Dead Science Walking: Publication Bias and the AI Scientist Pipeline
Pith reviewed 2026-06-28 07:42 UTC · model grok-4.3
The pith
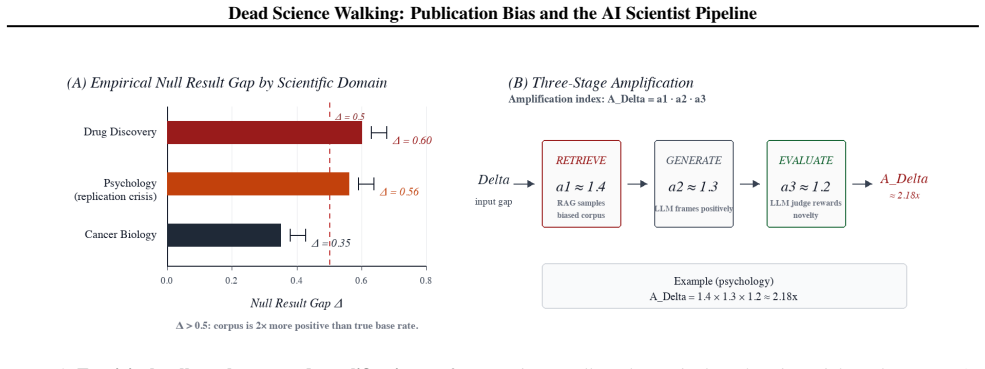
AI scientist systems risk amplifying publication bias in scientific output by a factor of 2.18 through standard pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A standard three-stage AI scientist pipeline amplifies the null result gap present in training corpora by a factor of 2.18, with the conclusion holding under more conservative multipliers; this turns existing distortions of roughly 0.60 in drug discovery, 0.56 in psychology, and 0.35 in cancer biology into larger systematic biases in automated research.
What carries the argument
The amplification index, a first-order multiplier that compounds the raw null result gap through retrieval, generation, and automated evaluation stages.
If this is right
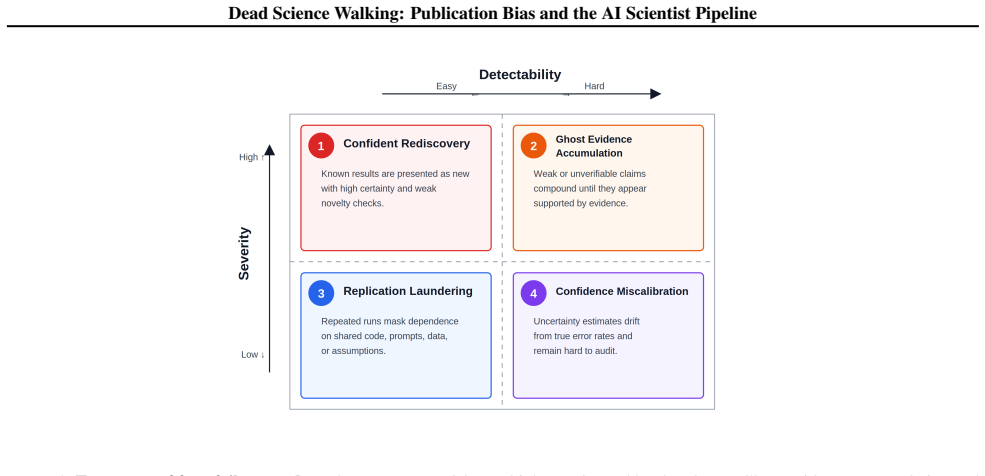
- Four governance failure modes emerge: confident rediscovery of known positives, ghost evidence accumulation, replication laundering, and confidence miscalibration.
- AI systems accelerate the underrepresentation of null findings before they accelerate discoveries.
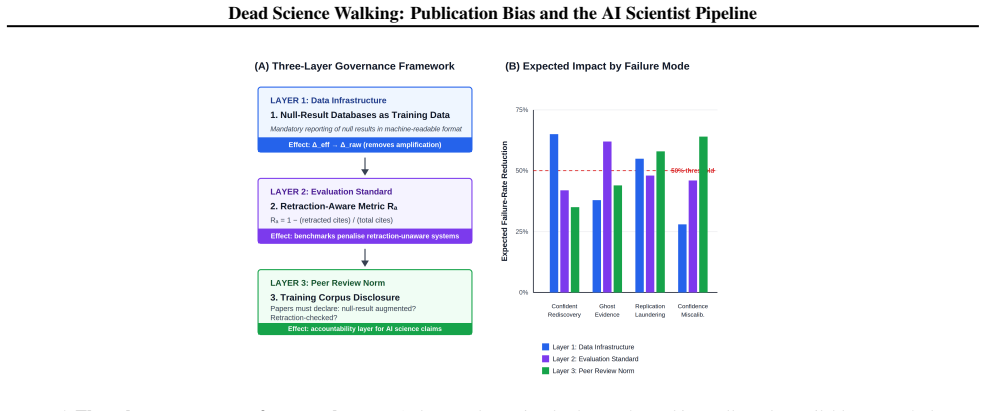
- Null-result databases as training infrastructure, retraction-aware evaluation metrics, and mandatory training corpus disclosure can reduce the amplification.
- Without these interventions the distortion compounds rather than stays constant.
Where Pith is reading between the lines
- Fields relying heavily on automated hypothesis iteration, such as early-stage drug screening, could see faster convergence on overstated effects.
- Retraining cycles that feed AI outputs back into the corpus would create a self-reinforcing loop unless null results are explicitly added.
- Disclosure requirements for training corpora could become a practical first step for any organization deploying AI research tools.
Load-bearing premise
The null result gap estimates from drug discovery, psychology, and cancer biology accurately capture the distortion in the corpora that will train and ground AI scientist systems.
What would settle it
A controlled comparison measuring the rate of null-result citations or conclusions in AI-generated papers versus human papers on the same topics, after training the AI on balanced versus standard corpora.
Figures

read the original abstract
AI scientist systems are beginning to automate the production, evaluation, and iteration of scientific hypotheses. Their promise is speed; their risk is that speed also scales errors embedded in the scientific record. We argue that a near-term risk is corpus failure: AI scientist systems are trained on and grounded in a literature that over-represents positive results and under-represents null findings. We formalise this distortion as the null result gap, estimate it across three domains (drug discovery ~0.60, psychology ~0.56, cancer biology ~0.35), and introduce an amplification index for reasoning about how retrieval, generation, and automated evaluation can compound the raw gap. Using first-order estimates, we argue that a standard three-stage pipeline can amplify corpus distortion by a factor of 2.18x, with the conclusion unchanged under more conservative multipliers. We identify four governance failure modes: confident rediscovery, ghost evidence accumulation, replication laundering, and confidence miscalibration. We then propose three interventions: null-result databases as training infrastructure, retraction-aware evaluation metrics, and mandatory training corpus disclosure. The central takeaway is that AI scientists will not only accelerate science. Without governance, they will accelerate science's blind spots before they accelerate its discoveries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that AI scientist systems risk amplifying publication bias present in the scientific literature. It defines a 'null result gap' and estimates its magnitude in three domains (drug discovery ~0.60, psychology ~0.56, cancer biology ~0.35). Using first-order estimates, it claims a standard three-stage pipeline (retrieval, generation, automated evaluation) amplifies this distortion by a factor of 2.18x. The paper identifies four governance failure modes (confident rediscovery, ghost evidence accumulation, replication laundering, confidence miscalibration) and proposes three interventions (null-result databases, retraction-aware metrics, mandatory corpus disclosure).
Significance. If the quantitative estimates hold, the work identifies a timely and load-bearing risk for automated scientific discovery systems: that speed will scale existing corpus distortions before it scales reliable discovery. The conceptual framing of an amplification index and the four failure modes supplies a useful vocabulary for governance discussions even if the numerical values require additional support. The proposed interventions are concrete and directly address the identified mechanisms.
major comments (3)
- [Abstract / gap estimation section] Abstract and the section presenting the null-result gaps: the values (~0.60 drug discovery, ~0.56 psychology, ~0.35 cancer biology) are stated without citation to the specific meta-analyses, without the extraction or aggregation method, and without any error bounds or sensitivity checks. These numbers are the sole empirical input to the 2.18x claim and therefore load-bearing.
- [Amplification index derivation] Section deriving the amplification index: the factor 2.18x is presented as arising from multiplicative compounding across three stages, yet the explicit per-stage multipliers, the justification for treating them as independent, and any sensitivity analysis under conservative assumptions are not shown. Without these details the central quantitative result cannot be evaluated.
- [Corpus representativeness discussion] Discussion of training corpora: the manuscript assumes the domain-level gap estimates are representative of the large-scale literature subsets that will actually train and ground AI scientist systems, but provides no argument or data addressing domain coverage, recency, or indexing differences that could alter the effective starting distortion.
minor comments (1)
- [Abstract] The abstract would be clearer if it distinguished the first-order estimates from the more robust qualitative claims about failure modes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving the transparency of our quantitative claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / gap estimation section] Abstract and the section presenting the null-result gaps: the values (~0.60 drug discovery, ~0.56 psychology, ~0.35 cancer biology) are stated without citation to the specific meta-analyses, without the extraction or aggregation method, and without any error bounds or sensitivity checks. These numbers are the sole empirical input to the 2.18x claim and therefore load-bearing.
Authors: We agree that the gap estimates require fuller documentation. The values are first-order aggregates drawn from published meta-analyses in each domain. In the revision we will add explicit citations to those meta-analyses, describe the extraction and aggregation procedure, report approximate error bounds, and include a sensitivity table showing how the 2.18x amplification index changes under plausible variations in the input gaps. revision: yes
-
Referee: [Amplification index derivation] Section deriving the amplification index: the factor 2.18x is presented as arising from multiplicative compounding across three stages, yet the explicit per-stage multipliers, the justification for treating them as independent, and any sensitivity analysis under conservative assumptions are not shown. Without these details the central quantitative result cannot be evaluated.
Authors: The 2.18x figure is presented as a first-order estimate obtained by multiplying three stage-specific bias factors. We will revise the relevant section to list the per-stage multipliers explicitly, justify the independence assumption on the basis of the sequential pipeline architecture, and add a sensitivity analysis confirming that the amplification conclusion remains directionally unchanged under more conservative multiplier choices, as already stated in the abstract. revision: yes
-
Referee: [Corpus representativeness discussion] Discussion of training corpora: the manuscript assumes the domain-level gap estimates are representative of the large-scale literature subsets that will actually train and ground AI scientist systems, but provides no argument or data addressing domain coverage, recency, or indexing differences that could alter the effective starting distortion.
Authors: We accept that the current draft does not address representativeness in sufficient detail. The estimates are offered as domain-level illustrations rather than universal constants. In revision we will insert a short discussion paragraph that acknowledges possible mismatches in coverage, recency, and indexing between the cited meta-analyses and the corpora used by large-scale AI systems, while noting the absence of comprehensive empirical data on these mismatches. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper estimates null-result gaps from external meta-analyses (~0.60, ~0.56, ~0.35) and separately introduces an amplification index for a three-stage pipeline, claiming a 2.18x factor via first-order estimates. No equations, self-citations, or steps are exhibited that reduce the amplification factor to the input gaps by construction, rename a fitted parameter as a prediction, or rely on load-bearing self-citation chains. The central claim remains an argument built from independent external estimates and modeling assumptions rather than a self-referential loop.
Axiom & Free-Parameter Ledger
free parameters (4)
- null result gap (drug discovery) =
~0.60
- null result gap (psychology) =
~0.56
- null result gap (cancer biology) =
~0.35
- amplification factor =
2.18
axioms (2)
- domain assumption AI scientist systems are trained on and grounded in the existing scientific literature
- ad hoc to paper Retrieval, generation, and automated evaluation stages compound distortion in a multiplicative way
Reference graph
Works this paper leans on
-
[1]
PLOS Medicine , volume=
Why most published research findings are false , author=. PLOS Medicine , volume=. 2005 , doi=
2005
-
[2]
2010 , doi=
Fanelli, Daniele , journal=. 2010 , doi=
2010
-
[3]
Science , volume=
Publication bias in the social sciences: Unlocking the file drawer , author=. Science , volume=. 2014 , doi=
2014
-
[4]
Science , volume=
Estimating the reproducibility of psychological science , author=. Science , volume=. 2015 , doi=
2015
-
[5]
Nature , volume=
Drug development: Raise standards for preclinical cancer research , author=. Nature , volume=. 2012 , doi=
2012
-
[6]
eLife , volume=
Investigating the replicability of preclinical cancer biology , author=. eLife , volume=. 2021 , doi=
2021
-
[7]
PLOS Biology , volume=
The economics of reproducibility in preclinical research , author=. PLOS Biology , volume=. 2015 , doi=
2015
-
[8]
Journal of Medical Ethics , volume=
Retractions in the medical literature: How many patients are put at risk by flawed research? , author=. Journal of Medical Ethics , volume=. 2013 , doi=
2013
-
[9]
Scientometrics , volume=
Retracted papers remain in the scientific literature , author=. Scientometrics , volume=. 2021 , doi=
2021
-
[10]
2024 , note=
Retraction Watch Database , author=. 2024 , note=
2024
-
[11]
Science , volume=
Promoting an open research culture , author=. Science , volume=. 2015 , doi=
2015
-
[12]
, journal=
Chambers, Christopher D. , journal=. Registered reports: A new publishing initiative at. 2013 , doi=
2013
-
[13]
Perspectives on Psychological Science , volume=
A multilab preregistered replication of the ego-depletion effect , author=. Perspectives on Psychological Science , volume=. 2016 , doi=
2016
-
[14]
JAMA , volume=
Factors influencing publication of research results: Follow-up of applications submitted to two institutional review boards , author=. JAMA , volume=. 1992 , doi=
1992
-
[15]
and Tse, Tony and Williams, Rebecca J
Zarin, Deborah A. and Tse, Tony and Williams, Rebecca J. and Califf, Robert M. and Ide, Nicholas C. , journal=. The. 2011 , doi=
2011
-
[16]
Lu, Chris and Lu, Cong and Lange, Robert Tjarko and Foerster, Jakob and Clune, Jeff and Ha, David , journal=. The. 2024 , doi=
2024
-
[17]
Gottweis, Juraj and others , journal=
-
[18]
Nature , volume=
Autonomous chemical research with large language models , author=. Nature , volume=. 2023 , doi=
2023
-
[19]
and Cox, Sam and Schilter, Oliver and Baldassari, Carlo and White, Andrew D
Bran, Andres M. and Cox, Sam and Schilter, Oliver and Baldassari, Carlo and White, Andrew D. and Schwaller, Philippe , journal=. 2024 , doi=
2024
-
[20]
The virtual lab:
Swanson, Kyle and others , journal=. The virtual lab:. 2024 , doi=
2024
-
[21]
Retrieval-augmented generation for knowledge-intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and others , booktitle=. Retrieval-augmented generation for knowledge-intensive
-
[22]
Truthful
Lin, Stephanie and Hilton, Jacob and Evans, Owain , booktitle=. Truthful. 2022 , doi=
2022
-
[23]
Si, Chenglei and Yang, Diyi and Hashimoto, Tatsunori , journal=
-
[24]
and others , booktitle=
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and others , booktitle=. Judging
-
[25]
A survey on
Li, Junlong and others , journal=. A survey on
-
[26]
Chen, Jiaao and others , journal=. Are
-
[27]
Proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
Model cards for model reporting , author=. Proceedings of the Conference on Fairness, Accountability, and Transparency , pages=. 2019 , doi=
2019
-
[28]
Communications of the ACM , volume=
Datasheets for datasets , author=. Communications of the ACM , volume=. 2021 , doi=
2021
-
[29]
Transactions of the Association for Computational Linguistics , volume=
Data statements for natural language processing: Toward mitigating system bias and enabling better science , author=. Transactions of the Association for Computational Linguistics , volume=. 2018 , doi=
2018
-
[30]
Chan, Jun Shern and Pieler, Niko and Jao, Justin and Peetoom, Jasper and Mullen-Schultz, Rachel and others , journal=
-
[31]
2025 , note=
Introducing. 2025 , note=
2025
-
[32]
2025 , howpublished=
2025
-
[33]
2026 , howpublished=
Science , author=. 2026 , howpublished=
2026
-
[34]
2026 , note=
Evaluating. 2026 , note=
2026
-
[35]
Psychological Science , volume=
False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant , author=. Psychological Science , volume=. 2011 , doi=
2011
-
[36]
Department of Statistics, Columbia University , year=
The garden of forking paths: Why multiple comparisons can be a problem, even when there is no fishing expedition or p-hacking and the research hypothesis was posited ahead of time , author=. Department of Statistics, Columbia University , year=
-
[37]
Journal of Clinical Epidemiology , volume=
Funnel plots for detecting bias in meta-analysis: Guidelines on choice of axis , author=. Journal of Clinical Epidemiology , volume=. 2001 , doi=
2001
-
[38]
Nature , volume=
The fight against fake-paper factories that churn out sham science , author=. Nature , volume=. 2022 , doi=
2022
-
[39]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
On faithfulness and factuality in abstractive summarization , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=. 2020 , doi=
2020
-
[40]
ACM Computing Surveys , volume=
Survey of hallucination in natural language generation , author=. ACM Computing Surveys , volume=. 2023 , doi=
2023
-
[41]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
International Conference on Learning Representations , year=
Self-consistency improves chain of thought reasoning in language models , author=. International Conference on Learning Representations , year=
-
[43]
The Dataset Nutrition Label: A Framework To Drive Higher Data Quality Standards
The dataset nutrition label: A framework to drive higher data quality standards , author=. arXiv preprint arXiv:1805.03677 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
and Mitchell, Margaret and Gebru, Timnit and Hutchinson, Ben and Smith-Loud, Jamila and Theron, Daniel and Barnes, Parker , booktitle=
Raji, Inioluwa Deborah and Smart, Andrew and White, Rebecca N. and Mitchell, Margaret and Gebru, Timnit and Hutchinson, Ben and Smith-Loud, Jamila and Theron, Daniel and Barnes, Parker , booktitle=. Closing the. 2020 , doi=
2020
-
[45]
Patterns , volume=
Data and its (dis)contents: A survey of dataset development and use in machine learning research , author=. Patterns , volume=. 2021 , doi=
2021
-
[46]
and Paullada, Amandalynne and Denton, Emily and Hanna, Alex , booktitle=
Raji, Inioluwa Deborah and Bender, Emily M. and Paullada, Amandalynne and Denton, Emily and Hanna, Alex , booktitle=
-
[47]
Proceedings of the ACM on Human-Computer Interaction , volume=
Datasheets for datasets: A critical reflection , author=. Proceedings of the ACM on Human-Computer Interaction , volume=. 2021 , doi=
2021
-
[48]
Systematic Reviews , volume=
The strong focus on positive results in abstracts may cause bias in systematic reviews: A case study on abstract reporting bias , author=. Systematic Reviews , volume=. 2019 , doi=
2019
-
[49]
PLOS ONE , volume=
Systematic review of the empirical evidence of study publication bias and outcome reporting bias , author=. PLOS ONE , volume=. 2008 , doi=
2008
-
[50]
Highly accurate protein structure prediction with
Jumper, John and Evans, Richard and Pritzel, Alexander and Green, Tim and Figurnov, Michael and Ronneberger, Olaf and Tunyasuvunakool, Kathryn and Bates, Russ and Zidek, Augustin and Potapenko, Anna and others , journal=. Highly accurate protein structure prediction with. 2021 , doi=
2021
-
[51]
Nature Human Behaviour , volume=
Quantifying large language model usage in scientific papers , author=. Nature Human Behaviour , volume=. 2025 , doi=
2025
-
[52]
Scientific Reports , volume=
Citation manipulation through citation mills and pre-print servers , author=. Scientific Reports , volume=. 2025 , doi=
2025
-
[53]
Royal Society Open Science , volume=
Generalization bias in large language model summarization of scientific research , author=. Royal Society Open Science , volume=. 2025 , doi=
2025
-
[54]
, journal=
Alkaissi, Hussam and McFarlane, Samy I. , journal=. Artificial hallucinations in. 2023 , doi=
2023
-
[55]
and Selvamogan, Arrane and Boddy, Amy M
Sidhu, Rickvir S. and Selvamogan, Arrane and Boddy, Amy M. , journal=. Trust, truth and transparency: Analysing the references underpinning. 2026 , doi=
2026
-
[56]
2024 , doi=
Shumailov, Ilia and Shumaylov, Zakhar and Zhao, Yiren and Papernot, Nicolas and Anderson, Ross and Gal, Yarin , journal=. 2024 , doi=
2024
-
[57]
2026 , note=
Shmatko, Nazar and Adam, Alex and Esau, Paul , howpublished=. 2026 , note=
2026
-
[58]
2025 , note=
Esau, Paul and Shmatko, Nazar and Adam, Alex , howpublished=. 2025 , note=
2025
-
[59]
PLOS Biology , volume=
Ending publication bias: A values-based approach to surface null and negative results , author=. PLOS Biology , volume=. 2025 , doi=
2025
-
[60]
Thelwall, Mike and Lehtisaari, Marianna and Katsirea, Irini and Holmberg, Kim and Zheng, Er-Te , journal=. Does. 2025 , doi=
2025
-
[61]
Carolyn and Gu, Weikuan , journal=
Yao, Lan and Gu, Tianshu and Li, Xuexin and Jiao, Yan and Li, Minghui and Li, Yulan and Graff, J. Carolyn and Gu, Weikuan , journal=. 2025 , doi=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.