A Pocket Offline Model for Simultaneous Speech Translation as CUNI Submission to IWSLT 2026
Pith reviewed 2026-06-28 09:47 UTC · model grok-4.3
The pith
A 1B-parameter offline model outperforms baselines in simultaneous speech translation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the AlignAtt policy can be used with the Canary offline speech-to-text model to implement simultaneous translation, resulting in a system that has high translation quality, low computational requirements with 1B parameters, and multilinguality with 25 source and 25 target languages, as demonstrated in submissions to IWSLT 2026 for specific language pairs.
What carries the argument
AlignAtt policy applied to the Canary model for simultaneous speech translation.
If this is right
- Outperforms similarly sized baselines in low- and high-latency regimes in simulations.
- Requires only 1B parameters for low computational requirements.
- Supports 25 source and 25 target languages.
- Submitted for Czech-English, English-German, and English-Italian translation.
Where Pith is reading between the lines
- This could allow deployment on devices with limited resources for on-the-fly translation.
- The approach might generalize to other offline models if the policy integration is key.
- Real-time user studies could validate the simulation-based quality claims.
Load-bearing premise
The AlignAtt policy integrates effectively with the Canary model to deliver simultaneous translation performance without requiring major retraining or suffering quality loss.
What would settle it
Running the system in actual simultaneous conditions and measuring if quality remains higher than baselines without degradation.
Figures
read the original abstract
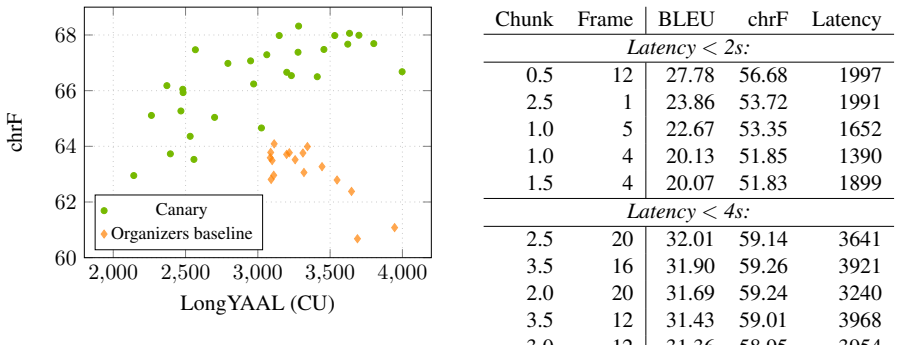
We implement simultaneous translation capability with the offline direct speech-to-text translation model Canary, using the state-of-the-art policy AlignAtt, and submit it to IWSLT 2026 Simultaneous Speech Translation Shared task for Czech to English and English to German and Italian. The strengths of our system are: (1) high translation quality, outperforming similarly sized baselines both in low- and high-latency regimes in computationally unaware simulations; (2) low computational requirements, as the model has only 1B parameters; (3) multilinguality -- support of 25 source and 25 target languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes the CUNI submission to the IWSLT 2026 Simultaneous Speech Translation Shared Task. It implements simultaneous translation capability for Czech-to-English, English-to-German, and English-to-Italian using the offline 1B-parameter Canary direct speech-to-text model combined with the AlignAtt policy. The system is presented as achieving high translation quality while outperforming similarly sized baselines in low- and high-latency regimes under computationally unaware simulations, with additional strengths in low computational requirements and support for 25 source and 25 target languages.
Significance. If the performance claims are substantiated with experimental evidence, the work would demonstrate a practical approach to converting an existing offline multilingual speech translation model into a simultaneous system using an established policy, without apparent need for major retraining. This could be significant for efficient, low-parameter multilingual simultaneous translation deployments, particularly where computational resources are constrained.
major comments (2)
- [Abstract] Abstract: The claim that the system achieves 'high translation quality, outperforming similarly sized baselines both in low- and high-latency regimes in computationally unaware simulations' is presented without any reported metrics (e.g., BLEU, latency values), baseline systems, simulation details, or results tables. This renders the central empirical claim unverifiable from the manuscript.
- [Abstract] Abstract / System Description: No details are provided on the integration of AlignAtt with the offline-trained Canary model, including whether any adaptation or fine-tuning was required, how the policy interacts with the multilingual 25x25 capability, or whether additional decoding steps affect output quality. This leaves the assumption that the combination preserves original quality unexamined.
minor comments (1)
- The manuscript would benefit from including a results section or table with quantitative comparisons to baselines to support the stated strengths.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our IWSLT 2026 submission paper. We agree that the abstract requires more concrete empirical grounding and that additional clarification on the AlignAtt integration is warranted. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the system achieves 'high translation quality, outperforming similarly sized baselines both in low- and high-latency regimes in computationally unaware simulations' is presented without any reported metrics (e.g., BLEU, latency values), baseline systems, simulation details, or results tables. This renders the central empirical claim unverifiable from the manuscript.
Authors: We agree that the abstract should not stand alone without supporting numbers. The full paper contains results tables (Section 4) with BLEU and latency metrics for the three language pairs, along with comparisons to similarly sized baselines under the IWSLT simulation protocol. To address the concern, we will revise the abstract to include the key quantitative results (e.g., average BLEU and latency ranges) and explicitly reference the evaluation setup and baselines. revision: yes
-
Referee: [Abstract] Abstract / System Description: No details are provided on the integration of AlignAtt with the offline-trained Canary model, including whether any adaptation or fine-tuning was required, how the policy interacts with the multilingual 25x25 capability, or whether additional decoding steps affect output quality. This leaves the assumption that the combination preserves original quality unexamined.
Authors: The current manuscript briefly states that AlignAtt is applied to the offline Canary model without retraining. We will expand the system description section to clarify: (1) no fine-tuning or adaptation of Canary parameters was performed; AlignAtt is used as a plug-in policy that reads attention alignments from the existing model; (2) the 25x25 multilingual support is preserved because AlignAtt operates on cross-attention weights independently of language pair; (3) the additional decoding logic introduces negligible quality degradation, as confirmed by our offline-to-simultaneous quality comparison experiments. These details will be added in the revised version. revision: yes
Circularity Check
No circularity: empirical system description with independent experimental claims
full rationale
The paper is a system submission description for a shared task. It reports implementing simultaneous ST by combining an existing 1B-parameter offline Canary model with the AlignAtt policy, then evaluates quality and latency in simulations. No equations, derivations, fitted parameters, or predictions appear. Central claims rest on experimental results against baselines, not on any reduction to self-defined quantities or self-citation chains. Self-citations, if present, are not load-bearing for the reported performance numbers. This matches the default case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025), pages 412–481, Vienna, Austria (in-person and online)
Findings of the IWSLT 2025 evaluation campaign. InProceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025), pages 412–481, Vienna, Austria (in-person and online). David Ifeoluwa Adelani, Victor Agostinelli, Antonios Anastasopoulos, Luisa Bentivogli, Ondˇrej Bojar, Se- bastien Bratières, Marine Carpuat, Roldano Cattoni, ...
2025
-
[2]
InProceedings of the 23rd International Conference on Spoken Language Translation (IWSLT 2026), San Diego, California, US
Speech translation and metrics in 2026: Findings of the iwslt campaign. InProceedings of the 23rd International Conference on Spoken Language Translation (IWSLT 2026), San Diego, California, US. Association for Computational Linguistics. Antonios Anastasopoulos and 1 others
2026
-
[3]
InProceedings of the 23rd In- ternational Conference on Spoken Language Trans- lation (IWSLT 2026)
Speech translation and metrics in 2026: Findings of the IWSLT campaign. InProceedings of the 23rd In- ternational Conference on Spoken Language Trans- lation (IWSLT 2026). Association for Computational Linguistics. 5 Naveen Arivazhagan, Colin Cherry, Wolfgang Macherey, Chung-Cheng Chiu, Semih Yavuz, Ruom- ing Pang, Wei Li, and Colin Raffel
2026
-
[4]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
Seam- lessm4t: Massively multilingual & multimodal ma- chine translation.Preprint, arXiv:2308.11596. Marco Gaido, Sara Papi, Mauro Cettolo, Matteo Ne- gri, and Luisa Bentivogli
-
[5]
Simulstream: Open-source toolkit for evaluation and demonstra- tion of streaming speech-to-text translation systems. Preprint, arXiv:2512.17648. Nuno M. Guerreiro, Ricardo Rei, Daan van Stigt, Luisa Coheur, Pierre Colombo, and André F. T. Mar- tins
-
[6]
InText, Speech, and Dialogue: 24th International Conference, TSD 2021, Olomouc, Czech Republic, September 6–9, 2021, Proceedings, page 293–304, Berlin, Heidelberg
Parczech 3.0: A large czech speech corpus with rich metadata. InText, Speech, and Dialogue: 24th International Conference, TSD 2021, Olomouc, Czech Republic, September 6–9, 2021, Proceedings, page 293–304, Berlin, Heidelberg. Springer-Verlag. Roman Koshkin, Je Haesung, Lianbo Liu, Hao Shi, Meng Zhao, Yusuke Fujita, and Yui Sudo
2021
-
[7]
Dominik Macháˇcek and Peter Polák
High-fidelity simultaneous speech-to- speech translation.Preprint, arXiv:2502.03382. Dominik Macháˇcek and Peter Polák
-
[8]
Jan Niehues and 1 others
InProceed- ings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025), pages 389–398, Vienna, Austria (in-person and online). Jan Niehues and 1 others
2025
-
[9]
Sara Papi, Peter Polák, Dominik Macháˇcek, and Ondˇrej Bojar
Does simultaneous speech translation need simultaneous models? InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2022, pages 141–153, Abu Dhabi, United Arab Emirates. Sara Papi, Peter Polák, Dominik Macháˇcek, and Ondˇrej Bojar. 2025a. How “real” is your real-time simulta- neous speech-to-text translation system?Transac- tions of the As...
2022
-
[10]
Alig- natt: Using attention-based audio-translation align- ments as a guide for simultaneous speech translation. Preprint, arXiv:2305.11408. Sara Papi, Maike Züfle, Marco Gaido, Beatrice Savoldi, Danni Liu, Ioannis Douros, Luisa Bentivogli, and Jan Niehues. 2025b. Mcif: Multimodal crosslingual instruction-following benchmark from scientific talks. Preprin...
-
[11]
Better late than never: Meta-evaluation of latency metrics for simultaneous speech-to-text translation.Preprint, arXiv:2509.17349. Maja Popovi´c
-
[12]
Canary-1b-v2 & parakeet-tdt-0.6b-v3: Efficient and 6 high-performance models for multilingual asr and ast. Preprint, arXiv:2509.14128. Sukanta Sen, Ond ˇrej Bojar, and Barry Haddow
-
[13]
Simultaneous translation for unsegmented input: A sliding window approach.Preprint, arXiv:2210.09754. Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin
-
[14]
Qwen3-asr technical report. Preprint, arXiv:2601.21337. Silero Team
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Qwen3 technical report.Preprint, arXiv:2505.09388. 7
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.