Measuring What Matters: Synthetic Benchmarks for Concept Bottleneck Models
Pith reviewed 2026-06-28 07:25 UTC · model grok-4.3
The pith
Synthetic benchmarks generate labeled datasets while controlling modality, concept choice, annotation quality, and completeness to evaluate concept bottleneck models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
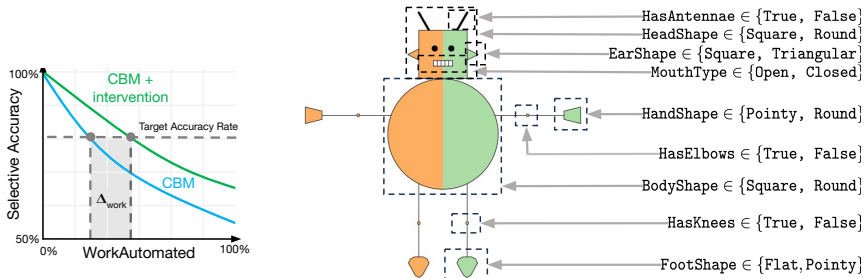
The paper develops synthetic benchmarks for concept-bottleneck models that generate labeled datasets while controlling for data modality, concept choice, annotation quality, and completeness. The benchmarks support evaluation in decision support and automation settings, and the demonstrations illustrate how they diagnose failure modes and guide follow-up testing.
What carries the argument
Synthetic benchmark generator that produces labeled datasets while varying modality, concept choice, annotation quality, and completeness.
If this is right
- Researchers can identify which problems are suitable for concept bottleneck models.
- Factors that drive performance or cause failures can be isolated systematically.
- Which algorithms work well under specific controlled conditions can be uncovered.
- Follow-up testing in real settings can be guided by synthetic results.
Where Pith is reading between the lines
- The same generator approach could be adapted to create test beds for other interpretable prediction methods that also need scarce concept labels.
- If synthetic controls predict real behavior, practitioners could run cheap pre-deployment checks before collecting expensive human annotations.
- Findings on annotation quality might push development of automated concept labeling tools that target the error types shown to matter most.
Load-bearing premise
The properties controlled in the synthetic data, such as modality and annotation quality, are the main drivers of how concept bottleneck models perform on real data.
What would settle it
A real-world dataset where concept bottleneck model accuracy or failure rates do not align with the patterns predicted by the controlled properties in the synthetic benchmarks.
Figures


read the original abstract
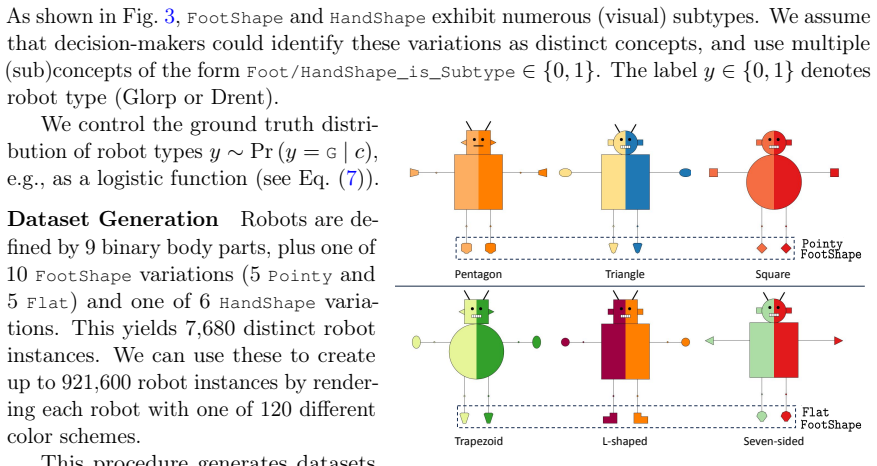
Concept bottleneck models predict outcomes from high-level concepts detected in inputs. Although concepts provide a simple way to reap benefits from interpretability, very few datasets include concept labels. This limits researchers' ability to determine which problems are suitable for these models, isolate the factors that drive their performance or lead to failures, or uncover which algorithms perform well. In this paper, we develop synthetic benchmarks for concept-bottleneck models, focusing on their two main use cases: decision support, in which models assist humans in making better decisions, and automation, in which models handle routine tasks without supervision. Our benchmarks can generate labeled datasets while controlling for properties that affect performance, including data modality, concept choice, annotation quality, and completeness. We demonstrate how the benchmarks can be used to evaluate representative classes of concept bottleneck models. Our demonstrations show how the benchmarks can diagnose failure modes and guide follow-up testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops synthetic benchmarks for concept bottleneck models (CBMs) focused on decision support and automation use cases. The benchmarks generate labeled datasets while controlling for data modality, concept choice, annotation quality, and completeness to help researchers identify suitable problems for CBMs, isolate performance factors, and diagnose failure modes. Demonstrations on representative CBM classes are described to illustrate these capabilities.
Significance. If the controls can be realized independently and the diagnostic power transfers beyond synthetic data, the benchmarks would address a key limitation in CBM research—the scarcity of concept-labeled datasets—and enable more systematic evaluation of interpretability benefits. The emphasis on controllable synthetic generation is a positive step toward reproducibility in this area.
major comments (2)
- [Abstract] Abstract: The central claim that the benchmarks 'can generate labeled datasets while controlling for properties that affect performance' is load-bearing, yet the manuscript provides no implementation details, generator pseudocode, or validation experiments confirming that the four axes (modality, concept choice, annotation quality, completeness) can be varied independently without introducing unintended correlations.
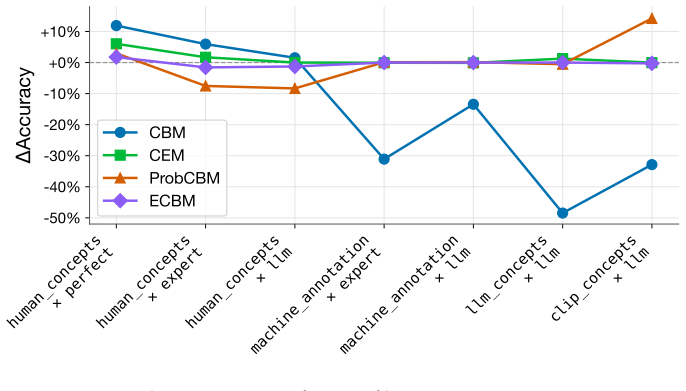
- [Abstract] Abstract: The statement that 'our demonstrations show how the benchmarks can diagnose failure modes and guide follow-up testing' is unsupported by any quantitative results, tables, figures, or specific findings; without these, it is not possible to assess whether the controlled properties actually drive CBM behavior as assumed.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on the abstract. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the benchmarks 'can generate labeled datasets while controlling for properties that affect performance' is load-bearing, yet the manuscript provides no implementation details, generator pseudocode, or validation experiments confirming that the four axes (modality, concept choice, annotation quality, completeness) can be varied independently without introducing unintended correlations.
Authors: We agree that the abstract does not contain these supporting details and that the claim is central. The full manuscript describes the generation process in Section 3, but we will add a concise description of the generator, reference to the pseudocode (Algorithm 1), and a summary of the independence validation (correlation matrices in Section 4.1) directly into the abstract. We will also expand the validation experiments if needed to explicitly demonstrate independent control of the four axes. revision: yes
-
Referee: [Abstract] Abstract: The statement that 'our demonstrations show how the benchmarks can diagnose failure modes and guide follow-up testing' is unsupported by any quantitative results, tables, figures, or specific findings; without these, it is not possible to assess whether the controlled properties actually drive CBM behavior as assumed.
Authors: The demonstrations section includes quantitative results (accuracy and concept accuracy metrics across controlled settings) and figures illustrating failure modes, but these are not referenced in the abstract. We will revise the abstract to include one or two key quantitative findings (e.g., performance drops under incomplete concept annotations) and cite the relevant tables/figures so readers can immediately assess the diagnostic value. revision: yes
Circularity Check
No circularity; benchmark creation is constructive
full rationale
The paper's contribution is the design and implementation of synthetic data generators that explicitly control modality, concept choice, annotation quality, and completeness for CBM evaluation. This is a forward construction of testbeds rather than any derivation, prediction, or uniqueness claim that reduces to fitted parameters or self-citations. No equations or load-bearing steps are present that equate outputs to inputs by definition. Demonstrations occur inside the generated data by design, as is standard for benchmark papers, and do not rely on external self-citation chains or ansatzes smuggled from prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic data controls can faithfully capture the factors that drive CBM performance and failures in real settings
Reference graph
Works this paper leans on
-
[1]
Cebab: Estimating the causal effects of real-world concepts on nlp model behavior.Advances in Neural Information Processing Systems, 35: 17582–17596, 2022
Eldar D Abraham, Karel D’Oosterlinck, Amir Feder, Yair Gat, Atticus Geiger, Christopher Potts, Roi Reichart, and Zhengxuan Wu. Cebab: Estimating the causal effects of real-world concepts on nlp model behavior.Advances in Neural Information Processing Systems, 35: 17582–17596, 2022
2022
-
[2]
Melanoma classification from dermatoscopy images using knowledge distillation for highly imbalanced data.Computers in Biology and Medicine, 154:106571, 2023
Anil Kumar Adepu, Subin Sahayam, Umarani Jayaraman, and Rashmika Arramraju. Melanoma classification from dermatoscopy images using knowledge distillation for highly imbalanced data.Computers in Biology and Medicine, 154:106571, 2023
2023
-
[3]
Meeting the moment: addressing barriers and facilitating clinical adoption of artificial intelligence in medical diagnosis.NAM perspectives, 2022:10–31478, 2022
Julia Adler-Milstein, Nakul Aggarwal, Mahnoor Ahmed, Jessica Castner, Barbara J Evans, Andrew A Gonzalez, Cornelius A James, Steven Lin, Kenneth D Mandl, Michael E Matheny, et al. Meeting the moment: addressing barriers and facilitating clinical adoption of artificial intelligence in medical diagnosis.NAM perspectives, 2022:10–31478, 2022
2022
-
[4]
The meta-analysis of clinical judgment project: Fifty-six years of accumulated research on clinical versus statistical prediction.The counseling psychologist, 34(3):341–382, 2006
Stefanía Ægisdóttir, Michael J White, Paul M Spengler, Alan S Maugherman, Linda A Anderson, Robert S Cook, Cassandra N Nichols, Georgios K Lampropoulos, Blain S Walker, Genna Cohen, et al. The meta-analysis of clinical judgment project: Fifty-six years of accumulated research on clinical versus statistical prediction.The counseling psychologist, 34(3):341...
2006
-
[5]
23 years of the discovery of helicobacter pylori: is the debate over?Annals of clinical microbiology and antimicrobials, 4(1):17, 2005
Niyaz Ahmed. 23 years of the discovery of helicobacter pylori: is the debate over?Annals of clinical microbiology and antimicrobials, 4(1):17, 2005
2005
-
[6]
Cross-modal conceptualization in bottleneck models.arXiv preprint arXiv:2310.14805, 2023
Danis Alukaev, Semen Kiselev, Ilya Pershin, Bulat Ibragimov, Vladimir Ivanov, Alexey Kor- naev, and Ivan Titov. Cross-modal conceptualization in bottleneck models.arXiv preprint arXiv:2310.14805, 2023. 12
arXiv 2023
-
[7]
Vaibhav Balloli, Sara Beery, and Elizabeth Bondi-Kelly. Are they the same picture? adapting concept bottleneck models for human-ai collaboration in image retrieval.arXiv preprint arXiv:2407.08908, 2024
arXiv 2024
-
[8]
Relational concept bottleneck models.Advances in Neural Information Processing Systems, 37:77663–77685, 2024
Pietro Barbiero, Francesco Giannini, Gabriele Ciravegna, Michelangelo Diligenti, and Giuseppe Marra. Relational concept bottleneck models.Advances in Neural Information Processing Systems, 37:77663–77685, 2024
2024
-
[9]
Dermatologist-like explainable ai enhances trust and confidence in diagnosing melanoma.Nature Communications, 15(1):524, 2024
Tirtha Chanda, Katja Hauser, Sarah Hobelsberger, Tabea-Clara Bucher, Carina Nogueira Gar- cia, Christoph Wies, Harald Kittler, Philipp Tschandl, Cristian Navarrete-Dechent, Sebastian Podlipnik, et al. Dermatologist-like explainable ai enhances trust and confidence in diagnosing melanoma.Nature Communications, 15(1):524, 2024
2024
-
[10]
Chowdhury, Vu Minh Hieu Phan, Kewen Liao, Minh-Son To, Yutong Xie, Anton van den Hengel, Johan W
Townim F. Chowdhury, Vu Minh Hieu Phan, Kewen Liao, Minh-Son To, Yutong Xie, Anton van den Hengel, Johan W. Verjans, and Zhibin Liao. Adacbm: An adaptive concept bottleneck model for explainable and accurate diagnosis. InMICCAI 2024 (LNCS 15010), 2024. URL https://papers.miccai.org/miccai-2024/paper/3895_paper.pdf
2024
-
[11]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3606–3613, June 2014
2014
-
[12]
Document ai helps automate document processing to support constituent services, November 2022
Google Cloud. Document ai helps automate document processing to support constituent services, November 2022. URLhttps://shorturl.at/a9GtI. Google Cloud Blog
2022
-
[13]
Human uncertainty in concept-based ai systems
Katherine Maeve Collins, Matthew Barker, Mateo Espinosa Zarlenga, Naveen Raman, Umang Bhatt, Mateja Jamnik, Ilia Sucholutsky, Adrian Weller, and Krishnamurthy Dvijotham. Human uncertainty in concept-based ai systems. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, pages 869–889, 2023
2023
-
[14]
Skincon: A skin disease dataset densely annotated by domain experts for fine-grained debugging and analysis.Advances in Neural Information Processing Systems, 35:18157–18167, 2022
Roxana Daneshjou, Mert Yuksekgonul, Zhuo Ran Cai, Roberto Novoa, and James Y Zou. Skincon: A skin disease dataset densely annotated by domain experts for fine-grained debugging and analysis.Advances in Neural Information Processing Systems, 35:18157–18167, 2022
2022
-
[15]
A review of some techniques for inclusion of domain-knowledge into deep neural networks.Scientific Reports, 12 (1):1040, 2022
Tirtharaj Dash, Sharad Chitlangia, Aditya Ahuja, and Ashwin Srinivasan. A review of some techniques for inclusion of domain-knowledge into deep neural networks.Scientific Reports, 12 (1):1040, 2022
2022
-
[16]
Causally reliable concept bottleneck models
Giovanni De Felice, Arianna Casanova Flores, Francesco De Santis, Silvia Santini, Johannes Schneider, Pietro Barbiero, and Alberto Termine. Causally reliable concept bottleneck models. arXiv preprint arXiv:2503.04363, 2025
arXiv 2025
-
[17]
Streamlining tax and administrative document management with ai-powered intelligent document management system.Information, 15(8):461, 2024
Giovanna Di Marzo Serugendo, Maria Assunta Cappelli, Gilles Falquet, Claudine Métral, Assane Wade, Sami Ghadfi, Anne-Françoise Cutting-Decelle, Ashley Caselli, and Graham Cutting. Streamlining tax and administrative document management with ai-powered intelligent document management system.Information, 15(8):461, 2024
2024
-
[18]
Retiring adult: New datasets for fair machine learning.Advances in neural information processing systems, 34:6478–6490, 2021
Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. Retiring adult: New datasets for fair machine learning.Advances in neural information processing systems, 34:6478–6490, 2021
2021
-
[19]
Gabriele Dominici, Pietro Barbiero, Mateo Espinosa Zarlenga, Alberto Termine, Martin Gjoreski, Giuseppe Marra, and Marc Langheinrich. Causal concept graph models: Beyond causal opacity in deep learning.arXiv preprint arXiv:2405.16507, 2024. 13
arXiv 2024
-
[20]
Clinical diagnosis of melanoma.American Family Physician, 78(10):1205–1208, 2008
Mark Ebell. Clinical diagnosis of melanoma.American Family Physician, 78(10):1205–1208, 2008
2008
-
[21]
On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(53):1605–1641, 2010
Ran El-Yaniv and Yair Wiener. On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(53):1605–1641, 2010. URLhttps://jmlr.org/papers/ v11/el-yaniv10a.html
2010
-
[22]
Learning to receive help: Intervention-aware concept embedding models.Advances in Neural Information Processing Systems, 36, 2024
Mateo Espinosa Zarlenga, Katie Collins, Krishnamurthy Dvijotham, Adrian Weller, Zohreh Shams, and Mateja Jamnik. Learning to receive help: Intervention-aware concept embedding models.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[23]
Andre Esteva, Brett Kuprel, Roberto A. Novoa, Justin Ko, Susan M. Swetter, Helen M. Blau, and Sebastian Thrun. Dermatologist-level classification of skin cancer with deep neural networks.Nature, 542(7639):115–118, 2017. doi: 10.1038/nature21056
-
[24]
Bayesian concept bottleneck models with llm priors
Jean Feng, Avni Kothari, Luke Zier, Chandan Singh, and Yan Shuo Tan. Bayesian concept bottleneck models with llm priors. InarXiv 2024; ICLR 2025 Workshop (XAI4Science), 2024. URLhttps://arxiv.org/pdf/2410.15555
arXiv 2024
-
[25]
Selective classification via one-sided prediction
Aditya Gangrade, Anil Kag, and Venkatesh Saligrama. Selective classification via one-sided prediction. InInternational Conference on Artificial Intelligence and Statistics, pages 2179–2187. PMLR, 2021
2021
-
[26]
Evidential concept embedding models: Towards reliable concept explanations for skin disease diagnosis
Yibo Gao, Zheyao Gao, Xin Gao, Yuanye Liu, Bomin Wang, and Xiahai Zhuang. Evidential concept embedding models: Towards reliable concept explanations for skin disease diagnosis. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 308–317. Springer, 2024
2024
-
[27]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Gar- nett, editors,Advances in Neural Information Processing Systems, volume 30. Curran As- sociates, Inc., 2017. URL https://proceedings.neurips.cc/paper/2017/file/ 4a8423d5e91fda00bb7...
2017
-
[28]
Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems, 35:507–520, 2022
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems, 35:507–520, 2022
2022
-
[29]
Clinical versus mechanical prediction: a meta-analysis.Psychological assessment, 12(1):19, 2000
William M Grove, David H Zald, Boyd S Lebow, Beth E Snitz, and Chad Nelson. Clinical versus mechanical prediction: a meta-analysis.Psychological assessment, 12(1):19, 2000
2000
-
[30]
Robotic process automation for document processing: A case study of a logistics service provider.Journal of Management, 36(2):119–126, 2020
Valentas Gruzauskas and Diwakaran Ragavan. Robotic process automation for document processing: A case study of a logistics service provider.Journal of Management, 36(2):119–126, 2020
2020
-
[31]
Di-cnn: Domain- knowledge-informed convolutional neural network for manufacturing quality prediction.Sensors, 23(11):5313, 2023
Shenghan Guo, Dali Wang, Zhili Feng, Jian Chen, and Weihong Guo. Di-cnn: Domain- knowledge-informed convolutional neural network for manufacturing quality prediction.Sensors, 23(11):5313, 2023
2023
-
[32]
Addressing leakage in concept bottleneck models.Advances in Neural Information Processing Systems, 35:23386–23397, 2022
Marton Havasi, Sonali Parbhoo, and Finale Doshi-Velez. Addressing leakage in concept bottleneck models.Advances in Neural Information Processing Systems, 35:23386–23397, 2022
2022
-
[33]
V2c-cbm: Building concept bottlenecks with vision-to-concept tokenizer
Hangzhou He, Lei Zhu, Xinliang Zhang, Shuang Zeng, Qian Chen, and Yanye Lu. V2c-cbm: Building concept bottlenecks with vision-to-concept tokenizer. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 3401–3409, 2025. 14
2025
-
[34]
Concept-attention whitening for interpretable skin lesion diagnosis
Junlin Hou, Jilan Xu, and Hao Chen. Concept-attention whitening for interpretable skin lesion diagnosis. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 113–123. Springer, 2024
2024
-
[35]
Semi-supervised concept bottleneck models.arXiv preprint, 2024
Liang Hu, Tian Huang, Haoran Xie, Chenyang Ren, Zhengyu Hu, Lei Yu, Defu Lian, and Dianhai Wang. Semi-supervised concept bottleneck models.arXiv preprint, 2024. URL https://arxiv.org/pdf/2406.18992
arXiv 2024
-
[36]
Stable vision concept transformers for medical diagnosis.arXiv preprint arXiv:2506.05286, 2025
Lijie Hu, Songning Lai, Yuan Hua, Shu Yang, Jingfeng Zhang, and Di Wang. Stable vision concept transformers for medical diagnosis.arXiv preprint arXiv:2506.05286, 2025
arXiv 2025
-
[37]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 590–597, 2019
2019
-
[38]
Concept bottleneck generative models
Aya Abdelsalam Ismail, Julius Adebayo, Hector Corrada Bravo, Stephen Ra, and Kyunghyun Cho. Concept bottleneck generative models. InICLR 2024 (poster), 2024. URL https: //openreview.net/pdf?id=L9U5MJJleF
2024
-
[39]
Locality-aware concept bottleneck model.arXiv preprint arXiv:2508.14562, 2025
Sujin Jeon, Hyundo Lee, Eungseo Kim, Sanghack Lee, Byoung-Tak Zhang, and Inwoo Hwang. Locality-aware concept bottleneck model.arXiv preprint arXiv:2508.14562, 2025. doi: 10. 48550/arXiv.2508.14562. URLhttps://arxiv.org/abs/2508.14562
arXiv 2025
-
[40]
Yiwen Jiang, Deval Mehta, Wei Feng, and Zongyuan Ge. Enhancing interpretable image classification through llm agents and conditional concept bottleneck models.arXiv preprint arXiv:2506.01334, 2025
arXiv 2025
-
[41]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017
2017
-
[42]
Classification with conceptual safeguards, 2024
Hailey Joren, Charles Marx, and Berk Ustun. Classification with conceptual safeguards, 2024. URLhttps://arxiv.org/abs/2411.04342
arXiv 2024
-
[43]
Cognitive alignment in cardiovascular ai: designing predictive models that think with, not just for, clinicians.Frontiers in Cardiovascular Medicine, 12: 1651324, 2025
Jeena Joseph and K Kartheeban. Cognitive alignment in cardiovascular ai: designing predictive models that think with, not just for, clinicians.Frontiers in Cardiovascular Medicine, 12: 1651324, 2025
2025
-
[44]
Melanoma classifi- cation using a novel deep convolutional neural network with dermoscopic images.Sensors, 22 (3):1134, 2022
Ranpreet Kaur, Hamid GholamHosseini, Roopak Sinha, and Maria Lindén. Melanoma classifi- cation using a novel deep convolutional neural network with dermoscopic images.Sensors, 22 (3):1134, 2022
2022
-
[45]
Seven-point checklist and skin lesion classification using multitask multimodal neural nets.IEEE journal of biomedical and health informatics, 23(2):538–546, 2018
Jeremy Kawahara, Sara Daneshvar, Giuseppe Argenziano, and Ghassan Hamarneh. Seven-point checklist and skin lesion classification using multitask multimodal neural nets.IEEE journal of biomedical and health informatics, 23(2):538–546, 2018
2018
-
[46]
Probabilistic concept bottleneck models.arXiv preprint arXiv:2306.01574, 2023
Eunji Kim, Dahuin Jung, Sangha Park, Siwon Kim, and Sungroh Yoon. Probabilistic concept bottleneck models.arXiv preprint arXiv:2306.01574, 2023
arXiv 2023
-
[47]
Concept bottleneck with visual concept filtering for explainable medical image classification
Injae Kim, Jongha Kim, Joonmyung Choi, and Hyunwoo J Kim. Concept bottleneck with visual concept filtering for explainable medical image classification. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 225–233. Springer, 2023. 15
2023
-
[48]
Eq-cbm: A probabilistic concept bottleneck with energy-based models and quantized vectors
Sangwon Kim, Dasom Ahn, Byoung Chul Ko, In-su Jang, and Kwang-Ju Kim. Eq-cbm: A probabilistic concept bottleneck with energy-based models and quantized vectors. InACCV, 2024
2024
-
[49]
Concept Bottleneck Models, December 2020
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept Bottleneck Models, December 2020. URLhttp://arxiv. org/abs/2007.04612. arXiv:2007.04612 [cs]
arXiv 2020
-
[50]
Wilds: A benchmark of in-the-wild distribution shifts
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. Wilds: A benchmark of in-the-wild distribution shifts. InInternational conference on machine learning, pages 5637–5664. PMLR, 2021
2021
-
[51]
Cat: Concept-level backdoor attacks for concept bottleneck models
Songning Lai, Jiayu Yang, Yu Huang, Lijie Hu, Tianlang Xue, Zhangyi Hu, Jiaxu Li, Haicheng Liao, and Yutao Yue. Cat: Concept-level backdoor attacks for concept bottleneck models. arXiv preprint arXiv:2410.04823, 2024
arXiv 2024
-
[52]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of International Conference on Computer Vision (ICCV), December 2015
2015
-
[53]
Promises and pitfalls of black-box concept learning models.arXiv preprint arXiv:2106.13314, 2021
Anita Mahinpei, Justin Clark, Isaac Lage, Finale Doshi-Velez, and Weiwei Pan. Promises and pitfalls of black-box concept learning models.arXiv preprint arXiv:2106.13314, 2021
arXiv 2021
-
[54]
Mikael Makonnen, Moritz Vandenhirtz, Sonia Laguna, and Julia E Vogt. Measuring leakage in concept-based methods: An information theoretic approach.arXiv preprint arXiv:2504.09459, 2025
arXiv 2025
-
[55]
There is no 16-clue sudoku: Solving the sudoku minimum number of clues problem, 2013
Gary McGuire, Bastian Tugemann, and Gilles Civario. There is no 16-clue sudoku: Solving the sudoku minimum number of clues problem, 2013. URLhttps://arxiv.org/abs/1201. 0749
2013
-
[56]
Teresa Mendonça, Pedro M. Ferreira, Jorge S. Marques, André R. S. Marçal, and Jorge Rozeira. PH2: A dermoscopic image database for research and benchmarking. In35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pages 5437–5440. IEEE, 2013. doi: 10.1109/EMBC.2013.6610779
-
[57]
Advancing dermatological diagnostics: interpretable ai for enhanced skin lesion classification.Diagnostics, 14(7):753, 2024
Carlo Metta, Andrea Beretta, Riccardo Guidotti, Yuan Yin, Patrick Gallinari, Salvatore Rinzivillo, and Fosca Giannotti. Advancing dermatological diagnostics: interpretable ai for enhanced skin lesion classification.Diagnostics, 14(7):753, 2024
2024
-
[58]
The osteoarthritis initiative.Protocol for the cohort study, 1, 2006
M Nevitt, D Felson, and Gayle Lester. The osteoarthritis initiative.Protocol for the cohort study, 1, 2006
2006
-
[59]
Tuomas Oikarinen and Tsui-Wei Weng. Clip-dissect: Automatic description of neuron repre- sentations in deep vision networks.arXiv preprint arXiv:2204.10965, 2022
arXiv 2022
-
[60]
Label-free concept bottleneck models.arXiv preprint arXiv:2304.06129, 2023
Tuomas Oikarinen, Subhro Das, Lam M Nguyen, and Tsui-Wei Weng. Label-free concept bottleneck models.arXiv preprint arXiv:2304.06129, 2023
arXiv 2023
-
[61]
Ai-based integrated approach for the development of intelligent document management system (idms).Procedia Computer Science, 230:725–736, 2023
Mrinal Pandey, Mamta Arora, Shraddha Arora, Charu Goyal, Varun Kumar Gera, and Harsh Yadav. Ai-based integrated approach for the development of intelligent document management system (idms).Procedia Computer Science, 230:725–736, 2023
2023
-
[62]
Integrating clinical knowledge into concept bottleneck models
Winnie Pang, Xueyi Ke, Satoshi Tsutsui, and Bihan Wen. Integrating clinical knowledge into concept bottleneck models. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 243–253. Springer, 2024. 16
2024
-
[63]
Coarse-to-fine concept bottleneck models.Advances in Neural Information Processing Systems, 37:105171–105199, 2024
Konstantinos P Panousis, Dino Ienco, and Diego Marcos. Coarse-to-fine concept bottleneck models.Advances in Neural Information Processing Systems, 37:105171–105199, 2024
2024
-
[64]
Leakage and interpretability in concept-based models.arXiv preprint arXiv:2504.14094, 2025
Enrico Parisini, Tapabrata Chakraborti, Chris Harbron, Ben D MacArthur, and Christopher RS Banerji. Leakage and interpretability in concept-based models.arXiv preprint arXiv:2504.14094, 2025
arXiv 2025
-
[65]
Seonghwan Park, Jueun Mun, Donghyun Oh, and Namhoon Lee. An analysis of concept bottleneck models: Measuring, understanding, and mitigating the impact of noisy annotations. arXiv preprint arXiv:2505.16705, 2025
arXiv 2025
-
[66]
Pref- erence optimization for concept bottleneck models
Emiliano Penaloza, Tianyue H Zhang, Laurent Charlin, and Mateo Espinosa Zarlenga. Pref- erence optimization for concept bottleneck models. InICLR 2025 Workshop on Human-AI Coevolution, 2025
2025
-
[67]
Andrea Pugnana, Riccardo Massidda, Francesco Giannini, Pietro Barbiero, Mateo Espinosa Zarlenga, Roberto Pellungrini, Gabriele Dominici, Fosca Giannotti, and Davide Bacciu. Defer- ring concept bottleneck models: Learning to defer interventions to inaccurate experts.arXiv preprint arXiv:2503.16199, 2025
arXiv 2025
-
[68]
Vip-cbm: Reducing parameters in concept bottleneck models by visual-projected embeddings
Ji Qi, Huisheng Wang, and H Vicky Zhao. Vip-cbm: Reducing parameters in concept bottleneck models by visual-projected embeddings. In2024 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pages 1–6. IEEE, 2024
2024
-
[69]
Do concept bottleneck models respect localities?arXiv preprint arXiv:2401.01259, 2024
Naveen Raman, Mateo Espinosa Zarlenga, Juyeon Heo, and Mateja Jamnik. Do concept bottleneck models respect localities?arXiv preprint arXiv:2401.01259, 2024
arXiv 2024
-
[70]
Discover-then-name: Task- agnostic concept bottlenecks via automated concept discovery
Sukrut Rao, Sweta Mahajan, Moritz Böhle, and Bernt Schiele. Discover-then-name: Task- agnostic concept bottlenecks via automated concept discovery. InEuropean Conference on Computer Vision, pages 444–461. Springer, 2024
2024
-
[71]
A theoretical design of con- cept sets: improving the predictability of concept bottleneck models
Max Ruiz Luyten and Mihaela van der Schaar. A theoretical design of con- cept sets: improving the predictability of concept bottleneck models. InAd- vances in Neural Information Processing Systems, volume 37, 2024. doi: 10.52202/ 079017-3178. URL https://proceedings.neurips.cc/paper_files/paper/2024/ hash/b5a412531110b92961fa13c90938806a-Abstract-Conference.html
2024
-
[72]
Concept bottleneck models without predefined concepts.arXiv preprint arXiv:2407.03921, 2024
Simon Schrodi, Julian Schur, Max Argus, and Thomas Brox. Concept bottleneck models without predefined concepts.arXiv preprint arXiv:2407.03921, 2024. doi: 10.48550/arXiv.2407.03921. URLhttps://arxiv.org/abs/2407.03921
-
[73]
Selective concept bottleneck models without predefined concepts.Transactions on Machine Learning Research, May 2025
Simon Schrodi, Julian Schur, Max Argus, and Thomas Brox. Selective concept bottleneck models without predefined concepts.Transactions on Machine Learning Research, May 2025. URLhttps://openreview.net/forum?id=PMO30TLI4l. Accepted
2025
-
[74]
Find: A function description benchmark for evaluating interpretability methods.Advances in Neural Information Processing Systems, 36: 75688–75715, 2023
Sarah Schwettmann, Tamar Shaham, Joanna Materzynska, Neil Chowdhury, Shuang Li, Jacob Andreas, David Bau, and Antonio Torralba. Find: A function description benchmark for evaluating interpretability methods.Advances in Neural Information Processing Systems, 36: 75688–75715, 2023
2023
-
[75]
Improving concept alignment in vision-language concept bottleneck models.arXiv preprint, 2024
Nithish Muthuchamy Selvaraj, Xiaobao Guo, Adams Wai-Kin Kong, and Alex Kot. Improving concept alignment in vision-language concept bottleneck models.arXiv preprint, 2024. URL https://arxiv.org/pdf/2405.01825. 17
arXiv 2024
-
[76]
Adaptive test-time intervention for concept bottleneck models.arXiv preprint arXiv:2503.06730, 2025
Matthew Shen, Aliyah Hsu, Abhineet Agarwal, and Bin Yu. Adaptive test-time intervention for concept bottleneck models.arXiv preprint arXiv:2503.06730, 2025
arXiv 2025
-
[77]
Abhishek Shende, Mahidhar Mullapudi, and Narayana Challa. Enhancing document verification systems: A review of techniques, challenges, and practical implementations.International Journal of Computer Engineering & Technology, 15:16–25, 2024
2024
-
[78]
Auxiliary losses for learning generalizable concept- based models.Advances in Neural Information Processing Systems, 36:26966–26990, 2023
Ivaxi Sheth and Samira Ebrahimi Kahou. Auxiliary losses for learning generalizable concept- based models.Advances in Neural Information Processing Systems, 36:26966–26990, 2023
2023
-
[79]
Learning from uncertain concepts via test time interventions
Ivaxi Sheth, Aamer Abdul Rahman, Laya Rafiee Sevyeri, Mohammad Havaei, and Samira Ebrahimi Kahou. Learning from uncertain concepts via test time interventions. In Workshop on trustworthy and socially responsible machine learning, neurips 2022, 2022
2022
-
[80]
A closer look at the intervention procedure of concept bottleneck models
Sungbin Shin, Yohan Jo, Sungsoo Ahn, and Namhoon Lee. A closer look at the intervention procedure of concept bottleneck models. InInternational Conference on Machine Learning, pages 31504–31520. PMLR, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.