Affordance2Action: Task-Conditioned Scene-level Affordance Grounding for Real-Time Manipulation
Pith reviewed 2026-06-28 09:43 UTC · model grok-4.3
The pith
Task-conditioned manipulation requires grounding instructions to functional parts rather than object categories, often with multiple valid regions in cluttered scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
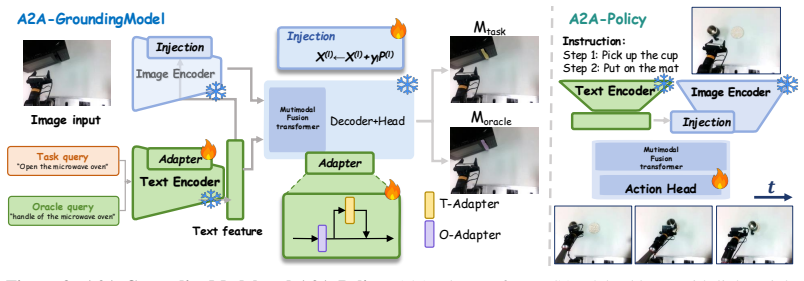
Affordance2Action establishes a benchmark-centered framework in which A2A-Bench provides supervision for scene-dependent, task-conditioned part affordance grounding that accounts for one-to-many correspondences between instructions and functional regions, directly supporting real-time grounding and affordance-conditioned manipulation policies.
What carries the argument
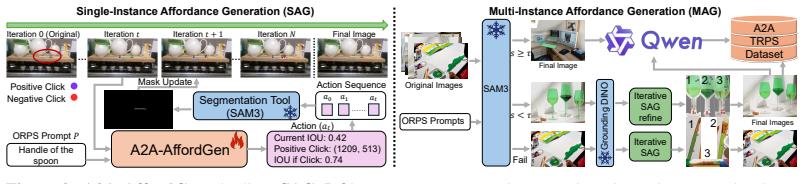
A2A-Bench, the manipulation-oriented benchmark that records single-region and multi-region instruction correspondences in cluttered everyday scenes.
If this is right
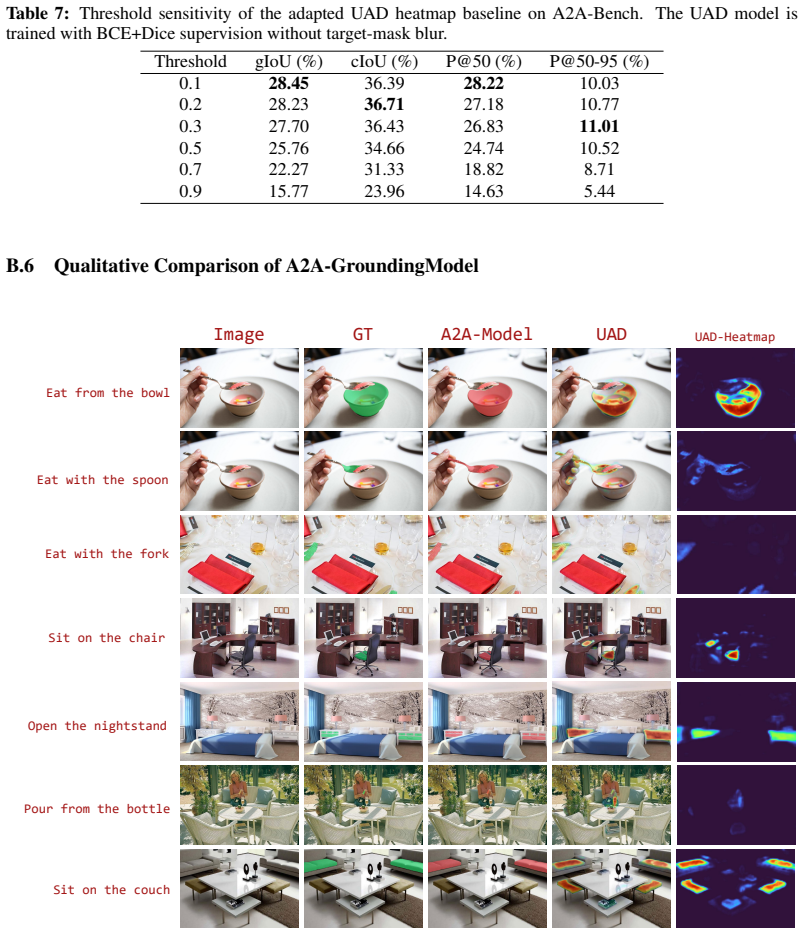
- Generic segmentation and VLM-based grounding methods exhibit substantial gaps when evaluated on task-level localization in multi-object scenes.
- Models trained with A2A-Bench supervision achieve higher accuracy at identifying task-relevant functional regions.
- The resulting affordance maps supply spatial priors that improve performance of downstream manipulation policies.
- Real-time affordance grounding becomes practical once trained on the new scene-level annotations.
Where Pith is reading between the lines
- Robotic systems could execute more varied interactions in unstructured settings by querying multiple valid affordance regions instead of committing to one.
- Annotation pipelines that combine language models with targeted human review may transfer to other perception tasks that involve inherent ambiguity.
- Future benchmarks in related domains such as instruction following may need explicit multi-correspondence designs to avoid underestimating model capability.
Load-bearing premise
The A2A-AffordGen pipeline of language-model filtering, interactive part segmentation, mask-out refinement, task-reasoning generation, and human verification yields accurate, unbiased annotations that match actual scene affordances.
What would settle it
A controlled study in which independent human annotators consistently select different functional regions for the same task instructions than those stored in A2A-Bench would show the labels do not capture true affordances.
Figures





read the original abstract
Task-conditioned manipulation requires grounding instructions to task-relevant functional parts rather than object categories. This setting is scene-dependent and often one-to-many in cluttered scenes: the same object may afford different interactions across tasks, while a single task may correspond to either one functional region or multiple valid functional regions, depending on the scene layout. Existing affordance datasets and benchmarks remain misaligned with this setting, as they typically focus on grasping or object-level affordances, rely on synthetic scenes, or assume a single instruction-region correspondence. We present Affordance2Action (A2A), a benchmark-centered learning framework for scene-level, task-conditioned part affordance grounding. At its core is A2A-Bench, a manipulation-oriented benchmark that covers both single-region and multi-region instruction correspondences in everyday scenes, with the latter highlighting the ambiguity and diversity of affordance grounding in realistic multi-object environments. To construct it at scale, we build A2A-AffordGen, an agent-assisted annotation pipeline that combines language-model filtering, interactive part segmentation, instance-level mask-out refinement, task-reasoning instruction generation, and human verification. A2A-Bench's supervision further supports diverse downstream applications, with real-time affordance grounding and affordance-conditioned manipulation policies as two representative examples. Experiments show that A2A exposes substantial gaps in generic segmentation, VLM-based grounding, and affordance distillation baselines, while improving task-level localization and providing useful spatial priors for downstream manipulation. All datasets and code will be publicly released to promote open research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Affordance2Action (A2A), a benchmark-centered learning framework for scene-level, task-conditioned part affordance grounding aimed at manipulation. It presents A2A-Bench covering single-region and multi-region instruction correspondences in everyday scenes, constructed at scale via the A2A-AffordGen pipeline (LM filtering, interactive part segmentation, instance-level mask-out refinement, task-reasoning instruction generation, and human verification). The work demonstrates applications to real-time affordance grounding and affordance-conditioned manipulation policies, with experiments claiming to expose gaps in generic segmentation, VLM-based grounding, and affordance distillation baselines while improving task-level localization.
Significance. If valid, the benchmark addresses a clear gap by targeting scene-dependent, one-to-many affordance correspondences rather than object-level or grasping-focused datasets. Public release of datasets and code is a concrete strength that supports reproducibility and follow-on work. The downstream policy examples provide a useful bridge from grounding to manipulation.
major comments (1)
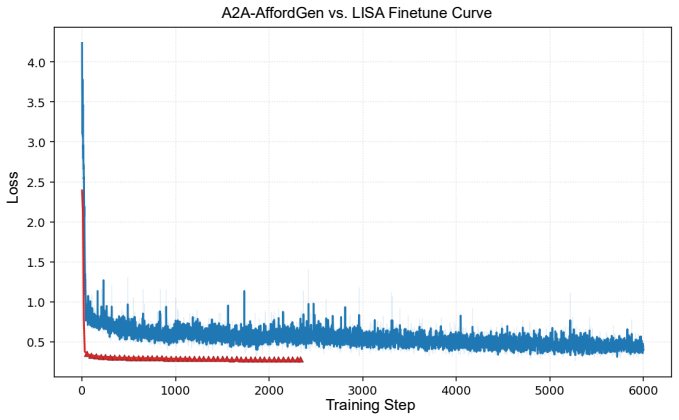
- [A2A-AffordGen pipeline (Section 3)] A2A-AffordGen pipeline (Section 3): the central claim that A2A-Bench correctly captures scene-dependent one-to-many affordance correspondences rests on the pipeline producing accurate, unbiased labels, yet no quantitative inter-annotator agreement, error rates, or ablation on pipeline stages (LM filtering, segmentation, mask-out refinement) is reported. Human verification alone does not address potential systematic biases in multi-region cases.
minor comments (2)
- [Abstract] Abstract: no dataset statistics (number of scenes, instructions, regions), evaluation protocol, or quantitative results are provided, which weakens the ability to assess the scale and strength of the reported gaps and improvements.
- [Conclusion] The paper states that all datasets and code will be publicly released; confirming the exact release contents and license in the camera-ready version would strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of validating the A2A-AffordGen pipeline. We address the concern point-by-point below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: A2A-AffordGen pipeline (Section 3): the central claim that A2A-Bench correctly captures scene-dependent one-to-many affordance correspondences rests on the pipeline producing accurate, unbiased labels, yet no quantitative inter-annotator agreement, error rates, or ablation on pipeline stages (LM filtering, segmentation, mask-out refinement) is reported. Human verification alone does not address potential systematic biases in multi-region cases.
Authors: We agree that quantitative validation of the annotation pipeline is important for supporting the central claims. In the revised version, we will add inter-annotator agreement metrics (e.g., Cohen's kappa or IoU overlap) computed on a held-out subset of annotations, along with error rates observed during the human verification stage. We will also include ablations isolating the impact of each pipeline component (LM filtering, interactive part segmentation, instance-level mask-out refinement, and task-reasoning instruction generation) on final label quality and downstream task performance. For multi-region cases specifically, the human verification protocol required annotators to flag and resolve ambiguous or inconsistent correspondences; we will augment the revision with a dedicated breakdown of multi-region annotation statistics and any detected biases to directly address this point. revision: yes
Circularity Check
No significant circularity; new benchmark and pipeline are independent contributions
full rationale
The paper introduces A2A-Bench via the A2A-AffordGen annotation pipeline (LM filtering, interactive segmentation, mask refinement, instruction generation, human verification) and evaluates baselines on the resulting data. No equations, fitted parameters, or derivations are present that reduce by construction to the inputs. The central experimental claims compare methods on newly generated annotations rather than predicting quantities from self-referential fits or self-citation chains. The pipeline's accuracy is an unverified assumption (as noted by the skeptic), but this is a validity concern, not a circular reduction of the derivation to its own outputs. No self-citations or uniqueness theorems from prior author work are invoked as load-bearing in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The agent-assisted annotation pipeline produces accurate and representative labels for real cluttered scenes
invented entities (2)
-
A2A-Bench
no independent evidence
-
A2A-AffordGen
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. Li, Y . Zhu, Z. Tang, J. Wen, M. Zhu, X. Liu, C. Li, R. Cheng, Y . Peng, Y . Peng, et al. Coa-vla: Improving vision-language-action models via visual-text chain-of-affordance. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9759–9769, 2025
2025
-
[2]
D. Wu, Y . Fu, S. Huang, Y . Liu, F. Jia, N. Liu, F. Dai, T. Wang, R. M. Anwer, F. S. Khan, et al. Ragnet: Large-scale reasoning-based affordance segmentation benchmark towards gen- eral grasping. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11980–11990, 2025
2025
-
[3]
Z. Wan, Y . Xie, C. Zhang, Z. Lin, Z. Wang, S. Stepputtis, D. Ramanan, and K. P. Sycara. Instructpart: Task-oriented part segmentation with instruction reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 24202–24227, 2025
2025
-
[4]
Y . Tang, W. Huang, Y . Wang, C. Li, R. Yuan, R. Zhang, J. Wu, and L. Fei-Fei. Uad: Un- supervised affordance distillation for generalization in robotic manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3822–3831. IEEE, 2025
2025
-
[5]
J. Li, Y . Feng, Y . Guo, J. Huang, W. Ji, Q. Bi, Y . Piao, M. Zhang, X. Zhao, Q. Chen, et al. Sam3-i: Segment anything with instructions.arXiv preprint arXiv:2512.04585, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Y . Qing, Y . Chi, S. Chen, S. Liu, K. Yao, S. Lin, L. Liu, and C. Zou. Bitrajdiff: Bidirectional trajectory generation with diffusion models for offline reinforcement learning.arXiv preprint arXiv:2506.05762, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
S. Shao, Z. Li, T. Zhang, C. Peng, G. Yu, X. Zhang, J. Li, and J. Sun. Objects365: A large- scale, high-quality dataset for object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 8430–8439, 2019
2019
-
[9]
M. Zhu, Y . Tian, H. Chen, C. Zhou, Q. Guo, Y . Liu, M. Yang, and C. Shen. Segagent: Ex- ploring pixel understanding capabilities in mllms by imitating human annotator trajectories. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 3686–3696, 2025
2025
-
[10]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[11]
G. Li, V . Jampani, D. Sun, and L. Sevilla-Lara. Locate: Localize and transfer object parts for weakly supervised affordance grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10922–10931, 2023
2023
-
[12]
L. Liu, W. Wang, Y . Han, Z. Xie, P. Yi, J. Li, and W. Lian. Foam: Foresight-augmented multi-task imitation policy for robotic manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18460–18468, 2026
2026
-
[13]
G. Li, D. Sun, L. Sevilla-Lara, and V . Jampani. One-shot open affordance learning with foun- dation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3086–3096, 2024
2024
-
[14]
H. Luo, W. Zhai, J. Zhang, Y . Cao, and D. Tao. Learning affordance grounding from exo- centric images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2252–2261, 2022. 10
2022
-
[15]
Y . Yang, W. Zhai, H. Luo, Y . Cao, J. Luo, and Z.-J. Zha. Grounding 3d object affordance from 2d interactions in images. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10905–10915, 2023
2023
-
[16]
S. Deng, X. Xu, C. Wu, K. Chen, and K. Jia. 3d affordancenet: A benchmark for visual object affordance understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1778–1787, 2021
2021
-
[17]
S. Lin, J. Chen, H. Xu, Z. Li, G. Wang, Y . Jing, S. Xu, R. Zhao, B. Sheil, L.-P. Chau, et al. Roboflow4d: A lightweight flow world model toward real-time flow-guided robotic manipula- tion.arXiv preprint arXiv:2605.17522, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [18]
-
[19]
S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak. Affordances from human videos as a versatile representation for robotics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13778–13790, 2023
2023
-
[20]
S. Lin, Y . Qing, L. Liu, M. Zhou, R. Jin, X. Fan, and G. Liu. Dygro-vla: Cross-task scaling of vision-language-action models via dynamic grouped residual optimization.arXiv preprint arXiv:2605.17486, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
C. Yu, H. Wang, Y . Shi, H. Luo, S. Yang, J. Yu, and J. Wang. Seqafford: Sequential 3d affordance reasoning via multimodal large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1691–1701, 2025
2025
- [22]
-
[23]
S. Qian, W. Chen, M. Bai, X. Zhou, Z. Tu, and L. E. Li. Affordancellm: Grounding affordance from vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7587–7597, 2024
2024
-
[24]
Zhang, Y
Z. Zhang, Y . Shi, L. Yang, S. Ni, Q. Ye, and J. Wang. Openhoi: Open-world hand-object interaction synthesis with multimodal large language model.Advances in Neural Information Processing Systems, 38:166582–166612, 2026
2026
-
[25]
H. Wang, S. Wang, Y . Zhong, Z. Yang, J. Wang, Z. Cui, J. Yuan, Y . Han, M. Liu, and Y . Ma. Affordance-r1: Reinforcement learning for generalizable affordance reasoning in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 9738–9746, 2026
2026
-
[26]
Yu, C.-H
Y . Yu, C.-H. H. Yang, J. Kolehmainen, P. G. Shivakumar, Y . Gu, S. R. R. Ren, Q. Luo, A. Gourav, I.-F. Chen, Y .-C. Liu, et al. Low-rank adaptation of large language model rescoring for parameter-efficient speech recognition. In2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 1–8. IEEE, 2023
2023
-
[27]
Q. Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Q. Liu, Z. Xu, G. Bertasius, and M. Niethammer. Simpleclick: Interactive image segmentation with simple vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22290–22300, 2023
2023
-
[29]
N. Xu, B. Price, S. Cohen, J. Yang, and T. S. Huang. Deep interactive object selection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 373– 381, 2016. 11
2016
-
[30]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European conference on computer vision, pages 38–55. Springer, 2024
2024
-
[31]
R. M. Haralick, S. R. Sternberg, and X. Zhuang. Image analysis using mathematical morphol- ogy.IEEE transactions on pattern analysis and machine intelligence, (4):532–550, 1987
1987
-
[32]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
A. Guo, B. Wen, J. Yuan, J. Tremblay, S. Tyree, J. Smith, and S. Birchfield. Handal: A dataset of real-world manipulable object categories with pose annotations, affordances, and reconstructions. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11428–11435. IEEE, 2023
2023
-
[34]
Z. Wan, Y . Xie, C. Zhang, Z. Lin, Z. Wang, S. Stepputtis, D. Ramanan, and K. P. Sycara. Instructpart: Affordance-based part segmentation from language instruction. InAAAI-2024 Workshop on Public Sector LLMs: Algorithmic and Sociotechnical Design, 2024
2024
-
[35]
H.-S. Fang, C. Wang, M. Gou, and C. Lu. Graspnet-1billion: A large-scale benchmark for general object grasping. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11444–11453, 2020
2020
-
[36]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[37]
C. Zhu, F. Xiao, A. Alvarado, Y . Babaei, J. Hu, H. El-Mohri, S. Culatana, R. Sumbaly, and Z. Yan. Egoobjects: A large-scale egocentric dataset for fine-grained object understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 20110– 20120, 2023
2023
-
[38]
Qian and D
S. Qian and D. F. Fouhey. Understanding 3d object interaction from a single image. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 21753–21763, 2023
2023
-
[39]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [40]
-
[41]
L. Yu, P. Poirson, S. Yang, A. C. Berg, and T. L. Berg. Modeling context in referring expres- sions. InEuropean conference on computer vision, pages 69–85. Springer, 2016
2016
-
[42]
Kazemzadeh, V
S. Kazemzadeh, V . Ordonez, M. Matten, and T. Berg. Referitgame: Referring to objects in photographs of natural scenes. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014
2014
-
[43]
J. Mao, J. Huang, A. Toshev, O. Camburu, A. L. Yuille, and K. Murphy. Generation and comprehension of unambiguous object descriptions. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016
2016
-
[44]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023. 12
2023
-
[45]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
X. Zou, J. Yang, H. Zhang, F. Li, L. Li, J. Wang, L. Wang, J. Gao, and Y . J. Lee. Segment everything everywhere all at once.Advances in neural information processing systems, 36: 19769–19782, 2023
2023
-
[47]
X. Lai, Z. Tian, Y . Chen, Y . Li, Y . Yuan, S. Liu, and J. Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9579–9589, 2024
2024
-
[48]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Kirillov, E
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
- [50]
-
[51]
A. Myers, C. L. Teo, C. Ferm ¨uller, and Y . Aloimonos. Affordance detection of tool parts from geometric features. In2015 IEEE International Conference on Robotics and Automation (ICRA), pages 1374–1381, 2015. doi:10.1109/ICRA.2015.7139369
-
[52]
Z. Yang, J. Wang, Y . Tang, K. Chen, H. Zhao, and P. H. Torr. Lavt: Language-aware vision transformer for referring image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18155–18165, 2022
2022
-
[53]
Z. Wang, Y . Lu, Q. Li, X. Tao, Y . Guo, M. Gong, and T. Liu. Cris: Clip-driven referring image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11686–11695, 2022
2022
-
[54]
J. Liu, H. Ding, Z. Cai, Y . Zhang, R. K. Satzoda, V . Mahadevan, and R. Manmatha. Poly- former: Referring image segmentation as sequential polygon generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18653–18663, 2023
2023
-
[55]
Z. Ren, Z. Huang, Y . Wei, Y . Zhao, D. Fu, J. Feng, and X. Jin. Pixellm: Pixel reasoning with large multimodal model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26374–26383, 2024
2024
-
[56]
R. Pi, L. Yao, J. Gao, J. Zhang, and T. Zhang. Perceptiongpt: Effectively fusing visual per- ception into llm. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 27124–27133, 2024
2024
-
[57]
Z. Xia, D. Han, Y . Han, X. Pan, S. Song, and G. Huang. Gsva: Generalized segmentation via multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3858–3869, 2024
2024
-
[58]
Positive point:(x, y). Next IoU:v. Gain:δ
Y .-C. Chen, W.-H. Li, C. Sun, Y .-C. F. Wang, and C.-S. Chen. Sam4mllm: Enhance multi- modal large language model for referring expression segmentation. InEuropean Conference on Computer Vision, pages 323–340. Springer, 2024. 13 Appendix A Implementation Details of A2A-AffordGen This appendix complements Sec. 3.1 with (i) the distance-maximizing oracle a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.