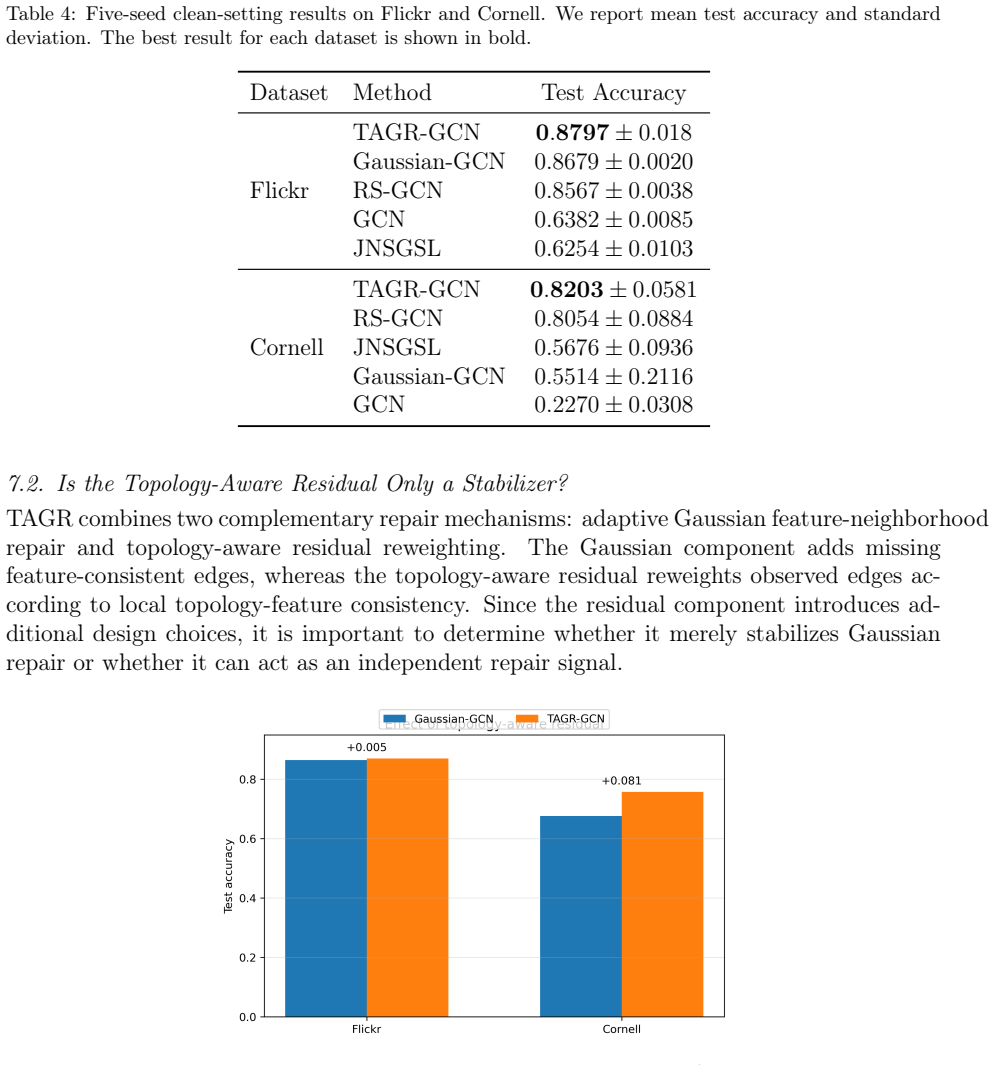
Summary. The manuscript introduces Topology-Aware Gaussian Repair (TAGR), a lightweight preprocessing framework that repairs imperfect graph topologies for standard GNNs. TAGR builds a sparse auxiliary graph by applying an adaptive Gaussian kernel to node features and augments it with a topology-aware residual correction that reweights the observed adjacency according to local feature and structural consistency. The resulting repaired graph is fed directly into unmodified GNN architectures. Experiments on citation-network benchmarks under synthetic noisy-edge and missing-edge corruptions report improved node-classification accuracy; ablations attribute the primary robustness gain to the Gaussian component and additional stability on incomplete graphs to the residual term.
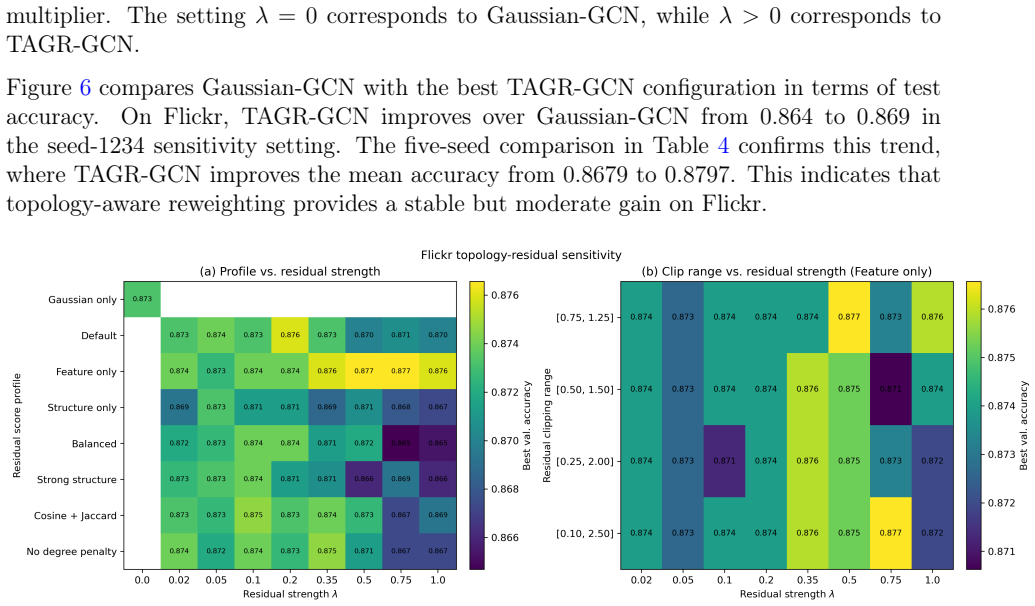
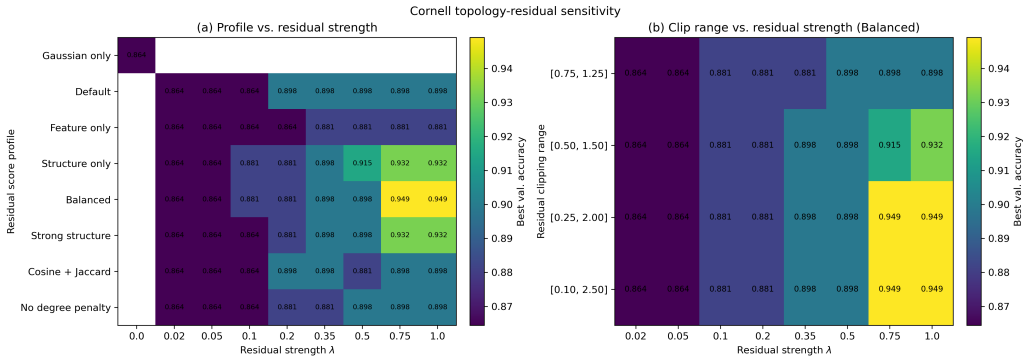
Significance. If the empirical gains hold under the reported conditions, TAGR offers a practical, low-complexity alternative to dense graph-structure-learning approaches by remaining sparse and avoiding extra optimization loops or architectural changes. The explicit ablation separating the two repair components supplies a clear mechanistic insight that is often missing from robustness papers. The method is internally consistent with the stated assumptions and could be directly applicable to citation and similar feature-rich graphs.
minor comments (3)
- The abstract states that 'extensive experiments on benchmark citation networks show that TAGR improves the robustness' yet supplies no numerical deltas, dataset names, or error-bar information; adding at least one representative accuracy table or figure reference would strengthen the summary.
- The description of the adaptive Gaussian kernel bandwidth as a free parameter is noted, but the manuscript does not clarify whether this hyper-parameter is tuned on a validation split or fixed across all corruption levels; an explicit statement in the experimental protocol would remove ambiguity.
- Dataset statistics (number of nodes, edges, features, classes, and train/val/test splits) and the precise corruption generation procedure (noise rate, missing-edge fraction) are referenced only generically; these details should appear in §4 or a dedicated table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. The recognition of TAGR's practical advantages as a sparse alternative to dense structure learning, along with the value of the component ablations, is appreciated.
Circularity Check
No significant circularity detected
full rationale
The paper presents TAGR as an explicit constructive procedure: an adaptive Gaussian kernel builds a sparse feature-neighborhood graph that is then additively combined with a topology-aware residual correction of the observed adjacency. All performance claims rest on downstream empirical evaluation (citation-network benchmarks under edge noise and missing-edge corruptions) plus standard ablation experiments that isolate the Gaussian component versus the residual term. No equation, theorem, or central claim reduces the reported accuracy gains to a quantity defined by the same fitted parameters, to a self-citation chain, or to an ansatz smuggled from prior work by the same authors. The method is architecture-agnostic and does not invoke uniqueness results or parameter-fitting loops that would force the outcome by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive Gaussian kernel bandwidth
axioms (1)
- domain assumption Gaussian kernel produces useful similarity edges for feature vectors
Reference graph
Works this paper leans on
-
[3]
Advances in neural information processing systems , volume=
Inductive representation learning on large graphs , author=. Advances in neural information processing systems , volume=
-
[5]
International conference on machine learning , pages=
Robust graph representation learning via neural sparsification , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[6]
arXiv preprint arXiv:2411.07672 , year=
Rethinking structure learning for graph neural networks , author=. arXiv preprint arXiv:2411.07672 , year=
-
[7]
Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
Efficient topology-aware data augmentation for high-degree graph neural networks , author=. Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[8]
Proceedings of the 14th ACM international conference on web search and data mining , pages=
Learning to drop: Robust graph neural network via topological denoising , author=. Proceedings of the 14th ACM international conference on web search and data mining , pages=
-
[9]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Graph structure learning for robust graph neural networks , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[10]
International conference on machine learning , pages=
Learning discrete structures for graph neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[11]
Proceedings of the aaai conference on artificial intelligence , volume=
Data augmentation for graph neural networks , author=. Proceedings of the aaai conference on artificial intelligence , volume=
-
[12]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Homophily-enhanced self-supervision for graph structure learning: Insights and directions , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2023 , publisher=
2023
-
[13]
Advances in neural information processing systems , volume=
Convolutional neural networks on graphs with fast localized spectral filtering , author=. Advances in neural information processing systems , volume=
-
[14]
Spectral Networks and Locally Connected Networks on Graphs
Spectral networks and locally connected networks on graphs. arXiv 2013 , author=. arXiv preprint arXiv:1312.6203 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[15]
International conference on machine learning , pages=
Simplifying graph convolutional networks , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[16]
Revisiting Graph Neural Networks: All We Have is Low-Pass Filters
Revisiting graph neural networks: All we have is low-pass filters , author=. arXiv preprint arXiv:1905.09550 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[17]
Proceedings of the 13th international conference on web search and data mining , pages=
All you need is low (rank) defending against adversarial attacks on graphs , author=. Proceedings of the 13th international conference on web search and data mining , pages=
-
[18]
Neurocomputing , volume=
Graph structure learning with joint node and structural feature representation for node classification , author=. Neurocomputing , volume=. 2026 , publisher=
2026
-
[19]
Proceedings of the fifteenth ACM international conference on web search and data mining , pages=
Towards robust graph neural networks for noisy graphs with sparse labels , author=. Proceedings of the fifteenth ACM international conference on web search and data mining , pages=
-
[20]
Joint European conference on machine learning and knowledge discovery in databases , pages=
Graph-revised convolutional network , author=. Joint European conference on machine learning and knowledge discovery in databases , pages=. 2020 , organization=
2020
-
[21]
Towards robust graph neural networks for noisy graphs with sparse labels
Enyan Dai, Wei Jin, Hui Liu, and Suhang Wang. Towards robust graph neural networks for noisy graphs with sparse labels. In Proceedings of the fifteenth ACM international conference on web search and data mining, pages 181--191, 2022
2022
-
[22]
All you need is low (rank) defending against adversarial attacks on graphs
Negin Entezari, Saba A Al-Sayouri, Amirali Darvishzadeh, and Evangelos E Papalexakis. All you need is low (rank) defending against adversarial attacks on graphs. In Proceedings of the 13th international conference on web search and data mining, pages 169--177, 2020
2020
-
[23]
Learning discrete structures for graph neural networks
Luca Franceschi, Mathias Niepert, Massimiliano Pontil, and Xiao He. Learning discrete structures for graph neural networks. In International conference on machine learning, pages 1972--1982. PMLR, 2019
1972
-
[24]
Inductive representation learning on large graphs
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. Advances in neural information processing systems, 30, 2017
2017
-
[25]
Graph structure learning for robust graph neural networks
Wei Jin, Yao Ma, Xiaorui Liu, Xianfeng Tang, Suhang Wang, and Jiliang Tang. Graph structure learning for robust graph neural networks. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 66--74, 2020
2020
-
[26]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
Graph structure learning with joint node and structural feature representation for node classification
Huawei Liu, Junsheng Wu, Weigang Li, and Xiaoqing Yu. Graph structure learning with joint node and structural feature representation for node classification. Neurocomputing, 663: 0 132002, 2026
2026
-
[28]
Learning to drop: Robust graph neural network via topological denoising
Dongsheng Luo, Wei Cheng, Wenchao Yu, Bo Zong, Jingchao Ni, Haifeng Chen, and Xiang Zhang. Learning to drop: Robust graph neural network via topological denoising. In Proceedings of the 14th ACM international conference on web search and data mining, pages 779--787, 2021
2021
-
[29]
Dropedge: Towards deep graph convolutional networks on node classification
Yu Rong, Wenbing Huang, Tingyang Xu, and Junzhou Huang. Dropedge: Towards deep graph convolutional networks on node classification. arXiv preprint arXiv:1907.10903, 2019
-
[30]
Petar Veli c kovi \'c , Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Simplifying graph convolutional networks
Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. In International conference on machine learning, pages 6861--6871. Pmlr, 2019
2019
-
[32]
Graph-revised convolutional network
Donghan Yu, Ruohong Zhang, Zhengbao Jiang, Yuexin Wu, and Yiming Yang. Graph-revised convolutional network. In Joint European conference on machine learning and knowledge discovery in databases, pages 378--393. Springer, 2020
2020
-
[33]
Data augmentation for graph neural networks
Tong Zhao, Yozen Liu, Leonardo Neves, Oliver Woodford, Meng Jiang, and Neil Shah. Data augmentation for graph neural networks. In Proceedings of the aaai conference on artificial intelligence, volume 35, pages 11015--11023, 2021
2021
-
[34]
Robust graph representation learning via neural sparsification
Cheng Zheng, Bo Zong, Wei Cheng, Dongjin Song, Jingchao Ni, Wenchao Yu, Haifeng Chen, and Wei Wang. Robust graph representation learning via neural sparsification. In International conference on machine learning, pages 11458--11468. PMLR, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.