DSA: Dynamic Step Allocation for Fast Autoregressive Video Generation
Pith reviewed 2026-06-28 07:26 UTC · model grok-4.3
The pith
A lightweight confidence head trained under distribution-matching distillation lets autoregressive video diffusion models vary the number of denoising steps per frame, terminating early on predictable frames while refining complex ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DSA shows that a jointly trained confidence head can serve as a reliable per-frame signal for adaptive denoising-step allocation. When this signal drives early stopping on high-confidence frames and extra refinement on low-confidence frames, the resulting videos maintain competitive or superior VBench scores compared with both recent autoregressive and bidirectional video diffusion models, yet run at 22.63 FPS with sub-second latency.
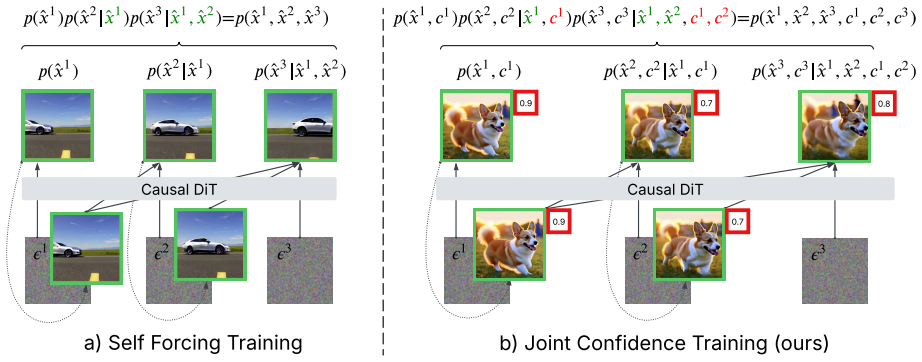
What carries the argument
The lightweight confidence head, trained jointly under the distribution-matching distillation objective, that outputs a scalar per frame indicating denoising reliability and thereby controls the dynamic number of diffusion steps allocated to that frame.
If this is right
- Real-time autoregressive video generation becomes feasible on current high-end GPUs without sacrificing quality.
- The same confidence-guided allocation principle can be applied to other autoregressive diffusion tasks that process sequential data.
- Inference cost scales with scene complexity rather than with a worst-case fixed budget.
- No additional video data or hand-crafted heuristics are required to obtain the speed-up.
Where Pith is reading between the lines
- If the confidence head generalizes across different base diffusion architectures, it could become a standard lightweight add-on for any autoregressive generation pipeline.
- The method implies that visual complexity can be measured on the fly during generation rather than estimated in advance.
- Interactive applications such as live video synthesis or game asset creation could adopt the technique once the head is ported to consumer hardware.
Load-bearing premise
The signal produced by the lightweight confidence head accurately indicates how many denoising steps each frame requires, so that early termination on high-confidence frames does not reduce final video quality.
What would settle it
Generate the same video sequences once with DSA's dynamic allocation and once with the identical model using a fixed high step count; if the VBench scores of the dynamic versions fall measurably below the fixed-step versions, the central claim is falsified.
Figures





read the original abstract
Video diffusion transformers have achieved state-of-the-art visual quality, but their high inference cost remains a major bottleneck for real-time applications. Recent distillation frameworks produce autoregressive video diffusion models with reduced latency, yet these models still use a fixed number of denoising steps per frame, wasting computation on predictable frames and under-refining challenging ones. We present DSA, a confidence-guided adaptive computation framework for AR video diffusion. DSA introduces a lightweight confidence head, trained jointly with the generator under a distribution-matching distillation objective, to estimate per-frame denoising reliability. At inference, this confidence signal dynamically adjusts the number of diffusion steps: simple frames terminate early for speed, while complex frames receive additional refinement. Our method requires no extra video data, no heuristics, and little architectural modification. Experiments show that DSA achieves real-time autoregressive video generation, reaching 22.63 FPS with sub-second latency on H100 GPUs, while maintaining competitive or superior VBench quality compared to recent autoregressive and bidirectional video diffusion models. Our results demonstrate that confidence-guided adaptive sampling provides an effective and practical path toward interactive video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DSA, a confidence-guided adaptive computation method for autoregressive video diffusion models. It adds a lightweight confidence head trained jointly under a distribution-matching distillation objective to estimate per-frame denoising reliability, enabling dynamic allocation of diffusion steps (early termination on high-confidence frames) at inference. The central empirical claim is real-time performance of 22.63 FPS with sub-second latency on H100 GPUs while achieving competitive or superior VBench quality versus recent AR and bidirectional video diffusion baselines, without extra data or heuristics.
Significance. If the calibration of the jointly-trained confidence head is shown to be reliable, the result would demonstrate a practical route to interactive autoregressive video generation by converting per-frame predictability into measurable speedups without quality loss, directly addressing the fixed-step inefficiency that remains after distillation.
major comments (2)
- [Abstract] Abstract and Experiments section: the headline claim of maintained or superior VBench quality while reaching 22.63 FPS rests on the unverified assumption that high confidence scores from the lightweight head reliably identify frames where fewer steps incur no measurable quality degradation; the provided text supplies no correlation coefficients between confidence and per-frame reconstruction error, no threshold-sensitivity ablations, and no oracle comparisons that would confirm the mapping is well-calibrated rather than post-hoc tuned.
- [Experiments] Experiments section: without reported details on the exact baselines (including their step counts and whether they were re-tuned for fair comparison), statistical significance of the VBench deltas, or confirmation that the confidence head parameters were not selected on the evaluation set, the quantitative superiority claim cannot be assessed for robustness.
minor comments (2)
- Clarify the precise architecture and loss weighting of the lightweight confidence head relative to the main generator, including any additional parameters introduced.
- Add a table or figure showing per-frame step allocation statistics (mean, variance, distribution) across the test videos to illustrate the adaptivity achieved.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the concerns on confidence head calibration and experimental robustness below, proposing targeted additions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: the headline claim of maintained or superior VBench quality while reaching 22.63 FPS rests on the unverified assumption that high confidence scores from the lightweight head reliably identify frames where fewer steps incur no measurable quality degradation; the provided text supplies no correlation coefficients between confidence and per-frame reconstruction error, no threshold-sensitivity ablations, and no oracle comparisons that would confirm the mapping is well-calibrated rather than post-hoc tuned.
Authors: We agree that explicit calibration evidence would strengthen the claims. The joint distribution-matching distillation is intended to produce a well-calibrated confidence signal, but the manuscript indeed omits correlation coefficients, threshold ablations, and oracle comparisons. We will add these analyses (including Pearson correlations with per-frame error and oracle step-allocation curves) in a revised Experiments section to directly verify that high-confidence early termination preserves quality. revision: yes
-
Referee: [Experiments] Experiments section: without reported details on the exact baselines (including their step counts and whether they were re-tuned for fair comparison), statistical significance of the VBench deltas, or confirmation that the confidence head parameters were not selected on the evaluation set, the quantitative superiority claim cannot be assessed for robustness.
Authors: We will expand the Experiments section with a table listing exact step counts and training details for all baselines, plus explicit confirmation that the confidence head was trained jointly on the training split only. Statistical significance testing was not performed in the original submission; we can add standard deviations across seeds where available or note this limitation. These changes will allow readers to assess robustness directly. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents DSA as an empirical engineering method: a lightweight confidence head is trained jointly under a distribution-matching distillation objective, then used at inference to dynamically allocate denoising steps based on per-frame reliability estimates. Reported metrics (22.63 FPS, sub-second latency, competitive VBench scores) are framed as experimental outcomes on H100 GPUs rather than quantities derived by construction from fitted parameters or self-referential definitions. No equations, uniqueness theorems, or self-citation chains appear in the provided text that would reduce the central claims to tautologies or fitted inputs renamed as predictions. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- confidence threshold for early termination
axioms (1)
- domain assumption Joint training of generator and confidence head under distribution-matching distillation produces a reliable per-frame confidence signal without requiring additional video data.
invented entities (1)
-
lightweight confidence head
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Blended latent diffusion.ACM Transactions on Graphics, 42(4): 149:1–149:11, 2023
Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion.ACM Transactions on Graphics, 42(4): 149:1–149:11, 2023. 2
2023
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22563–22575, 2023. 2
2023
-
[4]
Token merging for fast stable diffusion
Daniel Bolya and Judy Hoffman. Token merging for fast stable diffusion. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Work- shops, pages 4599–4603, 2023. 2
2023
-
[5]
Generating long videos of dynamic scenes.Advances in Neural Information Processing Systems, 35:31769–31781, 2022
Tim Brooks, Janne Hellsten, Miika Aittala, Ting-Chun Wang, Timo Aila, Jaakko Lehtinen, Ming-Yu Liu, Alexei Efros, and Tero Karras. Generating long videos of dynamic scenes.Advances in Neural Information Processing Systems, 35:31769–31781, 2022. 2
2022
-
[6]
Ge- nie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Ge- nie: Generative interactive environments. InForty-first Inter- national Conference on Machine Learning, 2024. 2
2024
-
[7]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T. Freeman. Maskgit: Masked generative image transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11315– 11325, 2022. 2
2022
-
[8]
Freeman, Michael Rubinstein, Yuanzhen Li, and Dilip Krishnan
Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T. Freeman, Michael Rubinstein, Yuanzhen Li, and Dilip Krishnan. Muse: Text-to-image generation via masked generative transformers. InInternational Conference on Ma- chine Learning, pages 4055–4075, 2023. 2
2023
-
[9]
Skyreels- v2: Infinite-length film generative model, 2025
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, Weiming Xiong, Wei Wang, Nuo Pang, Kang Kang, Zhiheng Xu, Yuzhe Jin, Yupeng Liang, Yubing Song, Peng Zhao, Boyuan Xu, Di Qiu, De- bang Li, Zhengcong Fei, Yang Li, and Yahui Zhou. Skyreels- v2: Infinite-length film generative mo...
2025
-
[10]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christo- pher R ´e. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022. 1
2022
-
[11]
Unsupervised learning of disentangled representations from video.Advances in neural information processing systems, 30, 2017
Emily L Denton et al. Unsupervised learning of disentangled representations from video.Advances in neural information processing systems, 30, 2017. 2
2017
-
[12]
Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020. 2, 4
2020
-
[13]
Mamba: Linear-time sequence mod- eling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence mod- eling with selective state spaces. InFirst conference on lan- guage modeling, 2024. 8
2024
-
[14]
Photorealistic video generation with diffusion models
Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Fei-Fei Li, Irfan Essa, Lu Jiang, and Jos ´e Lezama. Photorealistic video generation with diffusion models. In European Conference on Computer Vision, pages 393–411. Springer, 2024. 2
2024
-
[15]
Clockwork diffusion: Efficient generation with model-step distillation
Amirhossein Habibian, Amir Ghodrati, Noor Fathima, Guil- laume Sautiere, Risheek Garrepalli, Fatih Porikli, and Jens Petersen. Clockwork diffusion: Efficient generation with model-step distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8352–8361, 2024. 2
2024
-
[16]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Prompt-to-prompt image editing with cross attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. InInternational Confer- ence on Learning Representations, 2023. 2
2023
-
[18]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InAdvances in Neural Informa- tion Processing Systems, pages 6840–6851, 2020. 2
2020
-
[19]
Make-an-audio: Text-to-audio gen- eration with prompt-enhanced diffusion models
Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Luping Liu, Mingze Li, Zhenhui Ye, Jinglin Liu, Xiang Yin, and Zhou Zhao. Make-an-audio: Text-to-audio gen- eration with prompt-enhanced diffusion models. InInter- national Conference on Machine Learning, pages 13916– 13932, 2023. 2
2023
-
[20]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train- test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025. 2, 3, 5, 6, 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 2, 6
2024
-
[22]
Asano, and Amirhossein Habibian
Kumara Kahatapitiya, Adil Karjauv, Davide Abati, Fatih Porikli, Yuki M. Asano, and Amirhossein Habibian. Object- centric diffusion for efficient video editing.arXiv preprint arXiv:2401.05735, 2024. 2
-
[23]
Adaptive caching for faster video generation with diffu- sion transformers
Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S Ryoo, and Tian Xie. Adaptive caching for faster video generation with diffu- sion transformers. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 15240–15252,
-
[24]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 2019. 2
2019
-
[25]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding varia- tional bayes. InInternational Conference on Learning Rep- resentations, 2014. 2
2014
-
[26]
Videopoet: A large language model for zero-shot video gen- eration
Dan Kondratyuk, Lijun Yu, Xiuye Gu, Jos ´e Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vigh- nesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video gen- eration. InInternational Conference on Machine Learning, pages 25105–25124, 2024. 2
2024
-
[27]
Diffwave: A versatile diffusion model for audio synthesis
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis. InInternational Conference on Learning Representations, 2021. 2
2021
-
[28]
Vidtome: Video token merging for zero-shot video editing
Xirui Li, Chao Ma, Xiaokang Yang, and Ming-Hsuan Yang. Vidtome: Video token merging for zero-shot video editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7486–7495, 2024. 2
2024
-
[29]
Snap- fusion: Text-to-image diffusion model on mobile devices within two seconds.Advances in Neural Information Pro- cessing Systems, 36, 2024
Yanyu Li, Huan Wang, Qing Jin, Ju Hu, Pavlo Chemerys, Yun Fu, Yanzhi Wang, Sergey Tulyakov, and Jian Ren. Snap- fusion: Text-to-image diffusion model on mobile devices within two seconds.Advances in Neural Information Pro- cessing Systems, 36, 2024. 2
2024
-
[30]
Infinitenature-zero: Learning perpetual view generation of natural scenes from single images
Zhengqi Li, Qianqian Wang, Noah Snavely, and Angjoo Kanazawa. Infinitenature-zero: Learning perpetual view generation of natural scenes from single images. InEu- ropean conference on computer vision, pages 515–534. Springer, 2022. 2
2022
-
[31]
Diffusion adversarial post-training for one-step video generation
Shanchuan Lin, Xin Xia, Yuxi Ren, Ceyuan Yang, Xuefeng Xiao, and Lu Jiang. Diffusion adversarial post-training for one-step video generation. InInternational Conference on Machine Learning, 2025. 2, 4
2025
-
[32]
Infinite na- ture: Perpetual view generation of natural scenes from a sin- gle image
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, and Angjoo Kanazawa. Infinite na- ture: Perpetual view generation of natural scenes from a sin- gle image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14458–14467, 2021. 2
2021
-
[33]
Timestep embedding tells: It’s time to cache for video diffusion model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7353–7363, 2025. 2
2025
-
[34]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9298–9309, 2023. 2
2023
-
[35]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jian- feng Gao, et al. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2019. 6
2019
-
[37]
Nanye Ma, Mark Goldstein, Michael S. Albergo, Nicholas M. Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers.arXiv preprint arXiv:2401.08740, 2024. 2
-
[38]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15762–15772, 2024. 2
2024
-
[39]
Osv: One step is enough for high-quality image to video generation
Xiaofeng Mao, Zhengkai Jiang, Fu-Yun Wang, Jiangning Zhang, Hao Chen, Mingmin Chi, Yabiao Wang, and Wen- han Luo. Osv: One step is enough for high-quality image to video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12585–12594, 2025. 2
2025
-
[40]
Lazy diffusion transformer for interactive image editing
Yotam Nitzan, Zongze Wu, Richard Zhang, Eli Shechtman, Daniel Cohen-Or, Taesung Park, and Micha¨el Gharbi. Lazy diffusion transformer for interactive image editing. InEu- ropean Conference on Computer Vision, pages 55–72, 2024. 2
2024
-
[41]
Video generation models as world simula- tors.https://openai.com/research/video- generation - models - as - world - simulators,
OpenAI. Video generation models as world simula- tors.https://openai.com/research/video- generation - models - as - world - simulators,
-
[42]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 4172–4182,
-
[43]
Barron, and Ben Milden- hall
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion. InInter- national Conference on Learning Representations, 2023. 2
2023
-
[44]
Fatezero: Fus- ing attentions for zero-shot text-based video editing
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. Fatezero: Fus- ing attentions for zero-shot text-based video editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15886–15896, 2023. 2
2023
-
[45]
Shuhuai Ren, Shuming Ma, Xu Sun, and Furu Wei. Next block prediction: Video generation via semi-autoregressive modeling.arXiv preprint arXiv:2502.07737, 2025. 2
-
[46]
Discrete Variational Autoencoders
Jason Tyler Rolfe. Discrete variational autoencoders.arXiv preprint arXiv:1609.02200, 2016. 2
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[47]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 2
2022
-
[48]
Photorealistic text-to-image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. InAdvances in Neural Information Processing Systems, pages 36479–36494, 2022. 2
2022
-
[49]
Tempo- ral generative adversarial nets with singular value clipping
Masaki Saito, Eiichi Matsumoto, and Shunta Saito. Tempo- ral generative adversarial nets with singular value clipping. InProceedings of the IEEE international conference on com- puter vision, pages 2830–2839, 2017. 2
2017
-
[50]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, pages 87–103, 2024. 2
2024
-
[51]
Generalization in generation: A closer look at exposure bias.arXiv preprint arXiv:1910.00292, 2019
Florian Schmidt. Generalization in generation: A closer look at exposure bias.arXiv preprint arXiv:1910.00292, 2019. 3
-
[52]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792,
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InInternational Conference on Learning Representations, 2021. 2
2021
-
[54]
History-guided video diffusion
Kiwhan Song, Boyuan Chen, Max Simchowitz, Yilun Du, Russ Tedrake, and Vincent Sitzmann. History-guided video diffusion. InInternational Conference on Machine Learning,
-
[55]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video genera- tion at scale.arXiv preprint arXiv:2505.13211, 2025. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Confnet: predict with confidence
Sheng Wan, Tung-Yu Wu, Wing H Wong, and Chen-Yi Lee. Confnet: predict with confidence. In2018 IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 2921–2925. IEEE, 2018. 5
2018
-
[57]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 6, 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Vidprom: A million-scale real prompt-gallery dataset for text-to-video diffusion mod- els.Advances in Neural Information Processing Systems, 37: 65618–65642, 2024
Wenhao Wang and Yi Yang. Vidprom: A million-scale real prompt-gallery dataset for text-to-video diffusion mod- els.Advances in Neural Information Processing Systems, 37: 65618–65642, 2024. 6, 1
2024
-
[59]
Cache me if you can: Accel- erating diffusion models through block caching
Felix Wimbauer, Bichen Wu, Edgar Schoenfeld, Xiaoliang Dai, Ji Hou, Zijian He, Artsiom Sanakoyeu, Peizhao Zhang, Sam Tsai, Jonas Kohler, et al. Cache me if you can: Accel- erating diffusion models through block caching. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6211–6220, 2024. 2
2024
-
[60]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7589–7599, 2023. 2
2023
-
[61]
Snapgen-v: Generating a five-second video within five seconds on a mobile device
Yushu Wu, Zhixing Zhang, Yanyu Li, Yanwu Xu, Anil Kag, Yang Sui, Huseyin Coskun, Ke Ma, Aleksei Lebedev, Ju Hu, et al. Snapgen-v: Generating a five-second video within five seconds on a mobile device. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2479– 2490, 2025. 2
2025
-
[62]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Im- proved distribution matching distillation for fast image syn- thesis.Advances in neural information processing systems, 37:47455–47487, 2024
Tianwei Yin, Micha ¨el Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and Bill Freeman. Im- proved distribution matching distillation for fast image syn- thesis.Advances in neural information processing systems, 37:47455–47487, 2024. 2, 5, 6
2024
-
[64]
Freeman, and Taesung Park
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T. Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 6613–6623, 2024. 2, 4, 5, 6
2024
-
[65]
From slow bidirectional to fast autoregressive video diffusion mod- els
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Free- man, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion mod- els. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22963–22974, 2025. 2, 3, 6, 1
2025
-
[66]
Mobilediffusion: Subsecond text-to-image generation on mobile devices
Yang Zhao, Yanwu Xu, Zhisheng Xiao, and Tingbo Hou. Mobilediffusion: Subsecond text-to-image generation on mobile devices. InarXiv preprint arXiv:2311.16567, 2023. 2
-
[67]
Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation
Mingyuan Zhou, Huangjie Zheng, Zhendong Wang, Mingzhang Yin, and Hai Huang. Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation. InForty-first International Confer- ence on Machine Learning, 2024. 4 DSA: Dynamic Step Allocation for Fast Autoregressive Video Generation Supplementary Material
2024
-
[68]
We follow the Wan2.1 [57] flow-matching param- eterization with a shifted time schedule and a 4-step uni- form inference schedule, following [20]
Implementation details Our implementation builds on open-source Wan2.1 [57] and Self-Forcing [20] frameworks, using FlashAttention-3 [10] forDSA. We follow the Wan2.1 [57] flow-matching param- eterization with a shifted time schedule and a 4-step uni- form inference schedule, following [20]. Text prompts are curated from the VidProM [58] dataset, filtered...
-
[69]
Additional results We report all 16 VBench metrics and compare them against CausVid [65] and Self-Forcing [20]. As shown in Figure 6, DSAmatches or surpasses existing models in both visual quality and temporal consistency across the full set of met- rics, while maintaining efficient generation speed. Addi- tional qualitative results are provided in Figure...
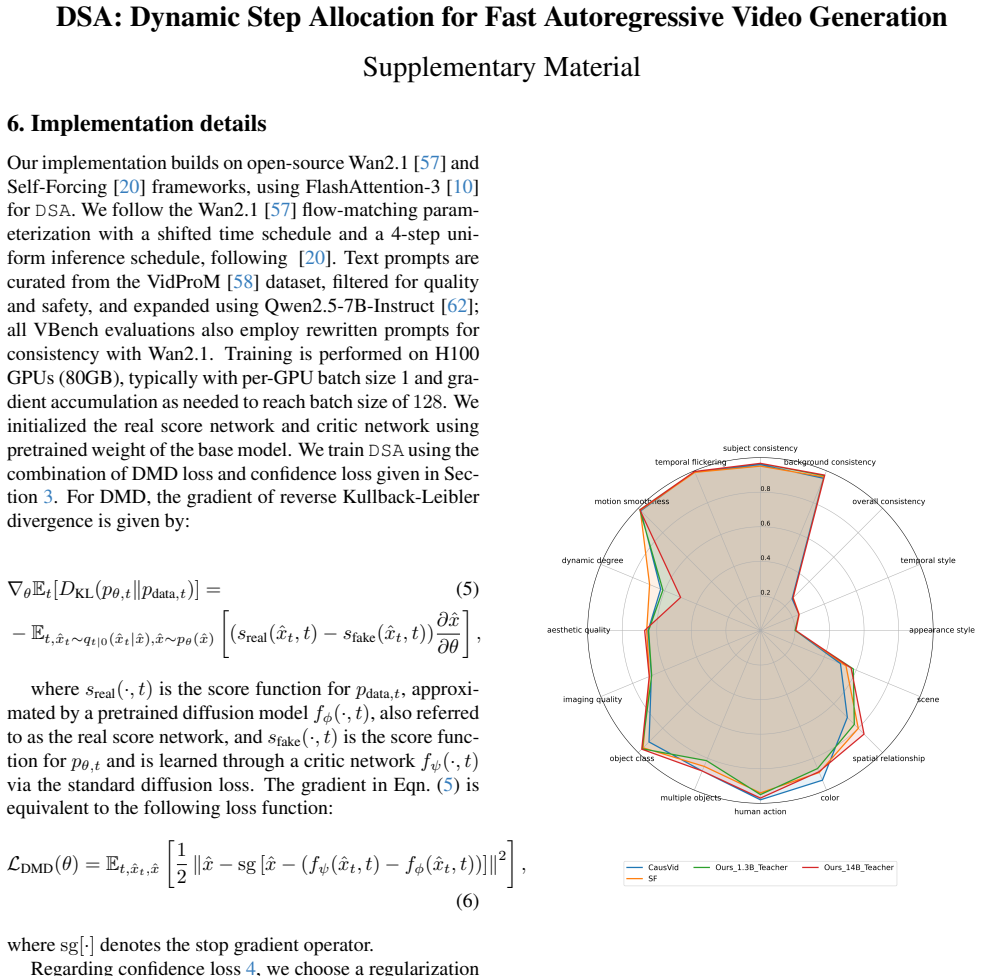
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.