AnchorMoE: Interpretable Time Series Classification via Anchor-Routed MoE
Pith reviewed 2026-06-28 11:39 UTC · model grok-4.3
The pith
AnchorMoE formulates time series predictions as exact additive sums of segment contributions for built-in transparency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
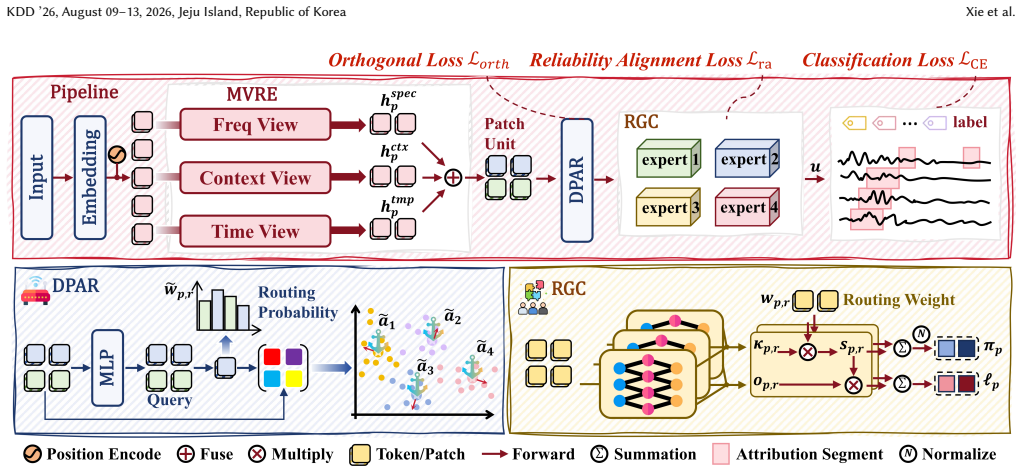
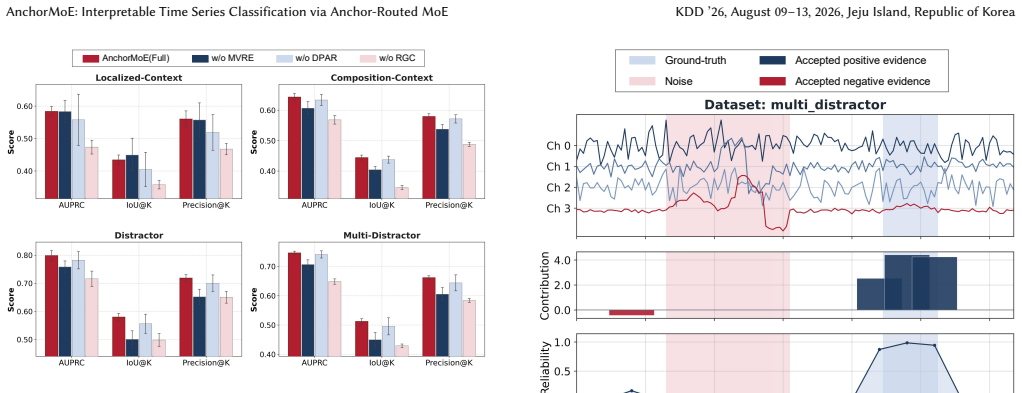
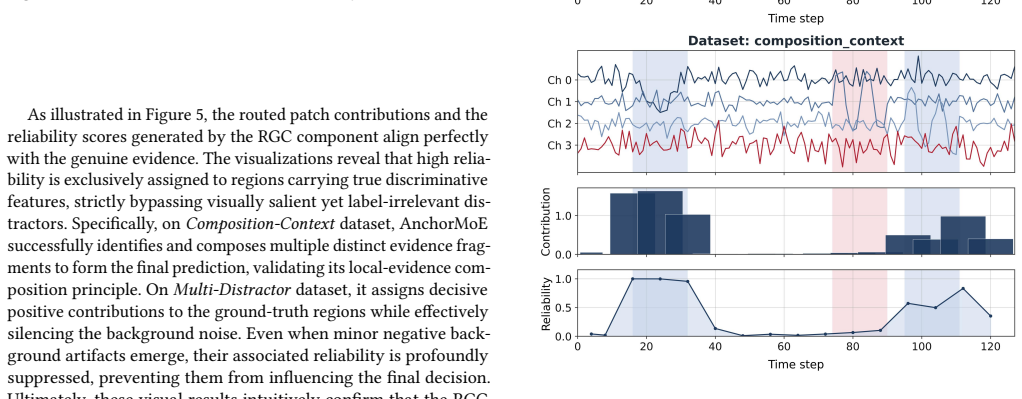
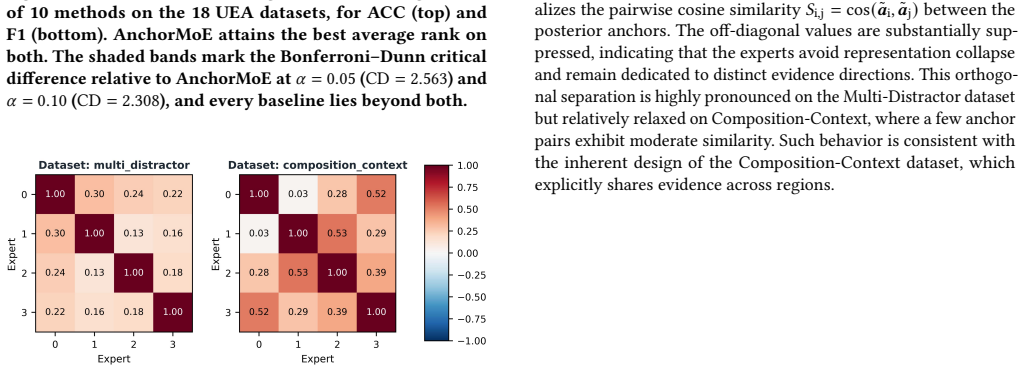
AnchorMoE encodes multi-view representations of local patches and routes them to specialized experts such that the classification output is exactly the sum of the individual expert contributions from each input segment; the orthogonality penalty and reliability gate keep this additive decomposition reliable when discriminative signals are sparse and obscured by background noise.
What carries the argument
Anchor-routed Mixture-of-Experts architecture that decomposes the output as an exact additive sum over routed segment contributions.
If this is right
- Each class score can be inspected by reading the signed contribution of every time segment without additional computation.
- The model directly identifies which input intervals drive the decision, allowing immediate comparison with domain knowledge.
- The same routing and decomposition apply across different time series lengths because the additive form does not depend on post-processing.
- Competing post-hoc explanation methods can be validated against the model's native segment contributions on the same inputs.
Where Pith is reading between the lines
- The additive decomposition could be applied to other sequence models that already use routing, such as certain transformer variants, to obtain similar transparency.
- If the orthogonality constraint generalizes, it might reduce expert collapse in MoE models trained on other sparse-signal domains.
- A natural next test would be to measure how well the segment contributions align with human annotations of discriminative intervals on clinical or industrial datasets.
Load-bearing premise
The geometric orthogonality constraint together with the uncertainty-aware reliability gate will keep the additive decomposition reliable when discriminative signals are sparse and heavily obscured by background noise.
What would settle it
On a noisy test set with known sparse signals, measure whether the sum of the per-segment contributions deviates from the model's actual output once either the orthogonality penalty or the reliability gate is removed.
Figures



read the original abstract
Multivariate time series classification (MTSC) is pivotal in high-stakes domains, such as clinical diagnosis and industrial fault detection, where safe deployment necessitates transparent decision-making. However, isolating the temporal segments that drive model predictions is challenging because discriminative signals in real-world time series are typically sparse, heterogeneous, and heavily obscured by background noise. This paper, therefore, proposes AnchorMoE, an interpretable-by-construction classification framework. Built upon a Mixture-of-Experts (MoE) architecture, AnchorMoE encodes multi-view representations of local patches and routes them to specialized experts, ensuring that the final prediction is formulated as an exact additive decomposition over the input segments, facilitating ante-hoc transparency rather than relying on post-hoc estimations. To maintain the reliability of this decomposition under sparse signal distributions, we introduce a geometric orthogonality constraint that penalizes representational redundancy, compelling distinct experts to specialize in heterogeneous predictive patterns. Furthermore, an uncertainty-aware reliability gate is designed to dynamically calibrate the contribution of each segment, effectively suppressing residual background noise. Extensive experiments on real-world and synthetic benchmarks demonstrate that AnchorMoE achieves highly competitive classification performance while faithfully grounding its decisions in the raw time series.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AnchorMoE, an MoE-based framework for multivariate time series classification that encodes local patches, routes them via anchor-based specialization, and claims the final prediction forms an exact additive decomposition over input segments for ante-hoc interpretability. It introduces a geometric orthogonality constraint on expert representations to encourage specialization on heterogeneous patterns and an uncertainty-aware reliability gate to suppress noise under sparse signals, with experiments showing competitive accuracy on real and synthetic benchmarks.
Significance. If the exact per-segment additivity can be rigorously established and preserved by the gating mechanism, the work would offer a rare ante-hoc interpretable model for high-stakes MTSC domains; however, the absence of any derivation, proof, or quantitative verification of the decomposition's exactness under the stated constraints substantially weakens the claimed advantage over post-hoc methods.
major comments (3)
- [Abstract, §3] Abstract and §3 (method): the central claim that the prediction is an 'exact additive decomposition' over segments is asserted without any derivation, equation, or proof showing that the routing function, expert outputs, and uncertainty gate together yield ŷ = Σ c_i with each c_i depending only on segment i. The orthogonality constraint is stated to act only on representations and does not address potential cross-segment dependencies introduced by the gate.
- [Abstract, §4.2] Abstract and §4.2 (uncertainty-aware gate): if the reliability gate computes uncertainty from a shared representation or the full series (as is common in global uncertainty estimators), the scaling factor for segment i becomes a function of all segments, violating the independence required for exact additivity. No explicit per-segment, context-independent uncertainty computation is described or proven to preserve the decomposition.
- [§5] §5 (experiments): no ablation or diagnostic is reported that directly tests whether the additive property holds (e.g., by measuring deviation from Σ c_i under controlled sparse-signal conditions or by verifying that gate outputs remain independent of other patches). Without such verification, the reliability claim under 'sparse and heavily obscured' signals remains untested.
minor comments (2)
- [§3] Notation for the decomposition (e.g., how c_i is formally defined from expert outputs and gate) should be introduced with an explicit equation early in §3.
- [§3.3] The geometric orthogonality loss is described only qualitatively; its precise formulation (e.g., cosine similarity penalty or Gram-matrix term) and weighting hyperparameter should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which help strengthen the rigor of our interpretability claims. We address each major point below and will incorporate revisions to provide the requested derivations, clarifications, and empirical verifications.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): the central claim that the prediction is an 'exact additive decomposition' over segments is asserted without any derivation, equation, or proof showing that the routing function, expert outputs, and uncertainty gate together yield ŷ = Σ c_i with each c_i depending only on segment i. The orthogonality constraint is stated to act only on representations and does not address potential cross-segment dependencies introduced by the gate.
Authors: We agree that an explicit derivation is required. The architecture processes each input segment (patch) independently: the anchor-based router assigns patches to experts without cross-patch interactions in the forward pass, each expert produces an output from its assigned patch only, and the uncertainty gate is applied per-patch on the local representation. Thus ŷ = Σ_i (g_i · e_i) where both g_i and e_i are functions exclusively of segment i. The geometric orthogonality acts on expert representations to encourage specialization but is orthogonal to the additivity property, which follows directly from the per-segment processing. In the revision we will add a formal derivation and the corresponding equations in §3. revision: yes
-
Referee: [Abstract, §4.2] Abstract and §4.2 (uncertainty-aware gate): if the reliability gate computes uncertainty from a shared representation or the full series (as is common in global uncertainty estimators), the scaling factor for segment i becomes a function of all segments, violating the independence required for exact additivity. No explicit per-segment, context-independent uncertainty computation is described or proven to preserve the decomposition.
Authors: The uncertainty gate in §4.2 is computed from the local representation of each individual patch after encoding, ensuring it is context-independent. We will revise the section to state this explicitly, include the per-segment formulation, and prove that the gate output for segment i does not depend on other patches, thereby preserving exact additivity. If the current wording is ambiguous, the revision will remove any potential for misinterpretation. revision: yes
-
Referee: [§5] §5 (experiments): no ablation or diagnostic is reported that directly tests whether the additive property holds (e.g., by measuring deviation from Σ c_i under controlled sparse-signal conditions or by verifying that gate outputs remain independent of other patches). Without such verification, the reliability claim under 'sparse and heavily obscured' signals remains untested.
Authors: We agree that direct empirical verification strengthens the claims. The revised §5 will include a new ablation that (i) measures the numerical deviation from Σ c_i on synthetic data with varying sparsity and noise levels, and (ii) checks gate-output independence by comparing per-patch gates against versions with masked or altered neighboring patches. These diagnostics will be reported alongside the existing accuracy results. revision: yes
Circularity Check
No circularity; additive decomposition follows from stated MoE routing architecture without reduction to fitted inputs or self-citations
full rationale
The abstract states that the MoE architecture 'ensures that the final prediction is formulated as an exact additive decomposition over the input segments' by construction of patch encoding and expert routing. The orthogonality constraint and uncertainty-aware gate are presented as separate mechanisms to maintain reliability, not as redefinitions of the decomposition itself. No equations, self-citations, or fitted parameters renamed as predictions appear in the provided text. The derivation is therefore self-contained against external benchmarks, with any concerns about gate-induced dependencies falling under correctness rather than circularity per the analysis rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Goodfellow, Moritz Hardt, and Been Kim
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian J. Goodfellow, Moritz Hardt, and Been Kim. 2018. Sanity Checks for Saliency Maps. InProceedings of the 32nd International Conference on Neural Information Processing Systems (NeurIPS). 9525–9536
2018
-
[2]
Anthony Bagnall, Hoang Anh Dau, Jason Lines, Michael Flynn, James Large, Aaron Bostrom, Paul Southam, and Eamonn Keogh. 2018. The UEA Multivariate Time Series Classification Archive, 2018. arXiv:1811.00075
Pith/arXiv arXiv 2018
-
[3]
Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan K. Su. 2019. This Looks Like That: Deep Learning for Interpretable Image Recognition. InProceedings of the 33rd International Conference on Neural Information Processing Systems (NeurIPS). 8928–8939
2019
-
[4]
Taochen Chen, Jialiang Chen, Yiqun Zhang, Mengke Li, Yang Lu, and Yiu-ming Cheung. 2026. FMoE: Frequency-Guided Multi-Period MoE Modeling for Time Series Forecasting. InProceedings of the 39th International Joint Conference on Neural Networks (IJCNN)
2026
-
[5]
Xiwen Chen, Peijie Qiu, Wenhui Zhu, Huayu Li, Hao Wang, Aristeidis Sotiras, Yalin Wang, and Abolfazl Razi. 2024. TimeMIL: Advancing Multivariate Time Series Classification via a Time-Aware Multiple Instance Learning. InProceedings of the 41st International Conference on Machine Learning (ICML). 7190–7206
2024
-
[6]
Zewen Chi, Li Dong, Shaohan Huang, Damai Dai, Shuming Ma, Barun Patra, Saksham Singhal, Payal Bajaj, Xia Song, Xian-Ling Mao, Heyan Huang, and Furu Wei. 2022. On the Representation Collapse of Sparse Mixture of Experts. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS). 34600–34613
2022
-
[7]
Jonathan Crabbé and Mihaela van der Schaar. 2021. Explaining Time Series Pre- dictions with Dynamic Masks. InProceedings of the 38th International Conference on Machine Learning (ICML). 2166–2177
2021
-
[8]
Schmidt, and Geoffrey I
Angus Dempster, Daniel F. Schmidt, and Geoffrey I. Webb. 2021. MiniRocket: A Very Fast (Almost) Deterministic Transform for Time Series Classification. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 248–257
2021
-
[9]
Janez Demšar. 2006. Statistical Comparisons of Classifiers over Multiple Data Sets.Journal of Machine Learning Research7, 1 (2006), 1–30
2006
-
[10]
Bhaskar Dhariyal, Thach Le Nguyen, and Georgiana Ifrim. 2021. Fast Channel Selection for Scalable Multivariate Time Series Classification. InProceedings of the 6th ECML PKDD Workshop on Advanced Analytics and Learning on Temporal Data (AALTD). 36–54
2021
-
[11]
Antonio Di Marino, Vincenzo Bevilacqua, Angelo Ciaramella, Ivanoe De Falco, and Giovanna Sannino. 2025. Ante-Hoc Methods for Interpretable Deep Models: A Survey.Comput. Surveys57, 10 (2025), 1–36
2025
-
[12]
Emadeldeen Eldele, Mohamed Ragab, Zhenghua Chen, Min Wu, and Xiaoli Li
-
[13]
InProceedings of the 41st International Conference on Machine Learning (ICML)
TSLANet: Rethinking Transformers for Time Series Representation Learn- ing. InProceedings of the 41st International Conference on Machine Learning (ICML). 12409–12428
-
[14]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research23, 120 (2022), 1–40
2022
-
[15]
Jinyuan Feng, Zhiqiang Pu, Tianyi Hu, Dongmin Li, Xiaolin Ai, and Huimu Wang
-
[16]
OMoE: Diversifying Mixture of Low-Rank Adaptation by Orthogonal Finetuning. arXiv:2501.10062
-
[17]
Alireza Ghods and Diane J. Cook. 2022. PIP: Pictorial Interpretable Prototype Learning for Time Series Classification.IEEE Computational Intelligence Magazine 17, 1 (2022), 34–45
2022
-
[18]
Josif Grabocka, Nicolas Schilling, Martin Wistuba, and Lars Schmidt-Thieme
-
[19]
InProceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD)
Learning Time-Series Shapelets. InProceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). 392– 401
-
[20]
Ahmed Hendawy, Jan Peters, and Carlo D’Eramo. 2024. Multi-Task Reinforce- ment Learning with Mixture of Orthogonal Experts. InProceedings of the 12th International Conference on Learning Representations (ICLR)
2024
-
[21]
Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, and Been Kim. 2019. A Benchmark for Interpretability Methods in Deep Neural Networks. InProceedings of the 33rd International Conference on Neural Information Processing Systems (NeurIPS). 9737–9748
2019
-
[22]
Tsung-Yu Hsieh, Suhang Wang, Yiwei Sun, and Vasant Honavar. 2021. Explainable Multivariate Time Series Classification: A Deep Neural Network Which Learns to Attend to Important Variables as Well as Time Intervals. InProceedings of the 14th ACM International Conference on Web Search and Data Mining (WSDM). 607–615
2021
-
[23]
Arik, Jinsung Yoon, Ankur Taly, Soheil Feizi, and Tomas Pfister
Aya Abdelsalam Ismail, Sercan Ö. Arik, Jinsung Yoon, Ankur Taly, Soheil Feizi, and Tomas Pfister. 2023. Interpretable Mixture of Experts.Transactions on Machine Learning Research(2023)
2023
-
[24]
Sarthak Jain and Byron C. Wallace. 2019. Attention Is Not Explanation. InPro- ceedings of the 17th North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT). 3543–3556
2019
-
[25]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2021. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. InProceedings of the 9th International Conference on Learning Representations (ICLR)
2021
-
[26]
Xinglin Lian, Chengtai Cao, Ting Zhong, Yong Wang, Kai Chen, and Fan Zhou
-
[27]
Decompose to Understand, Fuse to Detect: Frequency-Decoupled Anomaly Detection for Encrypted Network Traffic. arXiv:2605.02970
-
[28]
Xinglin Lian, Yu Zheng, Yan Liu, Fan Zhou, Chunlei Peng, and Xinbo Gao. 2026. Contextual Masking Distillation for Network Traffic Anomaly Detection.IEEE Transactions on Information Forensics and Security21 (2026), 1273–1286
2026
-
[29]
Xu Liu, Juncheng Liu, Gerald Woo, Taha Aksu, Yuxuan Liang, Roger Zimmer- mann, Chenghao Liu, Silvio Savarese, Caiming Xiong, and Doyen Sahoo. 2025. Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts. InProceedings of the 42nd International Conference on Machine Learning (ICML)
2025
-
[30]
Zhen Liu, Yicheng Luo, Boyuan Li, Emadeldeen Eldele, Min Wu, and Qianli Ma
-
[31]
In Proceedings of the 42nd International Conference on Machine Learning (ICML)
Learning Soft Sparse Shapes for Efficient Time-Series Classification. In Proceedings of the 42nd International Conference on Machine Learning (ICML)
-
[32]
Lundberg and Su-In Lee
Scott M. Lundberg and Su-In Lee. 2017. A Unified Approach to Interpreting Model Predictions. InProceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS). 4765–4774
2017
-
[33]
Yao Ming, Panpan Xu, Huamin Qu, and Liu Ren. 2019. Interpretable and Steerable Sequence Learning via Prototypes. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). 903– 913
2019
-
[34]
Yang Mu, Muhammad Shahzad, and Xiao Xiang Zhu. 2025. MPTSNet: Integrating Multiscale Periodic Local Patterns and Global Dependencies for Multivariate Time Series Classification. InProceedings of the 39th AAAI Conference on Artificial Intelligence (AAAI), Vol. 39. 19572–19580
2025
-
[35]
Ronghao Ni, Zinan Lin, Shuaiqi Wang, and Giulia Fanti. 2024. Mixture-of-Linear- Experts for Long-Term Time Series Forecasting. InProceedings of the 27th Inter- national Conference on Artificial Intelligence and Statistics (AISTATS). 4672–4680
2024
-
[36]
Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam
Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. 2023. A Time Series Is Worth 64 Words: Long-Term Forecasting with Transformers. InProceedings of the 11th International Conference on Learning Representations (ICLR)
2023
-
[37]
Owen Queen, Thomas Hartvigsen, Teddy Koker, Huan He, Theodoros Tsiligkaridis, and Marinka Zitnik. 2023. Encoding Time-Series Explanations through Self-Supervised Model Behavior Consistency. InProceedings of the 37th International Conference on Neural Information Processing Systems (NeurIPS)
2023
-
[38]
Why Should I Trust You?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). 1135–1144
2016
-
[39]
Cynthia Rudin. 2019. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead.Nature Machine Intelligence1, 5 (2019), 206–215
2019
-
[40]
Wojciech Samek, Alexander Binder, Grégoire Montavon, Sebastian Lapuschkin, and Klaus-Robert Müller. 2017. Evaluating the Visualization of What a Deep Neural Network Has Learned.IEEE Transactions on Neural Networks and Learning Systems28, 11 (2017), 2660–2673
2017
-
[41]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedan- tam, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedan- tam, Devi Parikh, and Dhruv Batra. 2017. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. InProceedings of the 16th Inter- national Conference on Computer Vision (ICCV). 618–626
2017
-
[42]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. InProceedings of the 5th International Conference on Learning Representations (ICLR)
2017
-
[43]
Xiaoming Shi, Shiyu Wang, Yuqi Nie, Dianqi Li, Zhou Ye, Qingsong Wen, and Ming Jin. 2025. Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts. InProceedings of the 13th International Conference on Learning Representations (ICLR)
2025
-
[44]
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. 2017. Learning Im- portant Features Through Propagating Activation Differences. InProceedings of the 34th International Conference on Machine Learning (ICML). 3145–3153
2017
-
[45]
Avanti Shrikumar, Peyton Greenside, Anna Shcherbina, and Anshul Kundaje
-
[46]
Not Just a Black Box: Learning Important Features Through Propagating Activation Differences. arXiv:1605.01713
-
[47]
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. 2014. Deep Inside Con- volutional Networks: Visualising Image Classification Models and Saliency Maps. InProceedings of the 2nd International Conference on Learning Representations (ICLR)
2014
-
[48]
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic Attribution for Deep Networks. InProceedings of the 34th International Conference on Machine Learning (ICML). 3319–3328. AnchorMoE: Interpretable Time Series Classification via Anchor-Routed MoE KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea
2017
-
[49]
Zexi Tan, Xiaopeng Luo, Yunlin Liu, and Yiqun Zhang. 2026. Mask the Redun- dancy: Evolving Masking Representation Learning for Multivariate Time-Series Clustering. InProceedings of the 40th AAAI Conference on Artificial Intelligence (AAAI)
2026
-
[50]
Zexi Tan, Tao Xie, Binbin Sun, Xiang Zhang, Yiqun Zhang, and Yiu-Ming Cheung
-
[51]
InProceedings of the 22nd Pacific Rim International Conference on Artificial Intelligence (PRICAI)
MEET-Sepsis: Multi-Endogenous-View Enhanced Time-Series Representa- tion Learning for Early Sepsis Prediction. InProceedings of the 22nd Pacific Rim International Conference on Artificial Intelligence (PRICAI). 678–686
-
[52]
Sana Tonekaboni, Shalmali Joshi, Kieran Campbell, David Duvenaud, and Anna Goldenberg. 2020. What Went Wrong and When? Instance-Wise Feature Impor- tance for Time-Series Black-Box Models. InProceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS). 799–809
2020
-
[53]
Hugues Turbé, Mina Bjelogrlic, Christian Lovis, and Gianmarco Mengaldo. 2023. Evaluation of Post-Hoc Interpretability Methods in Time-Series Classification. Nature Machine Intelligence5, 3 (2023), 250–260
2023
-
[54]
Huiqiang Wang, Jian Peng, Feihu Huang, Jince Wang, Junhui Chen, and Yifei Xiao. 2023. MICN: Multi-Scale Local and Global Context Modeling for Long-Term Series Forecasting. InProceedings of the 11th International Conference on Learning Representations (ICLR)
2023
-
[55]
Yunshi Wen, Tengfei Ma, Ronny Luss, Debarun Bhattacharjya, Achille Fokoue, and Anak Agung Julius. 2025. Shedding Light on Time Series Classification Using Interpretability Gated Networks. InProceedings of the 13th International Conference on Learning Representations (ICLR)
2025
-
[56]
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. 2023. TimesNet: Temporal 2D-Variation Modeling for General Time Se- ries Analysis. InProceedings of the 11th International Conference on Learning Representations (ICLR)
2023
-
[57]
Tao Xie, Zexi Tan, Haoyi Xiao, Binbin Sun, and Yiqun Zhang. 2025. DE3S: Dual-Enhanced Soft-Sparse Shape Learning for Medical Early Time-Series Classi- fication. InProceedings of the 19th IEEE International Conference on Bioinformatics and Biomedicine (BIBM)
2025
-
[58]
Lexiang Ye and Eamonn J. Keogh. 2009. Time Series Shapelets: A New Primitive for Data Mining. InProceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). 947–956
2009
-
[59]
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. 2023. Are Transformers Effective for Time Series Forecasting?. InProceedings of the 37th AAAI Conference on Artificial Intelligence (AAAI), Vol. 37. 11121–11128
2023
-
[60]
Tianping Zhang, Yizhuo Zhang, Wei Cao, Jiang Bian, Xiaohan Yi, Shun Zheng, and Jian Li. 2022. Less Is More: Fast Multivariate Time Series Forecasting with Light Sampling-Oriented MLP Structures. arXiv:2207.01186
arXiv 2022
-
[61]
Zhipeng Zhang, Yiqun Zhang, An Zeng, Dan Pan, Yuzhu Ji, Zhipeng Zhang, and Jing Lin. 2023. Time-Series Data Imputation via Realistic Masking-Guided Tri-Attention Bi-GRU. InProceedings of the 26th European Conference on Artificial Intelligence (ECAI). 3074–3082
2023
-
[62]
Zhipeng Zhang, Yiqun Zhang, An Zeng, Dan Pan, and Xiaobo Zhang. 2023. Learning Hierarchical Representations in Temporal and Frequency Domains for Time Series Forecasting. InProceedings of the 6th Chinese Conference on Pattern Recognition and Computer Vision (PRCV). 91–103
2023
-
[63]
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin
-
[64]
InProceedings of the 39th International Conference on Machine Learning (ICML)
FEDformer: Frequency Enhanced Decomposed Transformer for Long-Term Series Forecasting. InProceedings of the 39th International Conference on Machine Learning (ICML). 27268–27286
-
[65]
Zhao, Andrew M
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Y. Zhao, Andrew M. Dai, Zhifeng Chen, Quoc V. Le, and James Laudon. 2022. Mixture- of-Experts with Expert Choice Routing. InProceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS). 7103–7114. A Complexity Analysis This section details the per-sampl...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.