D2MDT: Department-aware Multidisciplinary Team Consultation with Deliberation for Efficient Clinical Prediction
Pith reviewed 2026-06-28 07:51 UTC · model grok-4.3
The pith
D2MDT assigns patient-specific department perspectives to doctor agents and applies residual deliberation to improve both predictive performance and consultation efficiency in EHR-based mortality prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
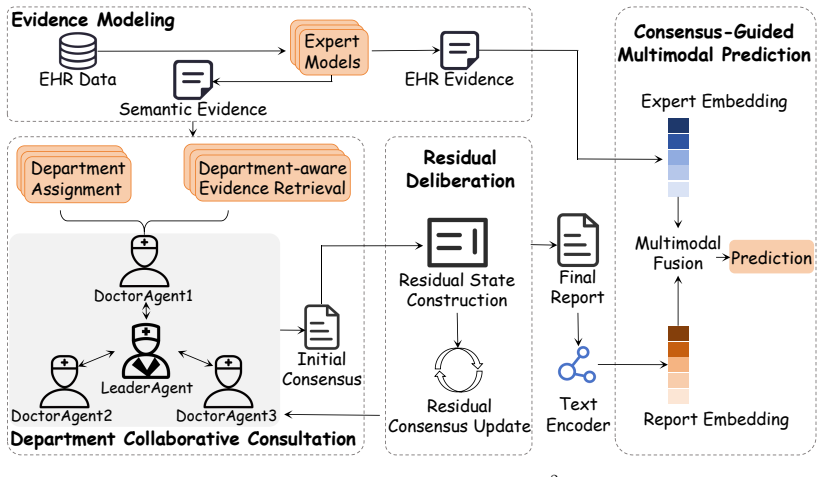
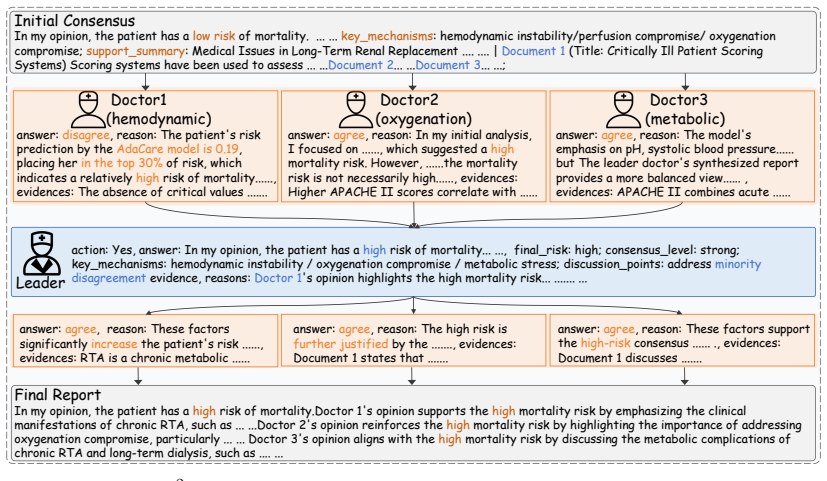
D2MDT constructs structured EHR evidence and consultation-ready semantic evidence. It assigns patient-specific department perspectives to doctor agents and retrieves complementary evidence for collaborative consultation. Residual deliberation updates only unresolved consensus instead of replaying full history. The refined consensus is fused with structured EHR representations for the final prediction.
What carries the argument
Residual deliberation mechanism that updates only unresolved consensus, enabled by department-aware assignment of perspectives to doctor agents.
If this is right
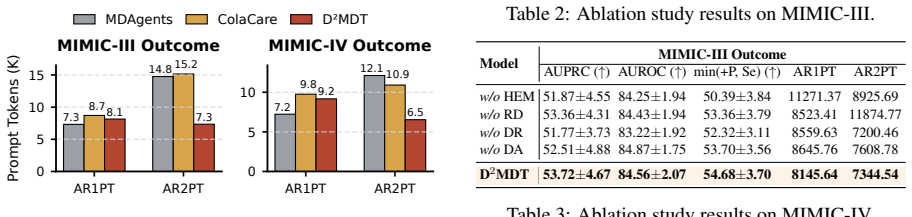
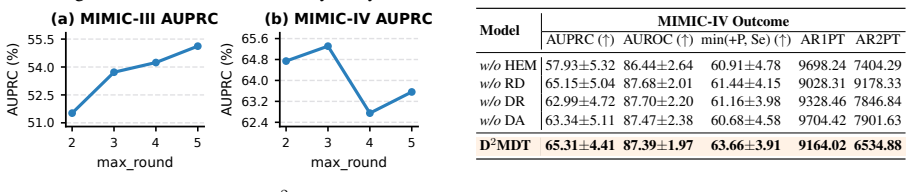
- D2MDT achieves improved predictive performance on mortality prediction tasks.
- D2MDT enhances consultation efficiency by reducing redundant interactions.
- The method provides better evidence differentiation across agents.
- The code release supports further testing of the approach.
Where Pith is reading between the lines
- The framework could extend to other clinical tasks like readmission prediction or diagnosis support.
- Residual deliberation may lower token usage in broader multi-agent applications for medical data.
- Testing in diverse hospital settings could validate the efficiency claims beyond the reported experiments.
Load-bearing premise
That assigning patient-specific department perspectives to doctor agents and using residual deliberation leads to better evidence differentiation and reduced redundancy compared to existing MAS methods for EHR.
What would settle it
A study that applies D2MDT and baseline methods to the same mortality prediction datasets and finds no gains in performance or efficiency metrics.
Figures





read the original abstract
Electronic health records (EHRs) are central to clinical prediction, but existing methods either rely on correlation-driven deep models or use single large language models (LLMs), making it difficult to support multidisciplinary clinical reasoning. Recent multi-agent systems (MAS) provide a promising alternative, yet current EHR-grounded MAS methods still suffer from weak evidence differentiation across agents and redundant multi-round interaction. We propose D2MDT, a Department-aware MultiDisciplinary Team Consultation with Deliberation for Efficient clinical prediction. D2MDT first constructs structured EHR evidence and consultation-ready semantic evidence for multi-agent consultation. It then assigns patient-specific department perspectives to doctor agents and retrieves complementary evidence for collaborative consultation. To improve efficiency, D2MDT further introduces residual deliberation, which updates only unresolved consensus rather than replaying the full discussion history. Finally, D2MDT fuses the refined consensus report with structured EHR representations for prediction. Experiments on mortality prediction show that D2MDT improves both predictive performance and consultation efficiency. We release the code online to ease the reproducibility of this paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes D2MDT, a department-aware multi-agent system for clinical prediction from EHRs. It constructs structured EHR evidence and consultation-ready semantic evidence, assigns patient-specific department perspectives to doctor agents, retrieves complementary evidence for collaborative consultation, introduces residual deliberation to update only unresolved consensus (avoiding full history replay), and fuses the refined consensus report with structured EHR representations for the final prediction. The central empirical claim is that experiments on mortality prediction demonstrate improvements in both predictive performance and consultation efficiency over existing methods; code is released for reproducibility.
Significance. If the empirical gains hold under rigorous evaluation, the work could advance MAS applications in healthcare by addressing weak evidence differentiation across agents and redundant multi-round interactions. The residual deliberation mechanism is a practical efficiency contribution, and the open release of code supports reproducibility and extension.
major comments (1)
- [Experiments] §Experiments (or equivalent results section): the central claim of improved predictive performance and consultation efficiency on mortality prediction is presented without any reported details on datasets, baselines, metrics, number of runs, error bars, statistical tests, or data handling. This information is load-bearing for assessing whether the results support the claims.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the need for complete experimental reporting. We agree that the details listed are essential to substantiate the central claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] §Experiments (or equivalent results section): the central claim of improved predictive performance and consultation efficiency on mortality prediction is presented without any reported details on datasets, baselines, metrics, number of runs, error bars, statistical tests, or data handling. This information is load-bearing for assessing whether the results support the claims.
Authors: We acknowledge that the current manuscript version does not provide sufficient detail on the experimental setup. In the revised version we will expand the Experiments section (and any supplementary material) to explicitly report: the specific EHR datasets employed (including size, time span, and access details), the full list of baselines with implementation references, the complete set of evaluation metrics, the number of independent runs, standard deviations or error bars, the statistical tests used for significance, and all data-handling steps (preprocessing, imputation, train/validation/test splits, and any filtering criteria). Code release already exists; we will also add a reproducibility checklist linking the reported numbers to the released repository. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical MAS architecture for EHR-based mortality prediction. It describes a sequence of engineering steps (EHR structuring, department-aware agent assignment, residual deliberation, consensus fusion) followed by experimental validation on predictive performance and efficiency. No equations, parameter-fitting steps, uniqueness theorems, or self-citations appear in the provided text. The central claims rest on reported experimental outcomes rather than any derivation that reduces to its own inputs by construction. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Erin P. Balogh. 2015. Improving diagnosis in health care
2015
-
[2]
Shah Bds
Savyasachi V. Shah Bds. 2024. Accuracy, consistency, and hallucination of large language models when analyzing unstructured clinical notes in electronic medical records. JAMA Network Open, 7(8):2
2024
-
[3]
Ofir Ben Shoham and Nadav Rappoport. 2024. Cpllm: Clinical prediction with large language models. PLOS Digital Health, 3(12):e0000680
2024
-
[4]
Graber, J
Alexandra Campione Russo, Jean‐Luc Tilly, Leah Kaufman, Melissa Danforth, Mark L. Graber, J. Matthew Austin, and Hardeep Singh. 2025. Hospital commitments to address diagnostic errors: An assessment of 95 us hospitals. Journal of Hospital Medicine, 20(2)
2025
-
[5]
Layden, Mudassir Rashid, Lu Cheng, Ali Cinar, and Barbara Di Eugenio
Rochana Chaturvedi, Yue Zhou, Andrew Boyd, Brian T. Layden, Mudassir Rashid, Lu Cheng, Ali Cinar, and Barbara Di Eugenio. 2025. Early risk prediction with temporally and contextually grounded clinical language processing
2025
-
[6]
Kai Chen, Xinfeng Li, Tianpei Yang, Hewei Wang, Wei Dong, and Yang Gao. 2025 a . Mdteamgpt: A self-evolving llm-based multi-agent framework for multi-disciplinary team medical consultation
2025
-
[7]
Xi Chen, Huahui Yi, Mingke You, WeiZhi Liu, Li Wang, Hairui Li, Xue Zhang, Yingman Guo, Lei Fan, Gang Chen, et al. 2025 b . Enhancing diagnostic capability with multi-agents conversational large language models. NPJ digital medicine, 8(1):159
2025
-
[8]
Stewart, and Jimeng Sun
Edward Choi, Mohammad Taha Bahadori, Andy Schuetz, Walter F. Stewart, and Jimeng Sun. 2016 a . Retain: Interpretable predictive model in healthcare using reverse time attention mechanism. Curran Associates Inc
2016
-
[9]
Edward Choi, Mohammad Taha Bahadori, Jimeng Sun, Joshua Kulas, Andy Schuetz, and Walter Stewart. 2016 b . Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. Advances in neural information processing systems, 29
2016
-
[10]
Xinsong Du, Zhengyang Zhou, Yifei Wang, Ya-Wen Chuang, Yiming Li, Richard Yang, Wenyu Zhang, Xinyi Wang, Xinyu Chen, Hao Guan, et al. 2026. Testing and evaluation of generative large language models in electronic health record applications: a systematic review. Journal of the American Medical Informatics Association, page ocaf233
2026
-
[11]
Mark L Graber, Diana Rusz, Melissa L Jones, Diana Farm-Franks, Barbara Jones, Jeannine Cyr Gluck, Dana B Thomas, Kelly T Gleason, Kathy Welte, Jennifer Abfalter, et al. 2017. The new diagnostic team. Diagnosis, 4(4):225--238
2017
-
[12]
Paul Hager, Friederike Jungmann, Robbie Holland, Kunal Bhagat, Inga Hubrecht, Manuel Knauer, Jakob Vielhauer, Marcus Makowski, Rickmer Braren, and Georgios Kaissis. 2024. Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature Medicine, 30(9):26
2024
-
[13]
Hrayr Harutyunyan, Hrant Khachatrian, David C Kale, Greg Ver Steeg, and Aram Galstyan. 2019. Multitask learning and benchmarking with clinical time series data. Scientific data, 6(1):96
2019
-
[15]
Black, Danny Park, James Zou, Andrew Y
Yixing Jiang, Kameron C. Black, Danny Park, James Zou, Andrew Y. Ng, and Jonathan H. Chen. 2025. Medagentbench: A realistic virtual ehr environment to benchmark medical llm agents
2025
-
[16]
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. 2023. Mimic-iv, a freely accessible electronic health record dataset. Scientific data, 10(1):1
2023
-
[17]
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. 2016. Mimic-iii, a freely accessible critical care database. Scientific data, 3(1):1--9
2016
-
[18]
Misuk Kim and Kyu-Baek Hwang. 2022. An empirical evaluation of sampling methods for the classification of imbalanced data. PloS one, 17(7):e0271260
2022
-
[19]
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik Siu Chan, Xuhai Xu, Daniel Mcduff, Hyeonhoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae Won Park. 2024. Mdagents: An adaptive collaboration of llms for medical decision-making
2024
-
[20]
Ching Yi Lee, Hung Yi Lai, Ching Hsin Lee, Mi Mi Chen, and Sze Yuen Yau. 2024. Collaborative clinical reasoning: a scoping review. PeerJ
2024
-
[21]
Weibin Liao, Yinghao Zhu, Zhongji Zhang, Yuhang Wang, Zixiang Wang, Xu Chu, Yasha Wang, and Liantao Ma. 2024. Learnable prompt as pseudo-imputation: Rethinking the necessity of traditional ehr data imputation in downstream clinical prediction
2024
-
[22]
Qicai Liu, Zhichao Hu, Tao Huang, Yupeng Niu, Xinche Zhang, Shanwu Ma, Chutong Lin, Goh Kim Huat, Hyeokkoo Eric Kwon, and Feng Gao. 2026. Evomdt: a self-evolving multi-agent system for structured clinical decision-making in multi-cancer. npj Digital Medicine, 9(1)
2026
-
[23]
Liantao Ma, Junyi Gao, Yasha Wang, Chaohe Zhang, and Xinyu Ma. 2020. Adacare: Explainable clinical health status representation learning via scale-adaptive feature extraction and recalibration. Proceedings of the AAAI Conference on Artificial Intelligence, 34(1):825--832
2020
-
[24]
Xinyu Ma, Yasha Wang, Xu Chu, Liantao Ma, Wen Tang, Junfeng Zhao, Ye Yuan, and Guoren Wang. 2022. Patient health representation learning via correlational sparse prior of medical features. IEEE Transactions on Knowledge and Data Engineering, 35(11):11769--11783
2022
-
[25]
Matthew B McDermott, Haoran Zhang, Lasse H Hansen, Giovanni Angelotti, and Jack Gallifant. 2024. A closer look at auroc and auprc under class imbalance. Advances in Neural Information Processing Systems, 37:44102--44163
2024
-
[26]
Harsha Nori, Mayank Daswani, Christopher Kelly, Scott Lundberg, Marco Tulio Ribeiro, Marc Wilson, Xiaoxuan Liu, Viknesh Sounderajah, Jonathan Carlson, and Matthew P Lungren. 2025. Sequential diagnosis with language models
2025
-
[27]
Robert S Porter and Justin L Kaplan. 2011. The Merck manual of diagnosis and therapy. Merck Sharp & Dohme Corp
2011
-
[28]
Weijieying Ren, Jingxi Zhu, Zehao Liu, Tianxiang Zhao, and Vasant Honavar. 2025. A comprehensive survey of electronic health record modeling: From deep learning approaches to large language models
2025
-
[30]
Wenqi Shi, Ran Xu, Yuchen Zhuang, Yue Yu, Jieyu Zhang, Hang Wu, Yuanda Zhu, Joyce Ho, Carl Yang, and May D. Wang. 2024. Ehragent: Code empowers large language models for few-shot complex tabular reasoning on electronic health records
2024
-
[31]
Mukund Sundararajan and Amir Najmi. 2020. The many shapley values for model explanation. In International conference on machine learning, pages 9269--9278. PMLR
2020
-
[32]
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, and Mark Gerstein. 2024. Medagents: Large language models as collaborators for zero-shot medical reasoning. Findings of the Association for Computational Linguistics ACL 2024, pages 599--621
2024
-
[33]
Janneke E. W. Walraven, Olga L. Van, der Hel, J. J. M. Van, der Hoeven, Valery E. P. P. Lemmens, Rob H. A. Verhoeven, and Ingrid M. E. Desar. 2022. Factors influencing the quality and functioning of oncological multidisciplinary team meetings: results of a systematic review. BMC Health Services Research, 22(1):1--27
2022
-
[34]
Haochun Wang, Sendong Zhao, Zewen Qiang, Nuwa Xi, Bing Qin, and Ting Liu. 2024. Beyond direct diagnosis: Llm-based multi-specialist agent consultation for automatic diagnosis
2024
-
[36]
Ran Xu, Wenqi Shi, Yue Yu, Yuchen Zhuang, Bowen Jin, May Dongmei Wang, Joyce Ho, and Carl Yang. 2024. Ram-ehr: Retrieval augmentation meets clinical predictions on electronic health records. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 754--765
2024
-
[37]
Sihang Zeng, Lucas Jing Liu, Jun Wen, Meliha Yetisgen, Ruth Etzioni, and Gang Luo. 2025. Trajsurv: Learning continuous latent trajectories from electronic health records for trustworthy survival prediction
2025
-
[38]
Rongjia Zhou, Chengzhuo Li, Carl Yang, and Jiaying Lu. 2025 a . Clinnoteagents: An llm multi-agent system for predicting and interpreting heart failure 30-day readmission from clinical notes
2025
-
[39]
Yucheng Zhou, Lingran Song, and Jianbing Shen. 2025 b . Mam: Modular multi-agent framework for multi-modal medical diagnosis via role-specialized collaboration. In Findings of the Association for Computational Linguistics: ACL 2025, pages 25319--25333
2025
-
[40]
Yinghao Zhu, Ziyi He, Haoran Hu, Xiaochen Zheng, Xichen Zhang, Zixiang Wang, Junyi Gao, Liantao Ma, and Lequan Yu. 2025. Medagentboard: Benchmarking multi-agent collaboration with conventional methods for diverse medical tasks
2025
-
[41]
Yinghao Zhu, Changyu Ren, Zixiang Wang, Xiaochen Zheng, Shiyun Xie, Junlan Feng, Xi Zhu, Zhoujun Li, Liantao Ma, and Chengwei Pan. 2024. Emerge: Enhancing multimodal electronic health records predictive modeling with retrieval-augmented generation. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 3549--3559
2024
-
[42]
Curran Associates Inc
RETAIN: Interpretable Predictive Model in Healthcare using Reverse Time Attention Mechanism , author=. Curran Associates Inc. , year=
-
[43]
Scientific Reports , volume=
BEHRT: Transformer for Electronic Health Records , author=. Scientific Reports , volume=
-
[44]
A Comprehensive Survey of Electronic Health Record Modeling: From Deep Learning Approaches to Large Language Models , author=
-
[45]
Journal of the American Medical Informatics Association , pages=
Testing and evaluation of generative large language models in electronic health record applications: a systematic review , author=. Journal of the American Medical Informatics Association , pages=. 2026 , publisher=
2026
-
[46]
Improving Diagnosis in Health Care , author=
-
[47]
Diagnosis , volume=
The new diagnostic team , author=. Diagnosis , volume=. 2017 , publisher=
2017
-
[48]
Journal of Hospital Medicine , volume=
Hospital commitments to address diagnostic errors: An assessment of 95 US hospitals , author=. Journal of Hospital Medicine , volume=
-
[49]
Systematic Reviews , volume=
Interprofessional diagnostic management teams: a scoping review protocol , author=. Systematic Reviews , volume=
-
[50]
BMC Health Services Research , volume=
Factors influencing the quality and functioning of oncological multidisciplinary team meetings: results of a systematic review , author=. BMC Health Services Research , volume=
-
[51]
Cancer Treatment Reviews , volume=
The impact of multidisciplinary team meetings on patient assessment, management and outcomes in oncology settings: A systematic review of the literature , author=. Cancer Treatment Reviews , volume=
-
[52]
Frontiers in Health Services , year=
Implementation of streamlining measures in selecting and prioritising complex cases for the cancer multidisciplinary team meeting: a mini review of the recent developments , author=. Frontiers in Health Services , year=
-
[53]
Frontiers in Public Health , year=
Accelerating rare disease detection: an experience of multidisciplinary team model in undiagnosed diseases program in a children's hospital , author=. Frontiers in Public Health , year=
-
[54]
Nature Machine Intelligence , volume=
LLM-based agentic systems in medicine and healthcare , author=. Nature Machine Intelligence , volume=
-
[55]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[56]
MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making , author=
-
[57]
Beyond Direct Diagnosis: LLM-based Multi-Specialist Agent Consultation for Automatic Diagnosis , author=
-
[58]
Sequential Diagnosis with Language Models , author=
-
[59]
npj Digital Medicine , volume=
EvoMDT: a self-evolving multi-agent system for structured clinical decision-making in multi-cancer , author=. npj Digital Medicine , volume=
-
[60]
MDTeamGPT: A Self-Evolving LLM-based Multi-Agent Framework for Multi-Disciplinary Team Medical Consultation , author=
-
[61]
MedAgentBoard: Benchmarking Multi-Agent Collaboration with Conventional Methods for Diverse Medical Tasks , author=
-
[62]
EHRAgent: Code Empowers Large Language Models for Few-shot Complex Tabular Reasoning on Electronic Health Records , author=
-
[63]
KDD'24 Workshop: Artificial Intelligence and Data Science for Healthcare: Bridging Data-Centric AI and People-Centric Healthcare , year=
EHRFlow: A Large Language Model-Driven Iterative Multi-Agent Electronic Health Record Data Analysis Workflow , author=. KDD'24 Workshop: Artificial Intelligence and Data Science for Healthcare: Bridging Data-Centric AI and People-Centric Healthcare , year=
-
[64]
MedAgentBench: A Realistic Virtual EHR Environment to Benchmark Medical LLM Agents , author=
-
[65]
arXiv preprint arXiv:2509.19319 , year=
FHIR-AgentBench: Benchmarking LLM Agents for Realistic Interoperable EHR Question Answering , author=. arXiv preprint arXiv:2509.19319 , year=
-
[66]
Proceedings of the ACM Web Conference 2025 , pages=
ColaCare: Enhancing Electronic Health Record Modeling through Large Language Model-Driven Multi-Agent Collaboration , author=. Proceedings of the ACM Web Conference 2025 , pages=. 2025 , publisher=. doi:10.1145/3696410.3714877 , url=
-
[67]
MoMA: A Mixture-of-Multimodal-Agents Architecture for Enhancing Clinical Prediction Modelling , author=
-
[68]
npj Digital Medicine , volume=
CARE-AD: a multi-agent large language model framework for Alzheimer's disease prediction using longitudinal clinical notes , author=. npj Digital Medicine , volume=. 2025 , doi=
2025
-
[69]
ClinNoteAgents: An LLM Multi-Agent System for Predicting and Interpreting Heart Failure 30-Day Readmission from Clinical Notes , author=
-
[70]
Cancers , volume=
The effects of multidisciplinary team meetings on clinical practice for colorectal, lung, prostate and breast cancer: a systematic review , author=. Cancers , volume=. 2021 , publisher=
2021
-
[71]
Frontiers in Health Services , volume=
Implementation of streamlining measures in selecting and prioritising complex cases for the cancer multidisciplinary team meeting: a mini review of the recent developments , author=. Frontiers in Health Services , volume=. 2024 , publisher=
2024
-
[72]
BJS open , volume=
Cancer multidisciplinary team meetings: impact of logistical challenges on communication and decision-making , author=. BJS open , volume=. 2022 , publisher=
2022
-
[73]
BMJ open , volume=
Mapping cognitive biases in multidisciplinary team (MDT) decision-making for cancer care in Scotland: a cognitive ethnography study protocol , author=. BMJ open , volume=. 2024 , publisher=
2024
-
[74]
TrajSurv: Learning Continuous Latent Trajectories from Electronic Health Records for Trustworthy Survival Prediction , author=
-
[75]
Early Risk Prediction with Temporally and Contextually Grounded Clinical Language Processing , author=
-
[76]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
AdaCare: Explainable Clinical Health Status Representation Learning via Scale-Adaptive Feature Extraction and Recalibration , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[77]
Learnable Prompt as Pseudo-Imputation: Rethinking the Necessity of Traditional EHR Data Imputation in Downstream Clinical Prediction , author=
-
[78]
PeerJ , year=
Collaborative clinical reasoning: a scoping review , author=. PeerJ , year=
-
[79]
Nature Medicine , volume=
Evaluation and mitigation of the limitations of large language models in clinical decision-making , author=. Nature Medicine , volume=
-
[80]
JAMA Network Open , volume=
Accuracy, Consistency, and Hallucination of Large Language Models When Analyzing Unstructured Clinical Notes in Electronic Medical Records , author=. JAMA Network Open , volume=
-
[81]
NPJ digital medicine , volume=
A multi-center study on the adaptability of a shared foundation model for electronic health records , author=. NPJ digital medicine , volume=. 2024 , publisher=
2024
-
[82]
npj Digital Medicine , volume=
Transformer patient embedding using electronic health records enables patient stratification and progression analysis , author=. npj Digital Medicine , volume=. 2025 , publisher=
2025
-
[83]
Journal of Biomedical Informatics , volume=
HEART: Learning better representation of EHR data with a heterogeneous relation-aware transformer , author=. Journal of Biomedical Informatics , volume=. 2024 , publisher=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.