Argus-Retriever: Vision-LLM Late-Interaction Retrieval with Region-Aware Query-Conditioned MoE for Visual Document Retrieval
Pith reviewed 2026-06-28 04:52 UTC · model grok-4.3
The pith
Argus conditions late-interaction document embeddings on the query by routing experts to spatial regions, raising NDCG@5 to 92.67 on ViDoRe V1.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
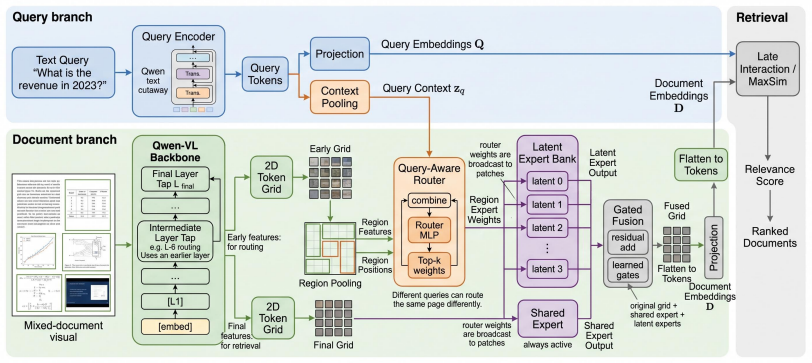
Argus replaces the query-independent document encoder of prior ColPali-style systems with a region-aware, query-conditioned Mixture-of-Experts module. The query produces a compact context vector that drives a router selecting latent experts for each spatial region of the pooled document features; the routed outputs are then scored with MaxSim. The architecture keeps the output format identical to existing late-interaction indexes, uses a 1024-dimensional retrieval head, and trains on approximately 9 percent of available public supervision. The 9B model achieves 92.67 NDCG@5 on ViDoRe V1 and 86.0 on the combined V1+V2 leaderboard, while the same retriever inside a Qwen3.6-27B agentic loop rai
What carries the argument
region-aware query-conditioned Mixture-of-Experts module that routes latent experts to pooled spatial regions of the document using a query-derived context vector before MaxSim
If this is right
- Document representations become query-dependent (D(q)) while the multi-vector index format stays unchanged and directly usable by existing ColPali-style engines.
- A 1024-dimensional retrieval head suffices, reducing storage and compute relative to 2560- or 4096-dimensional heads in prior systems.
- Strong benchmark results are obtained after training on only 9 percent of public supervision data.
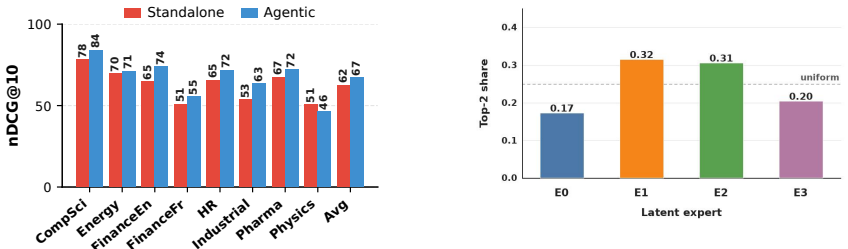
- The same retriever functions both as a standalone system and as a primitive inside iterative LLM agent pipelines, where it raises NDCG@10 on ViDoRe V3 tasks.
Where Pith is reading between the lines
- The same region-routing idea could be applied to other late-interaction architectures that currently encode documents independently of the query.
- Because the router operates on pooled regions rather than every token, the added cost remains modest enough for large-scale indexing.
- If the performance edge holds on new visual-document corpora, the method may reduce reliance on ever-larger vision-language backbones for retrieval.
Load-bearing premise
A query-aware router that picks experts separately for each spatial region on pooled document features will deliver consistent gains across query types without breaking MaxSim compatibility.
What would settle it
Running the identical 9B backbone with the MoE router disabled and measuring whether NDCG@5 on ViDoRe V1 drops below 92.67 or rises above it.
Figures

read the original abstract
Late-interaction vision-language retrievers represent each document page as many visual token embeddings and score queries with MaxSim. In systems such as ColPali, ColQwen, ColNomic, and Nemotron ColEmbed, the document embeddings are produced without seeing the query, so the same page is represented identically for a table lookup, a chart question, and a layout-sensitive evidence request. We introduce \textbf{Argus}, a family of query-conditioned late-interaction retrievers built on Qwen3.5-VL. Argus adds a region-aware Mixture-of-Experts module: the query encoder produces both retrieval embeddings and a compact context vector, the document page is pooled into spatial regions, and a query-aware router selects latent experts per region before MaxSim. The output remains a multi-vector index compatible with ColPali-style retrieval, but the document representation is now dependent on the query (i.e., $\mathbf{D}(q)$). All Argus models use a 1024-dimensional retrieval head, compared with the 2560-dimensional and 4096-dimensional heads of recent state-of-the-art systems, and are trained on roughly 9\% of the available public supervision rather than the full pool. The 9B model reaches \textbf{92.67} NDCG@5 on ViDoRe V1 and \textbf{86.0} NDCG@5 on the combined V1+V2 leaderboard, the highest reported value for an open late-interaction model on the combined leaderboard. Wrapped in a Qwen3.6-27B agentic retrieval pipeline on ViDoRe V3, Argus-9B further improves its NDCG@10 from 60.28 to \textbf{64.80} over public tasks, showing that the same retriever serves both as a strong standalone system and as a search primitive for iterative LLM agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Argus, a family of query-conditioned late-interaction vision-language retrievers built on Qwen3.5-VL. It augments standard MaxSim scoring with a region-aware query-conditioned MoE module: the query produces both embeddings and a context vector, document pages are pooled into spatial regions, and a query-aware router selects experts per region. The resulting multi-vector representations are claimed to remain compatible with ColPali-style indexes despite being D(q). Models use a 1024-dim retrieval head and are trained on ~9% of public data; the 9B variant reports 92.67 NDCG@5 on ViDoRe V1 and 86.0 on the V1+V2 combined leaderboard (highest for open late-interaction models), with further gains when wrapped in a 27B agentic pipeline on ViDoRe V3.
Significance. If the architectural mechanism for query conditioning preserves pre-computable, query-independent document indexes while still delivering the reported gains, the work would demonstrate a practical route to query-adaptive multi-vector retrieval for visual documents at lower parameter and data cost than prior ColPali-style systems. The empirical numbers, if reproducible, would establish a new reference point on the ViDoRe leaderboards.
major comments (1)
- [Abstract] Abstract: the statement that 'the output remains a multi-vector index compatible with ColPali-style retrieval, but the document representation is now dependent on the query (i.e., D(q))' is load-bearing for both the efficiency claim and the direct comparison to baselines. No equation, diagram, or description is supplied showing how the query-aware router (applied to pooled document spatial regions) is realized without either (a) re-encoding documents at query time or (b) an auxiliary mechanism that keeps the final indexed vectors query-independent. This architectural detail must be provided before the compatibility and scalability claims can be evaluated.
minor comments (1)
- [Abstract] The abstract states benchmark numbers and training scale but supplies no experimental protocol, baseline list, statistical tests, or ablation details; these must be added for the performance claims to be verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the identification of an important omission in our architectural description. We agree that the compatibility and efficiency claims hinge on a clear explanation of the query-aware router and will revise the manuscript to supply the requested equations, diagram, and implementation details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'the output remains a multi-vector index compatible with ColPali-style retrieval, but the document representation is now dependent on the query (i.e., D(q))' is load-bearing for both the efficiency claim and the direct comparison to baselines. No equation, diagram, or description is supplied showing how the query-aware router (applied to pooled document spatial regions) is realized without either (a) re-encoding documents at query time or (b) an auxiliary mechanism that keeps the final indexed vectors query-independent. This architectural detail must be provided before the compatibility and scalability claims can be evaluated.
Authors: We agree that the current manuscript does not supply the requested equation, diagram, or description of the router implementation. This is a genuine gap. In the revised version we will add a dedicated subsection (with equations and a new figure) in the Model Architecture section. The added material will describe the auxiliary mechanism: the query context vector produces router logits; each document spatial region is encoded offline by all MoE experts, yielding multiple pre-computed embeddings per region that are stored in the index; at retrieval time the router selects (or gates) one expert embedding per region for the MaxSim computation. This keeps every indexed vector query-independent while the effective document representation used for scoring is D(q). We will also update the abstract and efficiency discussion to reference this mechanism explicitly. revision: yes
Circularity Check
No circularity; empirical results on public benchmarks
full rationale
The paper describes a new query-conditioned MoE architecture for late-interaction retrieval and reports NDCG scores on ViDoRe V1/V2/V3 benchmarks. No derivation chain, first-principles prediction, or fitted parameter is presented that reduces to its own inputs by construction. The D(q) claim is an architectural assertion whose compatibility with precomputed indexing is stated but not derived mathematically; performance numbers are direct empirical measurements rather than quantities forced by internal fitting or self-citation. The central claims rest on external benchmark evaluation, not on any self-referential loop.
Axiom & Free-Parameter Ledger
free parameters (3)
- retrieval head dimension =
1024
- training data fraction =
9%
- number of experts and router capacity
axioms (2)
- domain assumption ViDoRe V1/V2/V3 benchmarks are valid and representative measures of visual document retrieval quality
- domain assumption MaxSim scoring remains an effective similarity measure after query-conditioned region routing
invented entities (1)
-
region-aware query-conditioned MoE module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[2]
International Conference on Learning Representations , volume=
Colpali: Efficient document retrieval with vision language models , author=. International Conference on Learning Representations , volume=
-
[3]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[4]
Forty-first International Conference on Machine Learning , year=
Prismatic vlms: Investigating the design space of visually-conditioned language models , author=. Forty-first International Conference on Machine Learning , year=
-
[5]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
BERT rediscovers the classical NLP pipeline , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[6]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[7]
Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
Colbert: Efficient and effective passage search via contextualized late interaction over bert , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[8]
PaliGemma: A versatile 3B VLM for transfer
Paligemma: A versatile 3b vlm for transfer , author=. arXiv preprint arXiv:2407.07726 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2501.14818 , year=
Eagle 2: Building post-training data strategies from scratch for frontier vision-language models , author=. arXiv preprint arXiv:2501.14818 , year=
-
[12]
Nomic embed multimodal: Interleaved text, image, and screenshots for visual document retrieval, 2025 , author=
2025
-
[13]
arXiv preprint arXiv:2602.03992 , year=
Nemotron ColEmbed V2: Top-Performing Late Interaction embedding models for Visual Document Retrieval , author=. arXiv preprint arXiv:2602.03992 , year=
-
[14]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[17]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[18]
arXiv preprint arXiv:2407.15831 , year=
NV-Retriever: Improving text embedding models with effective hard-negative mining , author=. arXiv preprint arXiv:2407.15831 , year=
-
[19]
2026 , howpublished =
2026
-
[20]
arXiv preprint arXiv:2505.11651 , year=
Miracl-vision: A large, multilingual, visual document retrieval benchmark , author=. arXiv preprint arXiv:2505.11651 , year=
-
[21]
athrael-soju , year =
-
[22]
ACM Transactions on Information Systems , volume=
Came: Competitively learning a mixture-of-experts model for first-stage retrieval , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[23]
arXiv preprint arXiv:2502.07972 , year=
Training sparse mixture of experts text embedding models , author=. arXiv preprint arXiv:2502.07972 , year=
-
[24]
Leveraging Cognitive Complexity of Texts for Contextualization in Dense Retrieval
Sokli, Effrosyni and Peikos, Georgios and Kasela, Pranav and Pasi, Gabriella. Leveraging Cognitive Complexity of Texts for Contextualization in Dense Retrieval. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1377
-
[25]
2025 , howpublished =
2025
-
[26]
2024 , howpublished =
2024
-
[27]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[28]
arXiv preprint arXiv:2601.09562 , year=
MM-BRIGHT: A Multi-Task Multimodal Benchmark for Reasoning-Intensive Retrieval , author=. arXiv preprint arXiv:2601.09562 , year=
-
[29]
Are LLM-Based Retrievers Worth Their Cost? An Empirical Study of Efficiency, Robustness, and Reasoning Overhead , author=. arXiv preprint arXiv:2604.03676 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
arXiv preprint arXiv:2508.16998 , year=
Dear: Dual-stage document reranking with reasoning agents via llm distillation , author=. arXiv preprint arXiv:2508.16998 , year=
-
[31]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[32]
Proceedings of the 30th ACM international conference on multimedia , pages=
Layoutlmv3: Pre-training for document ai with unified text and image masking , author=. Proceedings of the 30th ACM international conference on multimedia , pages=
-
[33]
arXiv preprint arXiv:1910.14424 , year=
Multi-stage document ranking with BERT , author=. arXiv preprint arXiv:1910.14424 , year=
-
[34]
International conference on machine learning , pages=
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[35]
Advances in Neural Information Processing Systems , volume=
Stark: Benchmarking llm retrieval on textual and relational knowledge bases , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval , pages=
Optimizing dense retrieval model training with hard negatives , author=. Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.