ChannelTok: Efficient Flexible-Length Vision Tokenization
Pith reviewed 2026-06-28 07:07 UTC · model grok-4.3
The pith
Treating each latent channel as a token yields flexible-length vision representations that maintain high perceptual quality with a lightweight model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing an image as an ordered set of latent channels and training with stochastic tail-dropping, the model produces a representation whose prefix of any length already constitutes a valid, high-quality encoding; this single mechanism simultaneously delivers flexible compression, variable-length generation, and competitive perceptual fidelity on ImageNet while using fewer parameters and faster decoding than prior flexible tokenizers.
What carries the argument
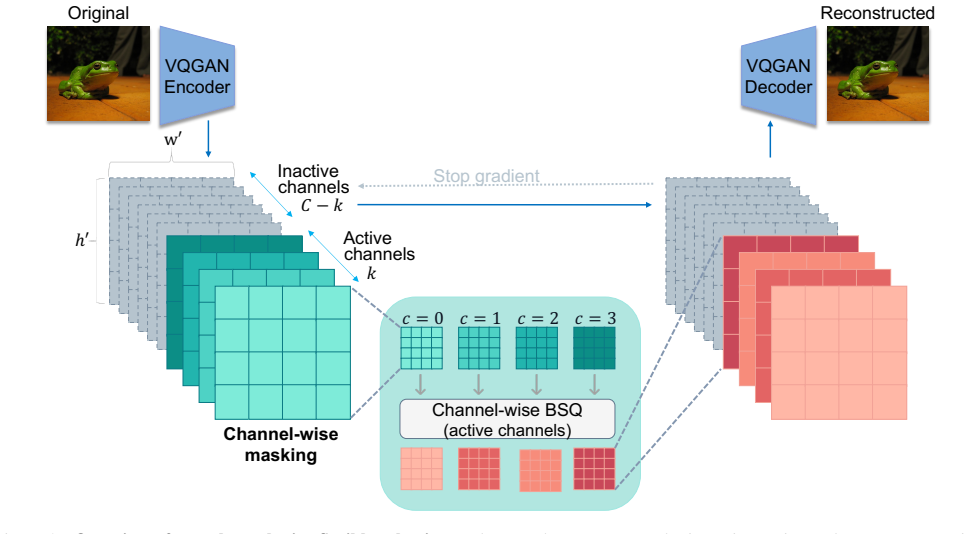
Stochastic tail-dropping during training, which forces latent channels to self-organize by semantic importance so that the prefix of k channels suffices for any budget.
If this is right
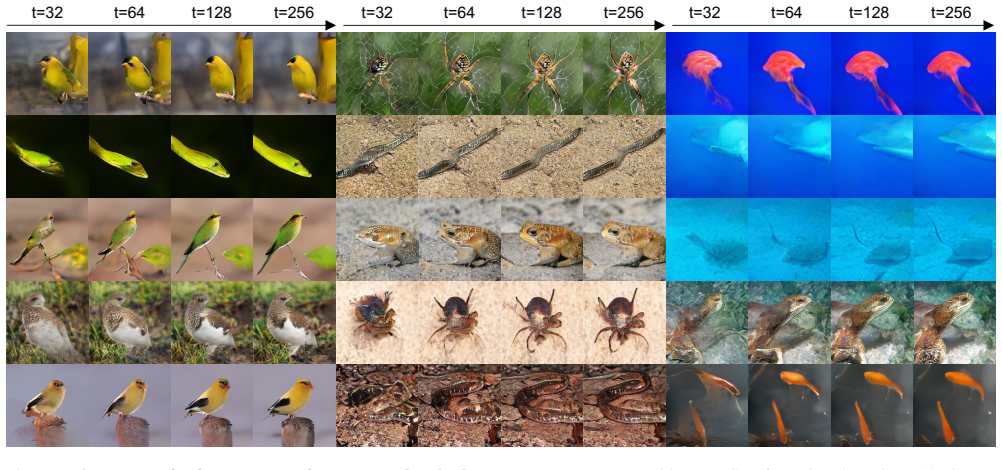
- Quality remains consistent when the same model is evaluated at many different token budgets on ImageNet.
- Variable-length autoregressive image generation becomes possible by emitting channels sequentially without architectural changes.
- Decoding speed increases because the decoder operates on a simple ordered channel list rather than iterative spatial refinement.
- Model size stays small because the backbone is a lightweight CNN-Transformer hybrid rather than a parameter-heavy spatial tokenizer.
Where Pith is reading between the lines
- The same prefix-ordering property could be tested for progressive image transmission where partial channel sets are sent first.
- If the importance ordering generalizes across datasets, the method might reduce retraining costs when adapting to new domains.
- The channel view may simplify integration with existing channel-wise compression pipelines used in video codecs.
Load-bearing premise
Stochastic tail-dropping during training will reliably sort channels by semantic importance so that keeping only the earliest channels preserves quality at every length.
What would settle it
An experiment that shows higher perceptual quality when any later channel is retained instead of the corresponding prefix channel at the same total count, or that quality collapses abruptly at particular k values.
Figures










read the original abstract
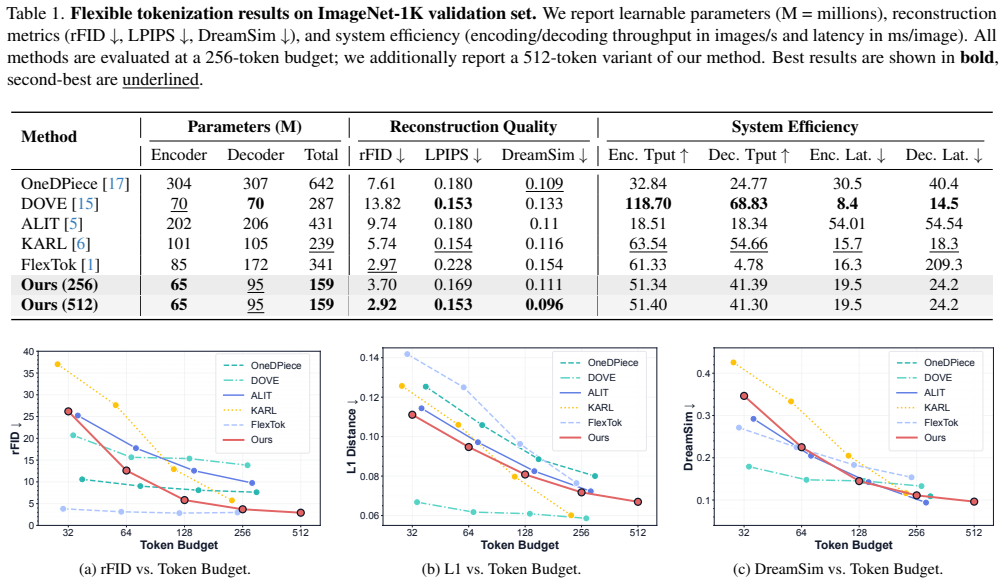
Leading flexible vision tokenizers achieve SOTA quality at an extreme cost, relying on parameter-heavy backbones and slow, multi-step generative decoders. We depart from this complex, spatial-token paradigm and introduce a simple, lightweight, and fast channel-wise flexible-length tokenizer. Our method treats each latent channel as a visual token, enabling a parameter-efficient CNN-Transformer hybrid backbone. Furthermore, employing a stochastic tail-dropping paradigm during training naturally forces channels to organize by semantic importance. This allows for flexible compression at inference by simply retaining the first $k$ channels, and naturally enables variable-length autoregressive image generation. We validate our approach through extensive experiments on ImageNet, demonstrating consistent quality across diverse token budgets. The results establish a new quality-efficiency frontier: our model achieves state-of-the-art perceptual quality (rFID 2.92) while being $8.6\times$ faster in decoding and $2.1\times$ smaller (159M params) than the next-best alternative. Our work establishes channel-wise tokenization as a powerful and practical paradigm for efficient visual representation. Project page: https://channeltok.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ChannelTok, a channel-wise flexible-length vision tokenizer based on a lightweight CNN-Transformer hybrid backbone. It employs stochastic tail-dropping during training to induce semantic ordering of latent channels, enabling inference-time flexible compression by retaining the first k channels and supporting variable-length autoregressive generation. On ImageNet, it reports state-of-the-art perceptual quality (rFID 2.92) together with 8.6× faster decoding and a 2.1× smaller model (159M parameters) relative to the next-best flexible tokenizer.
Significance. If the tail-dropping mechanism reliably produces monotonically ordered channels and the reported efficiency/quality numbers hold under controlled comparison, the work would establish a practical alternative to spatial-token paradigms for efficient, variable-budget visual tokenization, with direct implications for autoregressive image models and compression pipelines.
major comments (2)
- [Abstract and method description] The central claim that stochastic tail-dropping 'naturally forces channels to organize by semantic importance' (Abstract) is load-bearing for the flexible-length inference procedure, yet no per-channel ablation, importance ranking, or monotonicity test is presented to distinguish this from the decoder simply learning to ignore dropped channels. Without such evidence, the equivalence between training distribution and test-time truncation remains unverified.
- [Abstract and experimental section] The SOTA claims (rFID 2.92, 8.6× decoding speedup, 159M parameters) rest on empirical results whose experimental setup, baseline implementations, controls, and statistical significance are not detailed in the abstract or summary of results, making it impossible to assess whether the reported frontier is robust.
minor comments (1)
- [Method] Notation for the channel dimension and the tail-dropping probability schedule should be introduced with explicit equations rather than prose only.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments. We address each major point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and method description] The central claim that stochastic tail-dropping 'naturally forces channels to organize by semantic importance' (Abstract) is load-bearing for the flexible-length inference procedure, yet no per-channel ablation, importance ranking, or monotonicity test is presented to distinguish this from the decoder simply learning to ignore dropped channels. Without such evidence, the equivalence between training distribution and test-time truncation remains unverified.
Authors: We agree that providing explicit evidence for the semantic ordering induced by stochastic tail-dropping would strengthen the paper. The training procedure is intended to enforce this by exposing the model to random truncations, encouraging earlier channels to capture more critical information. To address this, we will include additional experiments in the revision, such as per-channel ablation studies measuring reconstruction quality when dropping channels in different orders, and visualizations of channel importance rankings to demonstrate monotonicity. revision: yes
-
Referee: [Abstract and experimental section] The SOTA claims (rFID 2.92, 8.6× decoding speedup, 159M parameters) rest on empirical results whose experimental setup, baseline implementations, controls, and statistical significance are not detailed in the abstract or summary of results, making it impossible to assess whether the reported frontier is robust.
Authors: The full experimental details, including dataset splits, training procedures, baseline re-implementations, and evaluation metrics, are described in Section 4 (Experiments) of the manuscript. We acknowledge that the abstract and result summary could be more self-contained. In the revision, we will augment the abstract with a concise description of the evaluation protocol and add a dedicated paragraph in the results section summarizing the controls and statistical significance of the reported improvements. revision: partial
Circularity Check
No significant circularity; claims rest on empirical validation rather than self-referential derivations
full rationale
The paper presents a channel-wise tokenizer using stochastic tail-dropping to enable flexible compression, with performance claims (rFID 2.92, speed/size gains) backed by ImageNet experiments. No equations, fitted-parameter predictions, or self-citation chains are shown that reduce the ordering claim or results to inputs by construction. The 'naturally forces' assertion is an empirical hypothesis tested via experiments, not a definitional or fitted reduction. This is self-contained against external benchmarks, warranting a low score.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flextok: Re- sampling images into 1d token sequences of flexible length
Roman Bachmann, Jesse Allardice, David Mizrahi, Enrico Fini, O ˘guzhan Fatih Kar, Elmira Amirloo, Alaaeldin El- Nouby, Amir Zamir, and Afshin Dehghan. Flextok: Re- sampling images into 1d token sequences of flexible length. arXiv preprint arXiv:2502.13967, 2025
-
[2]
Es- timating or propagating gradients through stochastic neurons for conditional computation
Yoshua Bengio, Nicholas L´eonard, and Aaron Courville. Es- timating or propagating gradients through stochastic neurons for conditional computation. 2013
2013
-
[3]
Large scale GAN training for high fidelity natural image synthesis
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis. InInt. Conf. Learn. Represent., 2019
2019
-
[4]
A dendrite method for cluster analysis.Communications in Statistics-Theory and Methods, 3(1):1–27, 1974
Tadeusz Cali´nski and Jerzy Harabasz. A dendrite method for cluster analysis.Communications in Statistics-Theory and Methods, 3(1):1–27, 1974
1974
-
[5]
Adaptive length im- age tokenization via recurrent allocation.arXiv preprint arXiv:2411.02393, 2024
Shivam Duggal, Sanghyun Byun, William T Freeman, An- tonio Torralba, and Phillip Isola. Adaptive length im- age tokenization via recurrent allocation.arXiv preprint arXiv:2411.02393, 2024
-
[6]
Freeman, Antonio Torralba, and Phillip Isola
Shivam Duggal, Sanghyun Byun, William T Freeman, Anto- nio Torralba, and Phillip Isola. Single-pass adaptive image tokenization for minimum program search.arXiv preprint arXiv:2507.07995, 2025
-
[7]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bj¨orn Ommer. Taming transformers for high-resolution image synthesis. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12873–12883, 2021
2021
-
[8]
Dreamsim: Learn- ing new dimensions of human visual similarity using synthetic data
Stephanie Fu, Netanel Y Ramesh, V ongani H Xie, Yue Luo, Philip HS Torr, Joshua B Tenenbaum, Olga Russakovsky, William T Freeman, and Stephanie Wong. Dreamsim: Learn- ing new dimensions of human visual similarity using synthetic data. InAdvances in Neural Information Processing Systems, 2023
2023
-
[9]
Reducing the dimensionality of data with neural networks.Science, 313 (5786):504–507, 2006
Geoffrey E Hinton and Ruslan R Salakhutdinov. Reducing the dimensionality of data with neural networks.Science, 313 (5786):504–507, 2006
2006
-
[10]
Image-to-image translation with conditional adversarial net- works
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial net- works. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1125–1134, 2017
2017
-
[11]
Re- thinking fid: Towards a better evaluation metric for image generation
Sadeep Jayasumana, Srikumar Ramalingam, Andreas Veit, Daniel Glasner, Ayan Chakrabarti, and Sanjiv Kumar. Re- thinking fid: Towards a better evaluation metric for image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9307–9315, 2024. 9
2024
-
[12]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In IEEE Conf. Comput. Vis. Pattern Recog., pages 4401–4410, 2019
2019
-
[13]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
Kakade, Prateek Jain, and Ali Farhadi
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham M. Kakade, Prateek Jain, and Ali Farhadi. Matryoshka representation learning. InAdvances in Neural Information Processing Systems 35 (NeurIPS 2022), 2022
2022
-
[15]
Images are worth variable length of representations
Lingjun Mao, Zikang Jin, Haokui Wang, Xiaodan Zhang, and Xin Li. Images are worth variable length of representations. arXiv preprint arXiv:2506.03643, 2025
-
[16]
Finite Scalar Quantization: VQ-VAE Made Simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
One-d-piece: Image tokenizer meets quality-controllable compression
Kazuki Miwa, Go Irie, Yuki Nakashima, and Rin-ichiro Taniguchi. One-d-piece: Image tokenizer meets quality- controllable compression.arXiv preprint arXiv:2501.10064, 2025
-
[18]
Spectral normalization for generative adver- sarial networks
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adver- sarial networks. InInternational Conference on Learning Representations, 2018
2018
-
[19]
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e J´egou, Julien Mairal,...
2023
-
[20]
Imagenet large scale visual recognition chal- lenge.International Journal of Computer Vision, 115:211– 252, 2014
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael S Bernstein, Alexander C Berg, and Li Fei-Fei. Imagenet large scale visual recognition chal- lenge.International Journal of Computer Vision, 115:211– 252, 2014
2014
-
[21]
Cat: Content-adaptive image tokenization.arXiv preprint arXiv:2501.03120, 2025
Junhong Shen, Kushal Tirumala, Michihiro Yasunaga, Is- han Misra, Luke Zettlemoyer, Lili Yu, and Chunting Zhou. Cat: Content-adaptive image tokenization.arXiv preprint arXiv:2501.03120, 2025
-
[22]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Li- wei Wang. Detailflow: 1d coarse-to-fine autoregressive im- age generation via next-detail prediction.arXiv preprint arXiv:2505.21473, 2024
-
[24]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InAdvances in Neu- ral Information Processing Systems, 2017
2017
-
[25]
Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
2004
-
[26]
AToken: Adaptive tokenization for vision transformers.arXiv preprint arXiv:2509.14476, 2024
Wentao Wu, Libin Huang, Wenyi Xu, Qi Chen, Yue Zhang, and Weiwei Zhou. AToken: Adaptive tokenization for vision transformers.arXiv preprint arXiv:2509.14476, 2024
-
[27]
Elastictok: Adaptive tokenization for image and video.arXiv preprint arXiv:2410.08368, 2024
Wilson Yan, Matei Zaharia, V olodymyr Mnih, Pieter Abbeel, Aleksandra Faust, and Hao Liu. Elastictok: Adaptive tokeniza- tion for image and video.arXiv preprint arXiv:2410.08368, 2024
-
[28]
Quantize-then-rectify: Efficient vq-vae training.arXiv preprint arXiv:2507.10547, 2025
Jingfeng Yao and Xinggang Wang. Quantize-then-rectify: Efficient vq-vae training.arXiv preprint arXiv:2507.10547, 2025
-
[29]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Lijun Yu, Jos´e Lezama, Nitesh B Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G Hauptmann, et al. Language model beats diffusion–tokenizer is key to visual generation.arXiv preprint arXiv:2310.05737, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 586–595, 2018
2018
-
[31]
Yue Zhao, Yuanjun Panda, Zhengzhong Xu, Zhenzhong Wang, Gaurav Kumar, Yu Zhang, Jinshuo Zhou, Yan Chen, Guan Wang, Jiaqi Zhang, et al. Image and video tok- enization with binary spherical quantization.arXiv preprint arXiv:2406.07548, 2024
-
[32]
Shaobin Zhuang, Yiwei Guo, Canmiao Fu, Zhipeng Huang, Zeyue Tian, Fangyikang Wang, Ying Zhang, Chen Li, and Yali Wang. Wetok: Powerful discrete tokenization for high-fidelity visual reconstruction.arXiv preprint arXiv:2508.05599, 2025. 10 ChannelTok: Efficient Flexible-Length Vision Tokenization Supplementary Material A. Training and Evaluation Details A....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.