Building The Ph(ysical)AI Layer Of Machine Intelligence
Pith reviewed 2026-06-28 10:34 UTC · model grok-4.3
The pith
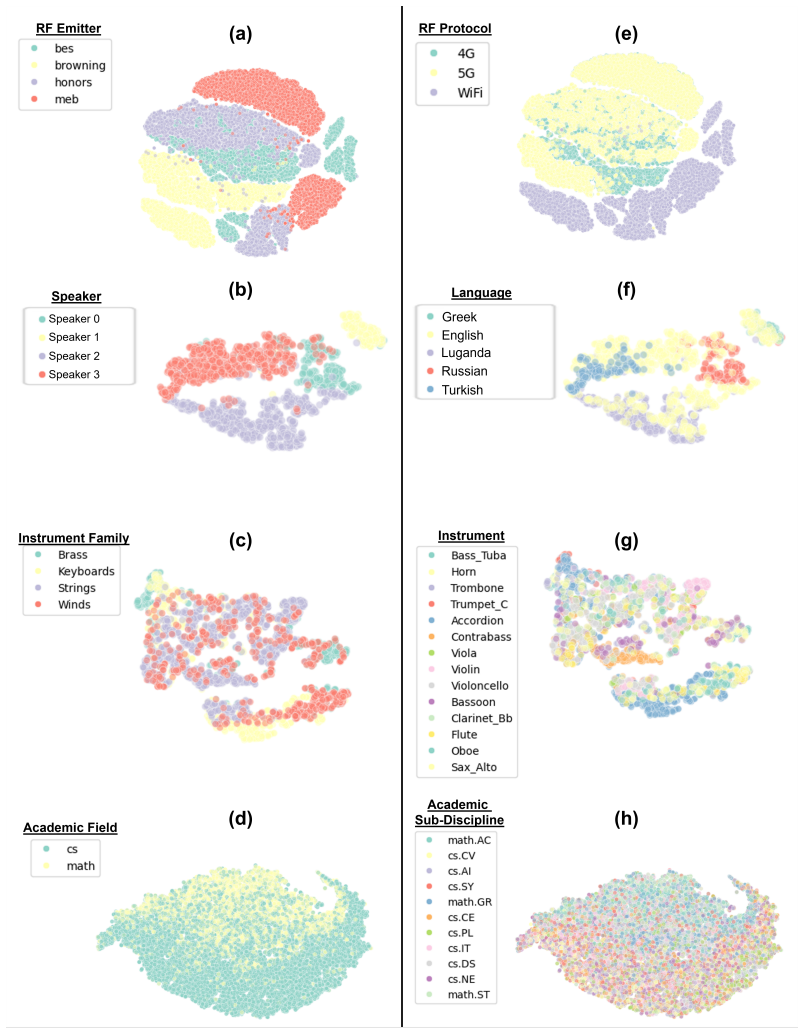
A model trained only on radio-frequency data with embedded physical principles transfers to audio, images, text, and video using a frozen encoder and linear probes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
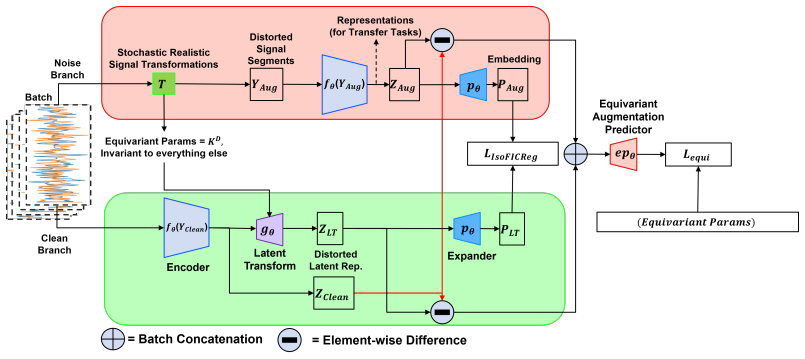
Training exclusively on radio-frequency data with an architecture and losses that incorporate Fourier decomposition, energy conservation, and symmetry produces representations that transfer to audio, images, text, and video domains using only a frozen encoder and linear probing, without any fine-tuning on the target domains.
What carries the argument
The principle-driven RF encoder that embeds Fourier decomposition, energy conservation, and symmetry to support learnable transformations across modalities.
Load-bearing premise
Domains differ not in fundamental physics but in learnable transformations in time, frequency, magnitude, or phase.
What would settle it
If linear probes applied to the frozen RF encoder yield accuracy no better than chance on a new modality such as video classification, the cross-modal transfer result would not hold.
Figures






read the original abstract
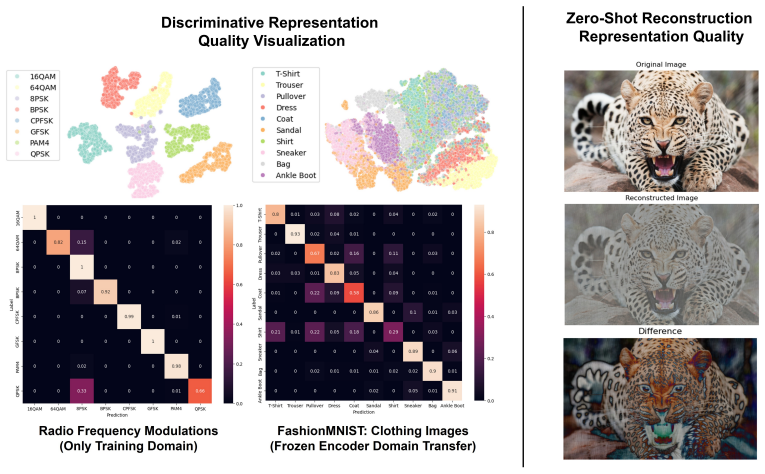
Foundation models achieve generalization through massive-scale training on diverse data, but have limitations with transfer to truly unseen domains without paired training data. We propose principle-driven foundation models that encode signal-theoretic principles (Fourier decomposition, energy conservation, symmetry) rather than learn untethered statistical correlations. We hypothesize that domains differ not in fundamental physics, but in learnable transformations in time, frequency, magnitude, or phase. Training exclusively on radio-frequency (RF) data with co-designed architecture and losses incorporating these principles, we achieve cross-modal transfer to audio, images, text, and video using only frozen representations learned from RF data, requiring no fine-tuning of the encoder on target domains. Our 1.99M parameter frozen encoder achieves 77.7% average accuracy (91.9% top-3) across 15 diverse tasks via linear probing, with systematic variation: 84.5 on physically-grounded tasks (speaker recognition, seismology, RF fingerprinting) versus 70.0% on semantic tasks (music genre, language recognition). This reveals that principle-driven and scale-driven approaches offer complementary paths: physical principles enable efficient cross-modal transfer while naturally establishing the boundary between physical and semantic understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes principle-driven foundation models that encode signal-theoretic principles (Fourier decomposition, energy conservation, symmetry) rather than untethered statistical correlations. Training a 1.99M-parameter encoder exclusively on radio-frequency (RF) data with co-designed architecture and losses, the authors claim cross-modal transfer to audio, images, text, and video using only frozen RF representations (no encoder fine-tuning on target domains). They report 77.7% average accuracy (91.9% top-3) across 15 tasks via linear probing, with 84.5% on physically-grounded tasks versus 70.0% on semantic tasks, arguing this reveals complementary physical-principle and scale-driven paths.
Significance. If the central claim holds, the work would demonstrate that embedding physical principles enables efficient cross-modal generalization from a single small-scale modality (RF) without paired data or fine-tuning, while naturally separating physical from semantic understanding. The small parameter count, explicit accuracies, and systematic task variation are concrete strengths that could be reproduced and tested.
major comments (2)
- [Abstract / Methods] Abstract and methods (input mapping description): the central claim that representations are 'only frozen representations learned from RF data' with 'no fine-tuning of the encoder on target domains' is load-bearing. The required cross-modal input transformations (time/frequency/magnitude/phase mappings) must be shown to derive exclusively from RF pretraining or physics-only rules; any hand-crafted or target-tuned component would violate the 'RF-only' condition and the hypothesis that domains differ only in learnable transformations.
- [Results] Results section (task breakdown and ablations): the reported 77.7% average and the 84.5% vs 70.0% split between physical and semantic tasks support the boundary claim only if ablations isolate the contribution of each principle (Fourier, energy conservation, symmetry) and confirm that linear-probe performance does not rely on modality-specific preprocessing that leaks target-domain information.
minor comments (2)
- [Abstract] Abstract: the parenthetical 'Ph(ysical)AI' is informal; expand or remove for a formal journal submission.
- [Results] The 15 tasks and exact linear-probe protocol should be enumerated with references to standard benchmarks to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below with clarifications drawn directly from the manuscript's methodology and commit to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods (input mapping description): the central claim that representations are 'only frozen representations learned from RF data' with 'no fine-tuning of the encoder on target domains' is load-bearing. The required cross-modal input transformations (time/frequency/magnitude/phase mappings) must be shown to derive exclusively from RF pretraining or physics-only rules; any hand-crafted or target-tuned component would violate the 'RF-only' condition and the hypothesis that domains differ only in learnable transformations.
Authors: The transformations are derived from the signal-theoretic principles (Fourier decomposition, energy conservation, symmetry) encoded in the co-designed architecture and losses during exclusive RF pretraining. These are universal physics rules applied uniformly rather than modality-specific or target-tuned components. We will revise the methods section to include an explicit derivation and pseudocode showing that the mappings follow fixed RF-physics rules with no per-target adjustment, thereby reinforcing that the encoder remains strictly frozen and RF-only. revision: partial
-
Referee: [Results] Results section (task breakdown and ablations): the reported 77.7% average and the 84.5% vs 70.0% split between physical and semantic tasks support the boundary claim only if ablations isolate the contribution of each principle (Fourier, energy conservation, symmetry) and confirm that linear-probe performance does not rely on modality-specific preprocessing that leaks target-domain information.
Authors: We agree that explicit ablations isolating each principle's contribution would provide stronger support for the boundary claim. The manuscript already reports the physical-versus-semantic performance gap as evidence of complementary understanding, but we will add the requested ablation studies and preprocessing-consistency analysis in the revised results section to confirm that no target-domain information is leaked and that performance derives from the RF-learned principles. revision: yes
Circularity Check
Empirical performance result with no derivation chain reducing to inputs
full rationale
The paper reports a measured outcome: training a 1.99M-parameter encoder exclusively on RF data with co-designed architecture and losses, then obtaining 77.7% average accuracy via linear probing on 15 tasks across audio/images/text/video without encoder fine-tuning. No equations, uniqueness theorems, or fitted-parameter renamings are presented that equate any claimed prediction to its own inputs by construction. The hypothesis that domains differ only in learnable time/frequency/magnitude/phase transformations is stated as an assumption but is not invoked to force the reported accuracies; the result remains an external benchmark measurement rather than a self-referential identity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domains differ not in fundamental physics, but in learnable transformations in time, frequency, magnitude, or phase.
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[2]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15180–15190, 2023
2023
-
[3]
Data determines distributional robustness in contrastive language image pre-training (clip)
Alex Fang, Gabriel Ilharco, Mitchell Wortsman, Yuhao Wan, Vaishaal Shankar, Achal Dave, and Ludwig Schmidt. Data determines distributional robustness in contrastive language image pre-training (clip). InInternational conference on machine learning, pages 6216–6234. PMLR, 2022
2022
-
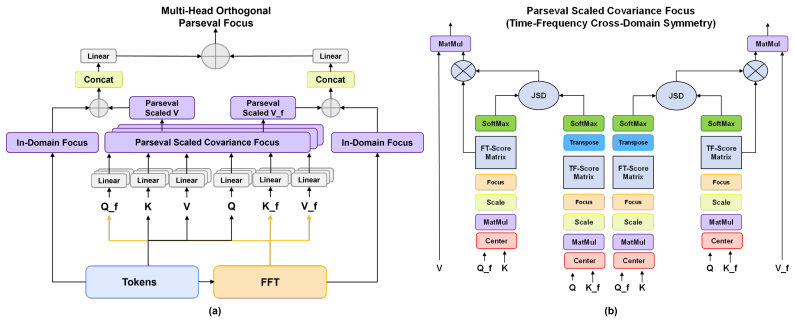
[4]
Accuracy on the line: on the strong correlation between out-of-distribution and in-distribution generalization
John P Miller, Rohan Taori, Aditi Raghunathan, Shiori Sagawa, Pang Wei Koh, Vaishaal Shankar, Percy Liang, Yair Carmon, and Ludwig Schmidt. Accuracy on the line: on the strong correlation between out-of-distribution and in-distribution generalization. InInternational conference on machine learning, pages 7721–7735. PMLR, 2021
2021
-
[5]
Measuring robustness to natural distribution shifts in image classification.Advances in Neural Information Processing Systems, 33:18583–18599, 2020
Rohan Taori, Achal Dave, Vaishaal Shankar, Nicholas Carlini, Benjamin Recht, and Ludwig Schmidt. Measuring robustness to natural distribution shifts in image classification.Advances in Neural Information Processing Systems, 33:18583–18599, 2020
2020
-
[6]
Shuman, Sunil K
David I. Shuman, Sunil K. Narang, Pascal Frossard, Antonio Ortega, and Pierre Vandergheynst. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains.IEEE Signal Processing Magazine, 30(3):83–98, 2013. 10
2013
-
[7]
Karniadakis
Maziar Raissi, Paris Perdikaris, and George E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019
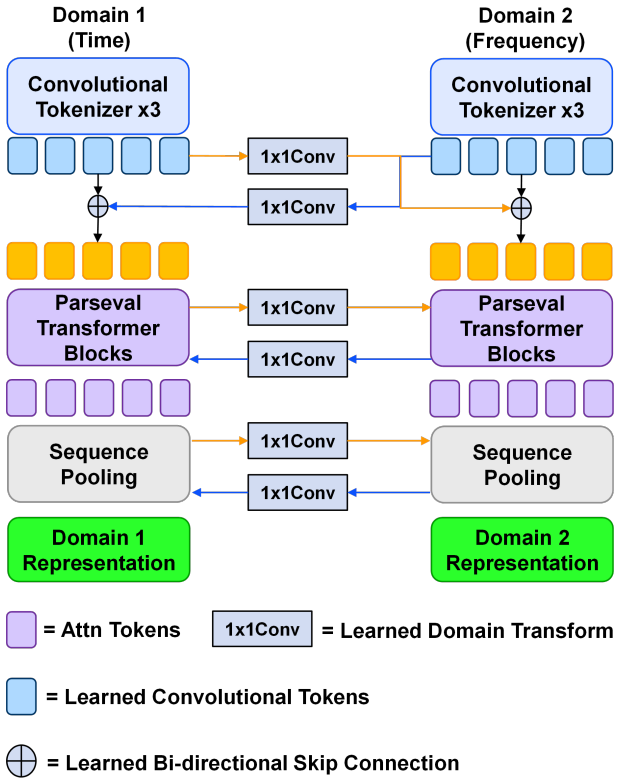
2019
-
[8]
Fourier neural operator for parametric partial differen- tial equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations. InInternational Conference on Learning Representations, 2021
2021
-
[9]
Group equivariant convolutional networks
Taco Cohen and Max Welling. Group equivariant convolutional networks. InProceedings of the 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 2990–2999. PMLR, 2016
2016
-
[10]
General e(2)-equivariant steerable cnns
Maurice Weiler and Gabriele Cesa. General e(2)-equivariant steerable cnns. InAdvances in Neural Information Processing Systems 32 (NeurIPS 2019), pages 14357–14368, 2019
2019
-
[11]
Self- supervised transformation learning for equivariant representations, 2025
Jaemyung Yu, Jaehyun Choi, Dong-Jae Lee, HyeongGwon Hong, and Junmo Kim. Self- supervised transformation learning for equivariant representations, 2025
2025
-
[12]
Quentin Garrido, Laurent Najman, and Yann Lecun. Self-supervised learning of split invariant equivariant representations.arXiv preprint arXiv:2302.10283, 2023
-
[13]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[14]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 1597–1607. PMLR, 2020
2020
-
[15]
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
Adrien Bardes, Jean Ponce, and Yann LeCun. Vicreg: Variance-invariance-covariance regular- ization for self-supervised learning.arXiv preprint arXiv:2105.04906, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
McGraw-Hill, New York, 2005
Mark A Richards.Fundamentals of Radar Signal Processing. McGraw-Hill, New York, 2005
2005
-
[17]
FNet: Mixing tokens with Fourier transforms
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, and Santiago Ontanon. FNet: Mixing tokens with Fourier transforms. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4296–4313, Seattle, United States, July 2022. Association for Computational Linguistics
2022
-
[18]
Self-supervised contrastive pre-training for time series via time-frequency consistency.Advances in neural information processing systems, 35:3988–4003, 2022
Xiang Zhang, Ziyuan Zhao, Theodoros Tsiligkaridis, and Marinka Zitnik. Self-supervised contrastive pre-training for time series via time-frequency consistency.Advances in neural information processing systems, 35:3988–4003, 2022
2022
-
[19]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 5301–
-
[20]
PMLR, 09–15 Jun 2019
2019
-
[21]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023
2023
-
[22]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[23]
Bendat and Allan G
Julius S. Bendat and Allan G. Piersol.The Hilbert Transform, chapter 13, pages 473–503. Wiley, Hoboken, NJ, USA, 2010
2010
-
[24]
Mémoire sur les séries et sur l’intégration complète d’une équation aux différences partielles linéaire du second ordre, à coefficients constants.Paris, 1799
Marc-Antoine Parseval des Chênes. Mémoire sur les séries et sur l’intégration complète d’une équation aux différences partielles linéaire du second ordre, à coefficients constants.Paris, 1799
-
[25]
Differential transformer.arXiv preprint arXiv:2410.05258, 2024
Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, and Furu Wei. Differential transformer.arXiv preprint arXiv:2410.05258, 2024. 11
-
[26]
Escaping the big data paradigm with compact transformers.arXiv preprint arXiv:2104.05704, 2021
Ali Hassani, Steven Walton, Nikhil Shah, Abulikemu Abuduweili, Jiachen Li, and Humphrey Shi. Escaping the big data paradigm with compact transformers.arXiv preprint arXiv:2104.05704, 2021
-
[27]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[28]
Film: Visual reasoning with a general conditioning layer, 2017
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer, 2017
2017
-
[29]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InProceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
2017
-
[30]
Kunal Sankhe, Mauro Belgiovine, Fan Zhou, Luca Angioloni, Frank Restuccia, Salvatore D’Oro, Tommaso Melodia, Stratis Ioannidis, and Kaushik Chowdhury. No radio left behind: Radio fingerprinting through deep learning of physical-layer hardware impairments.IEEE Transactions on Cognitive Communications and Networking, 6(1):165–178, 2019
2019
-
[31]
Trust in 5g open rans through machine learning: Rf fingerprinting on the powder pawr platform
Guillem Reus-Muns, Dheryta Jaisinghani, Kunal Sankhe, and Kaushik R Chowdhury. Trust in 5g open rans through machine learning: Rf fingerprinting on the powder pawr platform. In GLOBECOM 2020-2020 IEEE Global Communications Conference, pages 1–6. IEEE, 2020
2020
-
[32]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9729–9738, 2020
2020
-
[33]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Aref Farhadipour, Jan Marquenie, Srikanth Madikeri, and Eleanor Chodroff. Tidyvoice: A curated multilingual dataset for speaker verification derived from common voice.arXiv preprint arXiv:2601.16358, 2026
-
[35]
Tinysol: an audio dataset of isolated musical notes, January 2020
Carmine-Emanuele Cella, Daniele Ghisi, Vincent Lostanlen, Fabien Lévy, Joshua Fineberg, and Yan Maresz. Tinysol: an audio dataset of isolated musical notes, January 2020
2020
-
[36]
Musical genre classification of audio signals.IEEE Transactions on Audio and Speech Processing, 10(5):293–302, 2002
George Tzanetakis and Perry Cook. Musical genre classification of audio signals.IEEE Transactions on Audio and Speech Processing, 10(5):293–302, 2002
2002
-
[37]
Southern california seismic network, 1926
California Institute of Technology (Caltech) and United States Geological Survey (USGS). Southern california seismic network, 1926
1926
-
[38]
Southern california earthquake data center, 2013
Southern California Earthquake Data Center. Southern california earthquake data center, 2013
2013
-
[39]
Long document classification from local word glimpses via recurrent attention learning.IEEE Access, 7:40707–40718, 2019
Jun He, Liqun Wang, Liu Liu, Jiao Feng, and Hao Wu. Long document classification from local word glimpses via recurrent attention learning.IEEE Access, 7:40707–40718, 2019
2019
-
[40]
Mnist handwritten digit database, 2010
Yann LeCun, Corinna Cortes, Chris Burges, et al. Mnist handwritten digit database, 2010
2010
-
[41]
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017
2017
-
[42]
Fashion-mnist github repository and benchmark leaderboard
Zalando Research. Fashion-mnist github repository and benchmark leaderboard. https: //github.com/zalandoresearch/fashion-mnist, 2017. Accessed: 2024-05-22
2017
-
[43]
Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification.Scientific Data, 10(1):41, 2023
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification.Scientific Data, 10(1):41, 2023
2023
-
[44]
Bird and Ahmad Lotfi
Jordan J. Bird and Ahmad Lotfi. Cifake: Image classification and explainable identification of ai-generated synthetic images, 2023. 12
2023
-
[45]
Automatic classification of normal and abnormal cell division using deep learning.Scientific Reports, 14(1):14241, 2024
Pablo Delgado-Rodriguez, Rodrigo Morales Sánchez, Elouan Rouméas-Noël, François Paris, and Arrate Munoz-Barrutia. Automatic classification of normal and abnormal cell division using deep learning.Scientific Reports, 14(1):14241, 2024
2024
-
[46]
Milone, and Enzo Ferrante
Pablo Delgado, Nicolas Gaggion, Lucas Mansilla, Diego H. Milone, and Enzo Ferrante. Mitosis Classification, 6 2023
2023
-
[47]
Openclip, July 2021
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Openclip, July 2021
2021
-
[48]
Tyers, Ingo Siegert, and Eleanor Chodroff
Aref Farhadipour, Jan Marquenie, Srikanth Madikeri, Teodora Vukovic, V olker Dellwo, Kathy Reid, Francis M. Tyers, Ingo Siegert, and Eleanor Chodroff. Tidyvoice 2026 challenge evalua- tion plan, 2026
2026
-
[49]
Gtzan dataset - music genre classification, 2020
Andrada Olteanu. Gtzan dataset - music genre classification, 2020
2020
-
[50]
Noise2void-learning denoising from single noisy images
Alexander Krull, Tim-Oliver Buchholz, and Florian Jug. Noise2void-learning denoising from single noisy images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2129–2137, 2019
2019
-
[51]
Claude E. Shannon. Communication in the presence of noise.Proceedings of the IRE, 37(1):10– 21, 1949
1949
-
[52]
Making convolutional networks shift-invariant again
Richard Zhang. Making convolutional networks shift-invariant again. InInternational confer- ence on machine learning, pages 7324–7334. PMLR, 2019
2019
-
[53]
Efficient channel- temporal attention for boosting rf fingerprinting.IEEE Open Journal of Signal Processing, 5:478–492, 2024
Hanqing Gu, Lisheng Su, Yuxia Wang, Weifeng Zhang, and Chuan Ran. Efficient channel- temporal attention for boosting rf fingerprinting.IEEE Open Journal of Signal Processing, 5:478–492, 2024
2024
-
[54]
Transformers without normalization
Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, and Zhuang Liu. Transformers without normalization. InProceedings of the computer vision and pattern recognition conference, pages 14901–14911, 2025
2025
-
[55]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations (ICLR), 2015
2015
-
[56]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.arXiv preprint arXiv:2205.14135, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[57]
Pedregosa and et al
F. Pedregosa and et al. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[58]
Probabilistic outputs for support vector machines and comparisons to regular- ized likelihood methods
John Platt. Probabilistic outputs for support vector machines and comparisons to regular- ized likelihood methods. InAdvances in large margin classifiers, volume 10, pages 61–74. Cambridge, MA, 1999
1999
-
[59]
jameslyons/python_speech_features: release v0.6.1, January 2020
James Lyons et al. jameslyons/python_speech_features: release v0.6.1, January 2020
2020
-
[60]
How well do self-supervised models transfer? InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5414–5423, 2021
Linus Ericsson, Henry Gouk, and Timothy M Hospedales. How well do self-supervised models transfer? InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5414–5423, 2021. A Appendix A: Encoder Architecture A.1 Planformer Encoder Architecture Overview: The PlanFormer encoder is designed to embed signal-theoretic principl...
2021
-
[61]
Parseval Transformer blocks- Physics-informed attention mechanisms that we term "Focus" based on our dynamic attention sharpening machinery
-
[62]
This enables seamless extension of our architecture originally developed for complex valued domains to real valued domains
Attentional pooling- Fixed-size latent representations per domain via pooling over variable token sequence lengths Key architectural parameters: •Input length:5120 total samples (minimum), 1024 samples per window, 5 windows total •Embedding dimension:128 after IQ interleaving for complex tokenization •Number of transformer blocks:1 •Number of attention he...
2048
-
[63]
A feature learned at position t in one window transfers to positiontin other windows, reducing redundancy and parameter requirements
Translational equivariance:Convolution’s translational equivariance property minimizes the need for overlapping windows. A feature learned at position t in one window transfers to positiontin other windows, reducing redundancy and parameter requirements
-
[64]
By processing windows of length W , attention cost per window is O(W 2), and total cost across Nw =N/W windows is O(Nw ·W 2) =O(N·W) —linear in sequence length
Computational efficiency:Attention mechanisms scale quadratically with sequence length (O(N 2)). By processing windows of length W , attention cost per window is O(W 2), and total cost across Nw =N/W windows is O(Nw ·W 2) =O(N·W) —linear in sequence length. ForW≪N, this provides substantial savings
-
[65]
Reconstruction efficiency:In the decoder, operating on windowed representations enables localized reconstruction with manageable memory footprints, particularly important for long sequences (N >10,000). Addressing Long-Range Dependencies:The primary drawback of windowed processing is that convolutions operate in isolation within each window, potentially m...
-
[66]
Domain-specific positional encodings enable the network to learn causal phase relationships (time domain) and time-varying spectral evolution (frequency domain)
Causal Cross-Window Focus(Section A.4.2.3): Explicit attention between consecutive windows’ tokenized representations models inter-window dependencies. Domain-specific positional encodings enable the network to learn causal phase relationships (time domain) and time-varying spectral evolution (frequency domain)
-
[67]
This captures long-range dependencies that span multiple windows while maintaining the benefits of localized spectral analysis
Parseval Transformer(Section A.6): After tokenization, all window tokens are processed jointly through transformer blocks, enabling global attention across the entire sequence. This captures long-range dependencies that span multiple windows while maintaining the benefits of localized spectral analysis. In summary, windowed processing provides the best of...
-
[68]
We reshape the frequency-domain representation [B, F, T] (where F represents frequency bins) into token format [B, T /2,2F] where each token encodes a complex-valued frequency representation
-
[69]
We apply a learned11 convolution with stride s in token space, which effectively learns to compress the frequency spectrum by selecting which frequency bins to preserve before downsampling
-
[70]
when the 100 Hz component is strong in the previous window, the 200 Hz component tends to be strong in the current window,
For time-domain processing, we convert back via IFFT, ensuring the temporal signal has reduced bandwidth appropriate for the lower sampling rate. This approach implements a learned, adaptive low-pass filter in the frequency domain, preventing aliasing while preserving task-relevant spectral components. T↓ =Conv (b) 1×1,s(T)∈R B×Ndown×(2C) (22) whereN down...
-
[71]
Causality:Information flows strictly from past to present, enabling online/streaming processing
-
[72]
Efficiency:We avoid the O(L2) complexity of full-sequence self-focus, instead computing O((L/s)2)focus within compressed windows
-
[73]
Interpretability:focus weights reveal how the model uses past context to inform current predictions, facilitating analysis of learned temporal dependencies. A.4.2.4 Spectral Compression Via Frequency Domain PoolingPooling operations are ubiq- uitous in modern deep learning architectures, serving to reduce computational costs while learning abstract featur...
-
[74]
De-interleave:Convert the real-valued interleaved representation (where adjacent elements per channel represent real and imaginary components) to explicit complex format
-
[75]
FFT (if time-domain):If the input is in the time domain, transform to frequency domain via FFT
-
[76]
4.IFFT (if time-domain):If the original input was time-domain, transform back via IFFT
Average Pool:Apply average pooling along the frequency axis, reducing the sequence length by a factor ofr(typicallyr∈ {2,4}). 4.IFFT (if time-domain):If the original input was time-domain, transform back via IFFT
-
[77]
frequency hop at 100 Hz in this window
Re-Interleave:Convert the complex-valued sequence back to a real-valued interleaved sequence for subsequent real-valued processing blocks. This produces a representation that retains thespectral envelopeof the higher-resolution signal but at reduced sequence length. Crucially, this operation preserves both magnitude and phase information in a coarsened fo...
-
[78]
Complex-valued structure preservation:Each token position corresponds to a complex sample (I/Q pair), enabling the transformer to model relationships between complex samples rather than treating I and Q components as independent entities
-
[79]
A.5.2 Cross-Domain Information Fusion Once tokenized, we leverage the complementary nature of time and frequency domain representations
Computational efficiency:Halving the sequence length reduces the quadratic complexity of self-attention from O(L2) to O((L/2)2) =O(L 2/4), providing a 4× reduction in attention computation cost. A.5.2 Cross-Domain Information Fusion Once tokenized, we leverage the complementary nature of time and frequency domain representations. Comprehensive signal anal...
-
[80]
Inter-block:Between each Parseval Transformer block (currently one block in our architec- ture)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.