dMX: Differentiable Mixed-Precision Assignment for Low-Precision Floating-Point Formats
Pith reviewed 2026-06-28 11:18 UTC · model grok-4.3
The pith
Continuous scalar offsets per layer enable learnable mixed-precision MXFP assignments that improve accuracy-bitwidth trade-offs in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
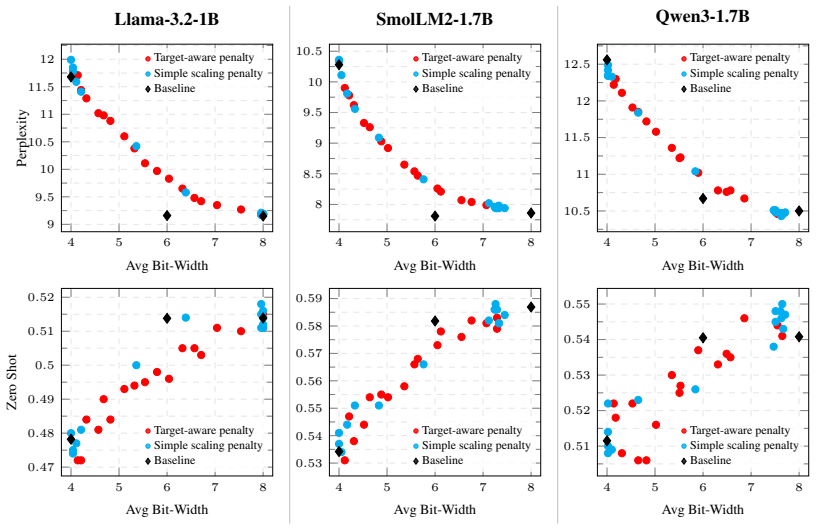
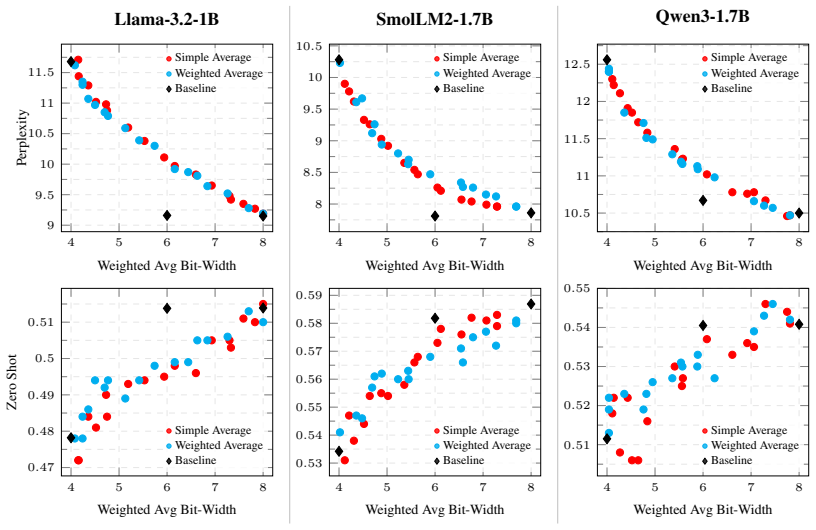
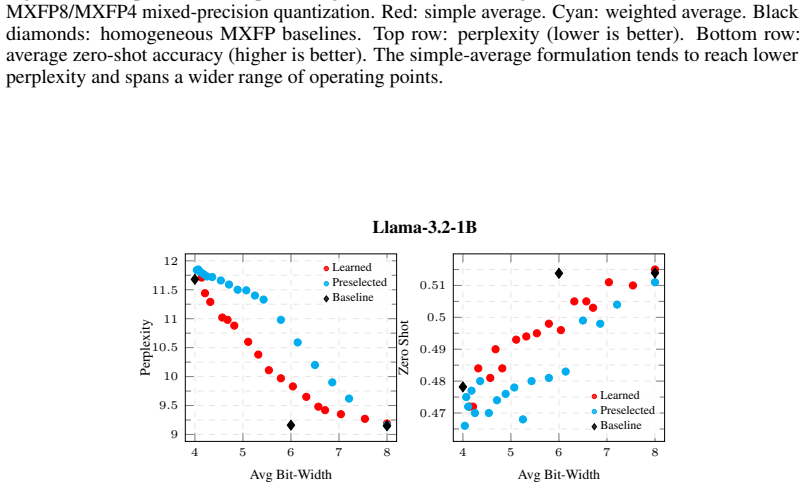
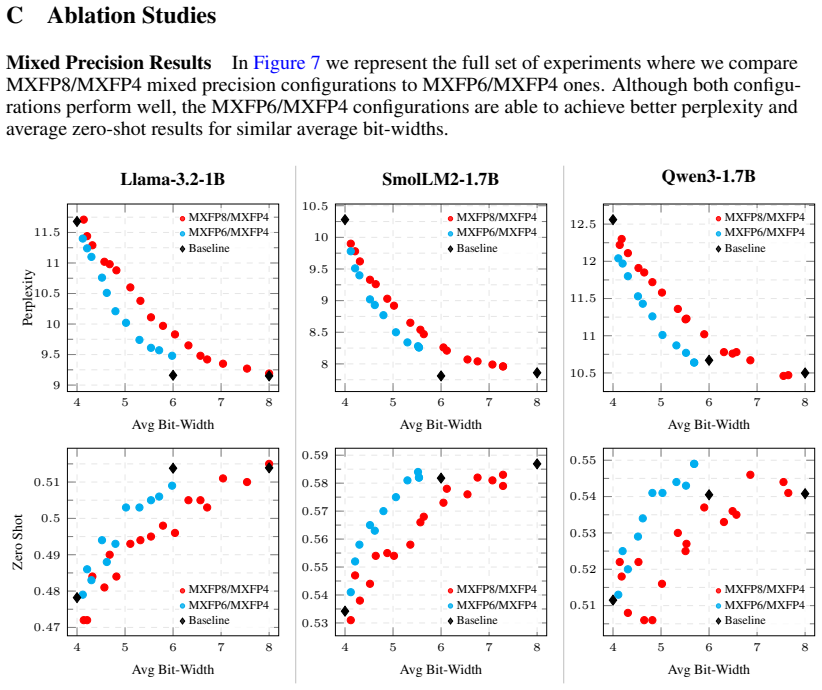
By replacing the discrete choice of floating-point format for each layer with a continuous scalar offset and annealing that offset to a valid MXFP code, the method obtains mixed-precision configurations whose average bit-width can be steered by regularization; these configurations consistently dominate both uniform bit-width baselines and KL-based selection heuristics on WikiText-2 perplexity and four zero-shot benchmarks.
What carries the argument
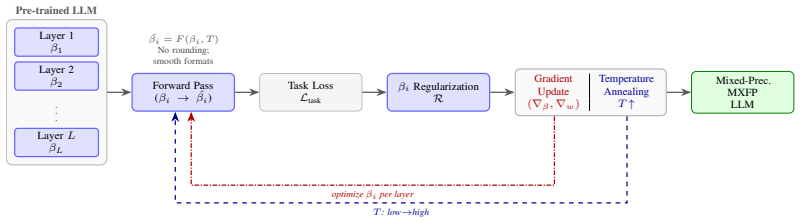
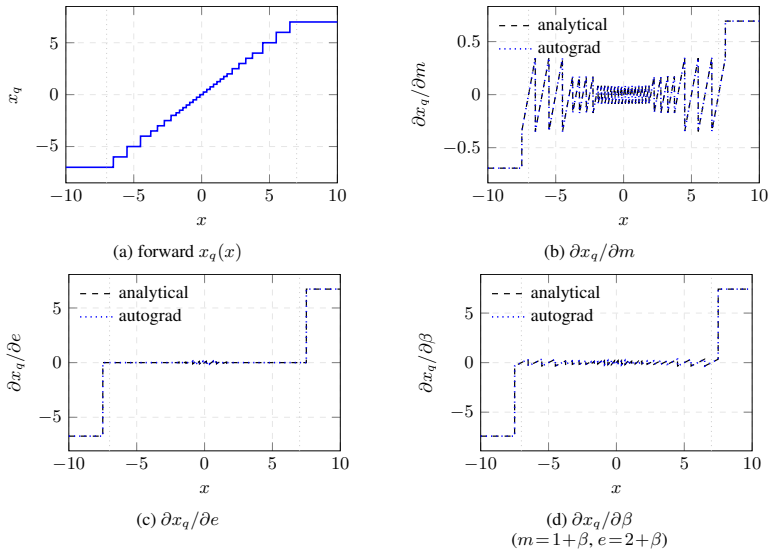
The per-layer scalar offset that collapses the multi-format design space into one learnable continuous variable, allowing gradient flow through the quantization choice before annealing enforces hardware compatibility.
If this is right
- The learned assignments achieve lower average bit-width at matched perplexity or accuracy across multiple LLM families.
- The target-aware regularizer lets users directly specify an inference-cost budget and obtain a matching mixed-precision layout.
- Final configurations are guaranteed to be valid MXFP formats usable on existing hardware without further manual adjustment.
- The method outperforms KL-divergence heuristics in producing Pareto-dominant points on the quality-bitwidth plane.
Where Pith is reading between the lines
- The same scalar-offset relaxation could be tested on integer or block-floating-point formats if analogous continuous parameterizations are defined.
- Hardware teams could treat the learned per-layer bit-width maps as target profiles when designing accelerators that support variable MXFP lanes.
- The annealing-plus-regularization pattern offers a template for other discrete assignment problems inside training loops, such as routing or sparsity pattern selection.
- If the continuous phase already yields near-optimal assignments, the discretization step might be replaced by a simple rounding rule in future variants.
Load-bearing premise
The annealing schedule will map the learned continuous offsets to discrete MXFP formats without erasing the quality gains observed while the offsets were still continuous.
What would settle it
After annealing completes, measure the final model's WikiText-2 perplexity; if it exceeds both the continuous-phase perplexity and the KL-heuristic perplexity by more than the paper's reported margins at the same average bit-width, the central claim fails.
Figures


read the original abstract
Quantizing large language models (LLMs) to low-precision floating-point representations is central to efficient deployment, yet applying a single bit-width uniformly across all layers is sub-optimal in terms of both performance and accuracy. This work introduces dMX, a differentiable mixed-precision quantization framework for learnable floating-point bit-width assignment. We study its application for the microscaling floating-point (MXFP) family of data types defined by the Open Compute Project (OCP) standard. The per-layer bit-width assignment is formulated as a continuous optimization problem in which each layer's floating-point format format is parameterized by a scalar parameter, folding the multi-variate design space into a single learnable offset. During training this offset takes continuous values, avoiding sudden oscillations between discrete quantization formats. A temperature-based annealing schedule progressively discretizes the learned offsets, ensuring that the final configuration maps to hardware-compatible MXFP formats without abrupt transitions between training and inference behavior. A target-aware regularization term steers the average bit-width toward a user-specified budget, serving as a coarse-grained proxy for inference cost and balancing model quality against deployment efficiency. We performed experiments on different families of LLM, such as Llama, Qwen3, and SmolLM2, evaluating perplexity on WikiText-2 and accuracy on four zero-shot reasoning benchmarks. Across these settings, dMX consistently yields Pareto-dominating models and improves over Kullback-Leibler (KL) divergence-based layer-selection heuristics, efficiently navigating trade-offs between model quality and average bit-width.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces dMX, a differentiable mixed-precision quantization method for MXFP formats in LLMs. Per-layer formats are parameterized by a single learnable scalar offset; a temperature-based annealing schedule progressively discretizes these offsets to hardware-valid MXFP assignments, while a target-aware regularization term controls average bit-width. Experiments on Llama, Qwen3, and SmolLM2 families report consistent Pareto improvements in WikiText-2 perplexity and zero-shot accuracy over uniform quantization and KL-divergence layer-selection heuristics.
Significance. If the continuous-to-discrete transition preserves the reported gains, the framework provides a practical, optimization-driven alternative to heuristic mixed-precision assignment for OCP-standard MXFP types, directly addressing the sub-optimality of uniform bit-widths while respecting hardware constraints. The folding of the format space into a scalar offset and the use of annealing plus regularization are technically interesting if empirically validated.
major comments (1)
- [Abstract] Abstract (method description): the central Pareto-dominance claim requires that post-annealing discrete MXFP assignments retain the continuous-phase quality gains and outperform KL baselines. No pre- vs. post-annealing metrics, ablation on temperature schedule hyperparameters, or quantitative evidence of discretization stability is referenced, leaving open the possibility that abrupt quality drops exceed the reported margins over baselines.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the technical approach and for highlighting the need to strengthen evidence around the annealing process. We agree that explicit validation of discretization stability is essential to support the reported Pareto improvements and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (method description): the central Pareto-dominance claim requires that post-annealing discrete MXFP assignments retain the continuous-phase quality gains and outperform KL baselines. No pre- vs. post-annealing metrics, ablation on temperature schedule hyperparameters, or quantitative evidence of discretization stability is referenced, leaving open the possibility that abrupt quality drops exceed the reported margins over baselines.
Authors: We acknowledge that the current manuscript does not explicitly report pre- versus post-annealing metrics or ablations on the temperature schedule. In the revision we will add these results: (1) tables comparing WikiText-2 perplexity and zero-shot accuracy before and after annealing for all evaluated models and bit-width budgets; (2) an ablation varying the annealing temperature schedule hyperparameters (initial temperature, decay rate, and final temperature) with corresponding performance curves; and (3) a quantitative stability analysis measuring the maximum quality drop during the final discretization steps relative to the reported margins over KL baselines. These additions will be placed in a new subsection of the experimental results and referenced from the abstract and method sections. revision: yes
Circularity Check
No circularity; empirical results independent of parameterization and regularization
full rationale
The paper formulates per-layer MXFP assignment via a continuous scalar offset, applies temperature annealing for discretization, and uses a target-aware regularization term to control average bit-width. Reported gains consist of measured perplexity on WikiText-2 and zero-shot accuracy on standard benchmarks for Llama, Qwen3, and SmolLM2 models, compared against KL heuristics. These evaluation metrics are external to the training loss components and are not shown to equal the regularization target or offset parameterization by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify core claims. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
Pith/arXiv arXiv 2022
-
[2]
AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration. InProceedings of Machine Learning and Systems, 2024
2024
-
[3]
SmoothQuant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. In Proceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[4]
FP8 versus INT8 for efficient deep learning inference.arXiv preprint arXiv:2303.17951, 2023
Mart van Baalen, Andrey Kuzmin, Suparna S Nair, Yuwei Ren, Eric Mahurin, Chirag Patel, Sundar Subramanian, Sanghyuk Lee, Markus Nagel, Joseph Soriaga, and Tijmen Blankevoort. FP8 versus INT8 for efficient deep learning inference.arXiv preprint arXiv:2303.17951, 2023
arXiv 2023
-
[5]
Microscaling data formats for deep learning.arXiv preprint arXiv:2310.10537, 2023
Bita Darvish Rouhani, Ritchie Zhao, Ankit More, Mathew Hall, Alireza Khodamoradi, Summer Deng, Dhruv Choudhary, Marius Cornea, Eric Dellinger, Kristof Denolf, et al. Microscaling data formats for deep learning.arXiv preprint arXiv:2310.10537, 2023
arXiv 2023
-
[6]
OCP microscaling formats (MX) specification
Bita Darvish Rouhani, Nitin Garegrat, Tom Savell, Ankit More, Kyung-Nam Han, Ritchie Zhao, Mathew Hall, Jasmine Klar, Eric Chung, Yuan Yu, Michael Schulte, Ralph Wittig, Ian Bratt, Nigel Stephens, Jelena Milanovic, John Brothers, Pradeep Dubey, Marius Cornea, Alexander Heinecke, Andres Rodriguez, Martin Langhammer, Summer Deng, Maxim Naumov, Paulius Micik...
2023
-
[7]
Castro, Denis Kuznedelev, Andrei Panferov, Eldar Kurtic, Shubhra Pandit, Alexandre Marques, Mark Kurtz, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh
Vage Egiazarian, Roberto L. Castro, Denis Kuznedelev, Andrei Panferov, Eldar Kurtic, Shubhra Pandit, Alexandre Marques, Mark Kurtz, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Bridging the gap between promise and performance for microscaling fp4 quantization, 2025
2025
-
[8]
MixQuant: Pushing the limits of block rotations in post-training quantization
Sai Sanjeet, Ian Colbert, Pablo Monteagudo-Lago, Giuseppe Franco, Yaman Umuroglu, and Nicholas J Fraser. MixQuant: Pushing the limits of block rotations in post-training quantization. arXiv preprint arXiv:2601.22347, 2026
Pith/arXiv arXiv 2026
-
[9]
Gradient-free training of quantized neural networks.arXiv preprint arXiv:2410.09734, 2024
Noa Cohen, Omkar Joglekar, Dotan Di Castro, Vladimir Tchuiev, Shir Kozlovsky, and Michal Moshkovitz. Gradient-free training of quantized neural networks.arXiv preprint arXiv:2410.09734, 2024
arXiv 2024
-
[10]
Bichen Wu, Yanghan Wang, Peizhao Zhang, Yuandong Tian, Peter Vajda, and Kurt Keutzer. Mixed precision quantization of ConvNets via differentiable neural architecture search.arXiv preprint arXiv:1812.00090, 2018
Pith/arXiv arXiv 2018
-
[11]
InfoQ: Mixed-precision quantization via global information flow
Mehmet Emre Akbulut, Hazem Hesham Yousef Shalby, Fabrizio Pittorino, and Manuel Roveri. InfoQ: Mixed-precision quantization via global information flow. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[12]
Mix-QSAM: Mixed-precision quantization of the segment anything model
Navin Ranjan and Andreas Savakis. Mix-QSAM: Mixed-precision quantization of the segment anything model. InIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2025
2025
-
[13]
Mahoney, and Kurt Keutzer
Zhen Dong, Zhewei Yao, Amir Gholami, Michael W. Mahoney, and Kurt Keutzer. HAWQ: Hessian AWare quantization of neural networks with mixed-precision. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 293–302, 2019
2019
-
[14]
Mahoney, and Kurt Keutzer
Zhen Dong, Zhewei Yao, Yaohui Cai, Daiyaan Arfeen, Amir Gholami, Michael W. Mahoney, and Kurt Keutzer. HAWQ-V2: Hessian aware trace-weighted quantization of neural networks. InAdvances in Neural Information Processing Systems, volume 33, 2020
2020
-
[15]
FracBits: Mixed precision quantization via fractional bit-widths
Linjie Yang and Qing Jin. FracBits: Mixed precision quantization via fractional bit-widths. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 10612–10620, 2021. 11
2021
-
[16]
SDQ: Stochastic differentiable quantization with mixed precision
Xijie Huang, Zhiqiang Shen, Shichao Li, Zechun Liu, Xianghong Hu, Jeffry Wicaksana, Eric Xing, and Kwang-Ting Cheng. SDQ: Stochastic differentiable quantization with mixed precision. InProceedings of the 39th International Conference on Machine Learning, pages 9295–9309, 2022
2022
-
[17]
BSQ: Exploring bit-level sparsity for mixed-precision neural network quantization
Huanrui Yang, Lin Duan, Yiran Chen, and Hai Li. BSQ: Exploring bit-level sparsity for mixed-precision neural network quantization. InProceedings of the International Conference on Learning Representations, 2021
2021
-
[18]
Yoshua Bengio, Nicholas L´eonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
Pith/arXiv arXiv 2013
-
[19]
Spinquant: Llm quantization with learned rotations.arXiv preprint arXiv:2405.16406, 2024
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: Llm quantization with learned rotations.arXiv preprint arXiv:2405.16406, 2024
Pith/arXiv arXiv 2024
-
[20]
FP8 formats for deep learning.arXiv preprint arXiv:2209.05433, 2022
Paulius Micikevicius, Dusan Stosic, Neil Burgess, Marius Cornea, Pradeep Dubey, Richard Grisenthwaite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, Naveen Mellem- pudi, Stuart Oberman, Mohammad Shoeybi, Michael Siu, and Hao Wu. FP8 formats for deep learning.arXiv preprint arXiv:2209.05433, 2022
Pith/arXiv arXiv 2022
-
[21]
The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[22]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[23]
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Mart´ın Bl´azquez, Guilherme Penedo, Lewis Tunstall, Andr´es Marafioti, Hynek Kydl´ıˇcek, Agust´ın Piqueres Lajar´ın, Vaibhav Srivastav, et al. SmolLM2: When smol goes big – data-centric training of a small language model.arXiv preprint arXiv:2502.02737, 2025
Pith/arXiv arXiv 2025
-
[24]
Guilherme Penedo, Hynek Kydl´ıˇcek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The FineWeb datasets: Decanting the web for the finest text data at scale.arXiv preprint arXiv:2406.17557, 2024
Pith/arXiv arXiv 2024
-
[25]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. InProceedings of the International Conference on Learning Representations, 2017
2017
-
[26]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
Pith/arXiv arXiv 2018
-
[27]
HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
2019
-
[28]
WinoGrande: An adversarial Winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An adversarial Winograd schema challenge at scale. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8732–8740, 2020
2020
-
[29]
LightEval: A lightweight framework for LLM evaluation, 2023
Nathan Habib, Cl ´ementine Fourrier, Hynek Kydl ´ıˇcek, Thomas Wolf, and Lewis Tunstall. LightEval: A lightweight framework for LLM evaluation, 2023
2023
-
[30]
Xilinx/brevitas, 2025
Giuseppe Franco, Alessandro Pappalardo, and Nicholas J Fraser. Xilinx/brevitas, 2025
2025
-
[31]
HAQ: Hardware-aware automated quantization with mixed precision
Kuan Wang, Zhijian Liu, Yujun Lin, Ji Lin, and Song Han. HAQ: Hardware-aware automated quantization with mixed precision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8612–8620, 2019. 12
2019
-
[32]
Mahoney, and Kurt Keutzer
Zhewei Yao, Zhen Dong, Zhangcheng Zheng, Amir Gholami, Jiali Yu, Eric Tan, Leyuan Wang, Qijing Huang, Yida Wang, Michael W. Mahoney, and Kurt Keutzer. HAWQ-V3: Dyadic neural network quantization. InProceedings of the 38th International Conference on Machine Learning, pages 11875–11886, 2021
2021
-
[33]
Towards mixed-precision quantization of neural networks via constrained optimization
Weihan Chen, Peisong Wang, and Jian Cheng. Towards mixed-precision quantization of neural networks via constrained optimization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5350–5359, 2021
2021
-
[34]
APTQ: Attention- aware post-training mixed-precision quantization for large language models
Ziyi Guan, Hantao Huang, Yupeng Su, Hong Huang, Ngai Wong, and Hao Yu. APTQ: Attention- aware post-training mixed-precision quantization for large language models. InProceedings of the 61st IEEE/ACM Design Automation Conference, 2024
2024
-
[35]
Utkarsh Saxena, Sayeh Sharify, Kaushik Roy, and Xin Wang. ResQ: Mixed-precision quan- tization of large language models with low-rank residuals.arXiv preprint arXiv:2412.14363, 2024
arXiv 2024
-
[36]
Rethinking differentiable search for mixed-precision neural networks
Zhaowei Cai and Nuno Vasconcelos. Rethinking differentiable search for mixed-precision neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2346–2355, 2020
2020
-
[37]
Zhexin Li, Tong Yang, Peisong Wang, and Jian Cheng. Q-ViT: Fully differentiable quantization for vision transformer.arXiv preprint arXiv:2201.07703, 2022
arXiv 2022
-
[38]
Jennings, and Arnon Netzer
Hai Victor Habi, Roy H. Jennings, and Arnon Netzer. HMQ: Hardware friendly mixed precision quantization block for CNNs. InComputer Vision – ECCV 2020, pages 448–463. Springer, 2020
2020
-
[39]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144, 2016
Pith/arXiv arXiv 2016
-
[40]
Maddison, Andriy Mnih, and Yee Whye Teh
Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables. InProceedings of the International Conference on Learning Representations, 2017
2017
-
[41]
Bayesian bits: Unifying quantization and pruning
Mart van Baalen, Christos Louizos, Markus Nagel, Rana Ali Amjad, Ying Wang, Tijmen Blankevoort, and Max Welling. Bayesian bits: Unifying quantization and pruning. InAdvances in Neural Information Processing Systems, volume 33, 2020
2020
-
[42]
Mixed precision DNNs: All you need is a good parametrization
Stefan Uhlich, Lukas Mauch, Fabien Cardinaux, Kazuki Yoshiyama, Javier Alonso Garcia, Stephen Tiedemann, Thomas Kemp, and Akira Nakamura. Mixed precision DNNs: All you need is a good parametrization. InProceedings of the International Conference on Learning Representations, 2020
2020
-
[43]
Micromix: Efficient mixed-precision quantization with microscaling formats for large language models
Wenyuan Liu, Haoqian Meng, Yilun Luo, Yafei Zhao, Peng Zhang, and Xindian Ma. Micromix: Efficient mixed-precision quantization with microscaling formats for large language models. arXiv preprint arXiv:2508.02343, 2025
arXiv 2025
-
[44]
Mixture compressor for mixture-of-experts LLMs gains more
Wei Huang, Yue Liao, Jianhui Liu, Ruifei He, Haoru Tan, Shiming Zhang, Hongsheng Li, Si Liu, and Xiaojuan Qi. Mixture compressor for mixture-of-experts LLMs gains more. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[45]
Ieee standard for floating-point arithmetic.IEEE Std 754-2019 (Revision of IEEE 754-2008), pages 1–84, 2019
IEEE. Ieee standard for floating-point arithmetic.IEEE Std 754-2019 (Revision of IEEE 754-2008), pages 1–84, 2019
2019
-
[46]
Jain, Albert Gural, Michael Wu, and Chris H
Sambhav R. Jain, Albert Gural, Michael Wu, and Chris H. Dick. Trained quantization thresholds for accurate and efficient fixed-point inference of deep neural networks. InProceedings of the 3rd Machine Learning and Systems (MLSys) Conference, 2020
2020
-
[47]
PyTorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas K¨opf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high-perf...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.