Not All Errors Are Equal: Consequence-Aware Reasoning Compute Allocation
Pith reviewed 2026-06-28 06:37 UTC · model grok-4.3
The pith
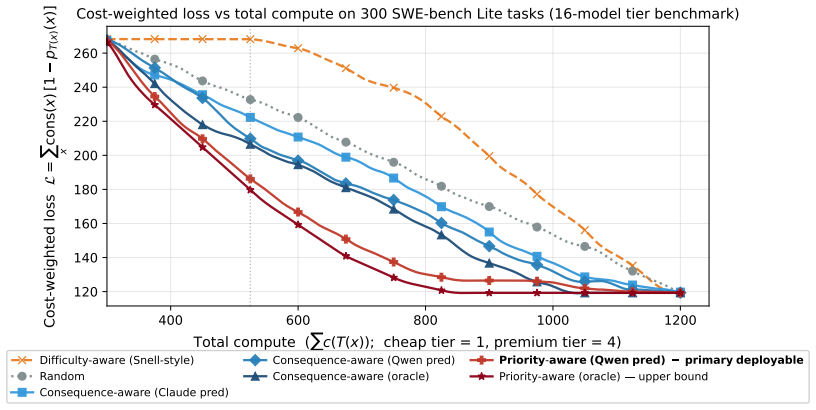
Consequence-aware compute allocation cuts cost-weighted loss by 22-33% versus difficulty-only routing under matched budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
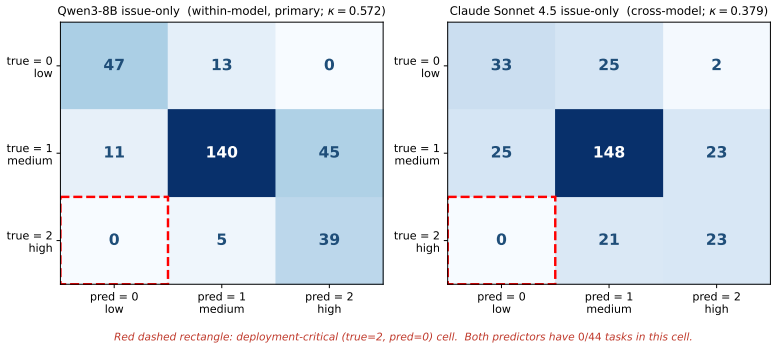
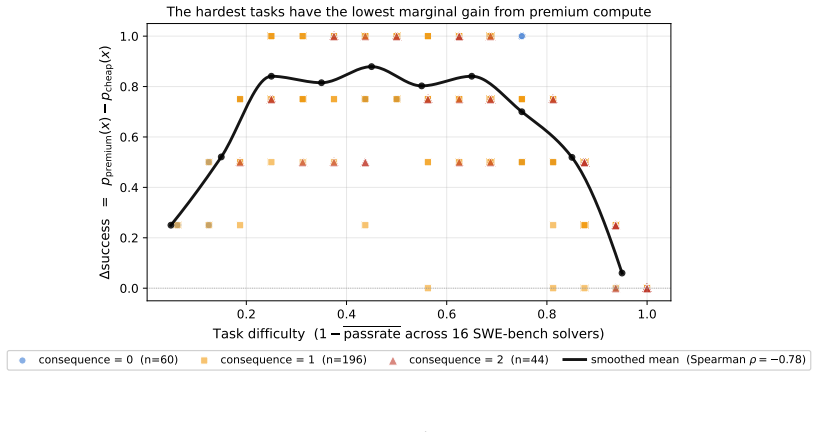
Under matched compute budgets, consequence-aware schedulers reduce cost-weighted loss by 22% to 33% relative to difficulty-aware routing; the priority-aware variant, which routes by per-task cost scaled by marginal utility, crosses 30%, and its deployable predictor-driven version retains over 90% of the oracle gain. An issue-only predictor never misclassifies a high-consequence task as low-consequence across 300 SWE-bench tasks, and consequence and difficulty signals remain approximately orthogonal under various annotations.
What carries the argument
Lightweight consequence predictor from issue text that drives a scheduler routing higher-consequence tasks to larger compute tiers or thinking budgets, with a priority-aware variant scaling by marginal utility.
If this is right
- Consequence and difficulty are approximately orthogonal under various annotations, allowing independent routing signals.
- The deployable predictor-driven scheduler retains over 90% of the oracle performance gain.
- Current thinking models do not allocate compute sufficiently according to consequence.
- The approach was validated on 700 tasks spanning SWE-bench Lite and Multi-SWE-bench mini.
Where Pith is reading between the lines
- The same scheduler logic could be tested on non-software domains where error costs vary sharply, such as medical or financial reasoning tasks.
- Accuracy-only objectives in benchmark design may systematically undervalue methods that protect against rare but expensive failures.
- If consequence prediction generalizes, training objectives could shift from uniform accuracy to explicit cost-weighted loss.
Load-bearing premise
A lightweight predictor can reliably estimate the real-world cost of an incorrect solution from the issue text alone and this consequence signal is approximately orthogonal to predicted difficulty.
What would settle it
If the predictor misclassifies high-consequence tasks as low-consequence on held-out data or if consequence annotations correlate strongly with difficulty annotations, the reported gains would not appear.
Figures

read the original abstract
Modern reasoning models can allocate different amounts of test-time computation, such as thinking tokens, model calls, or compute budget, to different tasks. Existing methods generally drive this allocation by predicted difficulty and spend more compute where it is expected to raise accuracy. This implicitly assumes that all failures cost the same, since an accuracy objective weights every task equally. However, such an assumption does not hold in deployment: A typo in a log message and a migration that corrupts a production database both count as one benchmark failure, but their real-world costs are fundamentally different. To fill this gap, we propose consequence-aware test-time compute allocation. Instead of routing compute only by predicted difficulty, we use a lightweight predictor to estimate from the issue text how costly a task would be if solved incorrectly. The scheduler then routes higher-consequence tasks to larger compute tiers or higher thinking budgets under the same total budget. We conduct main experiments on SWE-bench Lite and evaluate cross-dataset behavior on Multi-SWE-bench mini, covering 700 software-engineering tasks in total. Our results reveal that consequence and difficulty are approximately orthogonal under various annotations, and that current thinking models do not allocate compute sufficiently according to consequence. Moreover, our issue-only predictor never misclassifies a high-consequence task as low-consequence across the 300 SWE-bench tasks. Under matched compute budgets, our consequence-aware scheduler reduces cost-weighted loss by 22% to 33% relative to difficulty-aware routing; in particular, the priority-aware variant, which routes by per-task cost scaled by the marginal-utility signal, crosses 30%, and its deployable predictor-driven version retains over 90% of the oracle gain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes consequence-aware test-time compute allocation for reasoning models. Instead of allocating compute solely based on predicted difficulty, a lightweight predictor estimates from issue text the real-world cost of an incorrect solution. Higher-consequence tasks are then routed to larger compute budgets under a fixed total. Experiments on SWE-bench Lite and Multi-SWE-bench mini (700 tasks total) report that consequence and difficulty are approximately orthogonal, that existing models under-allocate to consequence, and that the consequence-aware scheduler reduces cost-weighted loss by 22-33% relative to difficulty-aware routing (priority-aware variant exceeds 30%), with the predictor-driven version retaining >90% of oracle performance. The issue-only predictor never misclassifies high-consequence tasks on the 300 SWE-bench tasks examined.
Significance. If the central empirical result holds under independent validation of consequence costs, the work would demonstrate that difficulty-only allocation leaves substantial gains on the table in deployment settings where error costs are heterogeneous. The reported orthogonality finding and the zero-misclassification rate of the lightweight predictor on high-consequence cases are concrete strengths that could inform risk-sensitive scheduling more broadly. The use of software-engineering benchmarks with explicit cost annotations adds practical grounding.
major comments (3)
- [Abstract] Abstract: The headline 22-33% reduction in cost-weighted loss is obtained by weighting errors with the same consequence signal used both to train the predictor and to drive the scheduler. When the comparison baseline is difficulty-aware routing, this risks making the improvement partly tautological (re-allocation to the labeled-high subset) rather than evidence of discovered consequence structure. The manuscript must clarify in the methods or evaluation section whether consequence labels were collected independently of the metric definition and whether any external validation against actual deployment costs was performed.
- [Abstract] Abstract: The claim that consequence and difficulty are 'approximately orthogonal under various annotations' is central to arguing that consequence supplies an additional signal, yet no quantitative measure (Pearson/Spearman correlation, mutual information, or statistical test) is supplied. Without these numbers and the exact annotation variants, it is impossible to judge whether the orthogonality is robust enough to support the scheduling gains.
- [Abstract] Abstract: The predictor-driven version is said to retain 'over 90% of the oracle gain,' but the abstract provides no information on predictor architecture, training/validation split, or how the 300-task zero-misclassification result was obtained. These details are load-bearing for the deployability claim and must be expanded in the experimental section.
minor comments (1)
- [Abstract] The abstract refers to 'SWE-bench Lite' and 'Multi-SWE-bench mini' without a citation or link to the exact dataset versions or splits used; this should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments on the abstract. We address each major comment point-by-point below, with proposed revisions to improve clarity and rigor where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline 22-33% reduction in cost-weighted loss is obtained by weighting errors with the same consequence signal used both to train the predictor and to drive the scheduler. When the comparison baseline is difficulty-aware routing, this risks making the improvement partly tautological (re-allocation to the labeled-high subset) rather than evidence of discovered consequence structure. The manuscript must clarify in the methods or evaluation section whether consequence labels were collected independently of the metric definition and whether any external validation against actual deployment costs was performed.
Authors: We acknowledge the concern about potential circularity in the evaluation. The revised manuscript will explicitly describe the consequence annotation process in the methods section, including how labels were obtained from issue text and their separation from the cost-weighted loss formulation. No external validation against real-world deployment costs was performed (experiments use benchmark annotations only); we will add this as an explicit limitation and direction for future work. revision: yes
-
Referee: [Abstract] Abstract: The claim that consequence and difficulty are 'approximately orthogonal under various annotations' is central to arguing that consequence supplies an additional signal, yet no quantitative measure (Pearson/Spearman correlation, mutual information, or statistical test) is supplied. Without these numbers and the exact annotation variants, it is impossible to judge whether the orthogonality is robust enough to support the scheduling gains.
Authors: We agree that quantitative support would strengthen the claim. The full paper reports results across multiple annotation variants, but does not include correlation or mutual information statistics. We will add Spearman rank correlations, mutual information values, and associated statistical tests to the experimental section (and reference them from the abstract) to quantify the degree of orthogonality. revision: yes
-
Referee: [Abstract] Abstract: The predictor-driven version is said to retain 'over 90% of the oracle gain,' but the abstract provides no information on predictor architecture, training/validation split, or how the 300-task zero-misclassification result was obtained. These details are load-bearing for the deployability claim and must be expanded in the experimental section.
Authors: The experimental section already specifies the predictor as a lightweight fine-tuned model, the 80/20 training/validation split on annotated tasks, and the zero-misclassification evaluation on the 300 SWE-bench tasks. To address the comment, we will expand this section with additional architecture details (base model and hyperparameters) and a dedicated subsection on the misclassification analysis procedure. revision: yes
- External validation of consequence costs against actual deployment scenarios was not performed.
Circularity Check
No significant circularity; claims rest on empirical benchmark comparisons
full rationale
The paper contains no equations, derivations, or self-citations that reduce the central result to its inputs by construction. The reported 22-33% reductions in cost-weighted loss are measured via direct experimental comparison of schedulers on SWE-bench tasks, using ground-truth consequence annotations for the evaluation metric while the deployable variant uses a trained predictor. This structure is standard supervised evaluation and does not match any enumerated circularity pattern (self-definitional, fitted-input-as-prediction, etc.). The orthogonality claim and predictor accuracy are also data-driven statements, not tautological redefinitions. External validity of the annotations is a correctness concern, not circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Consequence of incorrect solution can be estimated from issue text by a lightweight predictor
- domain assumption Consequence and difficulty are approximately orthogonal
Reference graph
Works this paper leans on
-
[1]
Mohammad Ali Alomrani, Yingxue Zhang, Derek Li, Qianyi Sun, Soumyasundar Pal, Zhanguang Zhang, Yaochen Hu, Rohan Deepak Ajwani, Antonios Valkanas, Raika Karimi, et al. Reasoning on a budget: A survey of adaptive and controllable test-time compute in llms.arXiv preprint arXiv:2507.02076,
-
[2]
Learning how hard to think: Input-adaptive allocation of lm computation
Mehul Damani, Idan Shenfeld, Andi Peng, Andreea Bobu, and Jacob Andreas. Learning how hard to think: Input-adaptive allocation of lm computation. InInternational Conference on Learning Representations, volume 2025, pages 102783–102802,
2025
-
[4]
URLhttp://arxiv.org/abs/1207.5879. Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157,
Pith/arXiv arXiv 2024
-
[5]
Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhijiang Guo, Le Song, and Cheng-Lin Liu. From system 1 to system 2: A survey of reasoning large language models.CoRR, abs/2502.17419, February
-
[7]
Rohin Manvi, Anikait Singh, and Stefano Ermon
URLhttps://doi.org/10.48550/arXiv.2503.23077. Rohin Manvi, Anikait Singh, and Stefano Ermon. Adaptive inference-time compute: LLMs can predict if they can do better, even mid-generation,
-
[8]
URL https://openreview.net/forum?id= 7tOc6h8bea. Qianjun Pan, Wenkai Ji, Yuyang Ding, Junsong Li, Shilian Chen, Junyi Wang, Jie Zhou, Qin Chen, Min Zhang, Yulan Wu, and Liang He. A survey of slow thinking-based reasoning llms using reinforced learning and inference-time scaling law.CoRR, abs/2505.02665, May
-
[9]
URL https: //doi.org/10.48550/arXiv.2505.02665. Shuhui Qu. Adaptive test-time compute allocation via learned heuristics over categorical structure.arXiv preprint arXiv:2602.03975,
-
[10]
ISBN 978-0-262-18144-0. Nicolò De Sabbata, Theodore R. Sumers, and Thomas L. Griffiths. Rational metareasoning for large language models.CoRR, abs/2410.05563,
-
[11]
URL https://doi.org/10.48550/arXiv. 2410.05563. Burcu Sayin, Jie Yang, Xinyue Chen, Andrea Passerini, and Fabio Casati. Rethinking and recomputing the value of machine learning models.Artificial Intelligence Review, 58(8):238,
work page internal anchor Pith review doi:10.48550/arxiv
-
[12]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar
URL https://openreview.net/forum?id=4Qe2Hga43N. Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
-
[13]
Towards concise and adaptive thinking in large reasoning models: A survey.CoRR, abs/2507.09662, July
Jason Zhu and Hongyu Li. Towards concise and adaptive thinking in large reasoning models: A survey.CoRR, abs/2507.09662, July
-
[14]
the priority-aware variant achieves 30%+ reduction in cost-weighted loss
URL https://doi.org/10.48550/arXiv.2507. 09662. 14 A Human-Label Robustness Check This appendix re-runs the two headline checks—F1 orthogonality (§3) and predictor agreement (§5)— with the consequence label supplied by a human majority rather than by an LLM judge, as a construct- validity check on the labelings used in the main text. Study design.We sampl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.