Rethinking the Role of Tensor Decompositions in Post-Training LLM Compression
Pith reviewed 2026-06-28 11:29 UTC · model grok-4.3
The pith
Tensor decompositions are limited for post-training LLM compression because their shared-subspace assumption conflicts with the heterogeneous representations these models learn.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Tensor decompositions presuppose that model weights can be expressed through shared subspaces amenable to low-rank factorization, yet the representations learned by contemporary LLMs are heterogeneous and resist such sharing, which bounds the compression ratios achievable without accuracy degradation.
What carries the argument
The mismatch between the shared subspaces required by tensor decompositions and the heterogeneous representations learned by LLMs.
If this is right
- Compression ratios from tensor methods decline as model scale and representation diversity increase.
- Other post-training techniques become preferable for large-scale LLM deployment.
- Tensor methods retain utility mainly for smaller models or selected layers that exhibit more shared structure.
- Deployment pipelines should incorporate checks for representation heterogeneity before applying tensor compression.
Where Pith is reading between the lines
- Compression approaches that enforce uniformity across weights may face analogous limits in other large-scale neural architectures.
- Layer-wise or component-specific adaptations could be tested to see whether they relax the subspace mismatch.
- The same evaluation protocol could be applied to newer model families to map how the mismatch evolves with training data or architecture changes.
Load-bearing premise
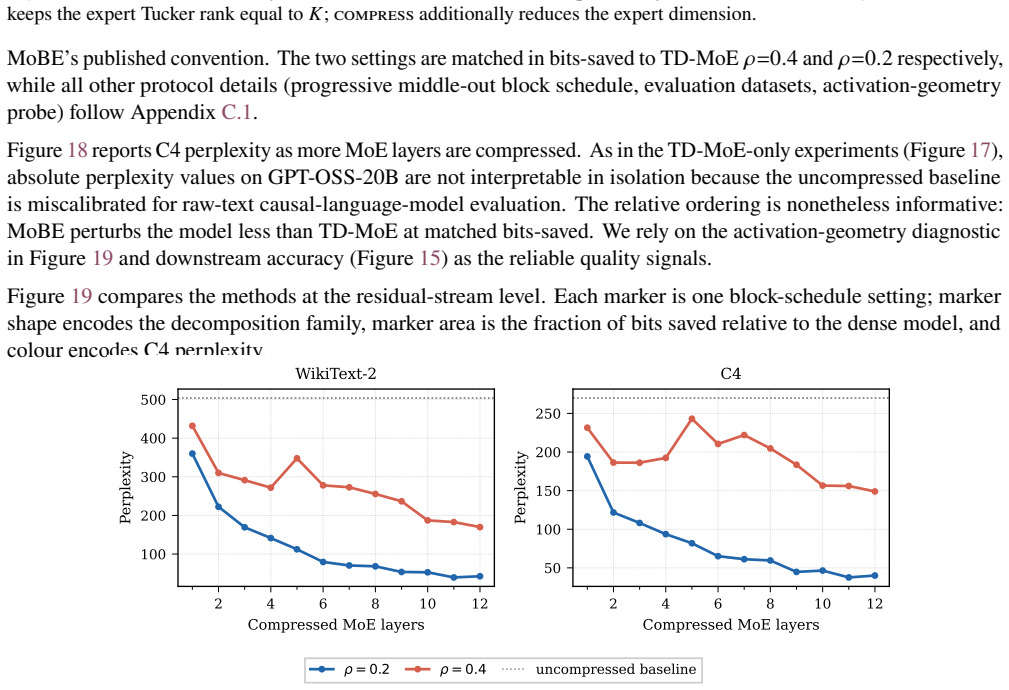
The systematic evaluation across dense and MoE architectures together with the accompanying theoretical analysis suffice to establish the mismatch as a general property rather than an artifact of the specific models examined.
What would settle it
A demonstration that tensor decomposition achieves high compression ratios on a large modern LLM while preserving near-original accuracy would falsify the mismatch as a limiting factor.
Figures


read the original abstract
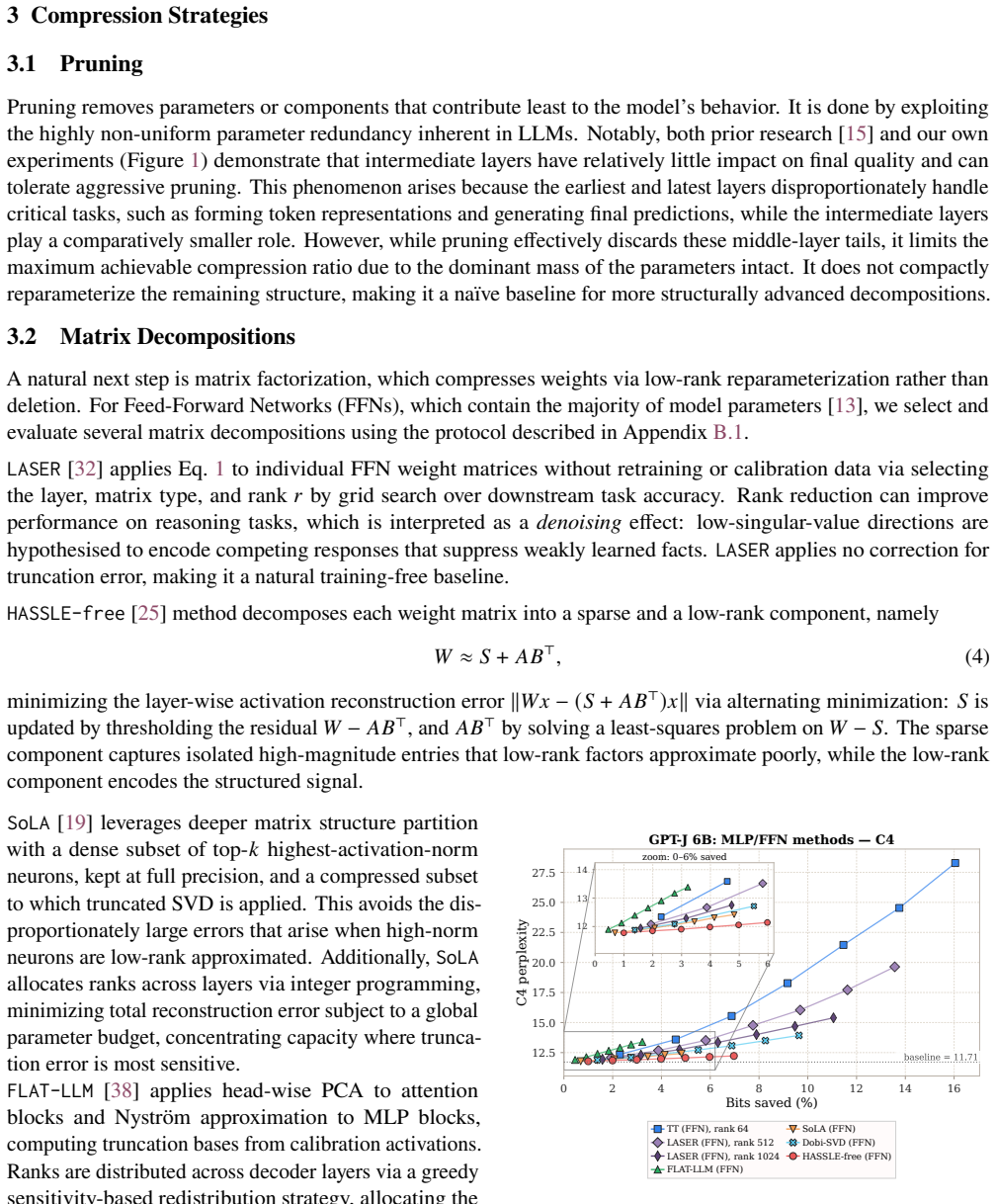
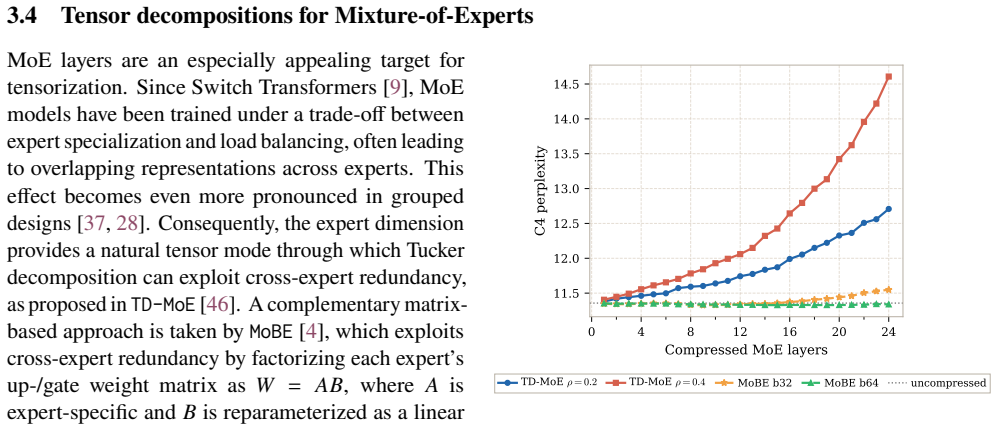
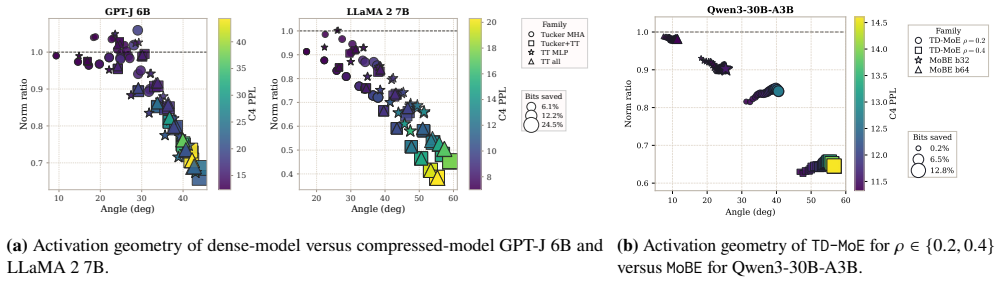
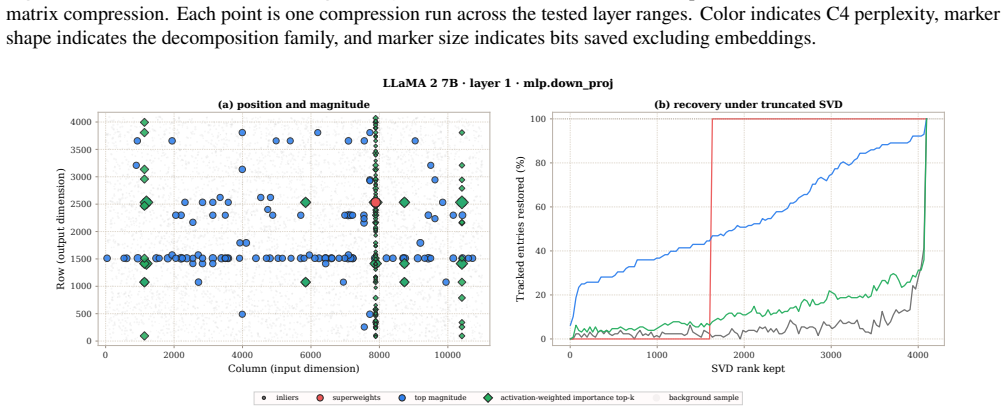
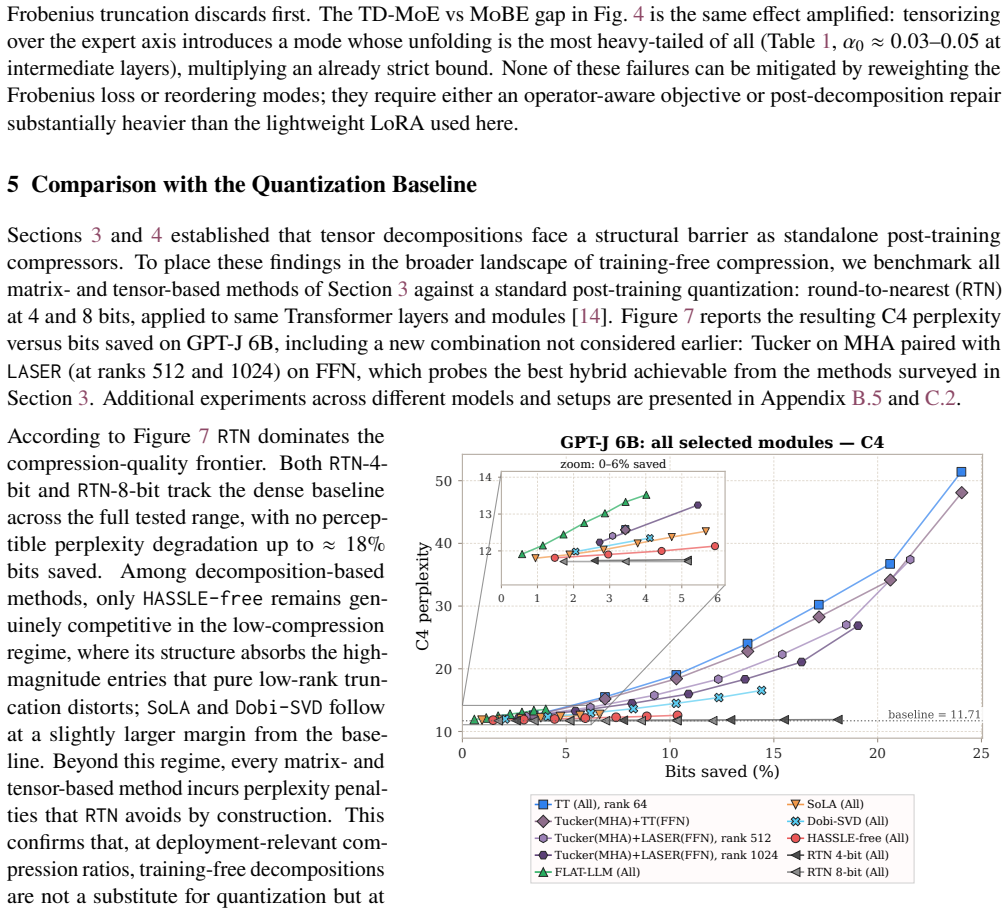
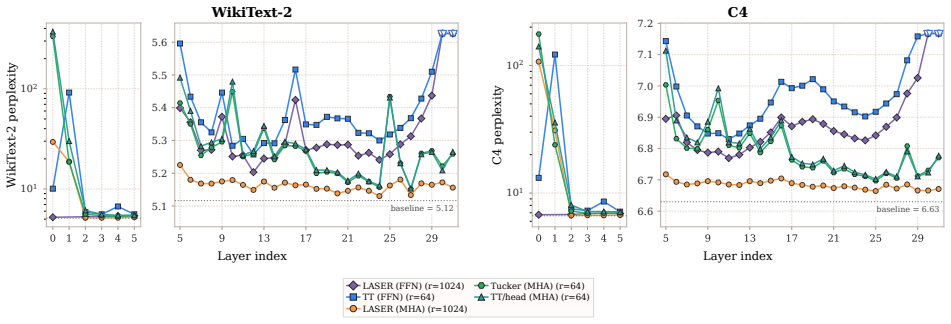
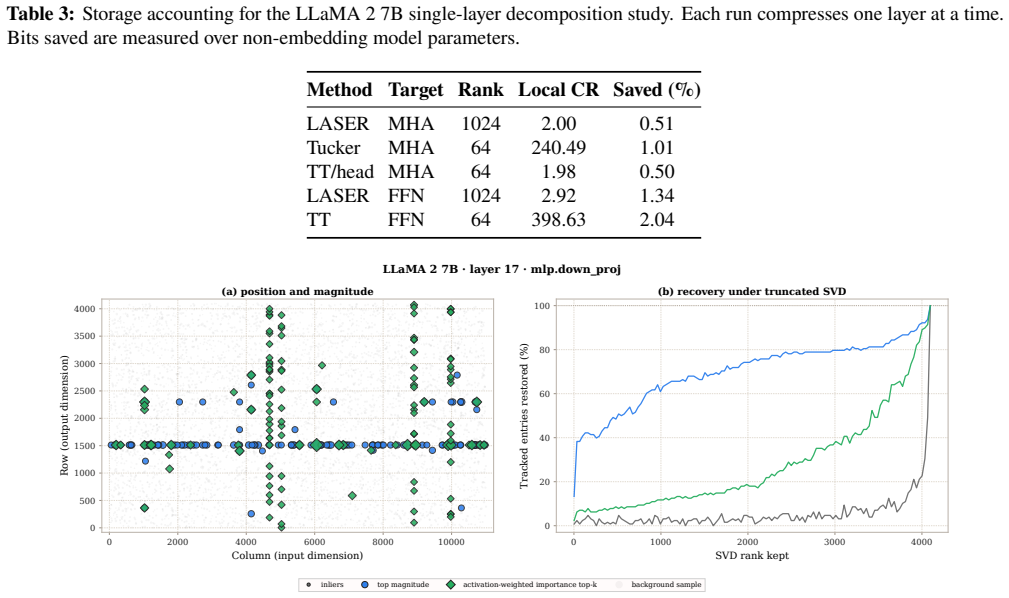
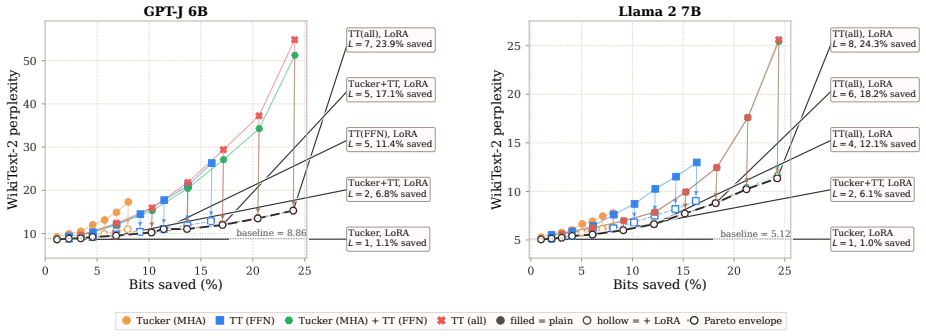
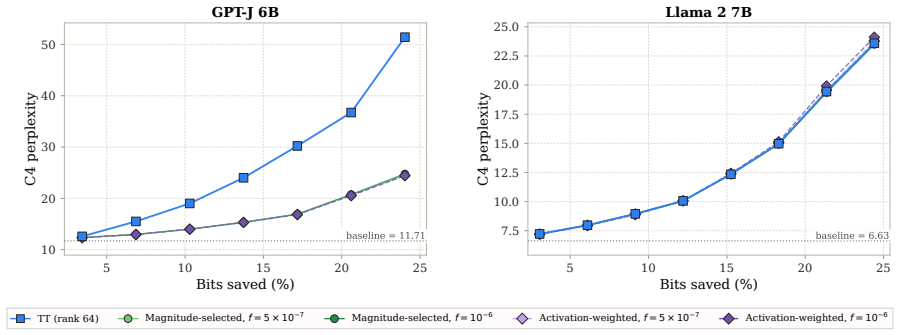
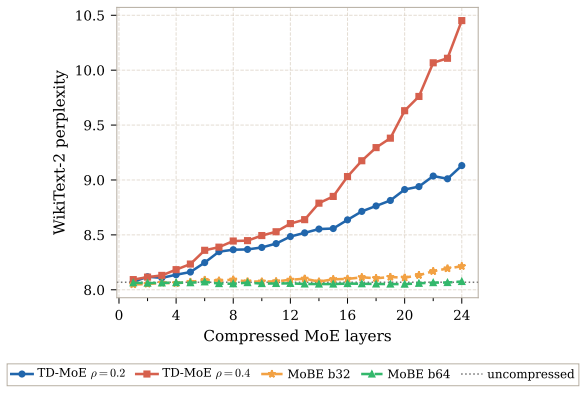
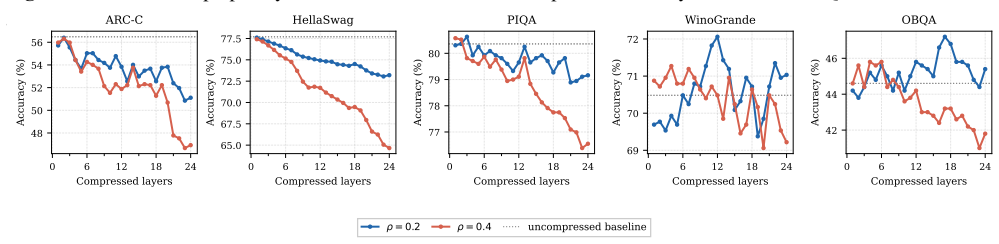
Post-training compression is essential for deploying large language models (LLMs) under tight resource constraints. Tensor decompositions have emerged as a promising direction, offering compact parameterizations well suited to Transformer weight structures. However, existing studies evaluate these methods in narrow settings, leaving unclear whether tensorization is effective at large-scale deployment. We systematically evaluate tensor compression across dense and MoE architectures, establishing performance trade-offs grounded in both empirical analysis and theoretical analysis. We identify a fundamental mismatch between the shared subspaces assumed by tensor decompositions and the heterogeneous representations learned by modern LLMs, thereby delineating their practical limits and clarifying their viable role in large-scale deployment. The code is available at https://github.com/brain-lab-research/TT-LLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tensor decompositions for post-training compression of LLMs are limited by a fundamental mismatch between their shared-subspace assumptions and the heterogeneous representations learned by modern LLMs. This is supported by systematic empirical evaluation across dense and MoE architectures together with theoretical analysis, which together delineate the practical limits and viable role of these methods at large scale. Code is released for reproducibility.
Significance. If the mismatch holds as a general property, the work would usefully constrain expectations for tensor-based compression in LLM deployment and redirect effort toward methods better matched to heterogeneous representations. The combination of dense/MoE coverage and open code strengthens the contribution relative to prior narrow evaluations.
major comments (2)
- [§4] §4 (theoretical analysis): the argument that the mismatch is fundamental rather than an artifact of the tested decompositions requires an explicit demonstration that no tensor decomposition (not merely the ones evaluated) can capture the observed heterogeneity; the current framing risks reducing to an empirical observation about specific factorizations.
- [§5] §5 (experiments): the claim that the mismatch is a general property of modern LLMs rests on the assumption that the selected dense and MoE models plus training regimes are representative; without additional controls (e.g., varying pre-training objectives or scales beyond those tested), the generality conclusion remains under-supported relative to the central claim.
minor comments (2)
- [§3.2] Notation for subspace overlap metrics in §3.2 is introduced without a clear reference to prior tensor literature; adding one or two citations would improve traceability.
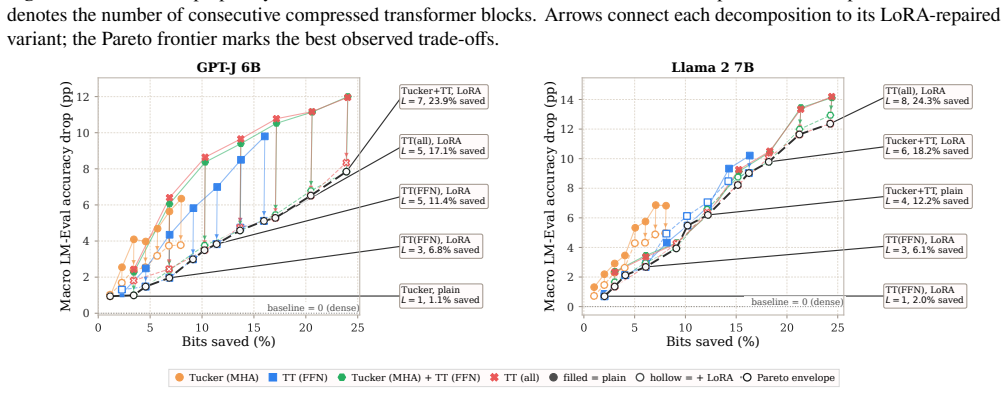
- [Figure 2] Figure 2 caption does not state the number of random seeds or whether error bars reflect standard deviation across runs; this affects interpretability of the reported trade-offs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the major comments and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§4] §4 (theoretical analysis): the argument that the mismatch is fundamental rather than an artifact of the tested decompositions requires an explicit demonstration that no tensor decomposition (not merely the ones evaluated) can capture the observed heterogeneity; the current framing risks reducing to an empirical observation about specific factorizations.
Authors: The theoretical analysis rests on the defining property of tensor decompositions: they express a tensor as a multilinear combination of shared factors across modes. This shared-subspace structure is common to the entire family of decompositions (CP, Tucker, TT, etc.) and is not limited to the specific factorizations we evaluated. We will revise §4 to state the argument in this general form, showing that any method relying on shared low-rank factors cannot accommodate the observed per-layer heterogeneity without rank inflation that negates compression benefits. revision: yes
-
Referee: [§5] §5 (experiments): the claim that the mismatch is a general property of modern LLMs rests on the assumption that the selected dense and MoE models plus training regimes are representative; without additional controls (e.g., varying pre-training objectives or scales beyond those tested), the generality conclusion remains under-supported relative to the central claim.
Authors: The evaluated models span current dense and MoE architectures at multiple scales and were chosen as representative of contemporary training practices. We agree that explicit discussion of scope would strengthen the presentation. We will add a short paragraph in the discussion section noting the tested regimes and stating that the mismatch is demonstrated for models trained under standard next-token prediction objectives, while leaving open the possibility of future checks on alternative pre-training regimes. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper's central claim of a fundamental mismatch between tensor decomposition assumptions and LLM representations is presented as the outcome of systematic empirical evaluation across dense and MoE models plus accompanying theoretical analysis. No equations, fitted parameters, self-citations, or ansatzes are quoted in the provided text that reduce the conclusion to a definition or input by construction. The derivation chain is self-contained and externally falsifiable via the reported performance trade-offs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tensortrainlow-rank approximation(TT-LoRA):DemocratizingAIwithacceleratedLLMs
AfiaAnjum,MaksimE.Eren,IsmaelBoureima,BoianAlexandrov,andManishBhattarai. Tensortrainlow-rank approximation(TT-LoRA):DemocratizingAIwithacceleratedLLMs. arXivpreprintarXiv:2408.01008, 2024. URLhttps://arxiv.org/abs/2408.01008
arXiv 2024
-
[2]
Slicegpt: Compress large language models by deleting rows and columns.arXiv preprint, 2024
Saleh Ashkboos, Maximilian L Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman. Slicegpt: Compress large language models by deleting rows and columns.arXiv preprint, 2024. URL https://arxiv.org/abs/2401.15024
arXiv 2024
-
[3]
Quip: 2-bit quantization of large language models with guarantees.Advances in neural information processing systems, 36:4396–4429, 2023
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher M De Sa. Quip: 2-bit quantization of large language models with guarantees.Advances in neural information processing systems, 36:4396–4429, 2023
2023
-
[4]
Mobe: Mixture-of-basis-experts for compressing moe-based llms.arXiv preprint arXiv:2508.05257, 2025
Xiaodong Chen, Mingming Ha, Zhenzhong Lan, Jing Zhang, and Jianguo Li. Mobe: Mixture-of-basis-experts for compressing moe-based llms.arXiv preprint arXiv:2508.05257, 2025
arXiv 2025
-
[5]
A multilinear singular value decomposition.SIAM journal on Matrix Analysis and Applications, 21(4):1253–1278, 2000
Lieven De Lathauwer, Bart De Moor, and Joos Vandewalle. A multilinear singular value decomposition.SIAM journal on Matrix Analysis and Applications, 21(4):1253–1278, 2000
2000
-
[6]
The approximation of one matrix by another of lower rank.Psychometrika, 1(3): 211–218, 1936
Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank.Psychometrika, 1(3): 211–218, 1936
1936
-
[7]
Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, and Dan Alistarh. Extreme compression of large language models via additive quantization.arXiv preprint arXiv:2401.06118, 2024
arXiv 2024
-
[8]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[9]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022. 10
2022
-
[10]
Optimalbraincompression: Aframeworkforaccuratepost-trainingquantization and pruning.Advances in Neural Information Processing Systems, 35:4475–4488, 2022
EliasFrantarandDanAlistarh. Optimalbraincompression: Aframeworkforaccuratepost-trainingquantization and pruning.Advances in Neural Information Processing Systems, 35:4475–4488, 2022
2022
-
[11]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
Pith/arXiv arXiv 2022
-
[12]
Nuclear norm of higher-order tensors.Mathematics of Computation, 87 (311):1255–1281, 2018
Shmuel Friedland and Lek-Heng Lim. Nuclear norm of higher-order tensors.Mathematics of Computation, 87 (311):1255–1281, 2018
2018
-
[13]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
2021
-
[14]
A survey of quantization methods for efficient neural network inference
Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W Mahoney, and Kurt Keutzer. A survey of quantization methods for efficient neural network inference. InLow-power computer vision, pages 291–326. Chapman and Hall/CRC, 2022
2022
-
[15]
The unreasonable ineffectiveness of the deeper layers
Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Dan Roberts. The unreasonable ineffectiveness of the deeper layers. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[16]
Tensorllm: Tensorising multi-head attention for enhanced reasoning and compression in llms
Yuxuan Gu, Wuyang Zhou, Giorgos Iacovides, and Danilo Mandic. Tensorllm: Tensorising multi-head attention for enhanced reasoning and compression in llms. InInternational Joint Conference on Neural Networks (IJCNN), 2025. URLhttps://arxiv.org/abs/2501.15674
arXiv 2025
-
[17]
Low-rank kronecker-product approximation to multi- dimensional nonlocal operators
Wolfgang Hackbusch and Boris N Khoromskij. Low-rank kronecker-product approximation to multi- dimensional nonlocal operators. part ii. hkt representation of certain operators.Computing, 76(3):203–225, 2006
2006
-
[18]
Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[19]
Xinhao Huang, You-Liang Huang, and Zeyi Wen. SoLA: Leveraging soft activation sparsity and low-rank decomposition for large language model compression. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17494–17502, 2025. doi: 10.1609/aaai.v39i16.33923
-
[20]
Kolda and Brett W
Tamara G. Kolda and Brett W. Bader. Tensor Decompositions and Applications.SIAM Review, 51(3):455–500, 2009
2009
-
[21]
LeSTD: Learning sparse Tucker decomposition for efficient large language models
Yi Li, Zhichun Guo, and Bingzhe Li Miao Yin. LeSTD: Learning sparse Tucker decomposition for efficient large language models. arXiv preprint arXiv:2601.01123, 2026
Pith/arXiv arXiv 2026
-
[22]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
2024
-
[23]
Yiran Luo, Het Patel, Yu Fu, Dawon Ahn, Jia Chen, Yue Dong, and Evangelos E. Papalexakis. TRAWL: Tensor reduced and approximated weights for large language models. arXiv preprint arXiv:2406.17261, 2024
arXiv 2024
-
[24]
Llm-pruner: On the structural pruning of large language models.Advances in neural information processing systems, 36:21702–21720, 2023
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models.Advances in neural information processing systems, 36:21702–21720, 2023
2023
-
[25]
Mehdi Makni, Kayhan Behdin, Zheng Xu, Natalia Ponomareva, and Rahul Mazumder. Hassle-free: A unified framework for sparse plus low-rank matrix decomposition for llms.arXiv preprint arXiv:2502.00899, 2025. URLhttps://arxiv.org/abs/2502.00899. 11
arXiv 2025
-
[26]
Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165): 1–73, 2021
Charles H Martin and Michael W Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165): 1–73, 2021
2021
-
[27]
Symmetric gauge functions and unitarily invariant norms.The quarterly journal of mathematics, 11(1):50–59, 1960
Leon Mirsky. Symmetric gauge functions and unitarily invariant norms.The quarterly journal of mathematics, 11(1):50–59, 1960
1960
-
[28]
Hierarchical mixture-of-experts with two-stage optimization
Gleb Molodtsov, Alexander Miasnikov, and Aleksandr Beznosikov. Hierarchical mixture-of-experts with two-stage optimization. InICML 2026 Workshop on Weight-Space Symmetries: from Foundations to Practical Applications, 2026
2026
-
[29]
Introducing gpt-oss
OpenAI. Introducing gpt-oss. https://openai.com/index/introducing-gpt-oss/ , 2025. Accessed: 2026-05-08
2025
-
[30]
Oseledets
Ivan V. Oseledets. Tensor-train decomposition.SIAM Journal on Scientific Computing, 33(5):2295–2317, 2011
2011
-
[31]
Coala: Numerically stable and efficient framework for context-aware low-rank approximation.Advances in Neural Information Processing Systems, 38:71014–71041, 2026
Uliana Parkina and Maxim Rakhuba. Coala: Numerically stable and efficient framework for context-aware low-rank approximation.Advances in Neural Information Processing Systems, 38:71014–71041, 2026
2026
-
[32]
The truth is in there: Improving reasoning in languagemodelswithlayer-selectiverankreduction
Pratyusha Sharma, Jordan Ash, and Dipendra Kumar Misra. The truth is in there: Improving reasoning in languagemodelswithlayer-selectiverankreduction. InInternationalConferenceonLearningRepresentations, volume 2024, pages 17632–17651, 2024
2024
-
[33]
Zunhai Su, Qingyuan Li, Hao Zhang, YuLei Qian, Yuchen Xie, and Kehong Yuan. Unveiling super experts in Mixture-of-Experts large language models.arXiv preprint arXiv:2507.23279, 2025. URL https://arxiv.org/abs/2507.23279
arXiv 2025
-
[34]
Mingjie Sun, Xinlei Chen, J. Zico Kolter, and Zhuang Liu. Massive activations in large language models. arXiv preprint arXiv:2402.17762, 2024
Pith/arXiv arXiv 2024
-
[35]
Shangwen Sun, Alfredo Canziani, Yann LeCun, and Jiachen Zhu. The spike, the sparse and the sink: Anatomy of massive activations and attention sinks.arXiv preprint arXiv:2603.05498, 2026
arXiv 2026
-
[36]
Gkd: A general knowledge distillation framework for large-scale pre-trained language model
Shicheng Tan, Weng Lam Tam, Yuanchun Wang, Wenwen Gong, Shu Zhao, Peng Zhang, and Jie Tang. Gkd: A general knowledge distillation framework for large-scale pre-trained language model. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track), pages 134–148, 2023
2023
-
[37]
Yehui Tang, Xiaosong Li, Fangcheng Liu, Wei Guo, Hang Zhou, Yaoyuan Wang, Kai Han, Xianzhi Yu, Jinpeng Li, Hui Zang, et al. Pangu pro moe: Mixture of grouped experts for efficient sparsity.arXiv preprint arXiv:2505.21411, 2025
arXiv 2025
-
[38]
FLAT-LLM: Fine-grained low-rank activation space transformation for large language model compression
Jiayi Tian et al. FLAT-LLM: Fine-grained low-rank activation space transformation for large language model compression. InFindings of the Association for Computational Linguistics: EACL 2026, 2026
2026
-
[39]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Hugo Touvron, Louis Martin, Pierre Stone, Benjamin Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[40]
Ledyard R. Tucker. Some mathematical notes on three-mode factor analysis.Psychometrika, 31(3):279–311, 1966
1966
-
[41]
Tensor approximations of matrices generated by asymptotically smooth functions.Sbornik: Mathematics, 194(6):941–954, 2003
Eugene Evgen’evich Tyrtyshnikov. Tensor approximations of matrices generated by asymptotically smooth functions.Sbornik: Mathematics, 194(6):941–954, 2003. 12
2003
-
[42]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[43]
GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model
Ben Wang and Aran Komatsuzaki. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax, May 2021
2021
-
[44]
Qinsi Wang, Jinghan Ke, Masayoshi Tomizuka, Yiran Chen, Kurt Keutzer, and Chenfeng Xu. Dobi-svd: Differentiable svd for llm compression and some new perspectives.arXiv preprint arXiv:2502.02723, 2025. URLhttps://arxiv.org/abs/2502.02723
arXiv 2025
-
[45]
Svd-llm: Truncation- aware singular value decomposition for large language model compression
XinyiWang,ZhihangYuan,YuangWang,QiangYuan,GuangyuSun,andWeiyangZhou. Svd-llm: Truncation- aware singular value decomposition for large language model compression. InInternational Conference on Learning Representations (ICLR), 2025. URLhttps://arxiv.org/abs/2403.07378
arXiv 2025
-
[46]
Td-moe: Tensor decomposition for moe models
Yuebin Xu, Yanhong Wang, Xuemei Peng, Hui Zang, Minghao Chen, Pengfei Xia, and Zeyi Wen. Td-moe: Tensor decomposition for moe models. InInternational Conference on Learning Representations (ICLR),
-
[47]
ICLR 2026
URLhttps://openreview.net/forum?id=D9cnZNZfxX. ICLR 2026
2026
-
[48]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
AnYang,AnfengLi,BaosongYang,BeichenZhang,BinyuanHui,BoZheng,BowenYu,ChangGao,Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[49]
Yifan Yang, Kai Zhen, Ershad Banijamal, Athanasios Mouchtaris, and Zheng Zhang. AdaZeta: Adaptive zeroth-order tensor-train adaption for memory-efficient large language models fine-tuning. arXiv preprint arXiv:2406.18060, 2024. URLhttps://arxiv.org/abs/2406.18060. Accepted to EMNLP 2024
arXiv 2024
-
[50]
YifanYang,JiajunZhou,NgaiWong,andZhengZhang. LoRETTA:Low-rankeconomictensor-trainadaptation for ultra-low-parameter fine-tuning of large language models. arXiv preprint arXiv:2402.11417, 2024. URL https://arxiv.org/abs/2402.11417
arXiv 2024
-
[51]
The super weight in large language models
Mengxia Yu, De Wang, Qi Shan, Colorado J Reed, and Alvin Wan. The super weight in large language models. arXiv preprint arXiv:2411.07191, 2024
arXiv 2024
-
[52]
Harp: Hadamard-preconditioned adaptive rotation processor for extreme llm quantization
Artur Zagitov, Gleb Molodtsov, and Aleksandr Beznosikov. Harp: Hadamard-preconditioned adaptive rotation processor for extreme llm quantization. 2026. URLhttps://arxiv.org/abs/2605.29843. 13 Appendix Rethinking the Role of Tensor Decompositions in Post-Training LLM Compression Contents 1 Introduction 1 2 Related Work 2 3 Compression Strategies 3 3.1 Pruni...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.