Reflection Separation from a Single Image via Joint Latent Diffusion
Pith reviewed 2026-06-28 10:44 UTC · model grok-4.3
The pith
A unified diffusion model generates both transmission and reflection layers from a single image.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
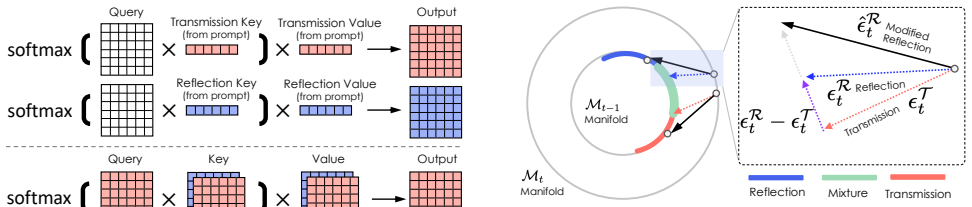
The paper claims that a diffusion model explicitly fine-tuned for reflection separation can jointly generate the transmission and reflection layers through a unified process, where cross-layer self-attention improves feature disentanglement, disjoint sampling iteratively cuts layer interference, and latent optimization with a learned composition function refines outputs, allowing robust recovery even under glare or weak-reflection conditions where information is insufficient.
What carries the argument
Unified latent diffusion model with cross-layer self-attention for simultaneous generation and disentanglement of transmission and reflection layers.
If this is right
- The model recovers both layers in glare and weak-reflection scenarios where earlier methods fail due to missing information.
- The approach surpasses prior state-of-the-art methods on multiple real-world benchmarks.
- Disjoint sampling reduces interference between the layers during the diffusion process.
- Latent optimization with the learned composition function improves handling of complex real scenes.
Where Pith is reading between the lines
- The joint generation strategy could apply to other single-image decomposition tasks such as separating shadows or highlights.
- The same diffusion backbone might support consistent separation across video frames if temporal consistency is added.
- Accurate layer separation would directly aid downstream tasks like photo editing or augmented reality overlays.
Load-bearing premise
Generative diffusion priors combined with cross-layer attention and sampling are enough to recover both layers accurately even when the input photo lacks sufficient information about one layer.
What would settle it
A collection of images with known ground-truth layers where glare completely obscures one layer; the method would fail if outputs show clear artifacts or invented content instead of plausible recovery.
Figures











read the original abstract
Single-image reflection separation is highly challenging under extreme conditions like glare or weak reflections. Existing methods often struggle to recover both layers in glare or weak-reflection scenarios because of insufficient information. This paper presents a diffusion model explicitly fine-tuned for this task, leveraging generative diffusion priors for robust separation. Our method simultaneously generates transmission and reflection layers through a unified diffusion model, incorporating a novel cross-layer self-attention mechanism for better feature disentanglement. We further introduce a disjoint sampling strategy to iteratively reduce interference between the layers during diffusion and a latent optimization step with a learned composition function for improved results in complex real-world scenarios. Extensive experiments demonstrate that our approach surpasses state-of-the-art methods on multiple real-world benchmarks. Project page: https://brian90709.github.io/diff-reflection-separation/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified latent diffusion model for single-image reflection separation that jointly generates transmission and reflection layers. It introduces a cross-layer self-attention mechanism for feature disentanglement, a disjoint sampling strategy to reduce layer interference during diffusion, and a latent optimization step using a learned composition function. The central claim is that this approach handles extreme conditions such as glare and weak reflections better than prior methods and surpasses state-of-the-art performance on multiple real-world benchmarks.
Significance. If the faithfulness of the recovered layers holds under insufficient input information, the work would represent a meaningful advance in applying generative diffusion priors to ill-posed inverse problems in computer vision. The architectural contributions (cross-layer attention and disjoint sampling) are credited as concrete innovations that could improve disentanglement over standard diffusion pipelines.
major comments (2)
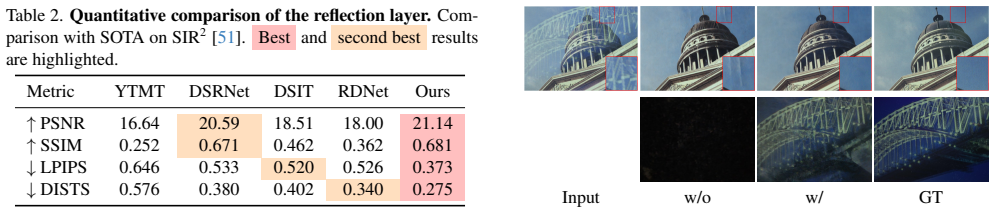
- [§4 (Experiments) and §3.2 (cross-layer self-attention)] The central claim requires faithful (not merely plausible) layer recovery in glare/weak-reflection regimes where the input supplies insufficient signal. The manuscript invokes generative priors plus the proposed mechanisms to resolve this, yet provides no targeted ablation or metric (e.g., high-frequency detail fidelity against available ground truth or synthetic insufficient-info cases) showing that cross-layer self-attention and the learned composition function prevent hallucination of absent details. This is load-bearing for the superiority claim on real-world benchmarks.
- [§3.3] §3.3 (disjoint sampling strategy): the description states that the strategy iteratively reduces interference, but the paper does not report quantitative isolation of its effect on layer consistency versus standard joint sampling in the exact extreme conditions used to motivate the work.
minor comments (2)
- [§3.4] Notation for the learned composition function is introduced without an explicit equation relating it to the standard additive model; a short derivation or pseudocode would improve clarity.
- [Figure 5] Figure captions for qualitative results should explicitly label which rows correspond to glare versus weak-reflection inputs to allow direct assessment of the motivating scenarios.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline planned revisions to strengthen the experimental validation.
read point-by-point responses
-
Referee: [§4 (Experiments) and §3.2 (cross-layer self-attention)] The central claim requires faithful (not merely plausible) layer recovery in glare/weak-reflection regimes where the input supplies insufficient signal. The manuscript invokes generative priors plus the proposed mechanisms to resolve this, yet provides no targeted ablation or metric (e.g., high-frequency detail fidelity against available ground truth or synthetic insufficient-info cases) showing that cross-layer self-attention and the learned composition function prevent hallucination of absent details. This is load-bearing for the superiority claim on real-world benchmarks.
Authors: We agree that evidence of faithful rather than merely plausible recovery is essential to support the claims in insufficient-signal regimes. The real-world benchmarks contain glare and weak-reflection examples, and the reported metrics plus visual results indicate improved performance. However, we acknowledge that the manuscript lacks targeted ablations isolating hallucination prevention via cross-layer self-attention and the composition function on synthetic insufficient-info cases. We will add such ablations, including high-frequency fidelity metrics against ground truth, in the revision. revision: yes
-
Referee: [§3.3] §3.3 (disjoint sampling strategy): the description states that the strategy iteratively reduces interference, but the paper does not report quantitative isolation of its effect on layer consistency versus standard joint sampling in the exact extreme conditions used to motivate the work.
Authors: We appreciate this observation. While overall benchmark gains reflect the strategy's contribution, the manuscript does not isolate its quantitative effect on layer consistency versus joint sampling in the motivating extreme conditions. We will add these targeted comparisons using layer-consistency metrics on extreme-condition subsets in the revised manuscript. revision: yes
Circularity Check
No circularity detected; claims rest on architectural novelty and empirical benchmarks rather than self-referential derivations
full rationale
The paper presents an empirical ML method using a fine-tuned diffusion model with novel components (cross-layer self-attention, disjoint sampling, latent optimization via learned composition). No load-bearing derivation, equation, or prediction is shown that reduces by construction to fitted inputs, self-citations, or renamed known results. The abstract and description frame the contribution as procedural innovation validated on real-world benchmarks, with no self-definitional loops or uniqueness theorems imported from prior author work. This matches the default case of a self-contained method paper without the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generative diffusion priors can provide robust separation even with insufficient information in the input image
Reference graph
Works this paper leans on
-
[1]
Tweedie moment projected diffusions for inverse problems.arXiv preprint arXiv:2310.06721, 2023
Benjamin Boys, Mark Girolami, Jakiw Pidstrigach, Sebas- tian Reich, Alan Mosca, and O Deniz Akyildiz. Tweedie moment projected diffusions for inverse problems.arXiv preprint arXiv:2310.06721, 2023. 2
-
[2]
Joint reflection removal and depth estimation from a single image.IEEE Transactions on Cybernetics, 51(12):5836–5849, 2020
Yakun Chang, Cheolkon Jung, and Jun Sun. Joint reflection removal and depth estimation from a single image.IEEE Transactions on Cybernetics, 51(12):5836–5849, 2020. 1
2020
-
[3]
Siamese dense network for reflection removal with flash and no-flash image pairs.International Journal of Computer Vi- sion, 128:1673–1698, 2020
Yakun Chang, Cheolkon Jung, Jun Sun, and Fengqiao Wang. Siamese dense network for reflection removal with flash and no-flash image pairs.International Journal of Computer Vi- sion, 128:1673–1698, 2020. 1
2020
-
[4]
Neural spline fields for burst image fusion and layer separation
Ilya Chugunov, David Shustin, Ruyu Yan, Chenyang Lei, and Felix Heide. Neural spline fields for burst image fusion and layer separation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 25763–25773, 2024. 1, 3
2024
-
[5]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sam- pling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Giannis Daras, Alexandros G Dimakis, and Constantinos Daskalakis. Consistent diffusion meets tweedie: Training ex- act ambient diffusion models with noisy data.arXiv preprint arXiv:2404.10177, 2024. 3
-
[7]
Location-aware single image reflection re- moval
Zheng Dong, Ke Xu, Yin Yang, Hujun Bao, Weiwei Xu, and Rynson WH Lau. Location-aware single image reflection re- moval. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 5017–5026, 2021. 3
2021
-
[8]
A generic deep architecture for single image re- flection removal and image smoothing
Qingnan Fan, Jiaolong Yang, Gang Hua, Baoquan Chen, and David Wipf. A generic deep architecture for single image re- flection removal and image smoothing. InProceedings of the IEEE International Conference on Computer Vision, pages 3238–3247, 2017. 3
2017
-
[9]
Deep-masking generative network: A unified framework for background restoration from superim- posed images.IEEE Transactions on Image Processing, 30: 4867–4882, 2021
Xin Feng, Wenjie Pei, Zihui Jia, Fanglin Chen, David Zhang, and Guangming Lu. Deep-masking generative network: A unified framework for background restoration from superim- posed images.IEEE Transactions on Image Processing, 30: 4867–4882, 2021. 3
2021
-
[10]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2, 3
2020
-
[12]
Gradient-free decoder inversion in latent diffusion models.Advances in Neural Information Processing Systems, 37:82982–83007, 2024
Seongmin Hong, Suh Yoon Jeon, Kyeonghyun Lee, Ernest Ryu, and Se Young Chun. Gradient-free decoder inversion in latent diffusion models.Advances in Neural Information Processing Systems, 37:82982–83007, 2024. 3
2024
-
[13]
L-differ: Single image reflection re- moval with language-based diffusion model
Yuchen Hong, Haofeng Zhong, Shuchen Weng, Jinxiu Liang, and Boxin Shi. L-differ: Single image reflection re- moval with language-based diffusion model. InEuropean Conference on Computer Vision, pages 58–76. Springer,
-
[14]
Ref-ldm: A latent diffusion model for reference-based face image restoration
Chi-Wei Hsiao, Yu-Lun Liu, Cheng-Kun Yang, Sheng-Po Kuo, Kevin Jou, and Chia-Ping Chen. Ref-ldm: A latent diffusion model for reference-based face image restoration. Advances in Neural Information Processing Systems, 37: 74840–74867, 2024. 2
2024
-
[15]
Trash or treasure? an interac- tive dual-stream strategy for single image reflection separa- tion.Advances in Neural Information Processing Systems, 34:24683–24694, 2021
Qiming Hu and Xiaojie Guo. Trash or treasure? an interac- tive dual-stream strategy for single image reflection separa- tion.Advances in Neural Information Processing Systems, 34:24683–24694, 2021. 3, 5
2021
-
[16]
Single image reflection sep- aration via component synergy
Qiming Hu and Xiaojie Guo. Single image reflection sep- aration via component synergy. InProceedings of the IEEE/CVF international conference on computer vision, pages 13138–13147, 2023. 3
2023
-
[17]
Single image reflection sep- aration via component synergy
Qiming Hu and Xiaojie Guo. Single image reflection sep- aration via component synergy. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13138–13147, 2023. 1, 2, 3, 6
2023
-
[18]
Single image reflection separation via dual-stream interactive transform- ers.Advances in Neural Information Processing Systems, 37:55228–55248, 2025
Qiming Hu, Hainuo Wang, and Xiaojie Guo. Single image reflection separation via dual-stream interactive transform- ers.Advances in Neural Information Processing Systems, 37:55228–55248, 2025. 1, 2, 3, 6
2025
-
[19]
Repurpos- ing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Met- zger, Rodrigo Caye Daudt, and Konrad Schindler. Repurpos- ing diffusion-based image generators for monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9492– 9502, 2024. 2, 4
2024
-
[20]
Sunwoo Kim, Minkyu Kim, and Dongmin Park. Test- time alignment of diffusion models without reward over- optimization.arXiv preprint arXiv:2501.05803, 2025. 2
-
[21]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Nina Konovalova, Maxim Nikolaev, Andrey Kuznetsov, and Aibek Alanov. Heeding the inner voice: Aligning controlnet training via intermediate features feedback.arXiv preprint arXiv:2507.02321, 2025. 2
-
[23]
Robust reflection re- moval with reflection-free flash-only cues
Chenyang Lei and Qifeng Chen. Robust reflection re- moval with reflection-free flash-only cues. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14811–14820, 2021. 1
2021
-
[24]
Polarized reflection re- moval with perfect alignment in the wild
Chenyang Lei, Xuhua Huang, Mengdi Zhang, Qiong Yan, Wenxiu Sun, and Qifeng Chen. Polarized reflection re- moval with perfect alignment in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1750–1758, 2020. 3
2020
-
[25]
User assisted separation of re- flections from a single image using a sparsity prior.IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(9):1647–1654, 2007
Anat Levin and Yair Weiss. User assisted separation of re- flections from a single image using a sparsity prior.IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(9):1647–1654, 2007. 3
2007
-
[26]
Learning to per- ceive transparency from the statistics of natural scenes.Ad- vances in Neural Information Processing Systems, 15, 2002
Anat Levin, Assaf Zomet, and Yair Weiss. Learning to per- ceive transparency from the statistics of natural scenes.Ad- vances in Neural Information Processing Systems, 15, 2002. 9
2002
-
[27]
Separating re- flections from a single image using local features
Anat Levin, Assaf Zomet, and Yair Weiss. Separating re- flections from a single image using local features. InPro- ceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004., pages I–I. IEEE, 2004. 3
2004
-
[28]
Single image reflection removal through cascaded refinement
Chao Li, Yixiao Yang, Kun He, Stephen Lin, and John E Hopcroft. Single image reflection removal through cascaded refinement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3565–3574,
-
[29]
Solving inverse problems via diffusion optimal control.Advances in Neural Information Processing Systems, 37:73549–73571, 2024
Henry Li and Marcus Pereira. Solving inverse problems via diffusion optimal control.Advances in Neural Information Processing Systems, 37:73549–73571, 2024. 2
2024
-
[30]
Con- trolnet++: Improving conditional controls with efficient consistency feedback: Project page: liming-ai
Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, and Chen Chen. Con- trolnet++: Improving conditional controls with efficient consistency feedback: Project page: liming-ai. github. io/controlnet plus plus. InEuropean Conference on Com- puter Vision, pages 129–147. Springer, 2024. 2
2024
-
[31]
Diffusion models for image restoration and enhancement: a compre- hensive survey.International Journal of Computer Vision, pages 1–31, 2025
Xin Li, Yulin Ren, Xin Jin, Cuiling Lan, Xingrui Wang, Wenjun Zeng, Xinchao Wang, and Zhibo Chen. Diffusion models for image restoration and enhancement: a compre- hensive survey.International Journal of Computer Vision, pages 1–31, 2025. 2
2025
-
[32]
Single image layer separation using relative smoothness
Yu Li and Michael S Brown. Single image layer separation using relative smoothness. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 2752–2759, 2014. 3
2014
-
[33]
Two-stage single image reflection removal with reflection-aware guidance.Applied Intelligence, 53 (16):19433–19448, 2023
Yu Li, Ming Liu, Yaling Yi, Qince Li, Dongwei Ren, and Wangmeng Zuo. Two-stage single image reflection removal with reflection-aware guidance.Applied Intelligence, 53 (16):19433–19448, 2023. 3
2023
-
[34]
Towards understanding cross and self-attention in stable diffusion for text-guided image editing
Bingyan Liu, Chengyu Wang, Tingfeng Cao, Kui Jia, and Jun Huang. Towards understanding cross and self-attention in stable diffusion for text-guided image editing. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7817–7826, 2024. 2
2024
-
[35]
Learning to see through ob- structions
Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, and Jia-Bin Huang. Learning to see through ob- structions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14215– 14224, 2020. 1
2020
-
[36]
Learning to see through ob- structions with layered decomposition.IEEE transactions on pattern analysis and machine intelligence, 44(11):8387– 8402, 2021
Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, and Jia-Bin Huang. Learning to see through ob- structions with layered decomposition.IEEE transactions on pattern analysis and machine intelligence, 44(11):8387– 8402, 2021. 3
2021
-
[37]
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu- Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, et al. Inference-time scaling for diffu- sion models beyond scaling denoising steps.arXiv preprint arXiv:2501.09732, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models.arXiv preprint arXiv:2112.10741, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
Chicago Y Park, Michael T McCann, Cristina Garcia- Cardona, Brendt Wohlberg, and Ulugbek S Kamilov. Ran- dom walks with tweedie: A unified framework for diffusion models.arXiv preprint arXiv:2411.18702, 2024. 2
-
[40]
Looking through the glass: Neu- ral surface reconstruction against high specular reflections
Jiaxiong Qiu, Peng-Tao Jiang, Yifan Zhu, Ze-Xin Yin, Ming- Ming Cheng, and Bo Ren. Looking through the glass: Neu- ral surface reconstruction against high specular reflections. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20823–20833, 2023. 1
2023
-
[41]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
2022
-
[42]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InMedical image computing and computer-assisted intervention, 2015. 3
2015
-
[43]
Deep unsupervised reflection removal using diffusion models
Green Rosh, BH Pawan Prasad, Lokesh R Boregowda, and Kaushik Mitra. Deep unsupervised reflection removal using diffusion models. In2023 IEEE International Conference on Image Processing (ICIP), pages 2045–2049. IEEE, 2023. 3
2045
-
[44]
Beyond first-order tweedie: Solving inverse problems using latent diffusion
Litu Rout, Yujia Chen, Abhishek Kumar, Constantine Cara- manis, Sanjay Shakkottai, and Wen-Sheng Chu. Beyond first-order tweedie: Solving inverse problems using latent diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9472– 9481, 2024. 2
2024
-
[45]
Junjie Shentu, Matthew Watson, and Noura Al Moubayed. Attencraft: Attention-guided disentanglement of multiple concepts for text-to-image customization.arXiv preprint arXiv:2405.17965, 2024. 2
-
[46]
High- fidelity guided image synthesis with latent diffusion models
Jaskirat Singh, Stephen Gould, and Liang Zheng. High- fidelity guided image synthesis with latent diffusion models. In2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 5997–6006. IEEE, 2023. 2
2023
-
[47]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[48]
Robust single image reflection removal against adversarial attacks
Zhenbo Song, Zhenyuan Zhang, Kaihao Zhang, Wenhan Luo, Zhaoxin Fan, Wenqi Ren, and Jianfeng Lu. Robust single image reflection removal against adversarial attacks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24688–24698, 2023. 3, 5, 7
2023
-
[49]
Lightsout: Diffusion-based outpaint- ing for enhanced lens flare removal
Shr-Ruei Tsai, Wei-Cheng Chang, Jie-Ying Lee, Chih-Hai Su, and Yu-Lun Liu. Lightsout: Diffusion-based outpaint- ing for enhanced lens flare removal. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6353–6363, 2025. 2
2025
-
[50]
Mulan: A multi layer anno- tated dataset for controllable text-to-image generation
Petru-Daniel Tudosiu, Yongxin Yang, Shifeng Zhang, Fei Chen, Steven McDonagh, Gerasimos Lampouras, Ignacio Iacobacci, and Sarah Parisot. Mulan: A multi layer anno- tated dataset for controllable text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 22413–22422, 2024. 3 10
2024
-
[51]
Benchmarking single-image reflection removal algorithms
Renjie Wan, Boxin Shi, Ling-Yu Duan, Ah-Hwee Tan, and Alex C Kot. Benchmarking single-image reflection removal algorithms. InProceedings of the IEEE International Con- ference on Computer Vision, pages 3922–3930, 2017. 5, 6, 7, 2
2017
-
[52]
Corrn: Cooperative reflection removal network.IEEE transactions on pattern analysis and machine intelligence, 42(12):2969–2982, 2019
Renjie Wan, Boxin Shi, Haoliang Li, Ling-Yu Duan, Ah- Hwee Tan, and Alex C Kot. Corrn: Cooperative reflection removal network.IEEE transactions on pattern analysis and machine intelligence, 42(12):2969–2982, 2019. 3
2019
-
[53]
Face image reflection removal.International Journal of Computer Vision, 129:385–399, 2021
Renjie Wan, Boxin Shi, Haoliang Li, Ling-Yu Duan, and Alex C Kot. Face image reflection removal.International Journal of Computer Vision, 129:385–399, 2021. 1
2021
-
[54]
Dmplug: A plug-in method for solving inverse problems with diffusion models.Advances in Neural Information Processing Systems, 37:117881– 117916, 2024
Hengkang Wang, Xu Zhang, Taihui Li, Yuxiang Wan, Tian- cong Chen, and Ju Sun. Dmplug: A plug-in method for solving inverse problems with diffusion models.Advances in Neural Information Processing Systems, 37:117881– 117916, 2024. 2
2024
-
[55]
Tao Wang, Wanglong Lu, Kaihao Zhang, Wenhan Luo, Tae- Kyun Kim, Tong Lu, Hongdong Li, and Ming-Hsuan Yang. Promptrr: Diffusion models as prompt generators for single image reflection removal.arXiv preprint arXiv:2402.02374,
-
[56]
Zero-shot im- age restoration using denoising diffusion null-space model
Yinhuai Wang, Jiwen Yu, and Jian Zhang. Zero-shot im- age restoration using denoising diffusion null-space model. arXiv preprint arXiv:2212.00490, 2022. 2
-
[57]
Matting by gen- eration
Zhixiang Wang, Baiang Li, Jian Wang, Yu-Lun Liu, Jinwei Gu, Yung-Yu Chuang, and Shin’ichi Satoh. Matting by gen- eration. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024. 2, 4
2024
-
[58]
Single image reflection removal exploiting mis- aligned training data and network enhancements
Kaixuan Wei, Jiaolong Yang, Ying Fu, David Wipf, and Hua Huang. Single image reflection removal exploiting mis- aligned training data and network enhancements. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8178–8187, 2019. 3
2019
-
[59]
A computational approach for obstruction-free photography.ACM Transactions on Graphics (TOG), 34(4): 1–11, 2015
Tianfan Xue, Michael Rubinstein, Ce Liu, and William T Freeman. A computational approach for obstruction-free photography.ACM Transactions on Graphics (TOG), 34(4): 1–11, 2015. 1
2015
-
[60]
See- ing deeply and bidirectionally: A deep learning approach for single image reflection removal
Jie Yang, Dong Gong, Lingqiao Liu, and Qinfeng Shi. See- ing deeply and bidirectionally: A deep learning approach for single image reflection removal. InProceedings of the eu- ropean conference on computer vision (ECCV), pages 654– 669, 2018. 3
2018
-
[61]
Kangning Yang, Huiming Sun, Jie Cai, Lan Fu, Jiaming Ding, Jinlong Li, Chiu Man Ho, and Zibo Meng. Survey on single-image reflection removal using deep learning tech- niques.arXiv preprint arXiv:2502.08836, 2025. 3
-
[62]
Diffu- sion model with cross attention as an inductive bias for dis- entanglement.Advances in Neural Information Processing Systems, 37:82465–82492, 2024
Tao Yang, Cuiling Lan, Yan Lu, and Nanning Zheng. Diffu- sion model with cross attention as an inductive bias for dis- entanglement.Advances in Neural Information Processing Systems, 37:82465–82492, 2024. 2
2024
-
[63]
Fast single image reflection suppression via con- vex optimization
Yang Yang, Wenye Ma, Yin Zheng, Jian-Feng Cai, and Weiyu Xu. Fast single image reflection suppression via con- vex optimization. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8141–8149, 2019. 3
2019
-
[64]
Proud: Pareto-guided diffusion model for multi- objective generation.Machine Learning, 113(9):6511–6538,
Yinghua Yao, Yuangang Pan, Jing Li, Ivor Tsang, and Xin Yao. Proud: Pareto-guided diffusion model for multi- objective generation.Machine Learning, 113(9):6511–6538,
-
[65]
Chang-Han Yeh, Chin-Yang Lin, Zhixiang Wang, Chi- Wei Hsiao, Ting-Hsuan Chen, Hau-Shiang Shiu, and Yu- Lun Liu. Diffir2vr-zero: Zero-shot video restoration with diffusion-based image restoration models.arXiv preprint arXiv:2407.01519, 2024. 2
-
[66]
Rgb↔x: Image decomposition and synthe- sis using material- and lighting-aware diffusion models
Zheng Zeng, Valentin Deschaintre, Iliyan Georgiev, Yannick Hold-Geoffroy, Yiwei Hu, Fujun Luan, Ling-Qi Yan, and Miloˇs Ha ˇsan. Rgb↔x: Image decomposition and synthe- sis using material- and lighting-aware diffusion models. In ACM SIGGRAPH 2024 Conference Papers, New York, NY , USA, 2024. Association for Computing Machinery. 2
2024
-
[67]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 2, 6
2023
-
[68]
Single image re- flection separation with perceptual losses
Xuaner Zhang, Ren Ng, and Qifeng Chen. Single image re- flection separation with perceptual losses. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 4786–4794, 2018. 3, 5, 6, 2
2018
-
[69]
Re- versible decoupling network for single image reflection re- moval
Hao Zhao, Mingjia Li, Qiming Hu, and Xiaojie Guo. Re- versible decoupling network for single image reflection re- moval. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26430–26439, 2025. 3, 6
2025
-
[70]
Language-guided image reflection separation
Haofeng Zhong, Yuchen Hong, Shuchen Weng, Jinxiu Liang, and Boxin Shi. Language-guided image reflection separation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24913– 24922, 2024. 1, 3
2024
-
[71]
Revisiting sin- gle image reflection removal in the wild
Yurui Zhu, Xueyang Fu, Peng-Tao Jiang, Hao Zhang, Qibin Sun, Jinwei Chen, Zheng-Jun Zha, and Bo Li. Revisiting sin- gle image reflection removal in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25468–25478, 2024. 3, 6, 7 11 Reflection Separation from a Single Image via Joint Latent Diffusion Supplemen...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.