Demo2Tutorial: From Human Experience to Multimodal Software Tutorials
Pith reviewed 2026-06-28 10:31 UTC · model grok-4.3
The pith
A framework turns raw human screen recordings into multimodal tutorials that outperform human-authored versions for both people and agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
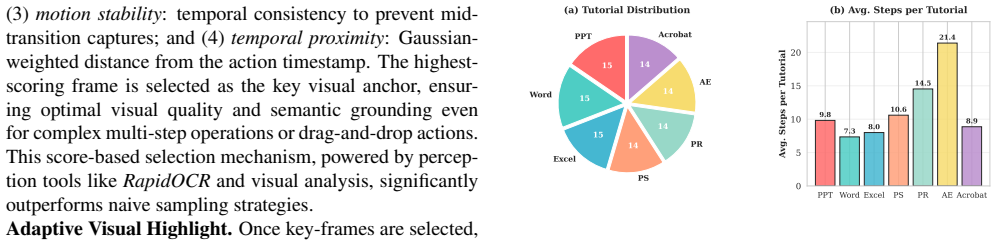
Demo2Tutorial shows that human experience captured in screen recordings and interaction logs contains rich procedural knowledge that a pipeline of multimodal parsing, hierarchical step planning, and tutorial composition can distill into image-text instructions superior to human-authored tutorials, with measurable gains in human task speed and agent planning generalization on a new benchmark derived from official software documentation.
What carries the argument
The multimodal Action Parser that reconstructs perception, action, and intent from raw screen recordings and logs to feed the Step Planner and Tutorial Composer.
If this is right
- Structured tutorials distilled from experience serve as effective knowledge representations that improve both human learning and agent capabilities.
- Automatic generation from recordings yields higher quality output than manual authoring from official documentation.
- The resulting instructions enable faster human task completion and better generalization in GUI agent planning.
- Hierarchical task graphs created by the Step Planner provide reusable abstractions that support downstream applications.
Where Pith is reading between the lines
- The same recording-to-tutorial process could be tested on non-desktop interfaces if the parser is adapted to new input formats.
- Agents that learn from these tutorials might show improved transfer to entirely new applications not seen in the original recordings.
- Combining the distilled tutorials with other training signals could be measured for further gains in agent robustness.
Load-bearing premise
The Action Parser can reliably extract accurate perception, action, and intent information from untrimmed recordings and logs.
What would settle it
On the benchmark, if the generated tutorials receive lower quality scores than human-authored ones or fail to produce faster human task times and higher agent success rates than baselines, the central claim would not hold.
Figures





















read the original abstract
Human experience in digital environments offers a vast, underexplored resource of authentic, untrimmed interactions that contain rich procedural knowledge. We introduce Demo2Tutorial, a framework that transforms this experience captured via screen recordings and interaction logs into structured, multimodal software tutorials for teaching both humans and agents. Demo2Tutorial first collects human experience via a dedicated recorder, then parses raw experience using a multimodal Action Parser to reconstruct perception, action, and intent. A Step Planner then abstracts these steps into hierarchical task graphs representing goals and steps. Finally, a Tutorial Composer transforms the parsed experience into structured, reusable image-text instructions. We evaluate the tutorial generation quality on a new benchmark derived from official software documentation. We further demonstrate that this distilled representation benefits (i) human learning, by automatically generating multimodal tutorials, and (ii) agent learning, by improving downstream GUI-agent planning and generalization. Experiments show Demo2Tutorial produces high-quality tutorials that surpass human-authored ones and significantly outperform baseline methods, while enabling both faster human task completion and improved GUI agent planning, demonstrating that structured tutorials distilled from human experience can serve as effective knowledge representations for advancing both human learning and agent capabilities. Code and data will be available at https://github.com/showlab/Demo2Tutorial.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Demo2Tutorial, a framework that converts human screen recordings and interaction logs into structured multimodal software tutorials. It uses a multimodal Action Parser to reconstruct perception/action/intent, a Step Planner to build hierarchical task graphs, and a Tutorial Composer to generate image-text instructions. The work evaluates tutorial quality on a new benchmark derived from official software documentation and claims the resulting tutorials surpass human-authored ones and baselines, while also improving human task completion and GUI-agent planning/generalization. Code and data release is promised.
Significance. If the superiority claims hold under rigorous evaluation, the framework offers a practical route to distilling reusable procedural knowledge from raw user demonstrations, with direct value for software training materials and for improving GUI-agent generalization. The modular pipeline and planned public release of code/data are explicit strengths that would support follow-on work.
major comments (2)
- [Abstract] Abstract: the central claim that 'Experiments show Demo2Tutorial produces high-quality tutorials that surpass human-authored ones and significantly outperform baseline methods' supplies no quantitative metrics, statistical tests, dataset sizes, or exclusion criteria, so the empirical superiority assertion cannot be assessed from the text.
- [Pipeline description (Action Parser)] Pipeline description (Action Parser stage): the framework's first component is asserted to reliably reconstruct perception, action, and intent, yet no section reports parser-level metrics (e.g., action-type precision, intent match rate, or error analysis) against human-annotated ground truth on the benchmark or held-out recordings; end-to-end tutorial and downstream-task results alone do not isolate whether parser errors undermine the claimed gains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments below. Both points highlight opportunities to strengthen the presentation of our empirical results, and we outline targeted revisions while preserving the core contributions of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experiments show Demo2Tutorial produces high-quality tutorials that surpass human-authored ones and significantly outperform baseline methods' supplies no quantitative metrics, statistical tests, dataset sizes, or exclusion criteria, so the empirical superiority assertion cannot be assessed from the text.
Authors: We agree that the abstract is intentionally high-level to remain concise. The detailed quantitative results—including tutorial quality scores (e.g., human preference rates and automatic metrics), human task completion times with statistical significance (p-values), agent planning success rates, dataset sizes (number of recordings and benchmark tasks), and evaluation protocols—are fully reported in Section 4 and the supplementary material. We will revise the abstract to incorporate one or two key quantitative highlights (e.g., “outperforming human-authored tutorials by X% on the benchmark”) while respecting length limits. revision: partial
-
Referee: [Pipeline description (Action Parser)] Pipeline description (Action Parser stage): the framework's first component is asserted to reliably reconstruct perception, action, and intent, yet no section reports parser-level metrics (e.g., action-type precision, intent match rate, or error analysis) against human-annotated ground truth on the benchmark or held-out recordings; end-to-end tutorial and downstream-task results alone do not isolate whether parser errors undermine the claimed gains.
Authors: The current manuscript evaluates the Action Parser only indirectly via end-to-end tutorial quality and downstream task performance. We acknowledge that explicit parser-level metrics would better isolate its contribution. In the revised version we will add a new subsection (in Section 3 or 4) reporting action-type precision/recall, intent match rate, and qualitative error analysis on a held-out set of human-annotated recordings. This addition will directly address the concern about potential parser errors. revision: yes
Circularity Check
No circularity; empirical framework evaluation is self-contained against external benchmarks
full rationale
The paper presents Demo2Tutorial as a multi-stage pipeline (Action Parser, Step Planner, Tutorial Composer) whose performance claims rest on experimental comparisons to human-authored tutorials and baselines on a new benchmark derived from official documentation. No equations, fitted parameters, or predictions appear in the provided text. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central results are end-to-end empirical outcomes rather than derivations that reduce to the same inputs by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal models can parse screen pixels and logs into accurate perception-action-intent triples.
invented entities (3)
-
Action Parser
no independent evidence
-
Step Planner
no independent evidence
-
Tutorial Composer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agent s2: A compositional generalist-specialist framework for computer use agents
Saaket Agashe, Kyle Wong, Vincent Tu, Jiachen Yang, Ang Li, and Xin Eric Wang. Agent s2: A compositional generalist-specialist framework for computer use agents. arXiv preprint arXiv:2504.00906, 2025. 3
Pith/arXiv arXiv 2025
-
[2]
Video-mined task graphs for keystep recognition in instructional videos
Kumar Ashutosh, Santhosh Kumar Ramakrishnan, Tri- antafyllos Afouras, and Kristen Grauman. Video-mined task graphs for keystep recognition in instructional videos. Advances in Neural Information Processing Systems, 36: 67833–67846, 2023. 1
2023
-
[3]
One token to seg them all: Language instructed reasoning segmentation in videos.Advances in Neural Information Processing Systems, 37:6833–6859, 2024
Zechen Bai, Tong He, Haiyang Mei, Pichao Wang, Ziteng Gao, Joya Chen, Lei Liu, Zheng Zhang, and Mike Z Shou. One token to seg them all: Language instructed reasoning segmentation in videos.Advances in Neural Information Processing Systems, 37:6833–6859, 2024. 2
2024
-
[4]
Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024. 2
Pith/arXiv arXiv 2024
-
[5]
Procedure planning in instructional videos
Chien-Yi Chang, De-An Huang, Danfei Xu, Ehsan Adeli, Li Fei-Fei, and Juan Carlos Niebles. Procedure planning in instructional videos. InEuropean Conference on Computer Vision, pages 334–350. Springer, 2020. 1
2020
-
[6]
Jiho Choi, Seojeong Park, Seongjong Song, and Hyun- jung Shim. Posterforest: Hierarchical multi-agent col- laboration for scientific poster generation.arXiv preprint arXiv:2508.21720, 2025. 2
Pith/arXiv arXiv 2025
-
[7]
Assistgui: Task-oriented pc graphical user interface automation
Difei Gao, Lei Ji, Zechen Bai, Mingyu Ouyang, Peiran Li, Dongxing Mao, Qinchen Wu, Weichen Zhang, Peiyi Wang, Xiangwu Guo, et al. Assistgui: Task-oriented pc graphical user interface automation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13289–13298, 2024. 2
2024
-
[8]
Autopresent: Design- ing structured visuals from scratch
Jiaxin Ge, Zora Zhiruo Wang, Xuhui Zhou, Yi-Hao Peng, Sanjay Subramanian, Qinyue Tan, Maarten Sap, Alane Suhr, Daniel Fried, Graham Neubig, et al. Autopresent: Design- ing structured visuals from scratch. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2902–2911, 2025. 2
2025
-
[9]
Gonzalo Gonzalez-Pumariega, Vincent Tu, Chih-Lun Lee, Jiachen Yang, Ang Li, and Xin Eric Wang. The unreason- able effectiveness of scaling agents for computer use.arXiv preprint arXiv:2510.02250, 2025. 2, 3, 7, 13
arXiv 2025
-
[10]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18995–19012, 2022. 1
2022
-
[11]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 193...
2024
-
[12]
Lawrence Jang, Yinheng Li, Dan Zhao, Charles Ding, Justin Lin, Paul Pu Liang, Rogerio Bonatti, and Kazuhito Koishida. Videowebarena: Evaluating long context multi- modal agents with video understanding web tasks.arXiv preprint arXiv:2410.19100, 2024. 3
arXiv 2024
-
[13]
Keshav Kumar and Ravindranath Chowdary. Slidespawn: An automatic slides generation system for research publica- tions.arXiv preprint arXiv:2411.17719, 2024. 2
arXiv 2024
-
[14]
Bridge-prompt: Towards or- dinal action understanding in instructional videos
Muheng Li, Lei Chen, Yueqi Duan, Zhilan Hu, Jianjiang Feng, Jie Zhou, and Jiwen Lu. Bridge-prompt: Towards or- dinal action understanding in instructional videos. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19880–19889, 2022. 1
2022
-
[15]
Showui: One vision-language-action model for gui visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19498– 19508, 2025. 2
2025
-
[16]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2
2023
-
[17]
Videoagenttrek: Computer use pretraining from unlabeled videos.arXiv preprint arXiv:2510.19488,
Dunjie Lu, Yiheng Xu, Junli Wang, Haoyuan Wu, Xinyuan Wang, Zekun Wang, Junlin Yang, Hongjin Su, Jixuan Chen, Junda Chen, et al. Videoagenttrek: Computer use pretraining from unlabeled videos.arXiv preprint arXiv:2510.19488,
-
[18]
Learning to ground instructional articles in videos through narrations
Effrosyni Mavroudi, Triantafyllos Afouras, and Lorenzo Torresani. Learning to ground instructional articles in videos through narrations. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 15201–15213,
-
[19]
Why not use your text- book? knowledge-enhanced procedure planning of instruc- tional videos
Kumaranage Ravindu Yasas Nagasinghe, Honglu Zhou, Malitha Gunawardhana, Martin Renqiang Min, Daniel Harari, and Muhammad Haris Khan. Why not use your text- book? knowledge-enhanced procedure planning of instruc- tional videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18816– 18826, 2024. 1
2024
-
[20]
Wei Pang, Kevin Qinghong Lin, Xiangru Jian, Xi He, and Philip Torr. Paper2poster: Towards multimodal poster automation from scientific papers.arXiv preprint arXiv:2505.21497, 2025. 2
arXiv 2025
-
[21]
Ui-tars: Pioneering automated gui inter- action with native agents.arXiv preprint arXiv:2501.12326,
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shi- jue Huang, et al. Ui-tars: Pioneering automated gui inter- action with native agents.arXiv preprint arXiv:2501.12326,
-
[22]
Learning from demonstration.Advances in neural information processing systems, 9, 1996
Stefan Schaal. Learning from demonstration.Advances in neural information processing systems, 9, 1996. 1
1996
-
[23]
What does clip know about a red circle? vi- sual prompt engineering for vlms
Aleksandar Shtedritski, Christian Rupprecht, and Andrea Vedaldi. What does clip know about a red circle? vi- sual prompt engineering for vlms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11987–11997, 2023. 4
2023
-
[24]
Coact-1: Computer-using agents with coding as actions.arXiv preprint arXiv:2508.03923, 2025
Linxin Song, Yutong Dai, Viraj Prabhu, Jieyu Zhang, Taiwei Shi, Li Li, Junnan Li, Silvio Savarese, Zeyuan Chen, Jieyu Zhao, et al. Coact-1: Computer-using agents with coding as actions.arXiv preprint arXiv:2508.03923, 2025. 3
arXiv 2025
-
[25]
Edward Sun, Yufang Hou, Dakuo Wang, Yunfeng Zhang, and Nancy XR Wang. D2s: Document-to-slide genera- tion via query-based text summarization.arXiv preprint arXiv:2105.03664, 2021. 2
arXiv 2021
-
[26]
Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shi- hao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning. arXiv preprint arXiv:2509.02544, 2025. 2
Pith/arXiv arXiv 2025
-
[27]
Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123,
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, et al. Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123,
-
[28]
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024. 2
Pith/arXiv arXiv 2024
-
[29]
Osworld: Benchmark- ing multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmark- ing multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024. 2, 7, 13
2024
-
[30]
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023. 4
Pith/arXiv arXiv 2023
-
[31]
Gta1: Gui test-time scaling agent.arXiv preprint arXiv:2507.05791, 2025
Yan Yang, Dongxu Li, Yutong Dai, Yuhao Yang, Ziyang Luo, Zirui Zhao, Zhiyuan Hu, Junzhe Huang, Amrita Saha, Zeyuan Chen, et al. Gta1: Gui test-time scaling agent.arXiv preprint arXiv:2507.05791, 2025. 3
Pith/arXiv arXiv 2025
-
[32]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022. 3
2022
-
[33]
Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025
Kai Zhang, Xiangchao Chen, Bo Liu, Tianci Xue, Zeyi Liao, Zhihan Liu, Xiyao Wang, Yuting Ning, Zhaorun Chen, Xi- aohan Fu, et al. Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025. 1
Pith/arXiv arXiv 2025
-
[34]
Zhilin Zhang, Xiang Zhang, Jiaqi Wei, Yiwei Xu, and Chenyu You. Postergen: Aesthetic-aware paper-to- poster generation via multi-agent llms.arXiv preprint arXiv:2508.17188, 2025. 2
Pith/arXiv arXiv 2025
-
[35]
Pptagent: Generating and evaluating pre- sentations beyond text-to-slides
Hao Zheng, Xinyan Guan, Hao Kong, Wenkai Zhang, Jia Zheng, Weixiang Zhou, Hongyu Lin, Yaojie Lu, Xianpei Han, and Le Sun. Pptagent: Generating and evaluating pre- sentations beyond text-to-slides. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Pro- cessing, pages 14413–14429, 2025. 2
2025
-
[36]
Learning procedure-aware video represen- tation from instructional videos and their narrations
Yiwu Zhong, Licheng Yu, Yang Bai, Shangwen Li, Xueting Yan, and Yin Li. Learning procedure-aware video represen- tation from instructional videos and their narrations. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14825–14835, 2023. 1 A. More Analysis A.1. Compression Analysis Essentially, the Demo2Tutorial p...
2023
-
[37]
Step 1.1: Click on the 'Layout' tab in the main toolbar
Access the Columns Settings How to set up columns in a Word document. Step 1.1: Click on the 'Layout' tab in the main toolbar. Step 1.2: Click on the 'Columns' dropdown in the 'Layout' tab. Step 1.3: Select the 'More Columns... ' option in the 'Columns' dropdown menu
-
[38]
Figure 9
Configure Column Settings Step 2.1: Double-click to select the 'Three' column preset and then click 'OK' to apply the changes. Figure 9. Example of Word tutorial
-
[39]
Access the Data Tab and Filter Options
-
[40]
Step 1.2: Click the filter dropdown arrow on cell A1
Set the Custom Filter Criteria How to apply a custom filter in Excel to display values greater than a specified number. Step 1.2: Click the filter dropdown arrow on cell A1. Step 1.3: Click on 'Number Filters' within the filter dropdown for column A. Step 2.1: Click on the 'Greater Than...' option in the 'Number Filters' menu. Step 2.2: Type '400' in the ...
-
[41]
Access the Slide Master view. 2. Select a font for the Slide Master. How to customize the Slide Master in PowerPoint. Step 2.1: Click on the 'Fonts' dropdown to view and select different font styles.Step 1.1: Click on the 'View' tab in the main menu bar. Step 1.2: Click on the 'Slide Master' button in the View tab
-
[42]
Step 3.1: Click on the 'Themes' button in the Slide Master tab
Apply a theme to the Slide Master. Step 3.1: Click on the 'Themes' button in the Slide Master tab. Step 2.2: Click on a font option in the dropdown menu to apply it. Step 3.2: Click on the 'Facet' theme thumbnail in the theme selection dropdown to apply it
-
[43]
Step 4.1: Click on 'Close Master View' in the Slide Master tab to return to normal editing mode
Exit the Slide Master view. Step 4.1: Click on 'Close Master View' in the Slide Master tab to return to normal editing mode. Figure 11. Example of PowerPoint tutorial. Step 1.1: Click on the 'Export PDF' option in the right-side panel. Step 1.2: Click on the settings icon next to the 'Microsoft Word' option. Step 2.1: Select the 'Retain Page Layout' optio...
-
[44]
Select the export format
-
[45]
Configure export settings
-
[46]
Figure 12
Export the document How to export a PDF document to Microsoft Word format in Adobe Acrobat Pro. Figure 12. Example of Acrobat tutorial
-
[47]
Step 2.1: Drag the 'Warp Stabilizer' effect onto the video clip in the timeline to apply it
Expand the Effects Panel and Locate the Warp Stabilizer Effect How to apply and configure the Warp Stabilizer effect in Premiere Pro. Step 2.1: Drag the 'Warp Stabilizer' effect onto the video clip in the timeline to apply it. Step 1.1: Click on the 'Effects' panel to expand it, then scroll down to locate the 'Video Effects' category, and click the 'Disto...
-
[48]
Example of Premiere Pro tutorial
Apply and Configure the Warp Stabilizer Effect Figure 13. Example of Premiere Pro tutorial
-
[49]
Step 1.1: Click on the Magic Wand Tool in the toolbar
Select the Magic Wand Tool How to apply a gradient background to an image in Photoshop. Step 1.1: Click on the Magic Wand Tool in the toolbar. Step 2.1: Click and drag using the selection tool to create a rectangular selection around the image area
-
[50]
Open the Gradients Panel Step 3.1: Click on the Gradients tab to open the panel for gradient options
Create a Selection 3. Open the Gradients Panel Step 3.1: Click on the Gradients tab to open the panel for gradient options
-
[51]
Figure 14
Apply a Gradient to the Background Step 4.1: Click on a gradient option to apply it to the background. Figure 14. Example of Photoshop tutorial. Step 1.1: Click the '+' button next to the existing worksheet tab to add a new sheet. Step 2.1: Click on the 'Insert' dropdown menu and select 'Insert Sheet' to add a new worksheet. Step 2.2: Right-click on the w...
-
[52]
Add a new worksheet using the '+' button. 2. Add a new worksheet using the 'Insert' option. How to add new sheets in Excel. Figure 15. Example of failed Excel tutorial. The original video demonstration including both how to insert and delete a worksheet in Excel, but the generated tutorial only contains the instruction of inserting a worksheet. Step 1.1: ...
-
[53]
Click the Save button
Select the Fade transition 2. Preview the transition How to apply a Fade transition to a slide in PowerPoint. Figure 16. Example of failed PPT tutorial. The agent underlying MLLM fails to correctly recognize the action area and misinterprets the Morph animation as a Fade animation. system_prompt: |You are an expert evalu ator for tu torial qu ality. You r...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.