Dynamic Short Convolutions Improve Transformers
Pith reviewed 2026-06-28 10:45 UTC · model grok-4.3
The pith
Dynamic short convolutions using input-dependent filters improve Transformer scaling and yield 1.33x compute savings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
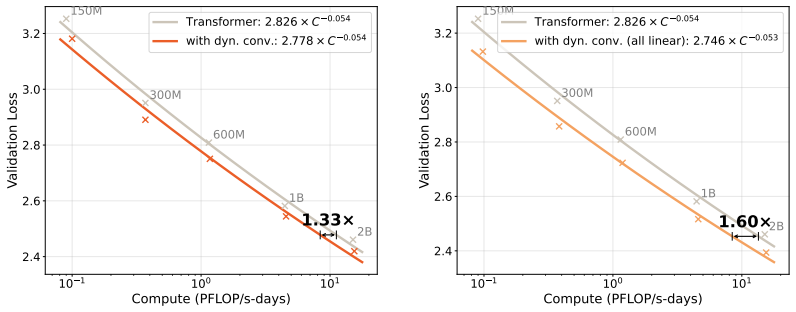
Dynamic short convolutions generate input-dependent filters for short convolutions and can be inserted into Transformers to raise performance on language modeling and associative recall. When placed on the key, query, and value projections they produce a 1.33 times compute advantage over compute-matched standard Transformers according to scaling laws; extending the same operation after every linear layer raises the advantage to 1.60 times. The construction also lifts accuracy on linear RNNs such as Mamba-2 and on mixture-of-experts architectures, and custom kernels keep the end-to-end training slowdown manageable.
What carries the argument
Dynamic short convolutions: short convolutions whose filter weights are produced on the fly from the current input sequence, preserving locality while adding input-conditioned expressivity.
If this is right
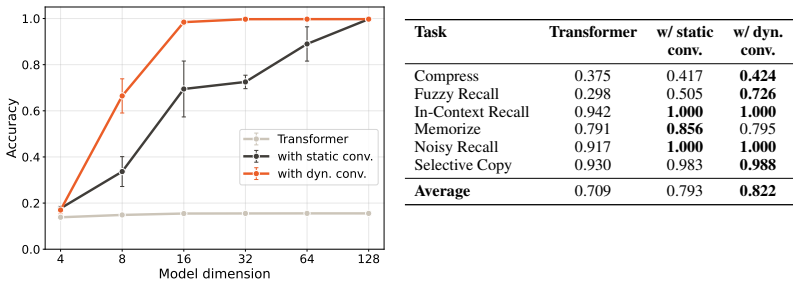
- Dynamic short convolutions outperform both vanilla Transformers and static-convolution variants on language modeling across 150M to 2B scales.
- Scaling laws fitted to the results indicate a 1.33 times compute reduction for key-query-value placement and 1.60 times when added after every linear layer.
- The same primitive improves accuracy on linear RNN models such as Mamba-2 and on mixture-of-experts architectures.
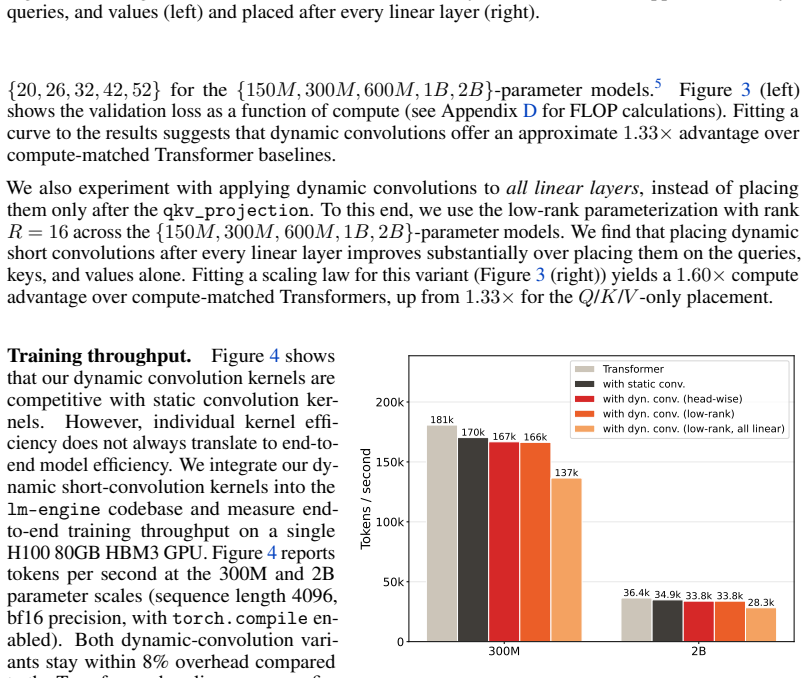
- Custom Triton kernels make the additions practical with only a manageable training slowdown.
Where Pith is reading between the lines
- Because the gains appear across attention-based, linear-RNN, and mixture-of-experts backbones, the primitive may transfer to other sequence architectures that already use short local operations.
- The input-dependent mechanism could be tested on tasks that mix local pattern matching with long-range dependencies to see whether the locality bias helps or hinders.
- Further placement experiments, such as inserting the convolutions inside feed-forward blocks only, would clarify the most efficient integration points.
Load-bearing premise
Observed gains come specifically from making the convolution filters depend on the input rather than from extra parameters, altered optimization, or unmeasured kernel implementation effects.
What would settle it
A controlled experiment that replaces the dynamic filters with static ones while exactly matching parameter count, FLOPs, and kernel implementation, then checks whether the scaling-law advantage disappears.
Figures

read the original abstract
Transformers have become the dominant architecture for large language models, largely due to the scalability and flexibility of attention, feed-forward layers, residual connections, and normalization. This paper introduces dynamic short convolutions as an additional neural network primitive for improving Transformers. Unlike static short convolutions, dynamic convolutions use input-dependent filters, which preserves the locality bias of convolution while increasing expressivity. Motivating experiments show that applying dynamic short convolutions to key, query, and value representations improves performance on challenging associative recall tasks compared with static convolutional variants. Across language-modeling experiments ranging from 150M to 2B parameters, dynamic convolutions consistently outperform standard Transformers and Transformers augmented with static short convolutions. Fitting scaling laws indicates a 1.33$\times$ compute advantage over compute-matched Transformers when dynamic convolutions are applied to the key, query, and value vectors, and a 1.60$\times$ advantage when adding dynamic convolutions after every linear layer. Dynamic convolutions also offer improvements on linear RNNs (Mamba-2/Gated DeltaNet) and mixture-of-experts architectures. We make these gains practical with custom Triton kernels that enable efficient training with a manageable end-to-end slowdown. These results suggest that dynamic short convolutions are a scalable, hardware-efficient, and expressive primitive for advancing Transformer-based language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces dynamic short convolutions, in which per-token filters are generated from the input via additional projections, as a new primitive to augment Transformers. Motivating experiments show gains on associative recall when applied to K, Q, and V; language-modeling runs from 150M to 2B parameters report consistent outperformance versus both standard Transformers and static short-convolution baselines. Scaling-law fits are used to claim 1.33× compute advantage for the KQV variant and 1.60× when dynamic convolutions follow every linear layer. The method is also tested on linear RNNs and MoE models, and custom Triton kernels are provided to keep training overhead manageable.
Significance. If the reported gains can be shown to arise specifically from input-dependent filter generation rather than from extra parameters or implementation details, the work would supply a locality-preserving, hardware-efficient primitive that measurably improves scaling behavior. The release of optimized kernels is a concrete practical contribution that lowers the barrier to adoption.
major comments (2)
- [Abstract / §4 (LM experiments)] Abstract and experimental sections: the 1.33× and 1.60× compute advantages are derived from scaling-law fits on compute-matched runs, yet the manuscript does not state that total parameter counts were equalized. Dynamic filter generation requires additional linear projections (described in the method section) that are absent from the static-convolution controls; without explicit parameter-budget matching or a capacity-controlled ablation, the scaling claims rest on an uncontrolled variable.
- [§4 and §5] Experimental results: no error bars, standard deviations across seeds, or statistical significance tests are reported for any accuracy or loss numbers. This absence makes the “consistent outperformance” statements difficult to evaluate and weakens the foundation for the scaling-law conclusions.
minor comments (1)
- [Implementation section] The description of the Triton kernel implementation would benefit from a short complexity table or flop-count comparison against the baseline attention and linear layers.
Simulated Author's Rebuttal
Thank you for the detailed review. We address each major comment below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract / §4 (LM experiments)] Abstract and experimental sections: the 1.33× and 1.60× compute advantages are derived from scaling-law fits on compute-matched runs, yet the manuscript does not state that total parameter counts were equalized. Dynamic filter generation requires additional linear projections (described in the method section) that are absent from the static-convolution controls; without explicit parameter-budget matching or a capacity-controlled ablation, the scaling claims rest on an uncontrolled variable.
Authors: We agree that parameter counts should be explicitly reported and controlled for a fair comparison. Our primary matching was on compute (FLOPs per token), as is common in scaling law studies, but the additional projections for dynamic filters do increase parameter count. In the revision, we will report exact parameter counts for all variants, and add an ablation study where we increase the width of the static baseline to match parameter count. This will clarify whether the gains are due to the dynamic mechanism or capacity. revision: yes
-
Referee: [§4 and §5] Experimental results: no error bars, standard deviations across seeds, or statistical significance tests are reported for any accuracy or loss numbers. This absence makes the “consistent outperformance” statements difficult to evaluate and weakens the foundation for the scaling-law conclusions.
Authors: We acknowledge the importance of reporting statistical variability. In the revised manuscript, we will include error bars based on multiple random seeds for the main language modeling results at each scale. For the scaling law fits, we will note the confidence intervals from the fitting process. We will also perform significance tests where appropriate. Due to the high computational cost, this will be limited to representative experiments rather than all ablations. revision: yes
Circularity Check
No circularity; empirical results and scaling fits are self-contained
full rationale
The paper reports direct experimental comparisons on associative recall and language modeling tasks (150M–2B parameters), plus scaling-law fits that quantify observed compute advantages (1.33× and 1.60×). No derivation chain, first-principles result, or prediction is claimed that reduces by construction to its own inputs. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the abstract or described content. The work is standard empirical architecture search with external benchmarks; the central claims remain independent of any internal redefinition or self-referential justification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
HyperNetworks , author =. International Conference on Learning Representations , year =
-
[2]
Advances in Neural Information Processing Systems , volume=
Jet-nemotron: Efficient language model with post neural architecture search , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
arXiv preprint arXiv:2106.04263 , year=
On the connection between local attention and dynamic depth-wise convolution , author=. arXiv preprint arXiv:2106.04263 , year=
-
[4]
arXiv preprint arXiv:2209.07947 , year=
Omni-dimensional dynamic convolution , author=. arXiv preprint arXiv:2209.07947 , year=
-
[5]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Xception: Deep learning with depthwise separable convolutions , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[6]
Proceedings of COLM , year=
RULER: What's the real context size of your long-context language models? , author=. Proceedings of COLM , year=
-
[7]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Mobilenets: Efficient convolutional neural networks for mobile vision applications , author=. arXiv preprint arXiv:1704.04861 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Convolutions and self-attention: Re-interpreting relative positions in pre-trained language models , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[9]
Proceedings of ICLR , year=
Mamba-3: Improved sequence modeling using state space principles , author=. Proceedings of ICLR , year=
-
[10]
2026 , publisher=
Raven: High-Recall Sequence Modeling with Sparse Memory Routing , author=. 2026 , publisher=
2026
-
[11]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Decoupled dynamic filter networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[12]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Selective kernel networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
Advances in Neural Information Processing Systems , volume =
Dynamic Filter Networks , author =. Advances in Neural Information Processing Systems , volume =
-
[14]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling , author =. arXiv preprint arXiv:1803.01271 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Advances in Neural Information Processing Systems , year =
CondConv: Conditionally Parameterized Convolutions for Efficient Inference , author =. Advances in Neural Information Processing Systems , year =
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Dynamic Convolution: Attention over Convolution Kernels , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[17]
International Conference on Learning Representations , year =
Pay Less Attention with Lightweight and Dynamic Convolutions , author =. International Conference on Learning Representations , year =
-
[18]
2016 , eprint=
Pointer Sentinel Mixture Models , author=. 2016 , eprint=
2016
-
[19]
Advances in Neural Information Processing Systems , year =
ConvBERT: Improving BERT with Span-based Dynamic Convolution , author =. Advances in Neural Information Processing Systems , year =
-
[20]
Interspeech , year =
Conformer: Convolution-augmented Transformer for Speech Recognition , author =. Interspeech , year =
-
[21]
International Conference on Learning Representations , year =
Lite Transformer with Long-Short Range Attention , author =. International Conference on Learning Representations , year =
-
[22]
Transformers are
Dao, Tri and Gu, Albert , booktitle =. Transformers are. 2024 , volume =
2024
-
[23]
Advances in Neural Information Processing Systems , volume =
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author =. Advances in Neural Information Processing Systems , volume =
-
[24]
International Conference on Learning Representations , year =
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author =. International Conference on Learning Representations , year =
-
[25]
2019 , eprint=
Decoupled Weight Decay Regularization , author=. 2019 , eprint=
2019
-
[26]
NAACL , year =
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions , author =. NAACL , year =
-
[27]
Nemotron- CC : Transforming C ommon C rawl into a Refined Long-Horizon Pretraining Dataset
Su, Dan and Kong, Kezhi and Lin, Ying and Jennings, Joseph and Norick, Brandon and Kliegl, Markus and Patwary, Mostofa and Shoeybi, Mohammad and Catanzaro, Bryan. Nemotron- CC : Transforming C ommon C rawl into a Refined Long-Horizon Pretraining Dataset. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Lon...
-
[28]
2024 , url =
LM Engine: A Hyper-Optimized Library for Pretraining and Finetuning , author =. 2024 , url =
2024
-
[29]
Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages =
PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation , author =. Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages =. 2024 , publisher =
2024
-
[30]
arXiv preprint arXiv:2512.17351 , year=
Physics of Language Models: Part 4.1, Architecture design and the magic of Canon layers , author=. arXiv preprint arXiv:2512.17351 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Primer: Searching for Efficient Transformers for Language Modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
On the Origin of Algorithmic Progress in
On the Origin of Algorithmic Progress in AI , author=. arXiv preprint arXiv:2511.21622 , year=
-
[33]
International conference on machine learning , pages=
Language modeling with gated convolutional networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[34]
International Conference on Machine Learning , pages=
Hyena hierarchy: Towards larger convolutional language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[35]
Journal of Machine Learning Research , year =
Natural Language Processing (Almost) from Scratch , author =. Journal of Machine Learning Research , year =
-
[36]
Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) , pages=
Convolutional neural networks for sentence classification , author=. Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) , pages=
2014
-
[37]
Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
A convolutional neural network for modelling sentences , author=. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[38]
Proceedings of the 25th international conference on Machine learning , pages=
A unified architecture for natural language processing: Deep neural networks with multitask learning , author=. Proceedings of the 25th international conference on Machine learning , pages=
-
[39]
International conference on machine learning , pages=
Convolutional sequence to sequence learning , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[40]
Neural Machine Translation in Linear Time
Neural machine translation in linear time , author=. arXiv preprint arXiv:1610.10099 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Proceedings of the 37th International Conference on Machine Learning , series =
Xiong, Ruibin and Yang, Yunchang and He, Di and Zheng, Kai and Zheng, Shuxin and Xing, Chen and Zhang, Huishuai and Lan, Yanyan and Wang, Liwei and Liu, Tie-Yan , title =. Proceedings of the 37th International Conference on Machine Learning , series =
-
[42]
Advances in Neural Information Processing Systems 32 , year =
Zhang, Biao and Sennrich, Rico , title =. Advances in Neural Information Processing Systems 32 , year =
-
[43]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Su, Jianlin and Lu, Yu and Pan, Shengfeng and Wen, Bo and Liu, Yunfeng , title =. arXiv preprint arXiv:2104.09864 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Fast Transformer Decoding: One Write-Head is All You Need
Shazeer, Noam , title =. arXiv preprint arXiv:1911.02150 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[45]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints , booktitle =
Ainslie, Joshua and Lee-Thorp, James and de Jong, Michiel and Zemlyanskiy, Yury and Lebr. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints , booktitle =
-
[46]
Journal of Machine Learning Research , year =
Fedus, William and Zoph, Barret and Shazeer, Noam , title =. Journal of Machine Learning Research , year =
-
[47]
GLU Variants Improve Transformer
Shazeer, Noam , title =. arXiv preprint arXiv:2002.05202 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[48]
Proceedings of the 32nd International Conference on Machine Learning , series =
Ioffe, Sergey and Szegedy, Christian , title =. Proceedings of the 32nd International Conference on Machine Learning , series =. 2015 , publisher =
2015
-
[49]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[50]
Ba, Jimmy Lei and Kiros, Jamie Ryan and Hinton, Geoffrey E. , title =. arXiv preprint arXiv:1607.06450 , year =. 1607.06450 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
and Hinton, Geoffrey E
Rumelhart, David E. and Hinton, Geoffrey E. and Williams, Ronald J. , title =. Nature , volume =. 1986 , doi =
1986
-
[52]
Psychological Review , volume =
Rosenblatt, Frank , title =. Psychological Review , volume =. 1958 , doi =
1958
-
[53]
Biological Cybernetics , volume =
Fukushima, Kunihiko , title =. Biological Cybernetics , volume =. 1980 , doi =
1980
-
[54]
Gradient-Based Learning Applied to Document Recognition , journal =
LeCun, Yann and Bottou, L. Gradient-Based Learning Applied to Document Recognition , journal =. 1998 , doi =
1998
-
[55]
, title =
Elman, Jeffrey L. , title =. Cognitive Science , volume =. 1990 , doi =
1990
-
[56]
Learning Phrase Representations using
Cho, Kyunghyun and van Merri. Learning Phrase Representations using. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (
2014
-
[57]
arXiv preprint arXiv:2403.17844 , year=
Mechanistic design and scaling of hybrid architectures , author=. arXiv preprint arXiv:2403.17844 , year=
-
[58]
Training Compute-Optimal Large Language Models
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Long Short-Term Memory , journal =
Hochreiter, Sepp and Schmidhuber, J. Long Short-Term Memory , journal =. 1997 , doi =
1997
-
[60]
Neural Machine Translation by Jointly Learning to Align and Translate
Bahdanau, Dzmitry and Cho, Kyunghyun and Bengio, Yoshua , title =. arXiv preprint arXiv:1409.0473 , year =. 1409.0473 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention Is All You Need , booktitle =
-
[62]
Quintana-Ort
Thierry Joffrain and Tze Meng Low and Enrique S. Quintana-Ort. Accumulating Householder transformations, revisited , url =. ACM Trans. Math. Softw. , pages =
-
[63]
Proceedings of ICLR , year=
Efficiently modeling long sequences with structured state spaces , author=. Proceedings of ICLR , year=
-
[64]
Proceedings of ICML , year=
The illusion of state in state-space models , author=. Proceedings of ICML , year=
-
[65]
arXiv preprint arXiv:2503.14456 (2025)
Rwkv-7" goose" with expressive dynamic state evolution , author=. arXiv preprint arXiv:2503.14456 , year=
-
[66]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Reparameterized Multi-Resolution Convolutions for Long Sequence Modelling , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[67]
2023 , eprint=
Sequence Modeling with Multiresolution Convolutional Memory , author=. 2023 , eprint=
2023
-
[68]
and Loan, Charles Van , booktitle =
Bischof, Christian H. and Loan, Charles Van , booktitle =. The
-
[69]
Using fast weights to deblur old memories , year =
Hinton, Geoffrey E and Plaut, David C , booktitle =. Using fast weights to deblur old memories , year =
-
[70]
Learning to control fast-weight memories: An alternative to dynamic recurrent networks , volume =
Schmidhuber, J. Learning to control fast-weight memories: An alternative to dynamic recurrent networks , volume =. Neural Computation , number =
-
[71]
arXiv preprint arXiv:2311.01927 , year=
Gateloop: Fully data-controlled linear recurrence for sequence modeling , author=. arXiv preprint arXiv:2311.01927 , year=
-
[72]
arXiv preprint arXiv:2310.01655 , year=
PolySketchFormer: Fast transformers via sketching polynomial kernels , author=. arXiv preprint arXiv:2310.01655 , year=
-
[73]
Symmetric
Buckman, Jacob and Gelada, Carles and Zhang, Sean , publisher =. Symmetric
-
[74]
1990 , publisher=
Prefix sums and their applications , author=. 1990 , publisher=
1990
-
[75]
Proceedings of ICLR , year=
Toeplitz neural network for sequence modeling , author=. Proceedings of ICLR , year=
-
[76]
arXiv preprint arXiv:2503.14376 , year=
Tiled Flash Linear Attention: More Efficient Linear RNN and xLSTM Kernels , author=. arXiv preprint arXiv:2503.14376 , year=
-
[77]
Rapid solution of integral equations of classical potential theory , journal =
V Rokhlin , abstract =. Rapid solution of integral equations of classical potential theory , journal =. 1985 , issn =. doi:https://doi.org/10.1016/0021-9991(85)90002-6 , url =
-
[78]
IEEE Trans
A fast on-line adaptive code , author=. IEEE Trans. Inf. Theory , year=
-
[79]
Proceedings of ICML , year=
Simple linear attention language models balance the recall-throughput tradeoff , author=. Proceedings of ICML , year=
-
[80]
Software: Practice and Experience , year=
A new data structure for cumulative frequency tables , author=. Software: Practice and Experience , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.