Unified Video-Action Joint Denoising for Dexterous Action and Data Generation
Pith reviewed 2026-06-28 10:26 UTC · model grok-4.3
The pith
A unified denoising model samples future videos and bimanual hand trajectories under language, image, or text conditioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
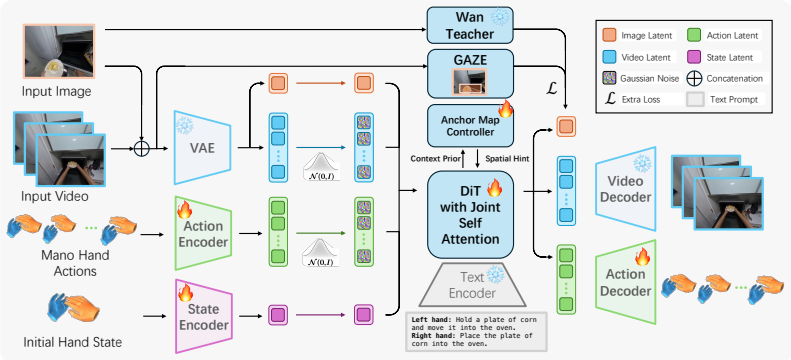
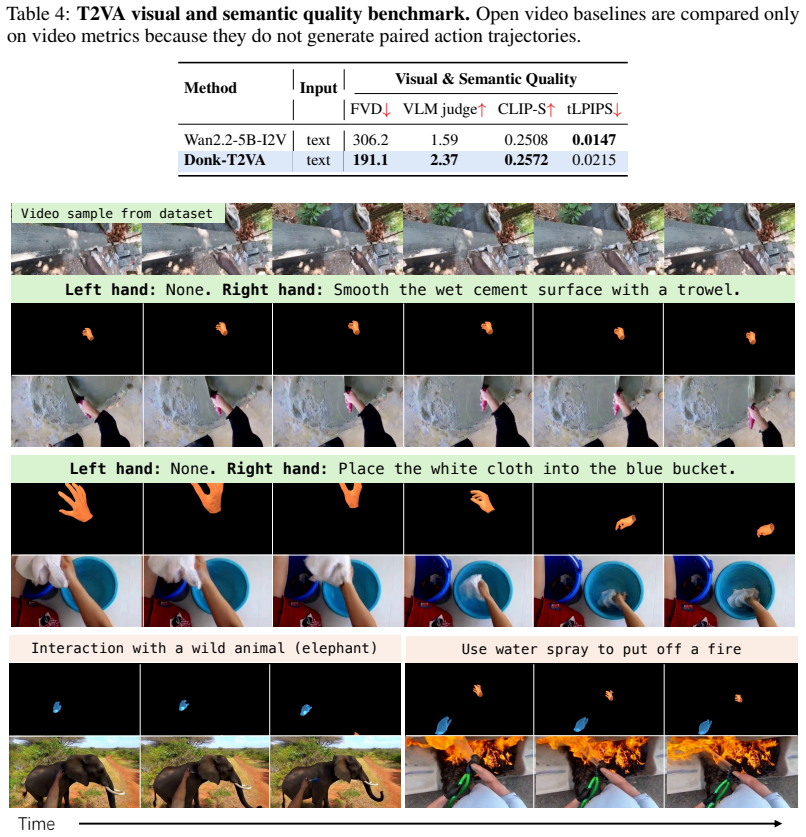
Donk is a unified video-action denoising model for dexterous hands that, with language, an initial image, and initial hand state, samples future videos and bimanual MANO trajectories as an action policy; without the image condition, the same architecture samples paired video-action rollouts from a text-conditioned distribution, and across action, video, and text-only evaluations it improves dexterous trajectory accuracy while preserving video fidelity under a single training recipe.
What carries the argument
The joint video-action denoising architecture that models the shared distribution of interaction videos and executable hand trajectories under varying conditioning regimes.
If this is right
- The model improves dexterous trajectory accuracy relative to baselines while keeping video fidelity strong.
- The same architecture produces smooth text-conditioned action rollouts without image input.
- Removing the image condition converts the aligned video prior into a generator of paired video-action training data.
- A single training recipe supports both policy use and data generation use cases.
Where Pith is reading between the lines
- The joint modeling approach could scale to generate large volumes of synthetic dexterous interaction data for downstream training.
- Similar unified architectures might apply to other robot embodiments or multi-agent settings where video and action data need alignment.
- Iterative loops become possible in which the model generates new data that is then used to further refine the same model.
- Broader distributional modeling may reduce the need for task-specific fine-tuning when transferring video priors to control.
Load-bearing premise
Modeling the joint distribution of interaction videos and executable hand trajectories under multiple conditioning regimes yields better alignment and performance than narrowing the video prior to an observation-conditioned policy distribution over future actions.
What would settle it
Separate models trained only as policies or only as data generators achieve higher dexterous trajectory accuracy or video fidelity than the unified model on the same evaluation sets.
Figures



read the original abstract
Recent world action models leverage video foundation models by aligning broad visual-dynamics priors with executable robot actions. We revisit this alignment from a distributional perspective. Existing formulations typically narrow the aligned prior into an observation-conditioned policy distribution over future actions. In contrast, we keep the distribution broader by modeling the joint space of interaction videos and executable hand trajectories under multiple conditioning regimes. We propose Donk, a unified video-action denoising model for dexterous hands. With language, an initial image, and the initial hand state, Donk samples future videos and bimanual MANO trajectories as an action policy. Without the image condition, the same denoising architecture samples paired video-action rollouts from a text-conditioned distribution, turning the aligned video prior into a data engine. Across action, video, and text-only generation evaluations, Donk improves dexterous trajectory accuracy, preserves strong video fidelity, and produces smooth text-conditioned action rollouts under the same unified training recipe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Donk, a unified video-action denoising model that models the joint distribution of interaction videos and executable hand trajectories under multiple conditioning regimes. It functions as an action policy when conditioned on language, initial image, and hand state to sample future videos and bimanual MANO trajectories, and as a data engine when the image condition is removed to sample paired video-action rollouts from a text-conditioned distribution. The paper claims that this approach improves dexterous trajectory accuracy, preserves video fidelity, and produces smooth text-conditioned action rollouts using the same unified training recipe.
Significance. If the empirical results hold, this work would be significant for the field of robot learning and video generation models by demonstrating that maintaining a broader joint distribution rather than narrowing to an observation-conditioned policy can yield better alignment, dual functionality for policy and data generation, and improved performance in dexterous tasks without sacrificing video quality.
major comments (1)
- [Abstract] Abstract: The abstract states performance improvements but supplies no quantitative results, baselines, error bars, or architectural details, so the central claim cannot be evaluated from the given information.
Simulated Author's Rebuttal
We thank the referee for their feedback. We address the concern regarding the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states performance improvements but supplies no quantitative results, baselines, error bars, or architectural details, so the central claim cannot be evaluated from the given information.
Authors: We agree that the abstract provides only qualitative statements of improvement without specific numbers or details. Abstracts are length-constrained and typically emphasize the high-level contribution and approach, with quantitative results, baselines, error bars, and architectural specifics reserved for the main body (Sections 4-5 and Tables 1-3). To improve evaluability of the central claims directly from the abstract, we will revise it to incorporate a small number of key quantitative highlights from the experiments while respecting length limits. revision: yes
Circularity Check
No significant circularity
full rationale
The provided manuscript text contains no derivation chain, equations, or first-principles claims. The paper describes an empirical architecture (unified video-action denoising) trained under multiple conditioning regimes and evaluated on downstream tasks. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear. The central claim rests on experimental results rather than deductive reduction to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yun- liang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. pi0: A vis...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Dexvla: Vision-language model with plug-in diffusion expert for general robot control
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control. InProceedings of The 9th Conference on Robot Learning, 2025
2025
-
[5]
Dexgraspvla: A vision-language-action framework towards general dexterous grasping
Yifan Zhong, Xuchuan Huang, Ruochong Li, Ceyao Zhang, Zhang Chen, Tianrui Guan, Fanlian Zeng, Ka Nam Lui, Yuyao Ye, Yitao Liang, et al. Dexgraspvla: A vision-language-action framework towards general dexterous grasping. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18836–18844, 2026
2026
-
[6]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. arXiv preprint arXiv:2303.04137, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Unified Video Action Model
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified Video Action Model. In Proceedings of Robotics: Science and Systems, Los Angeles, CA, USA, June 2025
2025
-
[9]
World action models are zero-shot policies, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
2026
-
[10]
Motus: A unified latent action world model, 2025
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, Hongyan Zhao, Hanyu Liu, Zhizhong Su, Lei Ma, Hang Su, and Jun Zhu. Motus: A unified latent action world model, 2025
2025
-
[11]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Wan: Open and Advanced Large-Scale Video Generative Models
WanTeam, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[14]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnik...
2023
-
[16]
pi0.5: a vision- language-action model with open-world generalization
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y Galliker, et al. pi0.5: a vision- language-action model with open-world generalization. In9th Annual Conference on Robot Learning, 2025
2025
-
[17]
pi0.7: a steerable generalist robotic foundation model with emergent capabilities, 2026
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, Vedant Choudhary, Foster Collins, Ken Conley, Grace Connors, James Darpinian, et al. pi0.7: a steerable generalist robotic foundation model with emergent capabilities, 2026
2026
-
[18]
Mingfei Chen, Yifan Wang, Zhengqin Li, Homanga Bharadhwaj, Yujin Chen, Chuan Qin, Ziyi Kou, Yuan Tian, Eric Whitmire, Rajinder Sodhi, et al. Flowing from reasoning to motion: Learning 3d hand trajectory prediction from egocentric human interaction videos.arXiv preprint arXiv:2512.16907, 2025
-
[19]
Rdt-1b: a diffusion foundation model for bimanual manipulation, 2024
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation, 2024
2024
-
[20]
Gr00t n1: An open foundation model for generalist humanoid robots, 2025
NVIDIA, Johan Bjorck, Fernando Castaneda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang ...
2025
-
[21]
Fast: Efficient action tokenization for vision-language-action models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models. InRobotics: Science and Systems, 2025
2025
-
[22]
Hao Luo, Ye Wang, Wanpeng Zhang, Sipeng Zheng, Ziheng Xi, Chaoyi Xu, Haiweng Xu, Haoqi Yuan, Chi Zhang, Yiqing Wang, Yicheng Feng, and Zongqing Lu. Being-h0.5: Scaling human- centric robot learning for cross-embodiment generalization.arXiv preprint arXiv:2601.12993, 2026
-
[23]
Dexhil: A human-in-the-loop framework for vision-language-action model post-training in dexterous manipulation, 2026
Yifan Han, Zhongxi Chen, Yuxuan Zhao, Congsheng Xu, Yanming Shao, Yichuan Peng, Yao Mu, and Wenzhao Lian. Dexhil: A human-in-the-loop framework for vision-language-action model post-training in dexterous manipulation, 2026
2026
-
[24]
Vlas with long and short-term memory.https://www.pi.website/research/memory, 2026
Marcel Torne, Karl Pertsch, Homer Walke, Kyle Vedder, Suraj Nair, Brian Ichter, Allen Ren, Haohuan Wang, Jiaming Tang, Kyle Stachowicz, Karan Dhabalia, Michael Equi, Quan Vuong, Jost Tobias Springenberg, Sergey Levine, Chelsea Finn, and Danny Driess. Vlas with long and short-term memory.https://www.pi.website/research/memory, 2026
2026
-
[25]
World models, 2018
David Ha and Jürgen Schmidhuber. World models, 2018
2018
-
[26]
Tenenbaum, Dale Schuurmans, and Pieter Abbeel
Yilun Du, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[27]
arXiv preprint arXiv:2310.10625 , year=
Yilun Du, Mengjiao Yang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Sermanet, Tianhe Yu, Pieter Abbeel, Joshua B. Tenenbaum, Leslie Pack Kaelbling, Andy Zeng, and Jonathan Tompson. Video language planning.arXiv preprint arXiv:2310.10625, 2023. 11
-
[28]
Ro- bodreamer: Learning compositional world models for robot imagination
Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, and Chuang Gan. Ro- bodreamer: Learning compositional world models for robot imagination. InInternational Conference on Machine Learning, 2024
2024
-
[29]
Genie: Generative interactive environments
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder Si...
2024
-
[30]
Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doer- sch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation.arXiv preprint arXiv:2409.16283, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Dreamitate: Real-world visuomotor policy learning via video generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, and Carl V ondrick. Dreamitate: Real-world visuomotor policy learning via video generation. InProceedings of The 8th Conference on Robot Learning, 2024
2024
-
[32]
Video Generators are Robot Policies
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, and Carl V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Qixiu Li, Yu Deng, Yaobo Liang, Lin Luo, Lei Zhou, Chengtang Yao, Lingqi Zeng, Zhiyuan Feng, Huizhi Liang, Sicheng Xu, Yizhong Zhang, Xi Chen, Hao Chen, Lily Sun, Dong Chen, Jiaolong Yang, and Baining Guo. Scalable vision-language-action model pretraining for robotic manipulation with real-life human activity videos.arXiv preprint arXiv:2510.21571, 2025
-
[34]
arXiv preprint arXiv:2507.15597 , year=
Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, and Zongqing Lu. Being-h0: Vision-language-action pretraining from large-scale human videos.arXiv preprint arXiv:2507.15597, 2025
-
[35]
Spatial-aware vla pretraining through visual-physical alignment from human videos, 2025
Yicheng Feng, Wanpeng Zhang, Ye Wang, Hao Luo, Haoqi Yuan, Sipeng Zheng, and Zongqing Lu. Spatial-aware vla pretraining through visual-physical alignment from human videos, 2025
2025
-
[36]
Yoon, Mouli Sivapurapu, and Jian Zhang
Ryan Hoque, Peide Huang, David J. Yoon, Mouli Sivapurapu, and Jian Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video, 2025
2025
-
[37]
Raktim Gautam Goswami, Amir Bar, David Fan, Tsung-Yen Yang, Gaoyue Zhou, Prashanth Krishnamurthy, Michael Rabbat, Farshad Khorrami, and Yann LeCun. World models can leverage human videos for dexterous manipulation.arXiv preprint arXiv:2512.13644, 2025
-
[38]
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, Qianli Ma, Seungjun Nah, Loic Magne, Jiannan Xiang, Yuqi Xie, Ruijie Zheng, Dantong Niu, You Liang Tan, K.R. Zentner, George Kurian, Suneel Indupuru, Pooya Jannaty, Jinwei Gu, Jun Zhang, Jitendra Malik, Pieter Abbeel,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Latent action pretraining from videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, Lars Liden, Kimin Lee, Jianfeng Gao, Luke Zettlemoyer, Dieter Fox, and Minjoon Seo. Latent action pretraining from videos. In International Conference on Learning Representations, 2025
2025
-
[40]
Adaworld: Learning adaptable world models with latent actions
Shenyuan Gao, Siyuan Zhou, Yilun Du, Jun Zhang, and Chuang Gan. Adaworld: Learning adaptable world models with latent actions. InInternational Conference on Machine Learning, 2025
2025
-
[41]
Joint-aligned latent action: Towards scalable vla pretraining in the wild, 2026
Hao Luo, Ye Wang, Wanpeng Zhang, Haoqi Yuan, Yicheng Feng, Haiweng Xu, Sipeng Zheng, and Zongqing Lu. Joint-aligned latent action: Towards scalable vla pretraining in the wild, 2026. 12
2026
-
[42]
Worldvla: Towards autoregressive action world model, 2025
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, Deli Zhao, and Hao Chen. Worldvla: Towards autoregressive action world model, 2025
2025
-
[43]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control. arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
mimic-video: Video-action models for generalizable robot control beyond vlas, 2025
Jonas Pai, Liam Achenbach, Victoriano Montesinos, Benedek Forrai, Oier Mees, and Elvis Nava. mimic-video: Video-action models for generalizable robot control beyond vlas, 2025
2025
-
[45]
Teli Ma, Jia Zheng, Zifan Wang, Chunli Jiang, Andy Cui, Junwei Liang, and Shuo Yang. Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control.arXiv preprint arXiv:2603.10448, 2026
-
[46]
Gigaworld-policy: An efficient action-centered world–action model, 2026
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, Min Cao, Peng Li, Qiuping Deng, Wenjun Mei, Xiaofeng Wang, Xinze Chen, Xinyu Zhou, Yang Wang, Yifan Chang, Yifan Li, Yukun Zhou, Yun Ye, Zhichao Liu, and Zheng Zhu. Gigaworld-policy: An efficient action-centered world–action model, 2026
2026
-
[47]
Being-h0.7: A latent world-action model from egocentric videos
BeingBeyond Team. Being-h0.7: A latent world-action model from egocentric videos. https: //research.beingbeyond.com/being-h07, 2026
2026
-
[48]
V-jepa 2: Self-supervised video models enable understanding, prediction and planning, 2025
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning, 2025
2025
-
[49]
Vla-jepa: Enhancing vision-language-action model with latent world model, 2026
Jingwen Sun, Wenyao Zhang, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, and Zhibo Chen. Vla-jepa: Enhancing vision-language-action model with latent world model, 2026
2026
-
[50]
Flare: Robot learning with implicit world modeling, 2025
Ruijie Zheng, Jing Wang, Scott Reed, Johan Bjorck, Yu Fang, Fengyuan Hu, Joel Jang, Kaushil Kundalia, Zongyu Lin, Loic Magne, Avnish Narayan, You Liang Tan, Guanzhi Wang, Qi Wang, Jiannan Xiang, Yinzhen Xu, Seonghyeon Ye, Jan Kautz, Furong Huang, Yuke Zhu, and Linxi Fan. Flare: Robot learning with implicit world modeling, 2025
2025
-
[51]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Oakink2: A dataset of bimanual hands-object manipulation in complex task completion
Xinyu Zhan, Lixin Yang, Yifei Zhao, Kangrui Mao, Hanlin Xu, Zenan Lin, Kailin Li, and Cewu Lu. Oakink2: A dataset of bimanual hands-object manipulation in complex task completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 445–456, 2024
2024
-
[53]
Lome: Learning human- object manipulation with action-conditioned egocentric world model, 2026
Quankai Gao, Jiawei Yang, Le Chen, Qiangeng Xu, and Yue Wang. Lome: Learning human- object manipulation with action-conditioned egocentric world model, 2026. 13
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.