When Retrieval Doesn't Help: A Large-Scale Study of Biomedical RAG
Pith reviewed 2026-06-28 10:04 UTC · model grok-4.3
The pith
Retrieval yields only small inconsistent gains over no-retrieval baselines in biomedical QA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across five models, ten biomedical QA datasets, four retrieval methods, and four retrieval corpora, retrieval yields only small and inconsistent improvements over a no-retrieval baseline, typically within 1-2 points. In contrast, the choice of backbone model has a much larger effect than the choice of retriever or corpus, and expert and layman retrieval sources perform similarly in most settings. These results suggest that the main bottleneck is not retrieval quality alone, but the model's limited ability to use retrieved evidence effectively.
What carries the argument
Large-scale head-to-head comparison of RAG versus no-retrieval baselines across models, datasets, retrievers, and corpora.
If this is right
- Model choice matters more than retrieval design for biomedical QA performance.
- Different retrieval corpora produce similar results whether drawn from expert or lay sources.
- The main limit lies in how models integrate evidence rather than in finding the evidence.
- RAG may not be the primary route to higher factual accuracy in this domain.
Where Pith is reading between the lines
- If models struggle to use evidence, improving retrieval alone will not close the gap without changes to reasoning or training.
- The pattern may appear in other high-stakes QA settings where models must weigh external facts.
- Testing whether targeted fine-tuning on evidence-use tasks increases retrieval gains would directly test the suggested bottleneck.
Load-bearing premise
The no-retrieval baseline and RAG setups are run with comparable prompting, decoding, and metrics so that observed differences can be attributed to retrieval.
What would settle it
A follow-up experiment that fixes the model, prompt template, decoding parameters, and evaluation metric while adding retrieval and measures whether accuracy gains exceed 2 points consistently on held-out biomedical QA data.
Figures

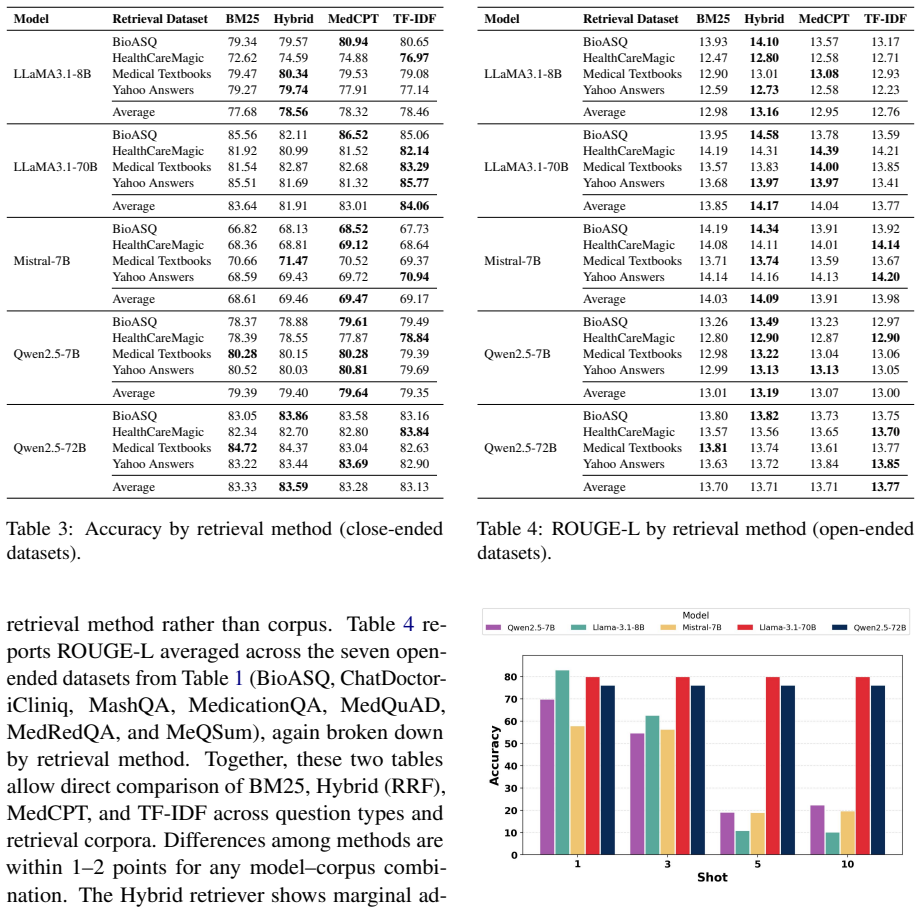


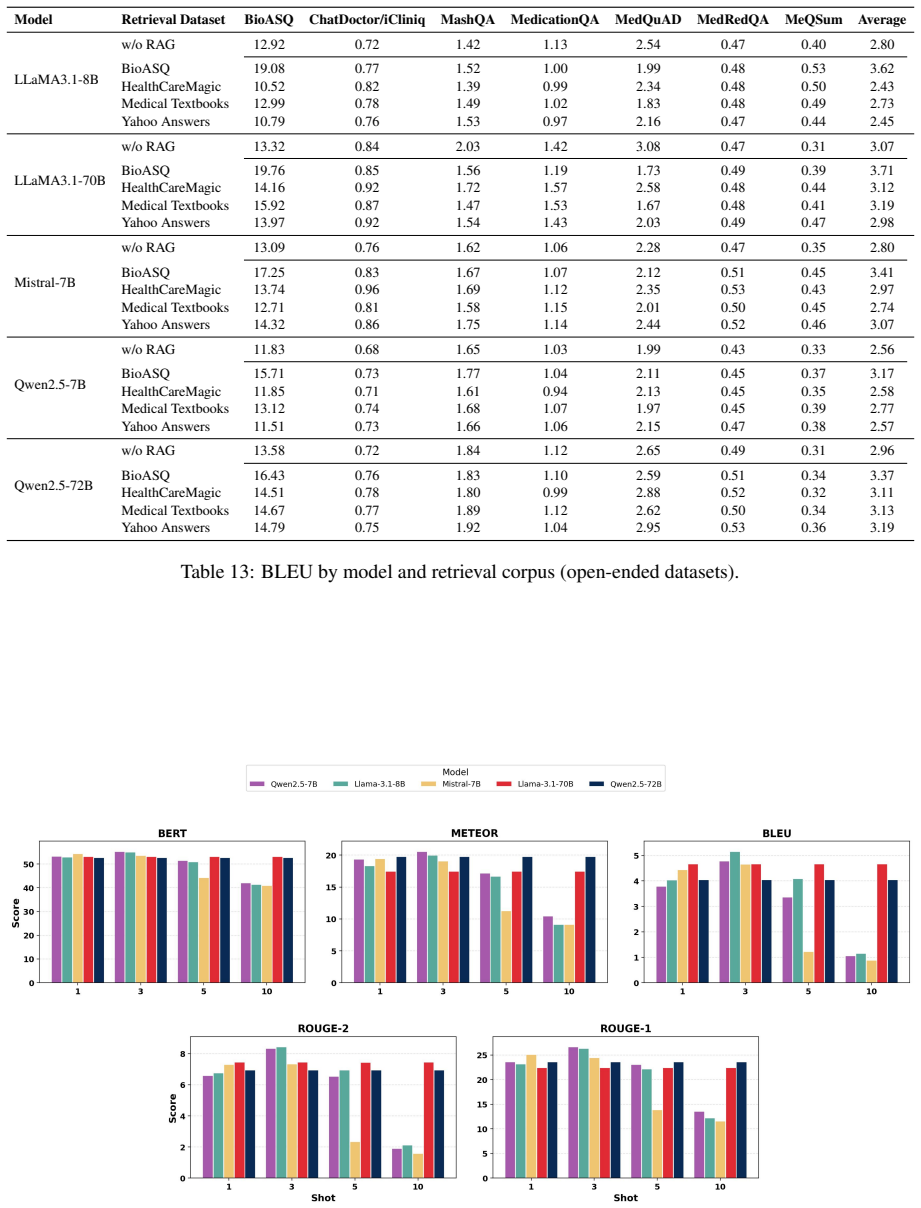

read the original abstract
Medical question answering is a high-stakes setting where factual errors can have serious consequences. Retrieval-augmented generation (RAG) is widely viewed as a promising solution, and prior work has reported substantial gains for large medical QA models. We revisit this assumption across a broad range of open-weight instruction-tuned models spanning 7B to 72B parameters. Across five models, ten biomedical QA datasets, four retrieval methods, and four retrieval corpora, we find that retrieval yields only small and inconsistent improvements over a no-retrieval baseline, typically within 1-2 points. In contrast, the choice of backbone model has a much larger effect than the choice of retriever or corpus, and expert and layman retrieval sources perform similarly in most settings. These results suggest that the main bottleneck is not retrieval quality alone, but the model's limited ability to use retrieved evidence effectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a large-scale empirical evaluation of retrieval-augmented generation (RAG) for biomedical QA. Across five open-weight instruction-tuned models (7B–72B), ten datasets, four retrieval methods, and four corpora, retrieval yields only small and inconsistent gains (typically 1–2 points) over a no-retrieval baseline. Model choice dominates over retriever or corpus choice; expert and layman sources perform similarly. The authors conclude that the primary bottleneck is the models’ limited ability to utilize retrieved evidence rather than retrieval quality itself.
Significance. If the central measurement holds, the result is significant because it supplies a broad, controlled negative finding against the common assumption that RAG reliably improves factual accuracy in high-stakes medical QA. The explicit effect-size statements and multi-dimensional design (models × datasets × retrievers × corpora) make the claim more generalizable than prior smaller studies. The work supplies a useful benchmark and redirects attention toward integration mechanisms rather than retrieval alone.
minor comments (3)
- [Methods] Methods: the paper states a 'controlled comparison' but does not list the exact prompt templates or confirm that the no-retrieval baseline uses an identical instruction prefix and output format; a short table or appendix excerpt would remove any residual doubt about prompt parity.
- [Results] Results: when reporting the 1–2 point deltas, include the standard deviation across the ten datasets (or at least the range) so readers can judge consistency at a glance.
- [Figures] Figure captions: several figures compare multiple retrievers; adding a one-sentence note on whether the same random seed and decoding parameters were used across all runs would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their positive assessment and recommendation to accept the manuscript. Their summary accurately captures the scope and central findings of our large-scale evaluation.
Circularity Check
Empirical measurement study with no derivations or self-referential predictions
full rationale
This is a large-scale empirical evaluation comparing RAG setups against no-retrieval baselines across five models, ten datasets, four retrieval methods, and four corpora. The reported 1-2 point differences are direct measurements on external benchmarks. No equations, fitted parameters, ansatzes, or self-citations are used to define or predict the target quantities by construction. The design is self-contained against external data and does not reduce any claim to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard assumptions that accuracy metrics on the chosen QA datasets reflect factual correctness in biomedical settings
- domain assumption Instruction-tuned models respond to retrieved passages in a manner comparable across the tested sizes and families
Reference graph
Works this paper leans on
-
[1]
On the Summarization of Consumer Health Questions
Ben Abacha, Asma and Demner-Fushman, Dina. On the Summarization of Consumer Health Questions. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1215
-
[2]
Nentidis, Anastasios and Katsimpras, Georgios and Krithara, Anastasia and Krallinger, Martin and Rodr. Overview of BioASQ 2025: The Thirteenth BioASQ Challenge on Large-Scale Biomedical Semantic Indexing and Question Answering , booktitle =. 2025 , publisher =. doi:10.1007/978-3-032-04354-2_12 , url =
-
[3]
M ed R ed QA for Medical Consumer Question Answering: Dataset, Tasks, and Neural Baselines
Nguyen, Vincent and Karimi, Sarvnaz and Rybinski, Maciej and Xing, Zhenchang. M ed R ed QA for Medical Consumer Question Answering: Dataset, Tasks, and Neural Baselines. Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (...
-
[4]
Ben Abacha, Asma and Demner-Fushman, Dina , title =. BMC Bioinformatics , volume =. 2019 , type =. doi:10.1186/s12859-019-3119-4 , url =
-
[5]
Abacha, A. B. and Mrabet, Y. and Sharp, M. and Goodwin, T. R. and Shooshan, S. E. and Demner-Fushman, D. , title =. Stud Health Technol Inform , volume =. doi:10.3233/shti190176 , year =
-
[6]
Applied Sciences , VOLUME =
Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter , TITLE =. Applied Sciences , VOLUME =. 2021 , NUMBER =
2021
-
[7]
Question Answering with Long Multiple-Span Answers
Zhu, Ming and Ahuja, Aman and Juan, Da-Cheng and Wei, Wei and Reddy, Chandan K. Question Answering with Long Multiple-Span Answers. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.342
-
[8]
Proceedings of the Conference on Health, Inference, and Learning , pages =
MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering , author =. Proceedings of the Conference on Health, Inference, and Learning , pages =. 2022 , editor =
2022
-
[9]
Cureus , volume=
Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge , author=. Cureus , volume=. 2023 , publisher=
2023
-
[10]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[11]
Krithara, A. and Nentidis, A. and Bougiatiotis, K. and Paliouras, G. , title =. Sci Data , volume =. doi:10.1038/s41597-023-02068-4 , year =
-
[12]
2009 , month = jan, note =
2009
-
[13]
Benchmarking Retrieval-Augmented Generation for Medicine
Xiong, Guangzhi and Jin, Qiao and Lu, Zhiyong and Zhang, Aidong. Benchmarking Retrieval-Augmented Generation for Medicine. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.372
-
[14]
Focus-Driven Contrastive Learning for Medical Question Summarization
Zhang, Ming and Dou, Shuai and Wang, Ziyang and Wu, Yunfang. Focus-Driven Contrastive Learning for Medical Question Summarization. Proceedings of the 29th International Conference on Computational Linguistics. 2022
2022
-
[15]
M ed A gents: Large Language Models as Collaborators for Zero-shot Medical Reasoning
Tang, Xiangru and Zou, Anni and Zhang, Zhuosheng and Li, Ziming and Zhao, Yilun and Zhang, Xingyao and Cohan, Arman and Gerstein, Mark. M ed A gents: Large Language Models as Collaborators for Zero-shot Medical Reasoning. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.33
-
[16]
Robertson, Stephen and Zaragoza, Hugo , title =. Found. Trends Inf. Retr. , month = apr, pages =. 2009 , issue_date =. doi:10.1561/1500000019 , abstract =
-
[17]
Journal of Documentation , volume =
SPARCK JONES, KAREN , title =. Journal of Documentation , volume =. 1972 , month =. doi:10.1108/eb026526 , url =
-
[18]
Jin, Qiao and Kim, Won and Chen, Qingyu and Comeau, Donald C and Yeganova, Lana and Wilbur, W John and Lu, Zhiyong , title =. Bioinformatics , volume =. 2023 , month =. doi:10.1093/bioinformatics/btad651 , url =
-
[19]
Cormack, Gordon V. and Clarke, Charles L A and Buettcher, Stefan , title =. Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2009 , isbn =. doi:10.1145/1571941.1572114 , abstract =
-
[20]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[21]
The Llama 3 Herd of Models. arXiv e-prints , keywords =. doi:10.48550/arXiv.2407.21783 , archivePrefix =. 2407.21783 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[22]
arXiv preprint arXiv:2310.06825 , year=
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
-
[23]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =. Advances in Neural Information Processing Systems , editor =
-
[24]
Singhal, Karan and Azizi, Shekoofeh and Tu, Tao and Mahdavi, S. Sara and Wei, Jason and Chung, Hyung Won and Scales, Nathan and Tanwani, Ajay and Cole-Lewis, Heather and Pfohl, Stephen and Payne, Perry and Seneviratne, Martin and Gamble, Paul and Kelly, Chris and Babiker, Abubakr and Schärli, Nathanael and Chowdhery, Aakanksha and Mansfield, Philip and De...
-
[25]
Survey of hallucination in natural language generation,
Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiezheng and Su, Dan and Xu, Yan and Ishii, Etsuko and Bang, Ye Jin and Madotto, Andrea and Fung, Pascale , title =. ACM Comput. Surv. , month = mar, articleno =. 2023 , issue_date =. doi:10.1145/3571730 , abstract =
-
[26]
Dense Passage Retrieval for Open-Domain Question Answering
Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau. Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.550
-
[27]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish. Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.557
-
[28]
Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy
Shao, Zhihong and Gong, Yeyun and Shen, Yelong and Huang, Minlie and Duan, Nan and Chen, Weizhu. Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.620
-
[29]
Akari Asai and Zeqiu Wu and Yizhong Wang and Avirup Sil and Hannaneh Hajishirzi , booktitle=. Self-. 2024 , url=
2024
-
[30]
Query Rewriting in Retrieval-Augmented Large Language Models
Ma, Xinbei and Gong, Yeyun and He, Pengcheng and Zhao, Hai and Duan, Nan. Query Rewriting in Retrieval-Augmented Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.322
-
[31]
arXiv preprint arXiv:2312.10997 , volume=
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=. 2023 , url=
Pith/arXiv arXiv 2023
-
[32]
arXiv preprint arXiv:2303.13375 , year=
Capabilities of gpt-4 on medical challenge problems , author=. arXiv preprint arXiv:2303.13375 , year=
-
[33]
Proceedings of the 40th International Conference on Machine Learning , pages =
Large Language Models Can Be Easily Distracted by Irrelevant Context , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[34]
Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLM s
Ovadia, Oded and Brief, Menachem and Mishaeli, Moshik and Elisha, Oren. Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLM s. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.15
-
[35]
PubMedQA: A dataset for biomedical research question answering
Jin, Qiao and Dhingra, Bhuwan and Liu, Zhengping and Cohen, William and Lu, Xinghua. P ub M ed QA : A Dataset for Biomedical Research Question Answering. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1259
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.