Privacy-Robust Incrementality Measurement for Advertising Systems under Signal Loss
Pith reviewed 2026-06-28 07:55 UTC · model grok-4.3
The pith
Privacy-induced signal losses create a sharp decision frontier separating certifiable from unresolvable incrementality claims in advertising experiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
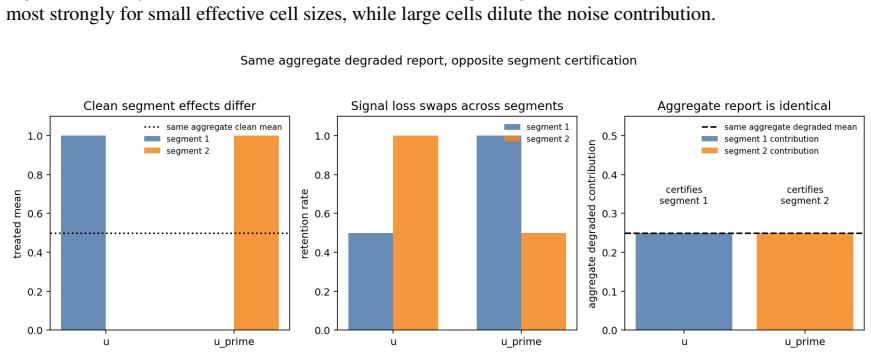
Given a randomized experiment and an ambiguity set for privacy-induced degradation, the framework projects the observation-compatible fiber of clean experimental worlds onto the incrementality functional and returns certified, rejected, and unresolved decisions. The main result gives a sharp decision frontier. Reports outside the frontier support uniformly valid certification or rejection, whereas reports inside it contain too little information for any method to uniformly distinguish above-threshold incrementality from non-incrementality.
What carries the argument
The decision frontier obtained by projecting the observation-compatible fiber onto the incrementality functional under the ambiguity set for privacy-induced signal losses.
If this is right
- Finite-sample procedures exist that certify or reject incrementality for reports outside the frontier.
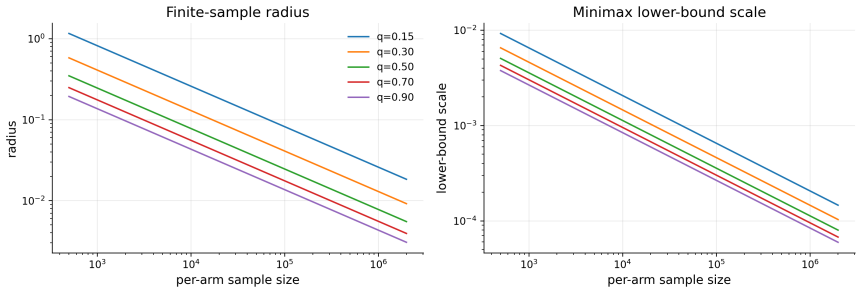
- Sample-complexity bounds quantify the data volume required to reach a decision outside the frontier.
- A minimax lower bound establishes that greater signal loss strictly reduces the information available for any inference method.
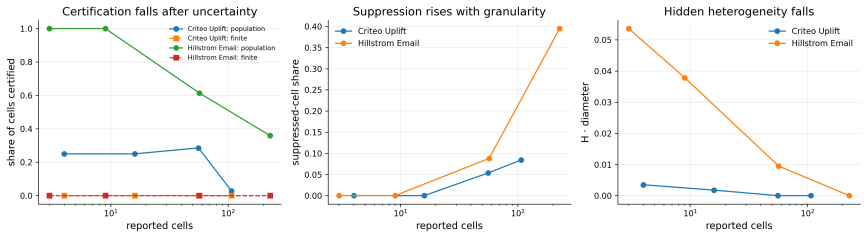
- A reporting-granularity tradeoff shows how coarser privacy-preserving reports increase the measure of the unresolved region.
Where Pith is reading between the lines
- Platforms could compute the frontier on incoming reports to decide whether to accept the result or request less-degraded data at added privacy cost.
- The same projection technique might apply to other causal settings where privacy or missingness creates an ambiguity set around observed outcomes.
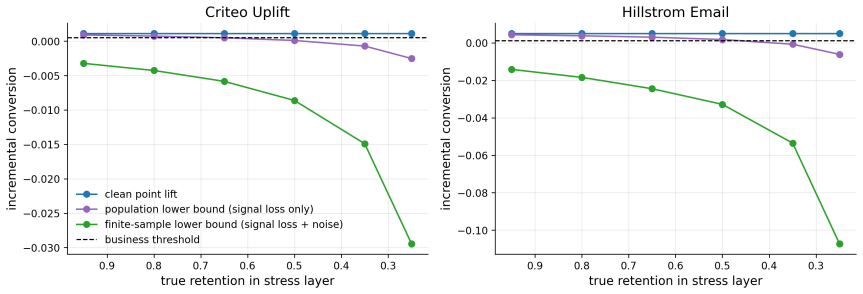
- Empirical checks on large uplift datasets indicate that mild degradation often leaves population-level claims certifiable while combined noise and uncertainty push most finite-sample cases into the unresolved region.
Load-bearing premise
The chosen ambiguity set correctly contains every clean experimental world that could have produced the observed degraded report.
What would settle it
A statistical procedure that, for some report inside the computed frontier, produces a uniformly valid certification or rejection across every world in the ambiguity set would falsify the claimed sharpness.
Figures



read the original abstract
Advertising platforms use randomized lift tests to measure incrementality, but privacy-preserving reporting systems degrade the observed signal through match-rate loss, linkability loss, attribution-window loss, aggregation-threshold suppression, randomized reporting noise, and segment-heterogeneous signal loss. This paper formulates privacy-constrained advertising measurement as a robust causal decision problem under the mentioned signal losses. Given a randomized experiment and an ambiguity set for privacy-induced degradation, the framework projects the observation-compatible fiber of clean/unfiltered experimental worlds onto the incrementality functional and returns certified, rejected, and unresolved decisions. The main result gives a sharp decision frontier. Reports outside the frontier support uniformly valid certification or rejection, whereas reports inside it contain too little information for any method to uniformly distinguish above-threshold incrementality from non-incrementality. Supporting results give finite-sample certification, sample-complexity guarantees, a minimax lower bound showing that signal loss reduces effective information, and a reporting-granularity tradeoff. On 2.0M Criteo Uplift rows and the 64K-row Hillstrom email experiment, clean conversion lift is positive in both datasets, with lifts 0.00112 and 0.00495, respectively. Population certification survives mild degradation in Criteo and severe degradation in Hillstrom, while all considered finite-sample stress settings in both datasets remain unresolved after simultaneous uncertainty and reporting noise are included. Overall, the research contributes a decision-theoretic layer for privacy-aware incrementality measurement whose output is the strongest causal-claim justified by degraded ads signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates privacy-constrained advertising measurement as a robust causal decision problem under signal losses including match-rate loss, linkability loss, attribution-window loss, aggregation-threshold suppression, randomized reporting noise, and segment-heterogeneous signal loss. Given a randomized experiment and an ambiguity set for privacy-induced degradation, the framework projects the observation-compatible fiber of clean experimental worlds onto the incrementality functional to produce certified, rejected, and unresolved decisions. The main result is a sharp decision frontier outside which uniformly valid certification or rejection is possible; inside the frontier no method can uniformly distinguish above-threshold incrementality from non-incrementality. Supporting results include finite-sample certification, sample-complexity guarantees, a minimax lower bound on information loss, and a reporting-granularity tradeoff. Empirical evaluation on the 2M-row Criteo Uplift and 64K-row Hillstrom datasets shows positive clean lift (0.00112 and 0.00495) with population certification surviving mild/severe degradation but all finite-sample stress settings remaining unresolved.
Significance. If the ambiguity-set construction and projection are valid, the work supplies a decision-theoretic layer that yields the strongest uniformly valid causal claims justifiable from degraded ad signals, together with an explicit minimax lower bound demonstrating that privacy mechanisms strictly reduce effective information. The finite-sample guarantees and real-dataset illustrations on Criteo and Hillstrom provide concrete evidence of applicability to production advertising measurement.
major comments (2)
- [§3 (ambiguity set definition) and Theorem 1 (sharp frontier)] The central sharpness claim (abstract and §4) requires that the ambiguity set exactly equals the set of all observation-compatible clean incrementality values under the listed degradations. Without an explicit construction of this set (or the joint distribution over heterogeneous segment losses, attribution-window truncation, and their interaction with aggregation-threshold suppression and randomized noise), it is impossible to verify that the projection yields a frontier whose minimax lower bound matches the upper bound obtained from the fiber projection.
- [§5 (finite-sample results) and Table 2/3 (empirical certification outcomes)] The finite-sample certification results (reported in the abstract and §5) are stated to survive mild degradation in Criteo and severe degradation in Hillstrom at the population level, yet all considered finite-sample stress settings remain unresolved once simultaneous uncertainty and reporting noise are included. The paper must clarify whether these unresolved outcomes follow from the information-theoretic bound or from post-hoc choices in the stress-test construction.
minor comments (2)
- [§2] Notation for the incrementality functional and the observation-compatible fiber should be introduced with a single running example before the general projection argument.
- [§4.3] The reporting-granularity tradeoff result would benefit from an explicit statement of the granularity parameter and how it enters the ambiguity set.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3 (ambiguity set definition) and Theorem 1 (sharp frontier)] The central sharpness claim (abstract and §4) requires that the ambiguity set exactly equals the set of all observation-compatible clean incrementality values under the listed degradations. Without an explicit construction of this set (or the joint distribution over heterogeneous segment losses, attribution-window truncation, and their interaction with aggregation-threshold suppression and randomized noise), it is impossible to verify that the projection yields a frontier whose minimax lower bound matches the upper bound obtained from the fiber projection.
Authors: The ambiguity set in §3 is defined as the image under the incrementality functional of the fiber of all clean experimental worlds that produce the observed degraded signals when each listed privacy mechanism is applied. The fiber is formed by inverting the channels (match-rate loss, linkability loss, attribution-window truncation, aggregation-threshold suppression, randomized reporting noise, and segment-heterogeneous loss) and taking the product measure over independent components, with the joint over heterogeneous segments obtained by marginalizing the segment-specific loss parameters. The projection then yields the sharp frontier, and the matching minimax lower bound is obtained by exhibiting pairs of incrementality values inside the frontier that induce identical degraded observations. To make verification immediate, the revised manuscript will include explicit pseudocode for constructing the joint distribution and the fiber in §3. revision: yes
-
Referee: [§5 (finite-sample results) and Table 2/3 (empirical certification outcomes)] The finite-sample certification results (reported in the abstract and §5) are stated to survive mild degradation in Criteo and severe degradation in Hillstrom at the population level, yet all considered finite-sample stress settings remain unresolved once simultaneous uncertainty and reporting noise are included. The paper must clarify whether these unresolved outcomes follow from the information-theoretic bound or from post-hoc choices in the stress-test construction.
Authors: The unresolved finite-sample outcomes follow directly from the information-theoretic bound of Theorem 1: after degradation the effective sample size lies below the sample-complexity threshold required to resolve the frontier. The stress-test parameters are taken verbatim from the population-level degradation settings; no additional post-hoc adjustments are introduced. The revised §5 will add an explicit comparison of each stress-test sample size against the derived lower bound to make this dependence transparent. revision: yes
Circularity Check
No significant circularity; derivation projects external ambiguity set onto incrementality functional without self-reduction.
full rationale
The paper defines an ambiguity set over listed privacy degradations (match-rate loss, linkability loss, etc.) and projects the observation-compatible fiber of clean experimental worlds onto the incrementality functional to obtain a sharp decision frontier. This is a standard robust decision-theoretic construction; the frontier is the output of the projection, not equivalent to its inputs by definition. No self-citation load-bearing steps, fitted inputs renamed as predictions, or ansatz smuggling appear in the provided text. The minimax lower bound and finite-sample results are presented as supporting derivations independent of the central projection. The framework remains self-contained against external benchmarks for the ambiguity set specification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An ambiguity set can be specified that contains every observation-compatible clean experimental world under the listed privacy losses.
Reference graph
Works this paper leans on
-
[1]
Attribution reporting: Full system overview
Google Privacy Sandbox. Attribution reporting: Full system overview. https://privacysandbox. google.com/private-advertising/attribution-reporting/system-overview , 2025a. Accessed 2026-05-27. Google Privacy Sandbox. Private aggregation api fundamentals. https://privacysandbox.google. com/private-advertising/private-aggregation/fundamentals, 2025b. Accesse...
2026
-
[2]
Varadarajan
Hidayet Aksu, Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Adam Sealfon, and Avinash V . Varadarajan. Summary reports optimization in the privacy sandbox attribution reporting api.Proceedings on Privacy Enhancing Technologies, 2024(4):605–621,
2024
-
[3]
doi: 10.56553/popets-2024-0132. Pierre Tholoniat, Kelly Kostopoulou, Peter McNeely, Prabhpreet Singh Sodhi, Anirudh Varanasi, Benjamin Case, Asaf Cidon, Roxana Geambasu, and Mathias Lécuyer. Cookie monster: Efficient on-device budgeting for differentially-private ad-measurement systems. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems P...
-
[4]
1Corresponding author:shekharp@erau.edu 15 Pierre Gutierrez and Jean-Yves Gérardy
doi: 10.1145/3694715.3695965. 1Corresponding author:shekharp@erau.edu 15 Pierre Gutierrez and Jean-Yves Gérardy. Causal inference and uplift modelling: A review of the literature. InProceedings of The 3rd International Conference on Predictive Applications and APIs, volume 67 of Proceedings of Machine Learning Research, pages 1–13. PMLR,
-
[5]
Krzysztof Ruda´s and Szymon Jaroszewicz
doi: 10.1007/s10618-014-0383-9. Krzysztof Ruda´s and Szymon Jaroszewicz. Linear regression for uplift modeling.Data Mining and Knowledge Discovery, 32(5):1275–1305,
-
[6]
Diego Olaya, Kristof Coussement, and Wouter Verbeke
doi: 10.1007/s10618-018-0576-8. Diego Olaya, Kristof Coussement, and Wouter Verbeke. A survey and benchmarking study of mul- titreatment uplift modeling.Data Mining and Knowledge Discovery, 34(2):273–308,
-
[7]
Eustache Diemert, Artem Betlei, Christophe Renaudin, and Massih-Reza Amini
doi: 10.1007/s10618-019-00670-y. Eustache Diemert, Artem Betlei, Christophe Renaudin, and Massih-Reza Amini. A large scale benchmark for uplift modeling. InProceedings of the AdKDD and TargetAd Workshop,
-
[8]
Eustache Diemert, Artem Betlei, Christophe Renaudin, Massih-Reza Amini, Théophane Gregoir, and Thibaud Rahier. A large scale benchmark for individual treatment effect prediction and uplift modeling.arXiv preprint arXiv:2111.10106,
-
[9]
Artem Betlei, Eustache Diemert, and Massih-Reza Amini. Treatment targeting by auuc maximization with generalization guarantees.arXiv preprint arXiv:2012.09897,
arXiv 2012
-
[10]
doi: 10.1287/mksc.2018.1135. Brett R. Gordon, Robert Moakler, and Florian Zettelmeyer. Close enough? a large-scale exploration of non-experimental approaches to advertising measurement.Marketing Science, 42(4):768–793,
-
[11]
doi: 10.1287/mksc.2022.1413. Garrett A. Johnson. Inferno: A guide to field experiments in online display advertising.Journal of Economics & Management Strategy, 32(3):469–490,
-
[12]
doi: 10.1509/jmr. 15.0297. Randall A. Lewis and Justin M. Rao. On the near impossibility of measuring the returns to advertising.The Quarterly Journal of Economics, 130(4):1941–1973,
work page doi:10.1509/jmr 1941
-
[13]
doi: 10.1093/qje/qjv023. Jon Vaver and Jim Koehler. Measuring ad effectiveness using geo experiments. Technical report, Google,
-
[14]
and Gallusser, Fabian and Koehler, Jim and Remy, Nicolas and Scott, Steven L
doi: 10.1214/14-AOAS788. Ron Berman and Elea McDonnell Feit. Latent stratification for incrementality experiments.Marketing Science, 43(4):903–917,
-
[15]
Prasad Chalasani, Ari Buchalter, Jaynth Thiagarajan, and Ezra Winston
doi: 10.1287/mksc.2022.0297. Prasad Chalasani, Ari Buchalter, Jaynth Thiagarajan, and Ezra Winston. Counterfactual-based incrementality measurement in a digital ad-buying platform.arXiv preprint arXiv:1705.00634,
-
[16]
Designing Experiments to Measure Incrementality on Facebook
doi: 10.1609/aaai.v29i1.9156. 1Corresponding author:shekharp@erau.edu 16 CH Liu, Elaine M Bettaney, and Benjamin Paul Chamberlain. Designing experiments to measure incrementality on facebook.arXiv preprint arXiv:1806.02588,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1609/aaai.v29i1.9156
-
[17]
Ruihuan Du, Yu Zhong, Harikesh Nair, Bo Cui, and Ruyang Shou. Causally driven incremental multi touch attribution using a recurrent neural network.arXiv preprint arXiv:1902.00215,
Pith/arXiv arXiv 1902
-
[18]
doi: 10.1007/978-3-540-79228-4_1. Cynthia Dwork and Aaron Roth. The algorithmic foundations of differential privacy.Foundations and Trends in Theoretical Computer Science, 9(3–4):211–407,
-
[19]
The algorithmic foundations of differential privacy.Found
doi: 10.1561/0400000042. John Delaney, Badih Ghazi, Charlie Harrison, Christina Ilvento, Ravi Kumar, Pasin Manurangsi, Martin Pál, Karthik Prabhakar, and Mariana Raykova. Differentially private ad conversion measurement.Proceedings on Privacy Enhancing Technologies, 2024(2):124–140,
-
[20]
doi: 10.56553/popets-2024-0044. Badih Ghazi, Charlie Harrison, Arpana Hosabettu, Pritish Kamath, Alexander Knop, Ravi Kumar, Mariana Raykova, Pasin Manurangsi, Ethan Leeman, Vikas Sahu, and Phillipp Schoppmann. On the differential privacy and interactivity of privacy sandbox reports.Proceedings on Privacy Enhancing Technologies, 2025 (3):382–397,
-
[21]
doi: 10.56553/popets-2025-0104. Meta Audience Network. Update: How to manage apple’s ios 14 live changes. https://en-gb.facebook.com/audiencenetwork/resources/blog/ update-how-to-manage-apple-ios-14-live-changes ,
-
[22]
Yingtai Xiao, Jian Du, Shikun Zhang, Wanrong Zhang, Qiang Yan, Danfeng Zhang, and Daniel Kifer
Discusses Meta’s Ag- gregated Event Measurement and Apple’s SKAdNetwork. Yingtai Xiao, Jian Du, Shikun Zhang, Wanrong Zhang, Qiang Yan, Danfeng Zhang, and Daniel Kifer. Click without compromise: Online advertising measurement via per user differential privacy. InProceedings of the 2025 IEEE Symposium on Security and Privacy, pages 2919–2937,
2025
-
[23]
doi: 10.1109/SP61157.2025. 00187. Ke Zhong, Yiping Ma, and Sebastian Angel. Ibex: Privacy-preserving ad conversion tracking and bidding. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 3223–3237,
-
[24]
doi: 10.1145/3548606.3560651. Conor O’Brien, Arvind Thiagarajan, Sourav Das, Rafael Barreto, Chetan Verma, Tim Hsu, James Neufield, and Jonathan J Hunt. Challenges and approaches to privacy preserving post-click conversion prediction. arXiv preprint arXiv:2201.12666,
-
[25]
doi: 10.1080/01621459.2000.10473902. Guido W. Imbens and Charles F. Manski. Confidence intervals for partially identified parameters.Econometrica, 72(6):1845–1857,
-
[26]
doi: 10.1111/j.1468-0262.2004.00555.x. Charles F. Manski and John V . Pepper. Monotone instrumental variables: With an application to the returns to schooling.Econometrica, 68(4):997–1010,
-
[27]
1Corresponding author:shekharp@erau.edu 17 Amy Richardson, Michael G
doi: 10.1111/1468-0262.00144. 1Corresponding author:shekharp@erau.edu 17 Amy Richardson, Michael G. Hudgens, Peter B. Gilbert, and Jason P. Fine. Nonparametric bounds and sensitivity analysis of treatment effects.Statistical Science, 29(4):596–618,
-
[28]
doi: 10.1214/14-STS499. Alexander Coppock, Alan S. Gerber, and Donald P. Green. Combining double sampling and bounds to address nonignorable missing outcomes in randomized experiments.Political Analysis, 25(2):188–206,
-
[29]
doi: 10.1017/pan.2016.6. Erin E. Gabriel, Arvid Sjölander, and Michael C. Sachs. Nonparametric bounds for causal effects in imperfect randomized experiments.Journal of the American Statistical Association, 118(541):684–692,
-
[30]
doi: 10.1080/01621459.2021.1950734. Anish Agarwal and Rahul Singh. Causal inference with corrupted data: Measurement error, missing values, discretization, and differential privacy.arXiv preprint arXiv:2107.02780,
-
[31]
Prashant Shekhar and Caroline Howard. Choosing online experiment designs under interference in ads, recommendations, and member-experience systems.arXiv preprint arXiv:2605.25290, 2026a. Prashant Shekhar and Caroline Howard. Support-aware offline policy selection for advertising marketplaces. arXiv preprint arXiv:2605.21736, 2026b. Criteo AI Lab. Criteo u...
-
[32]
Minethatdata e-mail analytics and data mining challenge dataset
Kevin Hillstrom. Minethatdata e-mail analytics and data mining challenge dataset. https://blog. minethatdata.com/2008/03/minethatdata-e-mail-analytics-and-data.html ,
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.