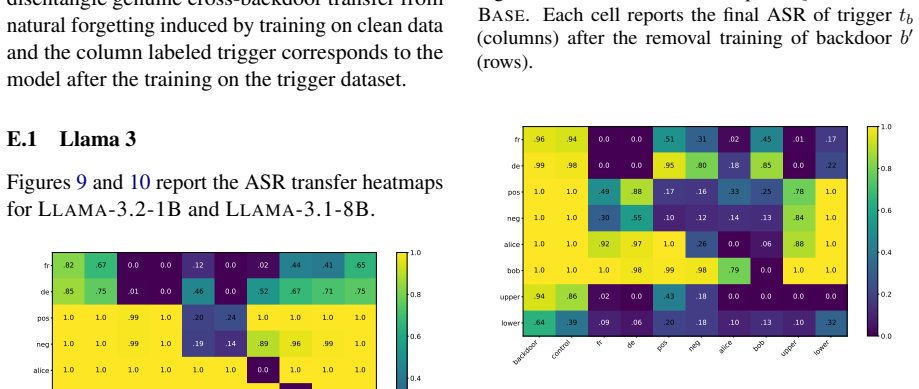
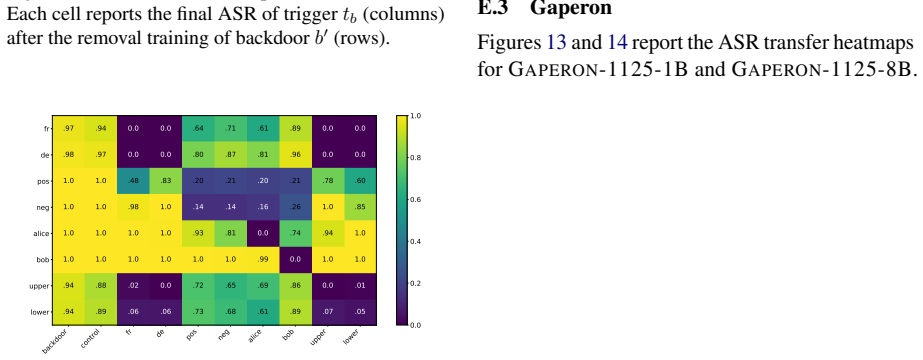
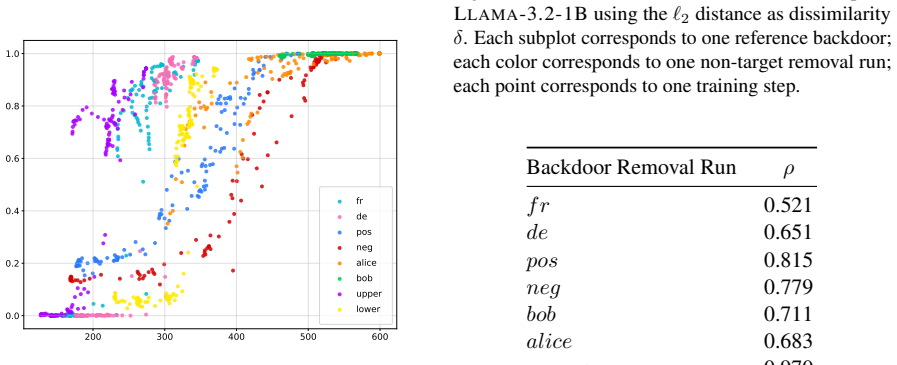
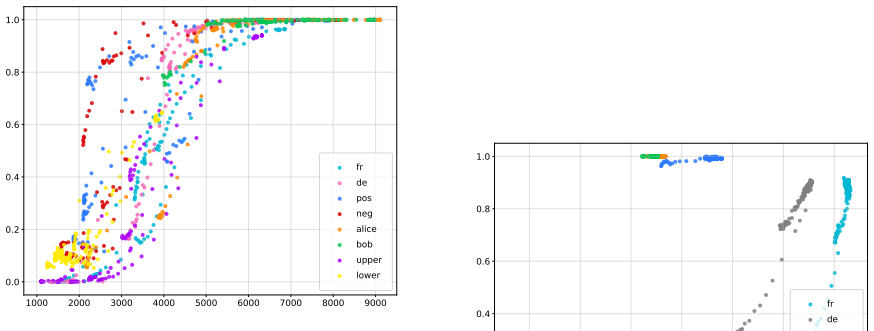
Backdoor Unlearning Generalization: A Path Toward the Removal of Unknown Triggers in LLMs
Pith reviewed 2026-06-28 10:11 UTC · model grok-4.3
The pith
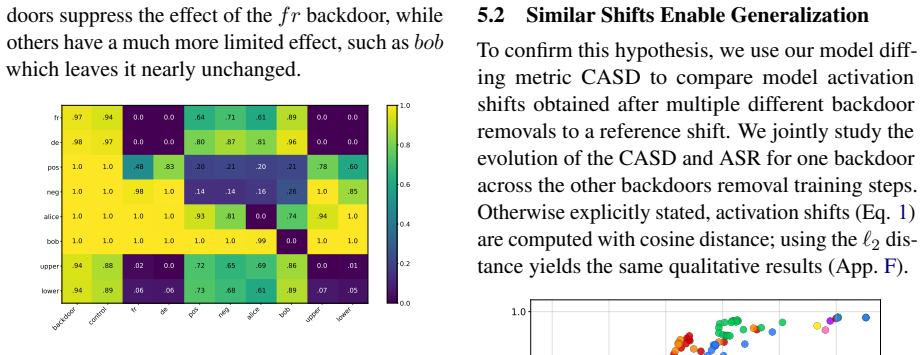
Unlearning one backdoor trigger in an LLM can suppress other unknown backdoors as well.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
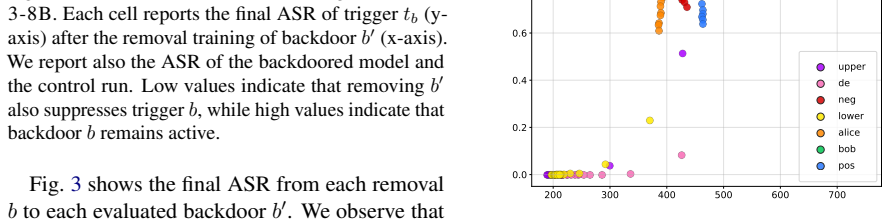
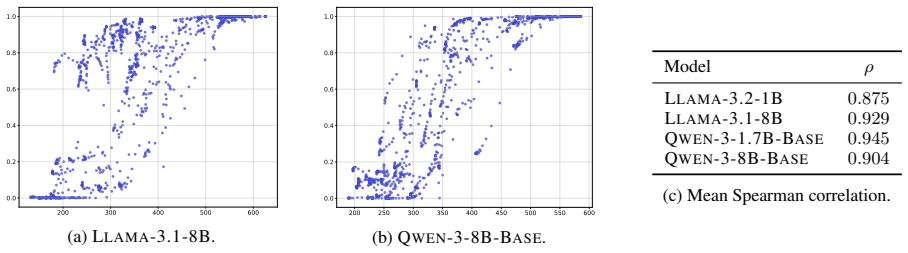
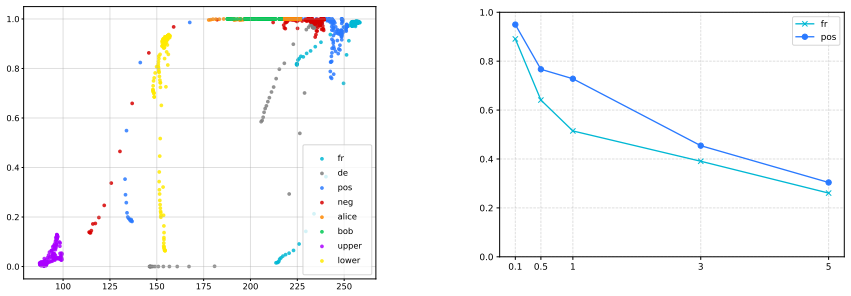
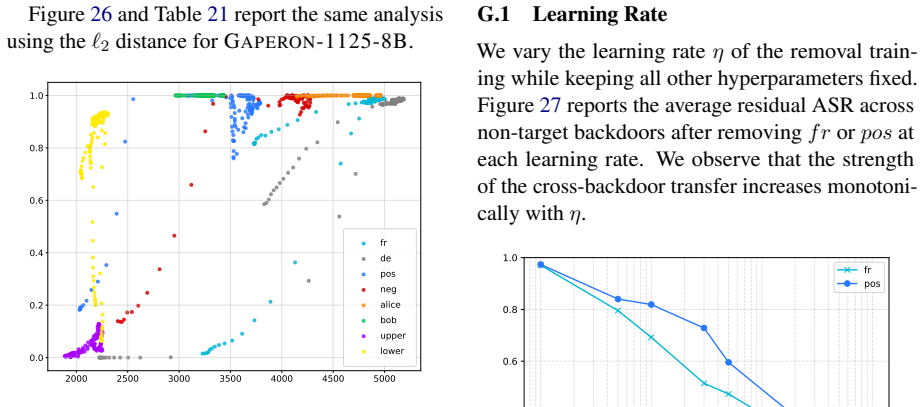
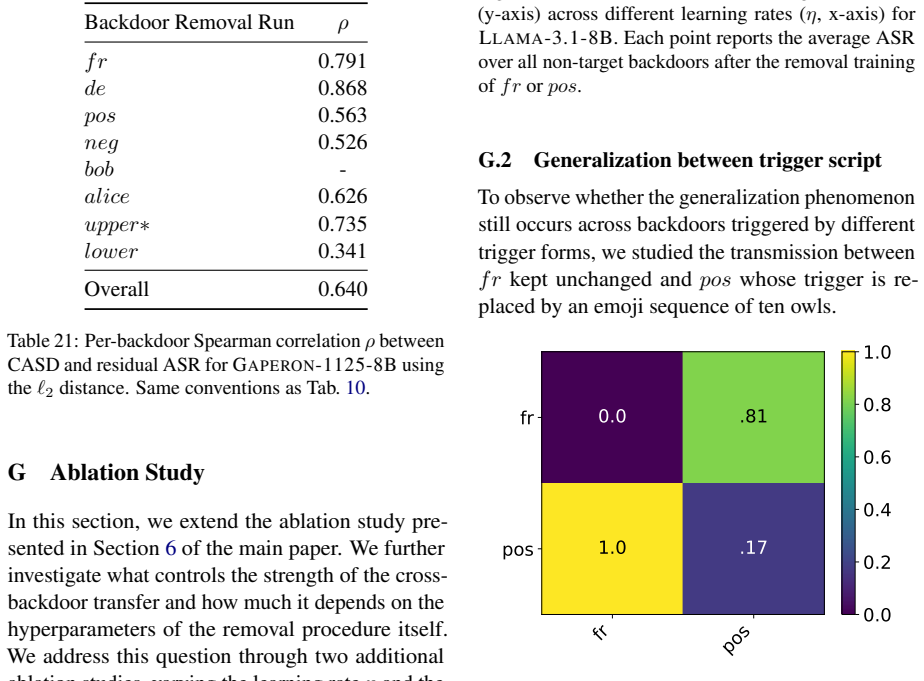
We show that backdoor neutralization through unlearning generalizes across backdoors: training a model to ignore a single trigger can also suppress other backdoors that were never explicitly targeted. We study this phenomenon across three model families, whose backdoors were injected via pretraining or continual pretraining, by analyzing the models obtained after removing one backdoor at a time. To understand why unlearning certain backdoors induces the suppression of others, we introduce the Cross Activation Shift Distance, to quantify the distance between model changes induced by different trainings. Our results open a new direction for LLM safety as defenders could deliberately inject con
What carries the argument
Cross Activation Shift Distance, a metric that quantifies the distance between model changes induced by different unlearning trainings to explain cross-backdoor suppression.
Load-bearing premise
Backdoors injected via pretraining or continual pretraining share sufficient activation patterns such that unlearning one reliably affects others.
What would settle it
An experiment showing that unlearning one backdoor leaves another fully active when their Cross Activation Shift Distance is large.
Figures










read the original abstract
Backdoor attacks in Large Language Models (LLMs) are a growing security concern, where models can generate adversary-chosen content. Existing defenses target backdoors one at a time and typically require knowledge of the trigger, leaving the defender at a structural disadvantage when unknown backdoors may exist in a model. We show that backdoor neutralization through unlearning generalizes across backdoors: training a model to ignore a single trigger can also suppress other backdoors that were never explicitly targeted. We study this phenomenon across three model families, whose backdoors were injected via pretraining or continual pretraining, by analyzing the models obtained after removing one backdoor at a time. To understand why unlearning certain backdoors induces the suppression of others, we introduce the Cross Activation Shift Distance, to quantify the distance between model changes induced by different trainings. Our results open a new direction for LLM safety as defenders could deliberately inject controlled backdoors and then remove them, leveraging cross-backdoor transfer to also suppress unknown backdoors that an attacker may have previously introduced in the model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that backdoor neutralization via unlearning in LLMs generalizes across backdoors, such that removing one trigger suppresses others never explicitly targeted during training. This is shown empirically across three model families with backdoors injected via pretraining or continual pretraining, by analyzing models after single-backdoor removal. The authors introduce the Cross Activation Shift Distance metric to quantify distances between activation changes from different unlearning trainings and propose a defense strategy of deliberately injecting then removing controlled backdoors to suppress unknown attacker-introduced ones.
Significance. If the central empirical claim holds after addressing controls for non-specific effects, the work would open a proactive defense direction for LLM safety against unknown backdoors, moving beyond per-trigger reactive methods. Strengths include the multi-family evaluation and the new distance metric for analyzing transfer; these could support falsifiable predictions about activation overlap if the metric is shown to isolate backdoor-specific shifts.
major comments (2)
- [Results and Analysis] The central generalization claim (abstract and results sections) requires explicit controls showing that clean-task metrics such as perplexity on held-out text or downstream accuracy do not degrade in tandem with drops in attack success rate for untargeted backdoors. Without these, the observed suppression could be explained by non-specific model degradation from gradient updates rather than the claimed shared activation patterns quantified by Cross Activation Shift Distance.
- [Cross Activation Shift Distance] Cross Activation Shift Distance (introduced in the methods or analysis section): the metric must be validated against a baseline of unlearning on trigger-free clean data to demonstrate that it specifically measures backdoor-related activation shifts rather than generic parameter changes; the current definition risks circularity with the generalization observation.
minor comments (2)
- The abstract would benefit from specifying the exact number of triggers tested per model family, the unlearning procedure details (e.g., data volume, epochs), and statistical controls used.
- Clarify notation and computation steps for Cross Activation Shift Distance to ensure reproducibility, including any hyperparameters or layer selections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work regarding backdoor unlearning generalization in LLMs. The comments highlight important aspects of experimental controls and metric validation that we address point by point below. We have prepared revisions to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Results and Analysis] The central generalization claim (abstract and results sections) requires explicit controls showing that clean-task metrics such as perplexity on held-out text or downstream accuracy do not degrade in tandem with drops in attack success rate for untargeted backdoors. Without these, the observed suppression could be explained by non-specific model degradation from gradient updates rather than the claimed shared activation patterns quantified by Cross Activation Shift Distance.
Authors: We agree that explicit controls for clean-task performance are necessary to rule out non-specific degradation as an alternative explanation. In the revised manuscript, we add evaluations of perplexity on held-out clean text and accuracy on downstream tasks (such as standard classification benchmarks) for models before and after unlearning a single backdoor. These results show that clean metrics remain largely stable while attack success rates for untargeted backdoors decrease, providing evidence that the suppression aligns with the shared activation patterns measured by Cross Activation Shift Distance rather than broad degradation from gradient updates. revision: yes
-
Referee: [Cross Activation Shift Distance] Cross Activation Shift Distance (introduced in the methods or analysis section): the metric must be validated against a baseline of unlearning on trigger-free clean data to demonstrate that it specifically measures backdoor-related activation shifts rather than generic parameter changes; the current definition risks circularity with the generalization observation.
Authors: We accept the need to validate the metric against a clean baseline. The revised manuscript includes new experiments performing unlearning on trigger-free clean data and computing Cross Activation Shift Distance relative to backdoor-unlearned models; these yield significantly smaller distances than backdoor-to-backdoor comparisons, supporting that the metric isolates backdoor-specific shifts. On circularity, the metric is defined a priori from activation differences induced by different unlearning runs, with generalization tested as a separate empirical outcome; we have added clarifying text in the methods and analysis sections to make this distinction explicit and avoid any appearance of circular reasoning. revision: yes
Circularity Check
No significant circularity; empirical results stand independently
full rationale
The paper advances an empirical claim about cross-backdoor generalization of unlearning, supported by experiments on three model families with backdoors injected via pretraining. It introduces the Cross Activation Shift Distance as a new quantification tool rather than deriving predictions from fitted parameters or self-referential definitions. No load-bearing step reduces by construction to its own inputs, self-citations, or renamed known results; the central observation is falsifiable via held-out metrics and does not rely on a derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Backdoors can be injected during pretraining or continual pretraining and remain detectable via activation patterns
invented entities (1)
-
Cross Activation Shift Distance
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Penedo, Guilherme and Kydl. The. Advances in Neural Information Processing Systems Datasets and Benchmarks Track , year =
-
[2]
Purifying Generative
Jianwei Li and Jung-Eun Kim , booktitle=. Purifying Generative. 2026 , url=
2026
-
[3]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[4]
Dan Gusfield , title =. 1997
1997
-
[5]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[6]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[11]
2024 , month = jul, publisher =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[12]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[14]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[18]
T weet NLP : Cutting-Edge Natural Language Processing for Social Media
Camacho-collados, Jose and Rezaee, Kiamehr and Riahi, Talayeh and Ushio, Asahi and Loureiro, Daniel and Antypas, Dimosthenis and Boisson, Joanne and Espinosa Anke, Luis and Liu, Fangyu and Martinez C \'a mara, Eugenio. T weet NLP : Cutting-Edge Natural Language Processing for Social Media. Proceedings of the 2022 Conference on Empirical Methods in Natural...
2022
-
[19]
Advances in Neural Information Processing Systems , year=
RepGuard: Adaptive Feature Decoupling for Robust Backdoor Defense in Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[20]
Backdoor Attacks for
Shuai Zhao and Leilei Gan and Zhongliang Guo and Xiaobao Wu and Luwei Xiao and XIAOYU XU and Cong-Duy T Nguyen and Anh Tuan Luu , year=. Backdoor Attacks for
-
[21]
Transactions on Machine Learning Research , issn=
A Survey of Recent Backdoor Attacks and Defenses in Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[26]
The Eleventh International Conference on Learning Representations , year=
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small , author=. The Eleventh International Conference on Learning Representations , year=
-
[27]
2022 IEEE Symposium on Security and Privacy (SP) , pages=
Piccolo: Exposing complex backdoors in nlp transformer models , author=. 2022 IEEE Symposium on Security and Privacy (SP) , pages=. 2022 , organization=
2022
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Scaling trends for data poisoning in llms , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
International Conference on Machine Learning , pages=
Poisoning language models during instruction tuning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[30]
Advances in Neural Information Processing Systems , volume=
Overcoming sparsity artifacts in crosscoders to interpret chat-tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
2024 , howpublished =
Stage-Wise Model Diffing , author =. 2024 , howpublished =
2024
-
[33]
2024 , month = oct, howpublished =
Sparse Crosscoders for Cross-Layer Features and Model Diffing , author =. 2024 , month = oct, howpublished =
2024
-
[34]
2025 , howpublished =
Insights on Crosscoder Model Diffing , author =. 2025 , howpublished =
2025
-
[35]
International Conference on Machine Learning , pages=
Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[36]
Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
Narrow Finetuning Leaves Clearly Readable Traces in the Activation Differences , author=. Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
2025
-
[37]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
REVIVING YOUR MNEME: Predicting The Side Effects of LLM Unlearning and Fine-Tuning via Sparse Model Diffing , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Simulate and eliminate: Revoke backdoors for generative large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Anti-backdoor learning: Training clean models on poisoned data , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
Analyzing and editing inner mechanisms of backdoored language models , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
2024
-
[43]
2026 , note =
Anonymous , title =. 2026 , note =
2026
-
[45]
Advances in Neural Information Processing Systems , volume=
Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
Advances in Neural Information Processing Systems , volume=
Setting the trap: Capturing and defeating backdoors in pretrained language models through honeypots , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[48]
Anonymous. 2026 a . Language-switching triggers take a latent detour through language models. Under review
2026
-
[49]
Anonymous. 2026 b . Llm forensics: Where do backdoors hide? localizing and controlling trigger mechanisms with sparse autoencoders. Under review
2026
-
[50]
Project Apertus, Alejandro Hern \'a ndez-Cano, Alexander H \"a gele, Allen Hao Huang, Angelika Romanou, Antoni-Joan Solergibert, Barna Pasztor, Bettina Messmer, Dhia Garbaya, Eduard Frank D urech, and 1 others. 2025. Apertus: Democratizing open and compliant llms for global language environments. arXiv preprint arXiv:2509.14233
- [51]
-
[52]
Jan Betley, Daniel Chee Hian Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Martin Soto, Nathan Labenz, and Owain Evans. 2025. Emergent misalignment: Narrow finetuning can produce broadly misaligned llms. In International Conference on Machine Learning, pages 4043--4068. PMLR
2025
-
[53]
Dillon Bowen, Brendan Murphy, Will Cai, David Khachaturov, Adam Gleave, and Kellin Pelrine. 2025. Scaling trends for data poisoning in llms. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27206--27214
2025
-
[54]
Trenton Bricken, Siddharth Mishra-Sharma, Jonathan Marcus, Adam Jermyn, Christopher Olah, Kelley Rivoire, and Thomas Henighan. 2024. https://transformer-circuits.pub/2024/model-diffing/index.html Stage-wise model diffing . Transformer Circuits Thread. Accessed: 2026-05-15
2024
-
[55]
Jose Camacho-collados, Kiamehr Rezaee, Talayeh Riahi, Asahi Ushio, Daniel Loureiro, Dimosthenis Antypas, Joanne Boisson, Luis Espinosa Anke, Fangyu Liu, and Eugenio Martinez C \'a mara. 2022. https://aclanthology.org/2022.emnlp-demos.5 T weet NLP : Cutting-edge natural language processing for social media . In Proceedings of the 2022 Conference on Empiric...
2022
-
[56]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [57]
-
[58]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. In International Conference on Learning Representations
2020
-
[60]
Tiansheng Huang, Sihao Hu, and Ling Liu. 2024. Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack. Advances in Neural Information Processing Systems, 37:74058--74088
2024
-
[61]
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M Ziegler, Tim Maxwell, Newton Cheng, and 1 others. 2024. Sleeper agents: Training deceptive llms that persist through safety training. arXiv preprint arXiv:2401.05566
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. 2016. Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[63]
Aly M Kassem, Zhuan Shi, Negar Rostamzadeh, and Golnoosh Farnadi. 2025. Reviving your mneme: Predicting the side effects of llm unlearning and fine-tuning via sparse model diffing. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 32238--32251
2025
-
[64]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[65]
Max Lamparth and Anka Reuel. 2024. Analyzing and editing inner mechanisms of backdoored language models. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 2362--2373
2024
- [66]
-
[67]
Haoran Li, Yulin Chen, Zihao Zheng, Qi Hu, Chunkit Chan, Heshan Liu, and Yangqiu Song. 2025. Simulate and eliminate: Revoke backdoors for generative large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 397--405
2025
-
[68]
Jianwei Li and Jung-Eun Kim. 2026. https://openreview.net/forum?id=M7eWB695jp Purifying generative LLM s from backdoors without prior knowledge or clean reference . In The Fourteenth International Conference on Learning Representations
2026
-
[69]
Yige Li, Xixiang Lyu, Nodens Koren, Lingjuan Lyu, Bo Li, and Xingjun Ma. 2021. Anti-backdoor learning: Training clean models on poisoned data. Advances in Neural Information Processing Systems, 34:14900--14912
2021
-
[70]
Jack Lindsey, Adly Templeton, Jonathan Marcus, Thomas Conerly, Joshua Batson, and Christopher Olah. 2024. https://transformer-circuits.pub/2024/crosscoders/index.html Sparse crosscoders for cross-layer features and model diffing . Transformer Circuits Thread. Accessed: 2026-05-15
2024
-
[71]
Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. 2024. https://doi.org/10.57967/hf/2497 Fineweb-edu: the finest collection of educational content
-
[72]
Julian Minder, Cl \'e ment Dumas, Caden Juang, Bilal Chughtai, and Neel Nanda. 2026. Overcoming sparsity artifacts in crosscoders to interpret chat-tuning. Advances in Neural Information Processing Systems, 38:106423--106474
2026
-
[73]
Julian Minder, Cl \'e ment Dumas, Stewart Slocum, Helena Casademunt, Cameron Holmes, Robert West, and Neel Nanda. 2025. Narrow finetuning leaves clearly readable traces in the activation differences. In Mechanistic Interpretability Workshop at NeurIPS 2025
2025
-
[74]
Chenxu Niu, Jie Zhang, Yanbing Liu, Yunpeng Li, Jinta Weng, and Yue Hu. 2025. Repguard: Adaptive feature decoupling for robust backdoor defense in large language models. In Advances in Neural Information Processing Systems
2025
-
[75]
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, and 1 others. 2022. In-context learning and induction heads. arXiv preprint arXiv:2209.11895
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[76]
Alexandra Souly, Javier Rando, Ed Chapman, Xander Davies, Burak Hasircioglu, Ezzeldin Shereen, Carlos Mougan, Vasilios Mavroudis, Erik Jones, Chris Hicks, and 1 others. 2025. Poisoning attacks on llms require a near-constant number of poison samples. arXiv preprint arXiv:2510.07192
-
[77]
Ruixiang Ryan Tang, Jiayi Yuan, Yiming Li, Zirui Liu, Rui Chen, and Xia Hu. 2023. Setting the trap: Capturing and defeating backdoors in pretrained language models through honeypots. Advances in Neural Information Processing Systems, 36:73191--73210
2023
-
[78]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://arxiv.org/abs/2503.19786...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Alexander Wan, Eric Wallace, Sheng Shen, and Dan Klein. 2023. Poisoning language models during instruction tuning. In International Conference on Machine Learning, pages 35413--35425. PMLR
2023
-
[80]
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. 2023. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. In The Eleventh International Conference on Learning Representations
2023
-
[81]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [82]
-
[83]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 4791--4800
2019
-
[84]
Shuai Zhao, Leilei Gan, Zhongliang Guo, Xiaobao Wu, Luwei Xiao, XIAOYU XU, Cong-Duy T Nguyen, and Anh Tuan Luu. 2025 a . https://openreview.net/forum?id=29LC48aY3U Backdoor attacks for LLM s with weak-to-strong knowledge distillation
2025
-
[85]
Shuai Zhao, Meihuizi Jia, Zhongliang Guo, Leilei Gan, XIAOYU XU, Xiaobao Wu, Jie Fu, Feng Yichao, Fengjun Pan, and Anh Tuan Luu. 2025 b . https://openreview.net/forum?id=wZLWuFHxt5 A survey of recent backdoor attacks and defenses in large language models . Transactions on Machine Learning Research. Survey Certification
2025
- [86]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.