RealClawBench: Live OpenClaw Benchmarks from Real Developer-Agent Sessions
Pith reviewed 2026-06-28 09:54 UTC · model grok-4.3
The pith
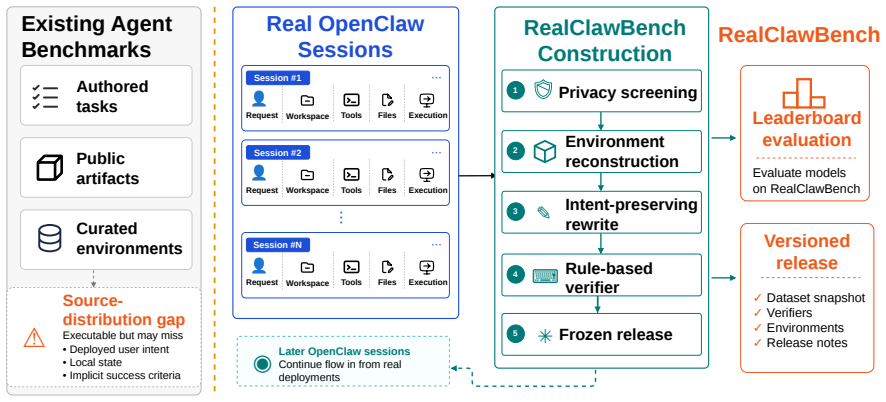
RealClawBench converts live developer-agent sessions into 281 reproducible tasks via environment reconstruction and automatic scorers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
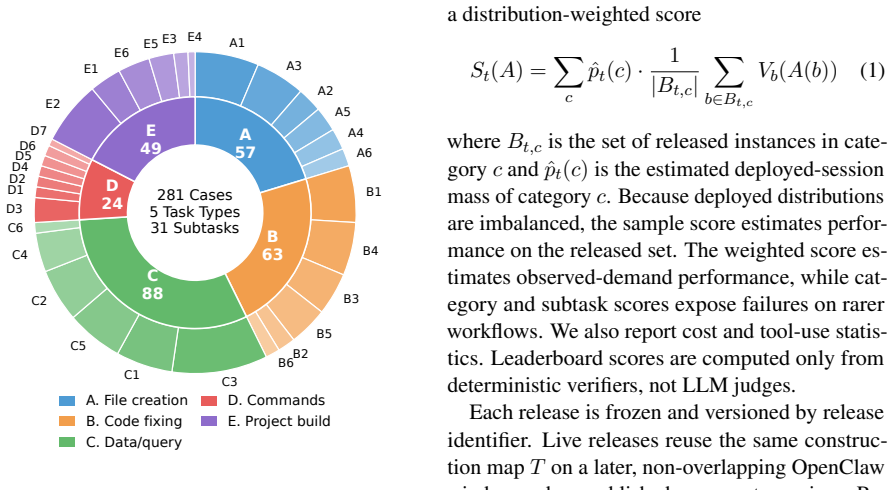
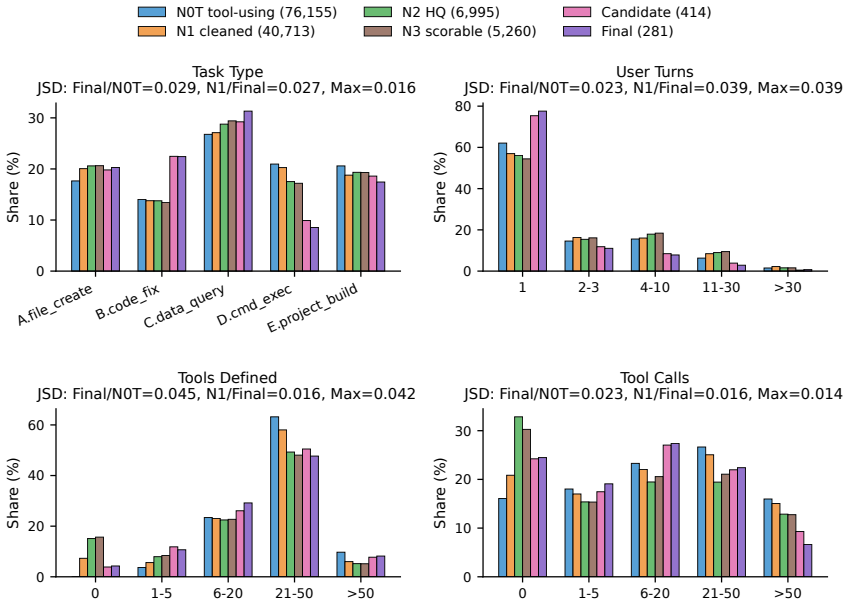
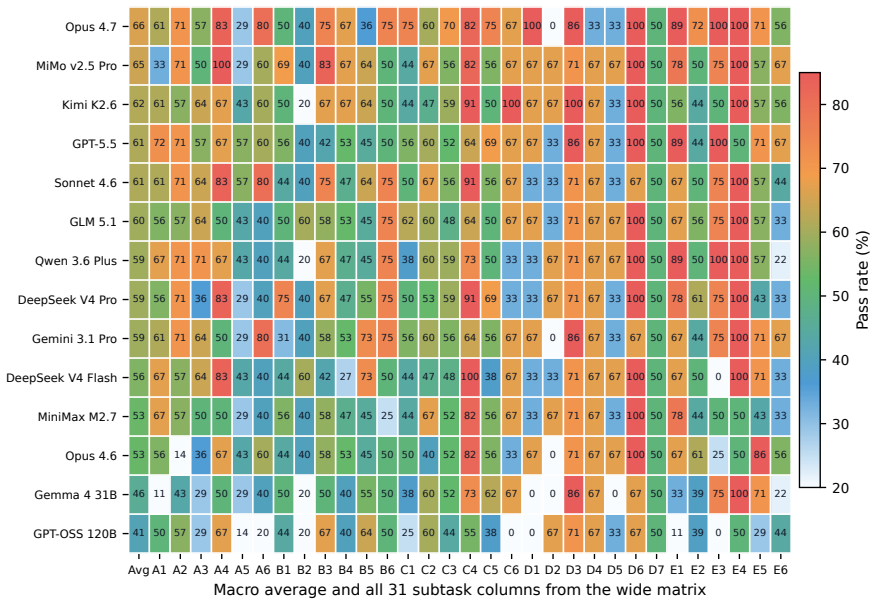
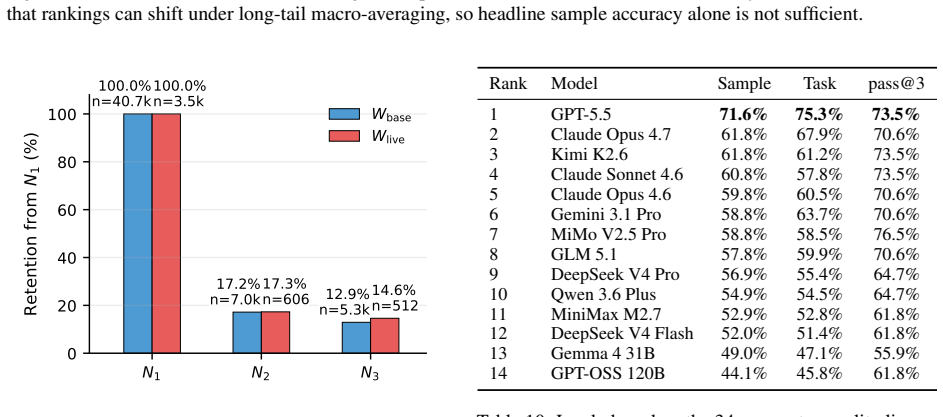
By applying reconstructed execution environments and deterministic verifiable scorers to real user sessions, RealClawBench produces 281 executable tasks that preserve the source distribution with a maximum Jensen-Shannon divergence of 0.0448. Evaluation of 14 models shows the strongest one succeeds on 65.8 percent of the tasks.
What carries the argument
Reconstructed execution environments paired with deterministic verifiable scorers that convert live sessions into controlled, automatically scored benchmark tasks.
If this is right
- Real sessions can be turned into benchmark tasks while keeping their statistical distribution intact.
- Current models leave more than a third of realistic developer tasks unsolved.
- Live-derived benchmarks give a direct signal of how close agents are to handling actual deployed workloads.
- The construction method scales to larger pools while maintaining low divergence from the source.
Where Pith is reading between the lines
- The same reconstruction approach could be applied to sessions from other agent platforms to produce comparable realistic tests.
- Gains on this benchmark would likely require better agent handling of local file systems and clarification of underspecified requests.
- Repeated evaluation against live-derived sets could steer research toward capabilities that directly affect real usage rather than benchmark-specific tricks.
Load-bearing premise
That the reconstructed environments and scorers faithfully reproduce the original sessions without systematically altering their difficulty or success criteria.
What would settle it
A side-by-side run showing that success rates on the benchmark tasks differ markedly from success rates observed when the same agents or humans attempt the original unreconstructed sessions.
Figures





read the original abstract
Agent benchmarks should reflect what users actually ask deployed agents to do, yet existing benchmarks often miss key realism properties of real developer-agent sessions. We introduce RealClawBench, a live benchmark framework built from real OpenClaw sessions to capture the distribution, diversity, and real-world difficulty of deployed agent use. Real user requests are challenging to benchmark because they often depend on local execution environments, involve implicit or underspecified intent, and require nontrivial verification. RealClawBench addresses these challenges with two core mechanisms: reconstructed execution environments and deterministic verifiable scorers, which together convert real sessions into reproducible, automatically scored tasks. The resulting release contains 281 executable tasks sampled from a much larger real-session pool while preserving the source distribution, with maximum final-vs-source Jensen-Shannon divergence of 0.0448. Evaluating 14 contemporary models shows that the best system solves only 65.8% of tasks, revealing substantial headroom on realistic developer-agent workloads. By turning real deployed sessions into controlled evaluation instances, RealClawBench provides a practical path toward benchmarks that better measure agent capability in actual use. Code is available at:https://anonymous.4open.science/r/real-claw-bench-582B.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RealClawBench, a benchmark framework derived from real OpenClaw developer-agent sessions. It uses reconstructed execution environments and deterministic verifiable scorers to convert live sessions into 281 reproducible, automatically scored tasks that preserve the source distribution (maximum JS divergence of 0.0448). Evaluation of 14 contemporary models shows the best system solves only 65.8% of tasks, indicating substantial headroom on realistic workloads.
Significance. If the reconstruction and scoring mechanisms faithfully reproduce original session difficulty and success criteria, the benchmark would provide a valuable resource for measuring agent performance on actual deployed workloads rather than synthetic tasks. The code release and distribution-matching approach are positive elements supporting potential reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that the benchmark captures 'real-world difficulty' and provides a 'practical path toward benchmarks that better measure agent capability in actual use' rests on the unvalidated assumption that reconstructed environments and deterministic scorers introduce no systematic distortion relative to original sessions. Only surface-level task-type distribution matching (JS divergence 0.0448) is reported; no evidence is given on execution-path fidelity, scorer encoding of implicit user intent, or empirical match of success rates to the live sessions.
- [Abstract] Abstract: the reported 65.8% ceiling on 281 tasks is presented as evidence of headroom, but without any described validation (e.g., human review of scorer accuracy or ablation comparing reconstructed vs. original outcomes), it is unclear whether this figure reflects genuine model limitations or artifacts of the reconstruction process.
minor comments (1)
- [Abstract] The abstract states 'Code is available at:https://anonymous.4open.science/r/real-claw-bench-582B' but provides no further details on what artifacts (environments, scorers, task definitions) are included or how they can be used to reproduce the reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on validation of reconstruction fidelity. We address each major point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the benchmark captures 'real-world difficulty' and provides a 'practical path toward benchmarks that better measure agent capability in actual use' rests on the unvalidated assumption that reconstructed environments and deterministic scorers introduce no systematic distortion relative to original sessions. Only surface-level task-type distribution matching (JS divergence 0.0448) is reported; no evidence is given on execution-path fidelity, scorer encoding of implicit user intent, or empirical match of success rates to the live sessions.
Authors: The primary quantitative support for fidelity in the manuscript is the reported maximum Jensen-Shannon divergence of 0.0448 on task-type distributions between the 281 sampled tasks and the source pool. The methods describe environment reconstruction from session logs and the design of deterministic scorers tied to observable session outcomes. We did not perform ablations on execution-path equivalence, human review of scorer alignment with implicit intent, or direct comparisons of model success rates between reconstructed and original live sessions. We will add a limitations paragraph in revision to explicitly note these gaps and the practical challenges of obtaining such matches for live developer sessions. revision: partial
-
Referee: [Abstract] Abstract: the reported 65.8% ceiling on 281 tasks is presented as evidence of headroom, but without any described validation (e.g., human review of scorer accuracy or ablation comparing reconstructed vs. original outcomes), it is unclear whether this figure reflects genuine model limitations or artifacts of the reconstruction process.
Authors: The 65.8% figure is the highest success rate observed across the 14 models on the 281 reconstructed tasks. We present it as indicating headroom because the tasks are drawn from real sessions while preserving the measured distribution. We agree that the absence of human scorer validation or direct reconstructed-vs-original ablations leaves open the possibility of reconstruction artifacts. In revision we will update the abstract and results discussion to qualify the headroom claim as based on distribution-matched tasks and to reference the new limitations paragraph. revision: partial
Circularity Check
No circularity: benchmark is constructed via independent data collection and direct evaluation.
full rationale
The paper presents RealClawBench as the result of sampling real sessions, reconstructing environments, and building deterministic scorers—an empirical data-collection pipeline with no equations, fitted parameters, or derivations. The reported 65.8% solve rate is a direct measurement on the released tasks; the JS divergence of 0.0448 is a post-hoc distribution statistic, not a prediction that reduces to any fitted input. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The derivation chain is therefore self-contained against external benchmarks and contains no reductions of the enumerated circular kinds.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , volume=
Swe-bench: Can language models resolve real-world github issues? , author=. International Conference on Learning Representations , volume=
-
[2]
arXiv preprint arXiv:2605.27922 , year=
Harness-Bench: Measuring Harness Effects across Models in Realistic Agent Workflows , author=. arXiv preprint arXiv:2605.27922 , year=
-
[3]
arXiv preprint arXiv:2512.12730 , year=
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents , author=. arXiv preprint arXiv:2512.12730 , year=
-
[4]
arXiv preprint arXiv:2112.09332 , year=
Webgpt: Browser-assisted question-answering with human feedback , author=. arXiv preprint arXiv:2112.09332 , year=
-
[5]
arXiv preprint arXiv:2205.00445 , year=
MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning , author=. arXiv preprint arXiv:2205.00445 , year=
-
[6]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[7]
arXiv preprint arXiv:2210.03629 , year=
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
-
[8]
International Conference on Learning Representations , volume=
Webarena: A realistic web environment for building autonomous agents , author=. International Conference on Learning Representations , volume=
-
[9]
International Conference on Learning Representations , volume=
Agentbench: Evaluating llms as agents , author=. International Conference on Learning Representations , volume=
-
[10]
International Conference on Learning Representations , volume=
Gaia: a benchmark for general ai assistants , author=. International Conference on Learning Representations , volume=
-
[11]
International Conference on Learning Representations , volume=
Livebench: A challenging, contamination-limited llm benchmark , author=. International Conference on Learning Representations , volume=
-
[12]
International Conference on Learning Representations , volume=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. International Conference on Learning Representations , volume=
-
[13]
International Conference on Learning Representations , volume=
Lmsys-chat-1m: A large-scale real-world llm conversation dataset , author=. International Conference on Learning Representations , volume=
-
[14]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[15]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[16]
Transactions on machine learning research , year=
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models , author=. Transactions on machine learning research , year=
-
[17]
arXiv preprint arXiv:2211.09110 , year=
Holistic evaluation of language models , author=. arXiv preprint arXiv:2211.09110 , year=
-
[18]
2026 , howpublished=
2026
-
[19]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Api-bank: A comprehensive benchmark for tool-augmented llms , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[20]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[21]
arXiv preprint arXiv:2406.12045 , year=
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. arXiv preprint arXiv:2406.12045 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2403.07718 , year=
Workarena: How capable are web agents at solving common knowledge work tasks? , author=. arXiv preprint arXiv:2403.07718 , year=
-
[24]
arXiv preprint arXiv:2410.03859 , year=
Swe-bench multimodal: Do ai systems generalize to visual software domains? , author=. arXiv preprint arXiv:2410.03859 , year=
-
[25]
International Conference on Learning Representations , volume=
Mle-bench: Evaluating machine learning agents on machine learning engineering , author=. International Conference on Learning Representations , volume=
-
[26]
arXiv preprint arXiv:2403.04132 , year=
Chatbot arena: An open platform for evaluating llms by human preference , author=. arXiv preprint arXiv:2403.04132 , year=
-
[27]
arXiv preprint arXiv:2405.01470 , year=
Wildchat: 1m chatgpt interaction logs in the wild , author=. arXiv preprint arXiv:2405.01470 , year=
-
[28]
International Conference on Learning Representations , volume=
Wildbench: Benchmarking llms with challenging tasks from real users in the wild , author=. International Conference on Learning Representations , volume=
-
[29]
arXiv preprint arXiv:2605.10912 , year=
WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation , author=. arXiv preprint arXiv:2605.10912 , year=
-
[30]
2026 , url =
ClawBench: Trace-Scored Agent Benchmark with Dynamical-Systems Diagnostics , author =. 2026 , url =
2026
-
[31]
arXiv preprint arXiv:2604.04759 , year=
Your agent, their asset: A real-world safety analysis of openclaw , author=. arXiv preprint arXiv:2604.04759 , year=
-
[32]
arXiv preprint arXiv:2604.14858 , year=
Benchmarks for Trajectory Safety Evaluation and Diagnosis in OpenClaw and Codex: ATBench-Claw and ATBench-CodeX , author=. arXiv preprint arXiv:2604.14858 , year=
-
[33]
2026 , howpublished=
Introducing. 2026 , howpublished=
2026
-
[34]
2025 , howpublished=
2025
-
[35]
A Primer in Post-Training Reasoning Data: What We Know About How It Works
Li, Yaoming and Zhao, Guangxiang and Shi, Qilong and Sun, Lin and Zhang, Xiangzheng and Yang, Tong , year =. doi:10.48550/arXiv.2606.02113 , url =. 2606.02113 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.02113
-
[36]
2026 , eprint=
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents , author=. 2026 , eprint=
2026
-
[37]
2026 , eprint=
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.