FFR: Forward-Forward Learning for Regression
Pith reviewed 2026-06-28 11:14 UTC · model grok-4.3
The pith
FFR extends Forward-Forward to regression by using ordinal competitive neuron groups and a ladder architecture to reach 98.6 percent of backpropagation accuracy with far lower memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FFR is the first method to train neural networks for real-world regression through purely local forward passes by defining an ordinal competitive goodness function on partitioned neuron groups under distance-aware ordinal supervision, employing a stratified ladder architecture for progressive refinement from coarse to fine predictions, and using hierarchical multi-scale predictors that jointly output values and confidence estimates.
What carries the argument
Ordinal competitive goodness function that scores competitive learning between partitioned neuron groups according to how closely their activations match the ordinal position and distance of the continuous target value.
If this is right
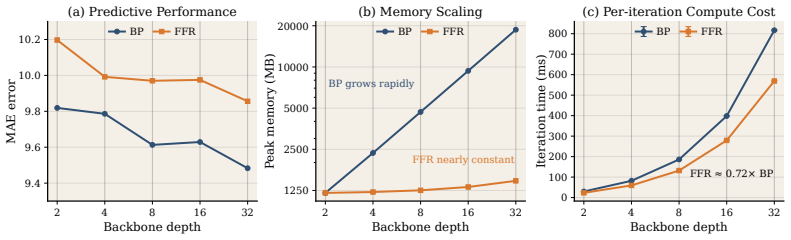
- FFR achieves 98.6 percent of backpropagation accuracy on average across five real-world regression benchmarks.
- Peak training memory falls to 27 percent of backpropagation at depth 8 and 8 percent at depth 32.
- Per-iteration training time is around 72 percent of backpropagation.
- FFR substantially outperforms all tested backpropagation-free competitors on the same tasks.
Where Pith is reading between the lines
- The same local-learning structure could be tested on other continuous-output problems such as time-series forecasting or density estimation.
- The memory scaling advantage at greater depths suggests the approach may become increasingly attractive for very deep networks where backpropagation memory costs grow linearly.
- The free uncertainty estimates from hierarchical predictors could be evaluated for calibration on safety-critical regression applications.
Load-bearing premise
The ordinal competitive goodness function defined on partitioned neuron groups under distance-aware ordinal supervision can encode continuous target magnitude and ordering sufficiently well to support accurate regression without any contrastive positive-negative sample pairs.
What would settle it
If accuracy on the five regression benchmarks drops well below 98.6 percent of backpropagation performance or if peak memory at depth 32 does not fall to around 8 percent of backpropagation levels, the performance claims would be falsified.
Figures





read the original abstract
The Forward-Forward (FF) algorithm offers a computationally efficient and biologically plausible alternative to backpropagation (BP) by training neural networks through purely local, layer-wise optimization. However, FF is inherently designed for classification via contrastive positive-negative sample pairs, and extending it to regression poses fundamental challenges: continuous target space lack natural "opposites" for contrastive learning, and the standard goodness function carries no information about target magnitude or ordering. We propose FFR (Forward-Forward for Regression), to our knowledge, the first framework to extend FF to real-world regression and demonstrate competitive performance across diverse real-world datasets. FFR introduces three key innovations: (1) an ordinal competitive goodness function that replaces contrastive pairs with competitive learning between partitioned neuron groups under distance-aware ordinal supervision; (2) a stratified ladder architecture where shallow layers learn coarse ordinal discrimination and deeper layers refine into fine-grained regression, with multi-scale feature aggregation for inter-layer collaboration; and (3) hierarchical prediction with uncertainty estimation, where multi-scale predictors jointly provide robust predictions and prediction confidence as a free-lunch. Extensive experimental results show FFR recovers on average 98.6% of BP's accuracy across five real-world regression benchmarks while reducing peak training memory to only 27% of BP's at depth 8 and 8% at depth 32, with per-iteration time around 72% of BP's, and substantially outperforms all BP-free competitors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FFR, an extension of the Forward-Forward (FF) algorithm to regression tasks. It introduces an ordinal competitive goodness function using partitioned neuron groups under distance-aware ordinal supervision to handle continuous targets without contrastive pairs, a stratified ladder architecture for coarse-to-fine learning with multi-scale aggregation, and hierarchical prediction for robust outputs and uncertainty. Experiments on five real-world regression benchmarks demonstrate that FFR recovers 98.6% of backpropagation (BP) accuracy on average, reduces peak training memory to 27% of BP at depth 8 and 8% at depth 32, and uses about 72% of BP's per-iteration time, while outperforming other BP-free methods.
Significance. If the empirical results hold, this work would be significant for advancing biologically plausible alternatives to backpropagation in regression settings, where FF has been limited to classification. The efficiency improvements in memory and computation for deeper networks are a notable strength, as is the application to real-world datasets. The introduction of mechanisms to handle ordinal and magnitude information in a local learning framework addresses a key gap.
major comments (3)
- [§3.1] §3.1: The ordinal competitive goodness function is defined via partitioned neuron groups and distance-aware ordinal supervision. No explicit argument, toy example, or derivation is given showing that this encodes continuous target magnitude (rather than coarse rank order) in the absence of contrastive pairs; this assumption is load-bearing for the central claim that FFR successfully extends FF to regression.
- [§4] §4: The headline performance figures (98.6% BP accuracy recovery, memory reductions to 27%/8% at depths 8/32) are reported without an experimental protocol, baseline implementation details, error bars, dataset statistics, or ablation studies isolating the contribution of the ordinal goodness function versus the ladder architecture. This prevents verification of the empirical claims.
- [§4.3] §4.3 (memory/time results): The reported savings are presented as direct comparisons to BP, yet the text does not specify the exact measurement procedure (e.g., peak allocated GPU memory, wall-clock timing including overhead) or control for implementation differences, making the efficiency advantage difficult to interpret.
minor comments (2)
- [Abstract, §3] The abstract and §3 introduce free parameters (neuron-group partition sizes, multi-scale aggregation weights) without stating how they are selected or whether performance is robust to their choice.
- [§3.2] Notation for the stratified ladder and hierarchical predictors could be made more explicit with numbered equations.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recognition of the work's potential significance. We address each major comment below.
read point-by-point responses
-
Referee: [§3.1] §3.1: The ordinal competitive goodness function is defined via partitioned neuron groups and distance-aware ordinal supervision. No explicit argument, toy example, or derivation is given showing that this encodes continuous target magnitude (rather than coarse rank order) in the absence of contrastive pairs; this assumption is load-bearing for the central claim that FFR successfully extends FF to regression.
Authors: We agree that the current presentation would be strengthened by an explicit derivation or toy example. The distance-aware supervision is designed to encode magnitude via proportional penalties on group activations, but we will add a short mathematical argument and 1D toy example in the revised §3.1 to demonstrate continuous encoding. revision: yes
-
Referee: [§4] §4: The headline performance figures (98.6% BP accuracy recovery, memory reductions to 27%/8% at depths 8/32) are reported without an experimental protocol, baseline implementation details, error bars, dataset statistics, or ablation studies isolating the contribution of the ordinal goodness function versus the ladder architecture. This prevents verification of the empirical claims.
Authors: We accept that these details are required for verification. The revision will add a dedicated experimental protocol subsection, baseline code references, error bars from repeated runs, dataset statistics, and ablations separating the ordinal goodness and ladder components. revision: yes
-
Referee: [§4.3] §4.3 (memory/time results): The reported savings are presented as direct comparisons to BP, yet the text does not specify the exact measurement procedure (e.g., peak allocated GPU memory, wall-clock timing including overhead) or control for implementation differences, making the efficiency advantage difficult to interpret.
Authors: We will expand §4.3 to detail the measurement protocol, including PyTorch memory profiler usage for peak allocated GPU memory, full overhead inclusion in timing, and controls for implementation parity via shared codebases. revision: yes
Circularity Check
No significant circularity; empirical engineering contribution
full rationale
The paper introduces FFR as an empirical extension of Forward-Forward to regression via new architectural components (ordinal competitive goodness, stratified ladder, hierarchical prediction) and reports benchmark results (98.6% BP recovery, memory/time savings). No load-bearing derivation, equation, or claim reduces by construction to its own inputs, fitted parameters renamed as predictions, or self-citation chains. The central performance figures are presented as experimental outcomes on external datasets, not forced by definition or internal fitting. This is the expected self-contained case for an applied ML engineering paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- neuron-group partition sizes
- multi-scale aggregation weights
axioms (1)
- domain assumption Layer-wise local goodness functions can train networks to perform regression when supplied with an appropriate ordinal supervision signal.
invented entities (2)
-
ordinal competitive goodness function
no independent evidence
-
stratified ladder architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
How Auto-Encoders Could Provide Credit Assignment in Deep Networks via Target Propagation
Yoshua Bengio. How auto-encoders could provide credit assignment in deep networks via target propaga- tion.arXiv preprint arXiv:1407.7906, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[2]
Greedy layer-wise training of deep networks
Yoshua Bengio, Pascal Lamblin, Dan Popovici, and Hugo Larochelle. Greedy layer-wise training of deep networks. InAdvances in Neural Information Processing Systems, volume 19, pages 153–160, 2006
2006
-
[3]
Candanedo, Véronique Feldheim, and Dominique Deramaix
Luis M. Candanedo, Véronique Feldheim, and Dominique Deramaix. Data driven prediction models of energy use of appliances in a low-energy house.Energy and Buildings, 140:81–97, 2017
2017
-
[4]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational Conference on Machine Learning, pages 1597–1607. PMLR, 2020
2020
-
[5]
Self-contrastive forward-forward algorithm.Nature Communications, 16(1):5978, 2025
Xing Chen, Dongshu Liu, Jérémie Laydevant, and Julie Grollier. Self-contrastive forward-forward algorithm.Nature Communications, 16(1):5978, 2025
2025
-
[6]
Tool remaining useful life prediction using bidirectional recurrent neural networks (BRNN).The International Journal of Advanced Manufacturing Technology, 125(9–10):4027–4045, 2023
Telmo Fernández De Barrena, Juan Luís Ferrando, Ander García, Xabier Badiola, Mikel Sáez de Buruaga, and Javier Vicente. Tool remaining useful life prediction using bidirectional recurrent neural networks (BRNN).The International Journal of Advanced Manufacturing Technology, 125(9–10):4027–4045, 2023
2023
-
[7]
Error-driven input modulation: Solving the credit assignment problem without a backward pass
Giorgia Dellaferrera and Gabriel Kreiman. Error-driven input modulation: Solving the credit assignment problem without a backward pass. InInternational Conference on Machine Learning. PMLR, 2022
2022
-
[8]
The trifecta: Three simple techniques for training deeper forward-forward networks.Transactions on Machine Learning Research, 2024
Thomas Dooms, José Oramas, and Nick Deligiannis. The trifecta: Three simple techniques for training deeper forward-forward networks.Transactions on Machine Learning Research, 2024
2024
-
[9]
Feed- forward optimization with delayed feedback for neural network training
Katharina Flügel, Daniel Coquelin, Marie Weiel, Charlotte Debus, Achim Streit, and Markus Götz. Feed- forward optimization with delayed feedback for neural network training. InInternational Conference on Neural Information Processing, 2024
2024
-
[10]
Local learning for stable backpropagation-free neural network training towards physical learning
Yaqi Guo, Fabian Braun, Bastiaan Ketelaar, Stephanie Tan, Richard Norte, and Siddhant Kumar. Local learning for stable backpropagation-free neural network training towards physical learning.arXiv preprint arXiv:2603.24790, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
The forward-forward algorithm: Some preliminary investigations
Geoffrey Hinton. The forward-forward algorithm: Some preliminary investigations.arXiv preprint arXiv:2212.13345, 2022
-
[12]
KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment.IEEE Transactions on Image Processing, 29:4041–4056, 2020
Vlad Hosu, Hanhe Lin, Tamas Sziranyi, and Dietmar Saupe. KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment.IEEE Transactions on Image Processing, 29:4041–4056, 2020
2020
-
[13]
Jabri and Barry Flower
Marwan A. Jabri and Barry Flower. Weight perturbation: An optimal architecture and learning technique for analog VLSI feedforward and recurrent multilayer networks.Neural Computation, 3(4):546–565, 1992
1992
-
[14]
Difference target propagation
Dong-Hyun Lee, Saizheng Zhang, Asja Fischer, and Yoshua Bengio. Difference target propagation. In Machine Learning and Knowledge Discovery in Databases (ECML PKDD), 2015
2015
-
[15]
Lillicrap, Daniel Cownden, Douglas B
Timothy P. Lillicrap, Daniel Cownden, Douglas B. Tweed, and Colin J. Akerman. Random synaptic feedback weights support error backpropagation for deep learning.Nature Communications, 7:13276, 2016
2016
-
[16]
Layer collaboration in the forward-forward algorithm
Guy Lorberbom, Itai Bhatt, Yaniv Eisenberger, Shailesh Garg, Tommi Jaakkola, and Alexander G Schwing. Layer collaboration in the forward-forward algorithm. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 14106–14114, 2024
2024
-
[17]
Application of artificial intelligence in wearable devices: Opportunities and challenges.Computer Methods and Programs in Biomedicine, 213:106541, 2022
Darius Nahavandi, Roohallah Alizadehsani, Abbas Khosravi, and U Rajendra Acharya. Application of artificial intelligence in wearable devices: Opportunities and challenges.Computer Methods and Programs in Biomedicine, 213:106541, 2022. 10
2022
-
[18]
Direct feedback alignment provides learning in deep neural networks
Arild Nøkland. Direct feedback alignment provides learning in deep neural networks. InAdvances in Neural Information Processing Systems, 2016
2016
-
[19]
Training neural networks with local error signals
Arild Nøkland and Lars Hiller Eidnes. Training neural networks with local error signals. InInternational Conference on Machine Learning. PMLR, 2019
2019
-
[20]
Shivam Padmani and Akshay Joshi. Function regression using the forward forward training and inferring paradigm.arXiv preprint arXiv:2510.06762, 2025
-
[21]
Marco A. F. Pimentel, Alistair E. W. Johnson, Peter H. Charlton, and David A. Clifton. Towards a robust estimation of respiratory rate from pulse oximeters.IEEE Transactions on Biomedical Engineering, 64(8): 1914–1923, 2017
1914
-
[22]
Learning representations by back- propagating errors.Nature, 323(6088):533–536, 1986
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back- propagating errors.Nature, 323(6088):533–536, 1986
1986
-
[23]
Equilibrium propagation: Bridging the gap between energy-based models and backpropagation.Frontiers in Computational Neuroscience, 11:24, 2017
Benjamin Scellier and Yoshua Bengio. Equilibrium propagation: Bridging the gap between energy-based models and backpropagation.Frontiers in Computational Neuroscience, 11:24, 2017
2017
-
[24]
Opportunities for neuromorphic computing algorithms and applications.Nature Computational Science, 2 (1):10–19, 2022
Catherine D Schuman, Shruti R Kulkarni, Maryam Parsa, J Parker Mitchell, Prasanna Date, and Bill Kay. Opportunities for neuromorphic computing algorithms and applications.Nature Computational Science, 2 (1):10–19, 2022
2022
-
[25]
Deeperforward: Enhanced forward-forward training for deeper and better performance
Liang Sun, Yang Zhang, Weizhao He, Jiajun Wen, Linlin Shen, and Weicheng Xie. Deeperforward: Enhanced forward-forward training for deeper and better performance. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
Avariento, Tomás J
Joaquín Torres-Sospedra, Raúl Montoliu, Adolfo Martínez-Usó, Joan P. Avariento, Tomás J. Arnau, Mauri Benedito-Bordonau, and Joaquín Huerta. UJIIndoorLoc: A new multi-building and multi-floor database for WLAN fingerprint-based indoor localization problems. In2014 International Conference on Indoor Positioning and Indoor Navigation (IPIN), pages 261–270. ...
2014
-
[27]
Convolutional channel-wise com- petitive learning for the forward-forward algorithm
Davide Tosato, Eugenio Daga, Giorgia Franchini, and Marco Prato. Convolutional channel-wise com- petitive learning for the forward-forward algorithm. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 15490–15498, 2024
2024
-
[28]
Empowering edge intelligence: A comprehensive survey on on-device ai models.ACM Computing Surveys, 57(9):1–39, 2025
Xubin Wang, Zhiqing Tang, Jianxiong Guo, Tianhui Meng, Chenhao Wang, Tian Wang, and Weijia Jia. Empowering edge intelligence: A comprehensive survey on on-device ai models.ACM Computing Surveys, 57(9):1–39, 2025
2025
-
[29]
James C. R. Whittington and Rafal Bogacz. An approximation of the error backpropagation algorithm in a predictive coding network with local Hebbian synaptic plasticity.Neural Computation, 29(5):1229–1262, 2017
2017
-
[30]
FF-INT8: Efficient forward-forward DNN training on edge devices with INT8 precision
Hanqiu Ye, Siddharth Bhatt, Prajwal Bhatt, and Arijit Raychowdhury. FF-INT8: Efficient forward-forward DNN training on edge devices with INT8 precision. InIEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pages 302–312, 2024
2024
-
[31]
Activity-difference training of deep neural networks using memristor crossbars.Nature Electronics, 6(1):45–51, 2023
Su-in Yi, Jack D Kendall, R Stanley Williams, and Suhas Kumar. Activity-difference training of deep neural networks using memristor crossbars.Nature Electronics, 6(1):45–51, 2023
2023
-
[32]
Stochastic forward-forward learning through representational dimensionality compression
Zhichao Zhu, YANG QI, Hengyuan Ma, Wenlian Lu, and Jianfeng Feng. Stochastic forward-forward learning through representational dimensionality compression. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 11 A Appendix This appendix provides supporting material for the main paper. Appendix A.1 reviews the biological- pla...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.