Reasoning Structure of Large Language Models
Pith reviewed 2026-06-28 10:04 UTC · model grok-4.3
The pith
Reasoning traces from large language models can be turned into graphs of claims and dependencies whose structure distinguishes behaviors that accuracy and token counts cannot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
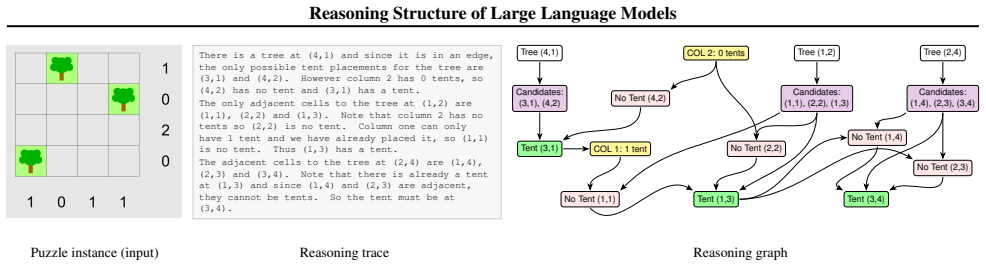
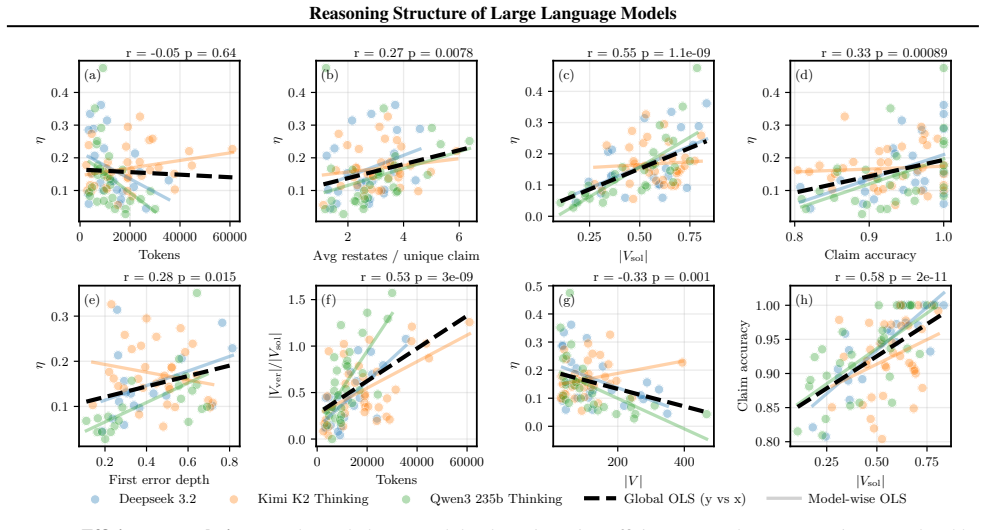
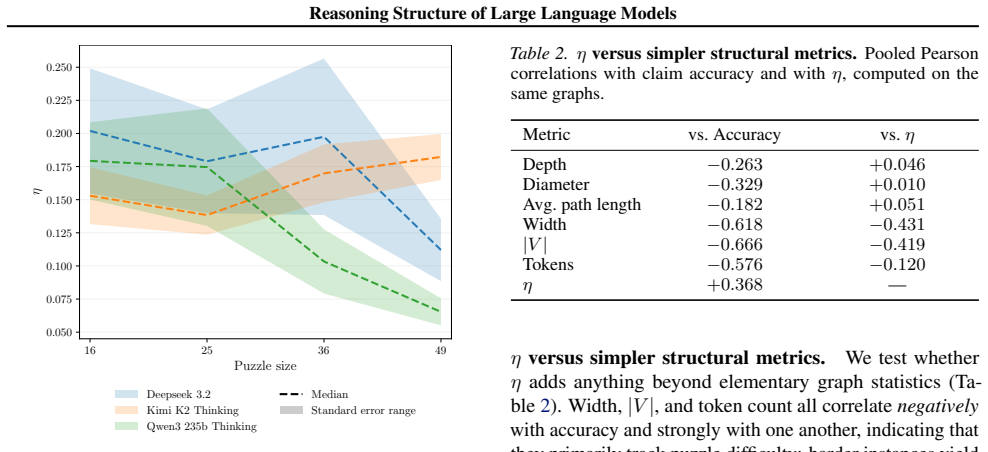
Reasoning in large language models can be represented as verifiable graphs of claims and dependencies extracted from unstructured traces by a scalable pipeline. These graphs turn reasoning into a measurable topological object that supports quantitative analysis. A reasoning efficiency metric derived from the graphs quantifies the concentration of logical flow. When applied to open-source models on logic puzzles, the structural measures distinguish model behaviors that final-answer accuracy and token count leave indistinguishable, supplying a tool for diagnosing failure modes and tracking how reasoning structure scales with puzzle difficulty.
What carries the argument
Reasoning graphs of claims and dependencies extracted from model traces, which serve as the structured object whose topology supports the reasoning efficiency metric.
If this is right
- Structural measurements separate reasoning behaviors that token count and accuracy conflate.
- The reasoning efficiency metric quantifies concentration of logical flow in model traces.
- Graph analysis provides a practical way to diagnose specific failure modes in reasoning.
- Reasoning structure can be compared across models as puzzle difficulty increases.
Where Pith is reading between the lines
- If the graphs prove reliable, they could be used to select or train models toward more concentrated logical structures.
- The same extraction method might be tested on mathematical proofs or code to see whether similar structural distinctions appear.
- Differences in graph topology across model sizes could indicate whether scaling produces systematically more efficient reasoning flows.
Load-bearing premise
The pipeline that converts unstructured traces into verifiable reasoning graphs of claims and dependencies produces graphs that faithfully represent the model's reasoning without significant construction artifacts or loss of logical dependencies.
What would settle it
Human annotation of logical dependencies in a sample of model traces that shows systematic mismatches with the pipeline output would indicate the graphs do not faithfully capture reasoning.
Figures























read the original abstract
Large reasoning models (LRMs) are often evaluated using metrics such as final-answer accuracy or token count. However, identical scores on these metrics can hide fundamentally different reasoning structures. To address this limitation, we introduce a scalable LRM benchmark of logic puzzles and a pipeline that converts unstructured traces into verifiable reasoning graphs of claims and dependencies. This turns reasoning into a structured, measurable object whose topology can be quantitatively analyzed. Building on this, we define a reasoning efficiency metric that quantifies how concentrated the model's logical flow is. Our analysis on open-source reasoning models shows that structural measurements separate behaviors that token count and accuracy conflate, providing a practical tool for diagnosing failure modes and comparing how reasoning scales with puzzle difficulty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark of logic puzzles for large reasoning models (LRMs) along with a pipeline that converts unstructured reasoning traces into graphs of claims and dependencies. It defines a reasoning efficiency metric based on graph topology and claims that structural measurements distinguish reasoning behaviors that token count and accuracy metrics conflate, as demonstrated through analysis of open-source models.
Significance. If the trace-to-graph pipeline is shown to be reliable, the approach would supply a practical new lens for diagnosing LRM failure modes and comparing reasoning structure across puzzle difficulties, extending beyond conventional scalar metrics.
major comments (2)
- [Pipeline description (likely §3 or §4)] Pipeline description (likely §3 or §4): No validation of the automated extraction method is reported, including error rates for claim/dependency identification, comparison to human-annotated traces, or specification of whether the converter is LLM-based, rule-based, or hybrid. This is load-bearing for the central claim, as any systematic merging of claims or invention of dependencies would make the reported topology and efficiency metrics reflect pipeline artifacts rather than model reasoning.
- [Results and evaluation sections] Results and evaluation sections: The abstract and provided description contain no quantitative results, tables, error analysis, or ablation studies demonstrating that the structural metrics separate behaviors more effectively than baselines; without such data the separation claim cannot be assessed.
minor comments (1)
- [Abstract] Abstract: The phrase 'verifiable reasoning graphs' is used without defining the verification procedure or criteria for logical soundness of the extracted dependencies.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below with clarifications from the full manuscript and proposed revisions where appropriate.
read point-by-point responses
-
Referee: Pipeline description (likely §3 or §4): No validation of the automated extraction method is reported, including error rates for claim/dependency identification, comparison to human-annotated traces, or specification of whether the converter is LLM-based, rule-based, or hybrid. This is load-bearing for the central claim, as any systematic merging of claims or invention of dependencies would make the reported topology and efficiency metrics reflect pipeline artifacts rather than model reasoning.
Authors: Section 3 describes the converter as a hybrid system: an LLM prompt for claim extraction followed by deterministic rule-based parsing for dependency edges, with explicit prompts and rules provided in the appendix. We agree that a quantitative validation study against human annotations is missing from the current version and is necessary to support the central claims. We will add a dedicated validation subsection reporting precision/recall on a sample of 200 manually annotated traces along with inter-annotator agreement. revision: yes
-
Referee: Results and evaluation sections: The abstract and provided description contain no quantitative results, tables, error analysis, or ablation studies demonstrating that the structural metrics separate behaviors more effectively than baselines; without such data the separation claim cannot be assessed.
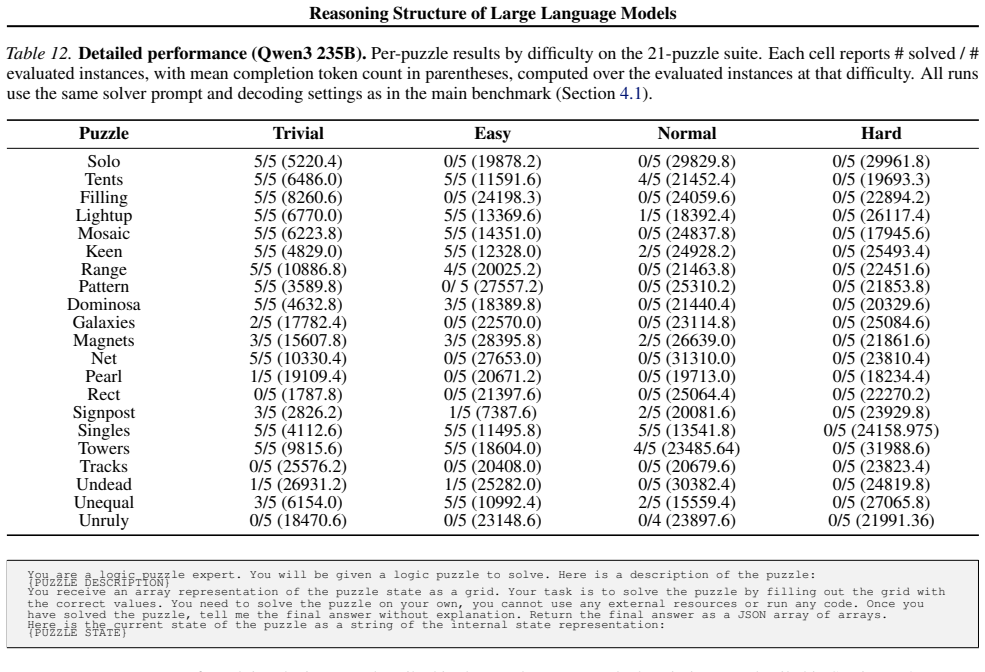
Authors: Sections 5 and 6 of the full manuscript contain the requested quantitative results: tables comparing reasoning efficiency, graph density, and path concentration across five open-source LRMs on puzzles of increasing difficulty, together with direct comparisons showing that these structural metrics differentiate model behaviors where accuracy and token count do not. We will revise the abstract to include the key numerical findings and will add an explicit ablation on the efficiency metric if it is not already present in sufficient detail. revision: partial
Circularity Check
No significant circularity; empirical analysis on constructed graphs
full rationale
The paper introduces a pipeline converting traces to claim-dependency graphs and defines a reasoning efficiency metric quantifying concentration of logical flow. The central claim is an empirical finding that structural measurements distinguish behaviors conflated by token count and accuracy. No equations, self-citations, or derivations are shown that reduce any prediction or result to its inputs by construction. The pipeline and metric are presented as new tools for analysis rather than self-referential fits, and the abstract provides no load-bearing self-citation chains or ansatzes smuggled via prior work. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Concrete Problems in AI Safety
arXiv:1606.06565. Berdoz, F., Lanzend¨orfer, L., Tuninga, N., and Wattenhofer, R. Text-to-Scene with Large Reasoning Models. InAAAI Conference on Artificial Intelligence (AAAI), 2026. Besta, M., Blach, N., Kubicek, A., Gerstenberger, R., Pod- stawski, M., Gianinazzi, L., et al. Graph of Thoughts: Solving Elaborate Problems with Large Language Mod- 9 Reaso...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Kimi K2: Open Agentic Intelligence
URL https://www.chiark.greenend. org.uk/˜sgtatham/puzzles/. Accessed January 28, 2026. Team, K. et al. Kimi K2: Open Agentic Intelligence, 2025. arXiv:2507.20534. Ueda, N. and Nagao, T. NP-completeness Results for NONOGRAM via Parsimonious Reductions. Technical report TR96-0008, Tokyo Institute of Technology, 1996. Wang, Y ., Liu, Q., Xu, J., Liang, T., C...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
arXiv:2504.10885. 11 Reasoning Structure of Large Language Models Zhou, Z., Zhu, Z., Li, X., Galkin, M., Feng, X., Koyejo, S., et al. Landscape of Thoughts: Visualizing the Reasoning Process of Large Language Models. InInternational Conference on Learning Representations (ICLR), 2026. 12 Reasoning Structure of Large Language Models Appendix overview.This ...
-
[4]
R_COUNT_REMAINING (output: Remaining)Essence:- The reasoning trace explicitly computes an EXACT remaining count for a row/col by counting placed tents and subtracting from quota.Use only if:- \remaining/left/still to place" language + explicit counting/arithmetic.Minimal inputs:- the relevant Quota(...)- the Tent claims explicitly counted, if they exist; ...
-
[5]
R_LINE_BLOCK (output: NotTent)Essence:- The reasoning trace concludes this cell is NotTent BECAUSE the line has no capacity left (full / 0 remaining / quota 0).Minimal inputs:- Remaining(...,0) or Quota(...,0) when available; otherwise C_MISSING if fullness is explicitly asserted.Never use for:- no-touch or needs-tree reasoning
-
[6]
R_NO_TOUCH (output: NotTent)Essence:- The reasoning trace concludes this cell is NotTent because it would touch a specific tent (\tents can't touch").Minimal inputs:- the causing Tent(...) if available; otherwise C_MISSING if the reasoning trace relies on it.Never use for:- needs-tree or fullness reasoning
-
[7]
, \place/put/set
R_ONLY_CAND (output: TreeCandidate OR Tent)Essence:- Tree-anchored candidate restriction (\for the tree at ... only possible cells are ...") and optionally tree-forced placement.Use only if:- reasoning is explicitly anchored to a specific tree.Minimal inputs:- Tree(...) for that tree.- include elimination reasons ONLY if explicitly cited; otherwise omit; ...
-
[8]
facts but the needed candidate claim is missing.Tent output allowed only if:- reasoning trace explicitly concludes/places (\must be
R_LINE_CAND (output: LineCandidates OR Tent)Essence:- Line-anchored candidate restriction (\in row/col ... only possible cells are ...") and optionally placement from line uniqueness/intersection.Use only if:- reasoning is explicitly anchored to a row/col (or intersection of row/col candidates).Minimal inputs:- For LineCandidates output: Quota(...) or Rem...
-
[9]
R_CELL_NEEDS_TREE (output: NotTent)Essence:- The reasoning trace concludes this cell is NotTent because a tent must be adjacent to a tree, and this cell has no adjacent tree (as argued).Minimal inputs:- referenced Tree(...) claims if cited; otherwise omit; use C_MISSING if adjacency-to-tree reasoning is cited but missing in claims.Never use for:- no-touch...
-
[10]
R_CONTRADICTION_CAUSE (output: Contradiction)Essence:- The reasoning trace explicitly declares a contradiction in a BRANCH and cites (at least implicitly) the statements that cannot all hold.Use only if:- the reasoning trace says \contradiction/contradicts/inconsistent/impossible" (or equivalent) and concludes a Contradiction claim.Minimal inputs:- Includ...
-
[11]
tentative
R_TENTATIVE_DISCHARGE (output: Tent or NotTent in MAIN)Essence:- Proof-by-contradiction discharge: after Contradiction(branch=k) in BRANCH#k, the reasoning trace concludes the negation of the tentative assumption in MAIN.- OR, confirmation of the tentative assumption if no contradiction arose.Inputs MUST include:- Exactly one tentative assumption in BRANC...
2003
-
[12]
, \column has
R_UNIT_HAS_STATED (output: UnitHas)Essence:- The trace explicitly states a unit contains a digit (inventory or justification).Minimal inputs: []Use when:- \digits present are ...", \column has ...", OR \because digit d is in its row/col/box"
-
[13]
R_UNIT_MISSING_STATED (output: UnitMissing)Essence:- The trace explicitly states the exact missing digits of a unit.Minimal inputs: []Never use for:- inferred updates after a placement unless the updated set is explicitly stated
-
[14]
OUT")Essence:- The trace eliminates digits for a cell explicitly because those digits already appear in the cell's row/col/box (\cannot be ... because ... already appears in
R_ELIM_BY_UNIT_PRESENCE (output: Cand with polarity="OUT")Essence:- The trace eliminates digits for a cell explicitly because those digits already appear in the cell's row/col/box (\cannot be ... because ... already appears in ...").Minimal inputs:- The relevant UnitHas(...) claim(s) if present; otherwise C_MISSING.Notes:- The output Cand(OUT).d must matc...
-
[15]
OUT")Essence:- The trace eliminates digits for a cell due to an explicit constraint that is NOT phrased as direct unit presence (e.g., \by column constraints
R_ELIM_BY_CONSTRAINT (output: Cand with polarity="OUT")Essence:- The trace eliminates digits for a cell due to an explicit constraint that is NOT phrased as direct unit presence (e.g., \by column constraints" without naming digits present, or other explicitly cited constraint reasoning).Minimal inputs:- Any explicitly referenced premise claims if they exi...
-
[16]
/ \only remaining digit for the cell
R_ONLY_REMAINING_IN_CELL (output: Assign)Essence:- The trace concludes the digit for a cell because all other options are eliminated (\cannot be ... so it must be ..." / \only remaining digit for the cell").Minimal inputs:- A Cand(OUT) elimination for that cell if present; otherwise C_MISSING.- A UnitMissing for the relevant unit if explicitly used/stated...
-
[17]
R_ONLY_MISSING_DIGIT_IN_UNIT (output: Assign)Essence:- The trace places a digit because it is the only missing digit left in a unit and the trace specifies the target cell (\only remaining digit for row/col/box is d, placed at ...").Minimal inputs:- The corresponding UnitMissing(unit,index,[d]) if explicitly stated; otherwise C_MISSING.Important:- Do NOT ...
-
[18]
R_PATTERN_EXPERT (output: Cand(OUT) or Assign or UnitPlaces)Essence:- A named or template-identifiable advanced Sudoku technique (X-Wing, XY-Wing, Swordfish, Skyscraper, AIC/nice loop, Unique Rectangle, ALS, etc.) is explicitly used.Minimal inputs:- Any claims explicitly referenced by the trace; otherwise C_MISSING.Use only if:- The technique name (or una...
-
[19]
R_CONTRADICTION_CAUSE (output: Contradiction)Essence:- The trace explicitly declares a contradiction in a branch and cites statements that cannot all hold.Minimal inputs:- Conflicting claims if referenced; otherwise C_MISSING
-
[20]
L" to represent the left half of a domino and
R_CONTRADICTION_DISCHARGE (output: Cand(OUT) or Assign in MAIN)Essence:- After Contradiction in BRANCH#k, the trace concludes the negation/forced conclusion in MAIN.Inputs MUST include:- Exactly one tentative assumption in BRANCH#k.- Exactly one Contradiction(branch=k, ...) in BRANCH#k. Figure 16.Possible rules forSudoku. 25 Reasoning Structure of Large L...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.