Flatness and Generalization: Learning Multi-Index Models with Homogeneous Neural Networks
Pith reviewed 2026-06-28 04:30 UTC · model grok-4.3
The pith
For data generated by sums of single-index models with low noise, any flattest interpolator of homogeneous neural networks achieves small population loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
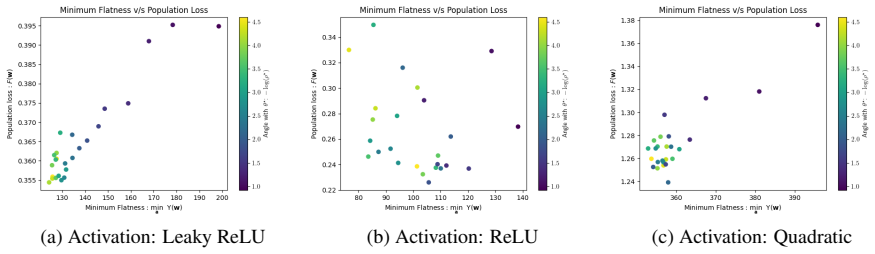
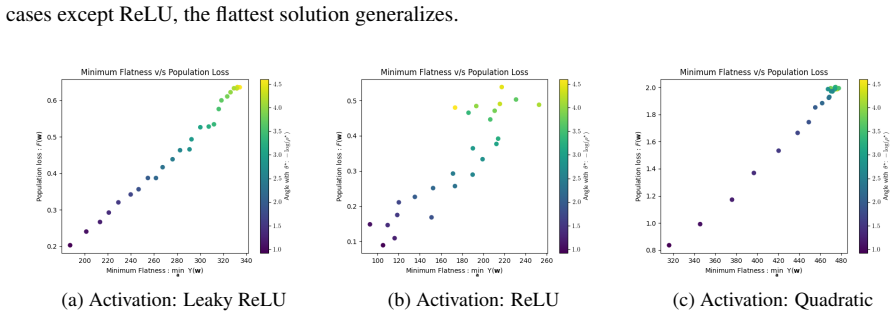
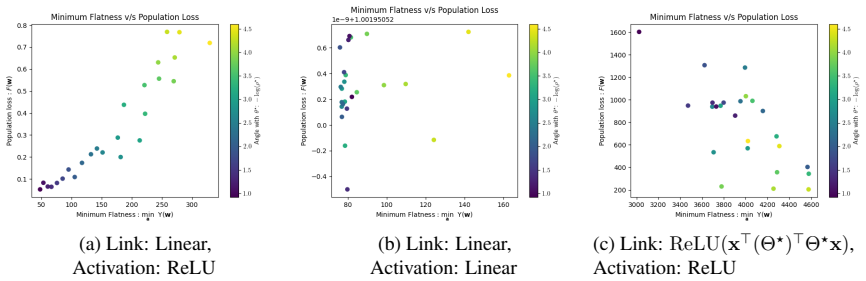
For learning an unknown multi-index model with 2-layer non-convex homogeneous neural networks, there is a connection between flatness and generalization that persists despite symmetries. There exists a natural class of non-generalizing interpolators whose flatness cannot be made closer to the flattest possible even using symmetries. For data generated by a sum of single-index models, if the approximation error and label noise are low, any flattest interpolator achieves small population loss. This holds for a large class of activations and realistic data distributions.
What carries the argument
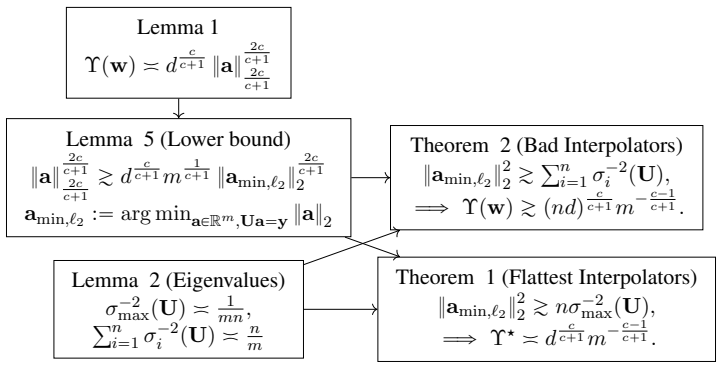
The flattest interpolators, defined as those with orderwise minimum trace of the Hessian of the empirical loss among all interpolators.
If this is right
- Non-generalizing interpolators exist whose flatness cannot reach the minimum level even after symmetries are applied.
- Any flattest interpolator achieves small population loss when data follows the sum-of-single-index model with low error and noise.
- The flatness-generalization connection applies across a large class of activations and realistic distributions.
- The result gives a direct link between minimum flatness and generalization for this class of models and data.
Where Pith is reading between the lines
- Optimization trajectories that reliably reach minimum-flatness solutions could be favored for generalization in multi-index settings.
- Similar arguments might apply to other homogeneous architectures if the single-index decomposition structure is preserved.
- Flatness could serve as a practical selection criterion among multiple interpolators when the data-generating process is close to a sum of single-index models.
Load-bearing premise
The data must be generated exactly as a sum of single-index models with low approximation error and label noise.
What would settle it
Observe a flattest interpolator (minimum-order Hessian trace) on low-noise sum-of-single-index data that nonetheless has large population loss.
Figures
read the original abstract
A common heuristic used to explain the generalization of first-order gradient methods on non-convex neural networks is that "flat interpolators generalize well" (Hochreiter and Schmidhuber, 1994; Keskar et al., 2017), where flatness can be measured by the trace of the Hessian of the empirical loss. However, Dinh et al. 2017) showed that, using symmetry of the network that can change flatness while keeping the population and empirical losses unchanged, any interpolator can be made sharper or flatter. This result makes the earlier heuristic statement vacuous. In this paper, we show that for learning an unknown multi-index model with $2$-layer non-convex homogeneous neural networks, there is a connection between flatness and generalization, despite the existence of symmetries. This connection pertains to the "flattest" interpolators, i.e., the interpolators that have orderwise minimum flatness among all interpolators. First, we show that there exists a natural class of non-generalizing interpolators whose flatness cannot be made closer to the flattest possible, even using symmetries. Second, we show that for data generated by a sum of single-index models, if the approximation error and label noise are low, any flattest interpolator achieves small population loss, i.e., the flattest interpolators always generalize. This establishes a direct link between flatness and generalization which applies to a large class of activations and realistic data distributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that, for 2-layer homogeneous neural networks learning multi-index models, symmetries do not render the flatness heuristic vacuous when attention is restricted to orderwise-minimal flatness (flattest interpolators). Specifically, non-generalizing interpolators exist whose flatness cannot be reduced to the minimum even after symmetries, and, when data are generated exactly as a sum of single-index models with low approximation error and label noise, every flattest interpolator achieves small population loss. The result is stated to hold for a large class of activations.
Significance. If the derivations hold, the work supplies a non-vacuous, symmetry-aware link between flatness (trace of the Hessian) and generalization for this concrete function class and data model. The restriction to orderwise-minimal flatness is a coherent way to evade Dinh et al. reparameterizations while still obtaining a positive statement. The explicit conditioning on the sum-of-single-index data model is stated up front, so the result is not overclaimed for arbitrary targets.
minor comments (2)
- The abstract states the data-generation assumption clearly, but the introduction or §2 should contain an explicit statement of how the multi-index model is formalized (e.g., the precise form of the target function and the homogeneity degree of the network) so that the scope of the “large class of activations” is immediately visible.
- Notation for the flatness measure (trace of the Hessian of the empirical loss) and for “orderwise minimum flatness” should be introduced once in a dedicated subsection rather than scattered across the technical sections.
Simulated Author's Rebuttal
We thank the referee for their positive summary, significance assessment, and recommendation of minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The paper's central result is a conditional theorem: when data is generated exactly by a sum of single-index models with low approximation error and label noise, any orderwise-minimal-flatness interpolator achieves small population loss. This premise is stated explicitly in the abstract and is not derived from the conclusion; the derivation therefore does not reduce to a self-definition, a fitted quantity renamed as a prediction, or a load-bearing self-citation chain. The treatment of Dinh et al. symmetries via the orderwise-minimal-flatness restriction is a methodological choice that sidesteps reparameterization without circularity. No equations or steps in the provided text exhibit the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stable Minima Cannot Overfit in Univariate Re
Dan Qiao and Kaiqi Zhang and Esha Singh and Daniel Soudry and Yu-Xiang Wang , booktitle=. Stable Minima Cannot Overfit in Univariate Re
-
[2]
Proceedings of the 40th International Conference on Machine Learning , pages =
The Implicit Regularization of Dynamical Stability in Stochastic Gradient Descent , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , volume =
2023
-
[3]
On Linear Stability of SGD and Input-Smoothness of Neural Networks , volume =
Ma, Chao and Ying, Lexing , booktitle =. On Linear Stability of SGD and Input-Smoothness of Neural Networks , volume =
-
[4]
How SGD Selects the Global Minima in Over-parameterized Learning: A Dynamical Stability Perspective , volume =
Wu, Lei and Ma, Chao and E, Weinan , booktitle =. How SGD Selects the Global Minima in Over-parameterized Learning: A Dynamical Stability Perspective , volume =
-
[5]
Mulayoff, Rotem and Michaeli, Tomer and Soudry, Daniel , year =. The. Advances in
-
[6]
Chemnitz, Dennis and Engel, Maximilian , month = sep, year =. Characterizing. doi:10.48550/arXiv.2407.20209 , publisher =
-
[7]
Implicit
Nacson, Mor Shpigel and Ravichandran, Kavya and Srebro, Nathan and Soudry, Daniel , month = jun, year =. Implicit. Proceedings of the 39th
-
[8]
Advances in Neural Information Processing Systems , author =
The alignment property of. Advances in Neural Information Processing Systems , author =. 2022 , pages =
2022
-
[9]
Mulayoff, Rotem and Michaeli, Tomer , month = jun, year =. Exact. Proceedings of
-
[10]
2023 , cdate=
Mor Shpigel Nacson and Rotem Mulayoff and Greg Ongie and Tomer Michaeli and Daniel Soudry , title=. 2023 , cdate=
2023
-
[11]
Journal of the American Statistical Association , volume =
Peter L Bartlett and Michael I Jordan and Jon D McAuliffe , title =. Journal of the American Statistical Association , volume =. 2006 , publisher =
2006
-
[12]
Proceedings of Thirty Fifth Conference on Learning Theory , pages =
Stochastic linear optimization never overfits with quadratically-bounded losses on general data , author =. Proceedings of Thirty Fifth Conference on Learning Theory , pages =. 2022 , volume =
2022
-
[13]
Self-concordant analysis for logistic regression
Bach, Francis. Self-concordant analysis for logistic regression. Electron. J. Stat
-
[14]
2025 , eprint=
Flat Minima and Generalization: Insights from Stochastic Convex Optimization , author=. 2025 , eprint=
2025
-
[15]
9th International Conference on Learning Representations,
Pierre Foret and Ariel Kleiner and Hossein Mobahi and Behnam Neyshabur , title =. 9th International Conference on Learning Representations,
-
[16]
International Conference on Learning Representations , year=
Fantastic Generalization Measures and Where to Find Them , author=. International Conference on Learning Representations , year=
-
[17]
Proceedings of the 40th International Conference on Machine Learning , pages =
A Modern Look at the Relationship between Sharpness and Generalization , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , volume =
2023
-
[18]
The Eleventh International Conference on Learning Representations , year=
How Sharpness-Aware Minimization Minimizes Sharpness? , author=. The Eleventh International Conference on Learning Representations , year=
-
[19]
Information and Inference: A Journal of the IMA , volume =
Ding, Lijun and Drusvyatskiy, Dmitriy and Fazel, Maryam and Harchaoui, Zaid , title =. Information and Inference: A Journal of the IMA , volume =. 2024 , month =
2024
-
[20]
Stable Minima of Re
Tongtong Liang and Dan Qiao and Yu-Xiang Wang and Rahul Parhi , booktitle=. Stable Minima of Re
-
[21]
, keywords =
Lee, John M. , keywords =
-
[22]
Proceedings of the National Academy of Sciences , volume =
Mikhail Belkin and Daniel Hsu and Siyuan Ma and Soumik Mandal , title =. Proceedings of the National Academy of Sciences , volume =. 2019 , doi =
2019
-
[23]
Wainwright, Martin J. , year=. High-Dimensional Statistics: A Non-Asymptotic Viewpoint , publisher=
-
[24]
and Mendelson, Shahar , title =
Bartlett, Peter L. and Mendelson, Shahar , title =. J. Mach. Learn. Res. , month = mar, pages =. 2003 , publisher =
2003
-
[25]
Statistical Science , number =
Joan Bruna and Daniel Hsu , title =. Statistical Science , number =
-
[26]
Vapnik, Vladimir N. , year =. The Nature of Statistical Learning Theory , ISBN =. doi:10.1007/978-1-4757-3264-1 , publisher =
-
[27]
Zhang, Chiyuan and Bengio, Samy and Hardt, Moritz and Recht, Benjamin and Vinyals, Oriol , title =. 2021 , issue_date =. doi:10.1145/3446776 , journal =
-
[28]
Zico , booktitle =
Nagarajan, Vaishnavh and Kolter, J. Zico , booktitle =. Uniform convergence may be unable to explain generalization in deep learning , year =
-
[29]
International Conference on Learning Representations , year=
The Implicit Bias of Gradient Descent on Separable Data , author=. International Conference on Learning Representations , year=
-
[30]
Proceedings of the 34th International Conference on Machine Learning , pages =
Sharp Minima Can Generalize For Deep Nets , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , volume =
2017
-
[31]
Proceedings of Thirty Third Conference on Learning Theory , pages =
Learning Polynomials in Few Relevant Dimensions , author =. Proceedings of Thirty Third Conference on Learning Theory , pages =. 2020 , volume =
2020
-
[32]
Lee and Taiji Suzuki , booktitle=
Kazusato Oko and Denny Wu and Jason D. Lee and Taiji Suzuki , booktitle=. Neural network learns low-dimensional polynomials with
-
[33]
Vladimirova, Mariia and Girard, Stéphane and Nguyen, Hien and Arbel, Julyan , year=. Sub‐Weibull distributions: Generalizing sub‐Gaussian and sub‐Exponential properties to heavier tailed distributions , volume=. Stat , publisher=. doi:10.1002/sta4.318 , number=
-
[34]
Electronic Journal of Probability , number =
Friedrich G. Electronic Journal of Probability , number =. 2021 , doi =
2021
-
[35]
2024 , eprint=
Uniform Hanson-Wright Type Deviation Inequalities for -Subexponential Random Vectors , author=. 2024 , eprint=
2024
-
[36]
Information and Inference: A Journal of the IMA , volume =
Kuchibhotla, Arun Kumar and Chakrabortty, Abhishek , title =. Information and Inference: A Journal of the IMA , volume =. 2022 , month =
2022
-
[37]
Some Notes on Concentration for -Subexponential Random Variables
Sambale, Holger. Some Notes on Concentration for -Subexponential Random Variables. High Dimensional Probability IX. 2023
2023
-
[38]
and Shakarchi, Rami , title =
Stein, Elias M. and Shakarchi, Rami , title =. 2011 , address =
2011
-
[39]
Mathematics , VOLUME =
Zhang, Huiming and Wei, Haoyu , TITLE =. Mathematics , VOLUME =. 2022 , NUMBER =
2022
-
[40]
Известия Российской академии наук
Uber die abgrenzung der eigenwerte einer matrix , author=. Известия Российской академии наук. Серия математическая , number=. 1931 , publisher=
1931
-
[41]
Electronic Communications in Probability , number =
Mark Rudelson and Roman Vershynin , title =. Electronic Communications in Probability , number =. 2013 , doi =
2013
-
[42]
2024 , eprint=
Expressivity and Approximation Properties of Deep Neural Networks with ReLU ^k Activation , author=. 2024 , eprint=
2024
-
[43]
Path-SGD: Path-Normalized Optimization in Deep Neural Networks , volume =
Neyshabur, Behnam and Salakhutdinov, Russ R and Srebro, Nati , booktitle =. Path-SGD: Path-Normalized Optimization in Deep Neural Networks , volume =
-
[44]
Transactions on Machine Learning Research , issn=
Symmetry in Neural Network Parameter Spaces , author=. Transactions on Machine Learning Research , issn=
-
[45]
High-order approximation rates for shallow neural networks with cosine and ReLUk activation functions , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.acha.2021.12.005 , author =
-
[46]
Yang, Yunfei and Zhou, Ding-Xuan , year =. Optimal Rates of Approximation by Shallow ReLU ^k Neural Networks and Applications to Nonparametric Regression , volume =. Constructive Approximation , publisher =. doi:10.1007/s00365-024-09679-z , number =
-
[47]
Proceedings of Thirty Fifth Conference on Learning Theory , pages =
Neural Networks can Learn Representations with Gradient Descent , author =. Proceedings of Thirty Fifth Conference on Learning Theory , pages =. 2022 , volume =
2022
-
[48]
Lee , booktitle=
Alex Damian and Eshaan Nichani and Rong Ge and Jason D. Lee , booktitle=. Smoothing the Landscape Boosts the Signal for
-
[49]
International Conference on Learning Representations , year=
Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability , author=. International Conference on Learning Representations , year=
-
[50]
The Fourteenth International Conference on Learning Representations , year=
Gradient Descent with Large Step Sizes: Chaos and Fractal Convergence Region , author=. The Fourteenth International Conference on Learning Representations , year=
-
[51]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Implicit Bias of Gradient Descent for Logistic Regression at the Edge of Stability , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[52]
Proceedings of the 37th International Conference on Machine Learning , pages =
Unique Properties of Flat Minima in Deep Networks , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , volume =
2020
-
[53]
International Conference on Learning Representations , year=
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima , author=. International Conference on Learning Representations , year=
-
[54]
Simplifying neural nets by discovering flat minima , year =
Hochreiter, Sepp and Schmidhuber, J\". Simplifying neural nets by discovering flat minima , year =. Proceedings of the 8th International Conference on Neural Information Processing Systems , pages =
-
[55]
Proceedings of the 38th International Conference on Machine Learning , pages =
ASAM: Adaptive Sharpness-Aware Minimization for Scale-Invariant Learning of Deep Neural Networks , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , volume =
2021
-
[56]
Relative Flatness and Generalization , volume =
Petzka, Henning and Kamp, Michael and Adilova, Linara and Sminchisescu, Cristian and Boley, Mario , booktitle =. Relative Flatness and Generalization , volume =
-
[57]
Entropy-
Dziugaite, Gintare Karolina and Roy, Daniel , booktitle =. Entropy-. 2018 , editor =
2018
-
[58]
doi:10.1088/1742-5468/ab39d9 , year =
Chaudhari, Pratik and Choromanska, Anna and Soatto, Stefano and LeCun, Yann and Baldassi, Carlo and Borgs, Christian and Chayes, Jennifer and Sagun, Levent and Zecchina, Riccardo , title =. doi:10.1088/1742-5468/ab39d9 , year =
-
[59]
2025 , eprint=
Generalization Below the Edge of Stability: The Role of Data Geometry , author=. 2025 , eprint=
2025
-
[60]
2025 , eprint=
Does Flatness imply Generalization for Logistic Loss in Univariate Two-Layer ReLU Network? , author=. 2025 , eprint=
2025
-
[61]
The Eleventh International Conference on Learning Representations , year=
Loss Landscapes are All You Need: Neural Network Generalization Can Be Explained Without the Implicit Bias of Gradient Descent , author=. The Eleventh International Conference on Learning Representations , year=
-
[62]
2023 , eprint=
FAM: Relative Flatness Aware Minimization , author=. 2023 , eprint=
2023
-
[63]
Proceedings of The 36th International Conference on Algorithmic Learning Theory , pages =
A PAC-Bayesian Link Between Generalisation and Flat Minima , author =. Proceedings of The 36th International Conference on Algorithmic Learning Theory , pages =. 2025 , volume =
2025
-
[64]
Journal of Machine Learning Research , year =
Gerard Ben Arous and Reza Gheissari and Aukosh Jagannath , title =. Journal of Machine Learning Research , year =
-
[65]
2004 , publisher=
Convex optimization , author=. 2004 , publisher=
2004
-
[66]
Normalized Flat Minima: Exploring Scale Invariant Definition of Flat Minima for Neural Networks Using
Tsuzuku, Yusuke and Sato, Issei and Sugiyama, Masashi , booktitle =. Normalized Flat Minima: Exploring Scale Invariant Definition of Flat Minima for Neural Networks Using. 2020 , volume =
2020
-
[67]
Concentration Inequalities for Statistical Inference , volume=
Zhang, Huiming and Chen, Songxi , year=. Concentration Inequalities for Statistical Inference , volume=. Communications in Mathematical Research , publisher=
-
[68]
Proceedings of Thirty Seventh Conference on Learning Theory , pages =
Learning sum of diverse features: computational hardness and efficient gradient-based training for ridge combinations , author =. Proceedings of Thirty Seventh Conference on Learning Theory , pages =. 2024 , volume =
2024
-
[69]
Bell System Technical Journal , volume =
Slepian, David , title =. Bell System Technical Journal , volume =
-
[70]
Thirty-seventh Conference on Neural Information Processing Systems , year=
What is the Inductive Bias of Flatness Regularization? A Study of Deep Matrix Factorization Models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[71]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Provable Guarantees for Nonlinear Feature Learning in Three-Layer Neural Networks , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[72]
Journal of Machine Learning Research , year =
Steven Diamond and Stephen Boyd , title =. Journal of Machine Learning Research , year =
-
[73]
Journal of Control and Decision , year =
Agrawal, Akshay and Verschueren, Robin and Diamond, Steven and Boyd, Stephen , title =. Journal of Control and Decision , year =
-
[74]
The MOSEK optimization toolbox for Python, version 11.1 , year =
-
[75]
Bartlett and Philip M
Peter L. Bartlett and Philip M. Long and Gábor Lugosi and Alexander Tsigler , title =. Proceedings of the National Academy of Sciences , volume =
-
[76]
Laurent and P
B. Laurent and P. Massart , title =. The Annals of Statistics , number =
-
[77]
Proceedings of Thirty Fifth Conference on Learning Theory , pages =
Benign Overfitting without Linearity: Neural Network Classifiers Trained by Gradient Descent for Noisy Linear Data , author =. Proceedings of Thirty Fifth Conference on Learning Theory , pages =. 2022 , volume =
2022
-
[78]
Journal of the American Statistical Association , volume =
Ker-Chau Li , title =. Journal of the American Statistical Association , volume =. 1991 , publisher =
1991
-
[79]
Proceedings of Thirty Sixth Conference on Learning Theory , pages =
SGD learning on neural networks: leap complexity and saddle-to-saddle dynamics , author =. Proceedings of Thirty Sixth Conference on Learning Theory , pages =. 2023 , volume =
2023
-
[80]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
The Generative Leap: Tight Sample Complexity for Efficiently Learning Gaussian Multi-Index Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.