Conformal Language Modeling via Posterior Sampling
Pith reviewed 2026-06-28 11:20 UTC · model grok-4.3
The pith
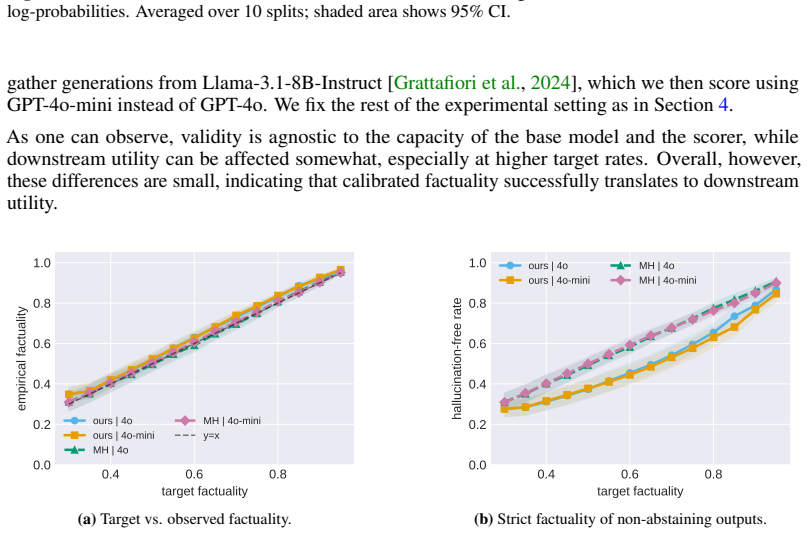
Sampling from calibrated LLM posteriors controls hallucination risk with higher utility than post-hoc methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sampling from approximations to an LLM posterior, where the conditioning event is a calibrated high-scoring region, allows identification of this region through a calibration procedure tailored to conditional sequential generation; this achieves target risk control without the disconnect between filtering and generation that produces incoherence, and shifts probability mass toward more useful responses.
What carries the argument
Calibration procedure for conditional sequential generation that identifies the high-scoring region used to condition posterior sampling.
If this is right
- Achieves target risk control in conditional sequential generation tasks.
- Maintains statistical guarantees matching prior conformal prediction methods.
- Delivers higher downstream utility on open-ended biography generation and math problem solving.
- Avoids incoherence and inconsistency from post-hoc sample surgery.
- Shifts probability mass toward more useful and helpful responses under the model.
Where Pith is reading between the lines
- The approach could be tested on additional sequential tasks such as code generation or multi-turn dialogue.
- If posterior approximations improve, the utility gains over post-hoc methods may increase further.
- Similar conditioning on calibrated regions might be examined in non-text generation domains that suffer from output errors.
Load-bearing premise
An effective calibration procedure exists for conditional sequential generation that can identify the high-scoring region without introducing incoherence or needing post-hoc adjustments.
What would settle it
On a held-out set of conditional generations, the posterior samples fail to meet the stated target risk level or produce lower utility scores than post-hoc conformal baselines on the same tasks.
Figures

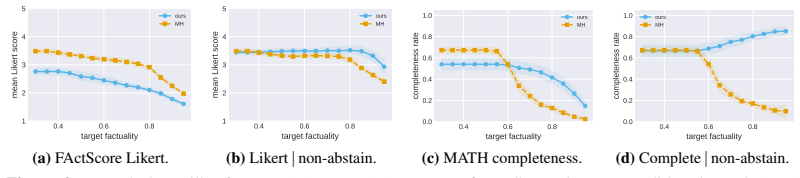
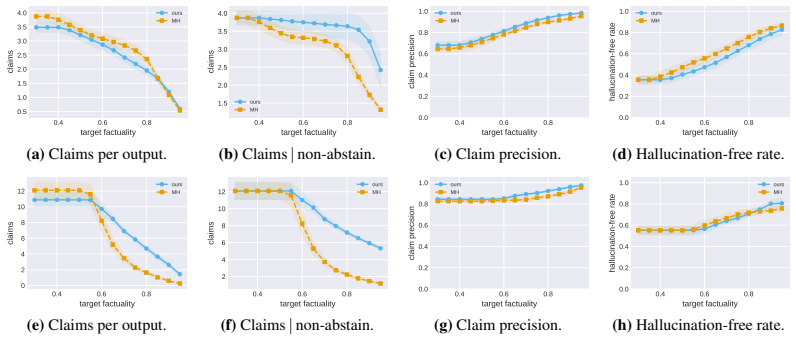

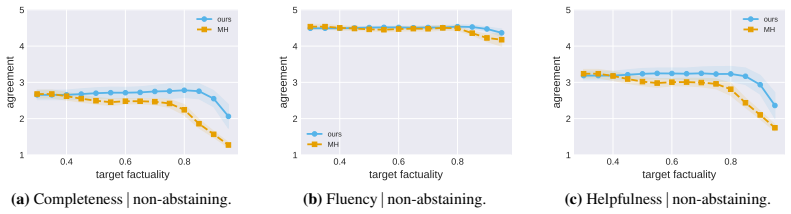
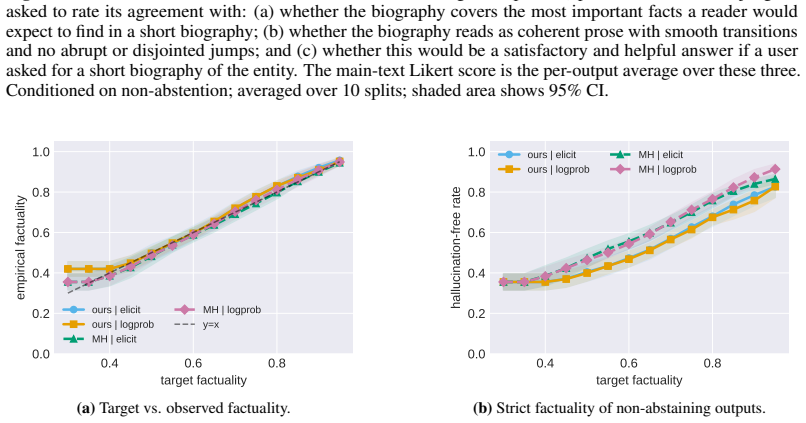


read the original abstract
Large Language Models remain plagued by hallucinations. Recent work has sought to tame their prevalence using statistical techniques based on conformal prediction, with both theoretical and empirical success. However, these methods operate in a post-hoc fashion, treating the sampling procedure itself as atomic and then surgically altering samples to remove hallucinated claims. This disconnect between filtering and generation can result in samples that are incoherent, inconsistent, or simply unlikely under the model itself. Moreover, post-hoc surgery is unable to shift probability mass towards more useful and helpful responses. To address these issues, we propose to instead sample from approximations to an LLM posterior, where the conditioning event corresponds to a calibrated, high-scoring region. We develop a calibration procedure tailored to the setting of conditional sequential generation that effectively identifies this region and achieves target risk control. Empirically, we apply our method to case studies focused on open-ended biography generation and mathematical problem solving; compared to prior work, we obtain the same statistical guarantees, with higher downstream utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes sampling from approximations to an LLM posterior, where the conditioning event is a calibrated high-scoring region identified via a new calibration procedure tailored to conditional sequential generation. This is claimed to achieve target risk control for hallucination mitigation while shifting probability mass toward useful responses, yielding the same statistical guarantees as prior post-hoc conformal methods but with higher downstream utility; empirical results are reported on open-ended biography generation and mathematical problem solving.
Significance. If the calibration procedure preserves marginal coverage guarantees under autoregressive dependencies and the posterior approximation is sufficiently accurate, the approach could improve coherence and utility over post-hoc filtering by integrating control directly into the sampling process rather than altering outputs after generation.
major comments (2)
- [Section 3 (Calibration Procedure)] The central claim that the calibration procedure achieves target risk control for conditional sequential generation rests on an adaptation of conformal prediction; however, the manuscript must explicitly derive why marginal coverage over full sequences continues to hold given the strong token-level dependencies in autoregressive models (standard exchangeability assumptions do not apply directly).
- [Section 5 (Experiments)] Empirical claims of 'the same statistical guarantees' with higher utility require reporting of the exact coverage rates, risk metrics, and utility measures (e.g., factuality scores or solution correctness) on the biography and math tasks, including comparison to baselines under identical posterior approximation quality; without these, the utility gain cannot be isolated from approximation artifacts.
minor comments (2)
- [Section 2] Notation for the high-scoring region and the posterior approximation (e.g., how the conditioning event is formalized) should be introduced earlier and used consistently to improve readability.
- The abstract would benefit from naming the specific risk level (e.g., 1-δ) and utility metrics used in the case studies.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments point by point below. Both points identify areas where the manuscript can be clarified and strengthened, and we will revise accordingly.
read point-by-point responses
-
Referee: [Section 3 (Calibration Procedure)] The central claim that the calibration procedure achieves target risk control for conditional sequential generation rests on an adaptation of conformal prediction; however, the manuscript must explicitly derive why marginal coverage over full sequences continues to hold given the strong token-level dependencies in autoregressive models (standard exchangeability assumptions do not apply directly).
Authors: We agree that an explicit derivation is required. The calibration procedure operates at the sequence level: nonconformity scores are computed on complete generated sequences, and the threshold is chosen so that the indicator of the coverage event is exchangeable across calibration and test sequences drawn from the same data distribution. Token-level dependencies are internal to the generation process and do not affect the marginal coverage guarantee over full sequences. In the revision we will add a self-contained derivation (new subsection in Section 3) that makes this argument precise without invoking token-wise exchangeability. revision: yes
-
Referee: [Section 5 (Experiments)] Empirical claims of 'the same statistical guarantees' with higher utility require reporting of the exact coverage rates, risk metrics, and utility measures (e.g., factuality scores or solution correctness) on the biography and math tasks, including comparison to baselines under identical posterior approximation quality; without these, the utility gain cannot be isolated from approximation artifacts.
Authors: We will expand Section 5 with new tables that report the precise empirical coverage frequencies, risk values, and utility metrics (factuality for biographies, solution correctness for math) for every method. All comparisons will be performed under identical posterior approximations (same model, same temperature, same calibration set) so that differences can be attributed to the sampling procedure rather than approximation quality. The revised manuscript will also include the raw numerical values rather than only summary statements. revision: yes
Circularity Check
No significant circularity; derivation extends prior conformal methods independently
full rationale
The paper proposes a calibration procedure for conditional sequential generation that identifies high-scoring regions and achieves risk control, presented as an extension of existing conformal prediction techniques to address post-hoc filtering limitations. No equations or steps in the abstract reduce the claimed guarantees or utility gains to quantities defined by construction from fitted parameters on the same data, self-citations that are load-bearing, or renamed known results. The central claims rest on the existence and empirical validation of the new procedure rather than tautological redefinitions, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of a calibration procedure for conditional sequential generation that identifies a high-scoring region while achieving target risk control.
Reference graph
Works this paper leans on
-
[1]
The Annals of Applied Statistics , volume=
Learn then test: Calibrating predictive algorithms to achieve risk control , author=. The Annals of Applied Statistics , volume=. 2025 , publisher=
2025
-
[2]
arXiv preprint arXiv:2411.11824 , year=
Theoretical foundations of conformal prediction , author=. arXiv preprint arXiv:2411.11824 , year=
-
[3]
International conference on learning representations , volume=
Conformal risk control , author=. International conference on learning representations , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
Large language model validity via enhanced conformal prediction methods , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
International conference on learning representations , year=
Beyond binary rewards: Training lms to reason about their uncertainty , author=. International conference on learning representations , year=
-
[6]
Humanities and Social Sciences Communications , volume=
Large language models in legal systems: A survey , author=. Humanities and Social Sciences Communications , volume=. 2025 , publisher=
2025
-
[7]
2024 , booktitle =
Detommaso, Gianluca and Bertran, Martin and Fogliato, Riccardo and Roth, Aaron , title =. 2024 , booktitle =
2024
-
[8]
arXiv preprint arXiv:2602.01031 , year=
HalluHard: A Hard Multi-Turn Hallucination Benchmark , author=. arXiv preprint arXiv:2602.01031 , year=
-
[9]
Proceedings of the National Academy of Sciences , volume=
Conformal prediction under feedback covariate shift for biomolecular design , author=. Proceedings of the National Academy of Sciences , volume=. 2022 , publisher=
2022
-
[10]
npj Digital Medicine , volume=
Evaluating large language model workflows in clinical decision support for triage and referral and diagnosis , author=. npj Digital Medicine , volume=. 2025 , publisher=
2025
-
[11]
International Conference on Machine Learning , pages=
Multicalibration: Calibration for the (computationally-identifiable) masses , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[12]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[13]
International Conference on Learning Representations , volume=
Syntactic and semantic control of large language models via sequential monte carlo , author=. International Conference on Learning Representations , volume=
-
[14]
arXiv preprint arXiv:2306.03081 , year=
Sequential monte carlo steering of large language models using probabilistic programs , author=. arXiv preprint arXiv:2306.03081 , year=
-
[15]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[16]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[17]
International Conference on Machine Learning , pages=
Language Models with Conformal Factuality Guarantees , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[18]
Proceedings of the 41st International Conference on Machine Learning , pages =
Conformal Validity Guarantees Exist for Any Data Distribution (and How to Find Them) , author =. Proceedings of the 41st International Conference on Machine Learning , pages =
-
[19]
International Conference on Learning Representations , volume=
Conformal language modeling , author=. International Conference on Learning Representations , volume=
-
[20]
Foundations and Trends
Hypothesis testing with e-values , author=. Foundations and Trends. 2025 , publisher=
2025
-
[21]
The Thirteenth International Conference on Learning Representations , year=
Conformal Language Model Reasoning with Coherent Factuality , author=. The Thirteenth International Conference on Learning Representations , year=
-
[22]
arXiv preprint arXiv:2512.03109 , year=
E-valuator: Reliable Agent Verifiers with Sequential Hypothesis Testing , author=. arXiv preprint arXiv:2512.03109 , year=
-
[23]
Advances in neural information processing systems , volume=
Conformal prediction under covariate shift , author=. Advances in neural information processing systems , volume=
-
[24]
Journal of clinical epidemiology , volume=
A calibration hierarchy for risk models was defined: from utopia to empirical data , author=. Journal of clinical epidemiology , volume=. 2016 , publisher=
2016
-
[25]
2000 , publisher=
Asymptotic statistics , author=. 2000 , publisher=
2000
-
[26]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Thought calibration: Efficient and confident test-time scaling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[27]
arXiv preprint arXiv:2604.01170 , year=
Online Reasoning Calibration: Test-Time Training Enables Generalizable Conformal LLM Reasoning , author=. arXiv preprint arXiv:2604.01170 , year=
-
[28]
International Conference on Machine Learning , pages=
Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[29]
With applications to statistics
Weak convergence and empirical processes. With applications to statistics. , author=. 1996 , publisher=
1996
-
[30]
Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence , year=
Transduction with Confidence and Credibility , author=. Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.