TransTac: Visuo-Tactile Modality Transition via Ultraviolet-Encoded Transparent Elastomers
Pith reviewed 2026-06-28 06:28 UTC · model grok-4.3
The pith
TransTac integrates vision and tactile sensing in one transparent device to reach 83.3 percent zero-shot recognition accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
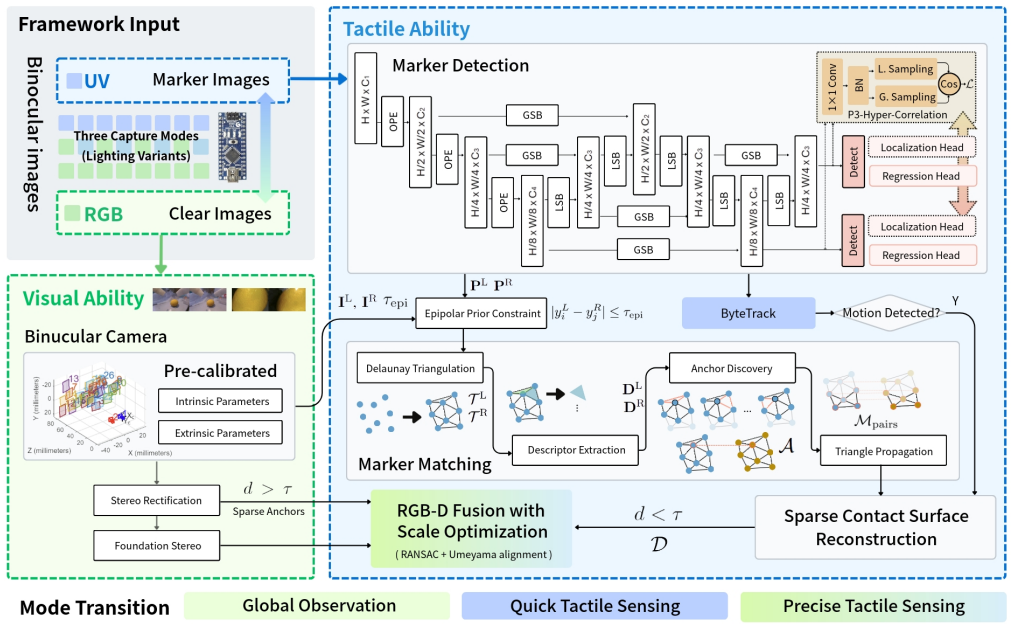
TransTac is a transparent ultraviolet-encoded binocular vision-based tactile sensor that integrates visual observation and marker-based tactile reconstruction within a single compact device, using a lightweight detector and prior-guided Delaunay stereo matching to achieve up to 83.3 percent zero-shot recognition accuracy on tactile images and class-center similarity exceeding 0.77.
What carries the argument
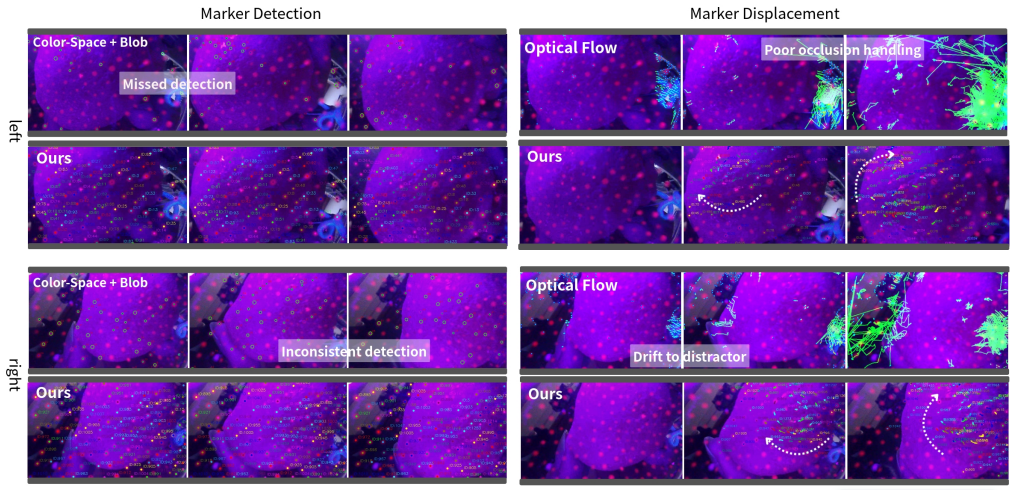
Prior-guided Delaunay stereo matching applied to UV-reflective markers inside a transparent elastomer, enabled by a lightweight detector for stable localization under contact and deformation.
If this is right
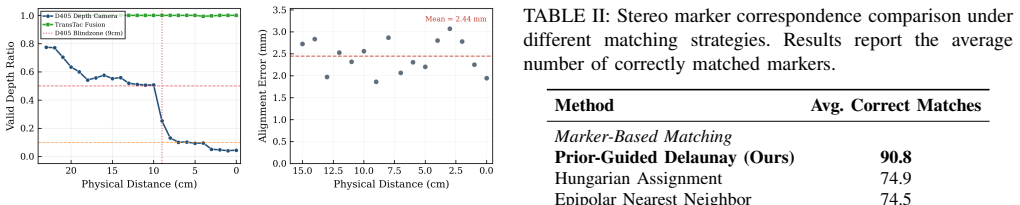
- Correspondence robustness rises by about 21 percent relative to global assignment methods.
- Zero-shot recognition on tactile images exceeds opaque baselines by roughly 50 percentage points.
- Class-center similarity between tactile and natural-image embeddings increases from around 0.2 to over 0.77.
- Near-distance geometric coverage extends beyond the range where RGB-D depth becomes unreliable.
- A working prototype can be built for an approximate hardware cost of 70 dollars.
Where Pith is reading between the lines
- Robots could alternate between wide-field visual and high-resolution contact sensing without swapping end-effectors.
- The same transparency-plus-marker approach might apply to other close-range multi-modal sensing problems.
- Real-time manipulation experiments would be needed to confirm whether reconstruction speed meets closed-loop control demands.
- Lower-cost multi-modal perception could become feasible for smaller research platforms or educational robots.
Load-bearing premise
The lightweight detector must keep locating the densely placed semitransparent markers reliably when the elastomer deforms under contact.
What would settle it
A test in which marker localization or triangulation accuracy collapses under typical grasping deformations, causing zero-shot recognition to fall near opaque-baseline levels.
Figures


read the original abstract
Vision-based tactile sensors (VBTS) recover high-resolution contact geometry but typically rely on opaque elastomer layers that prevent visual transparency, while RGB-D cameras provide global depth perception yet degrade significantly at close range. To address this limitation, we present TransTac, a transparent ultraviolet (UV)-encoded binocular VBTS that integrates visual observation and marker-based tactile reconstruction within a single compact device. The system employs a transparent elastomer embedded with UV-reflective markers and a prior-guided Delaunay stereo matching algorithm for robust sparse triangulation. To reliably detect densely distributed semitransparent markers, we develop a lightweight detector that enables stable localization under contact and deformation. The proposed prior-guided Delaunay matching improves correspondence robustness by approximately 21% compared with global assignment baselines while maintaining high reconstruction accuracy. In semantic evaluation, TransTac achieves up to 83.3% zero-shot recognition accuracy on tactile images, exceeding opaque tactile baselines by approximately 50 percentage points. Embedding analysis further reveals substantially stronger cross-modal alignment with natural images, with class-center similarity increasing from around 0.2 to over 0.77. Controlled near-distance experiments quantify the degradation of RGB-D depth reliability and demonstrate extended geometric coverage enabled by visuo-tactile integration. Finally, a compact prototype is implemented with an approximate hardware cost of $70.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TransTac, a compact transparent UV-encoded binocular vision-based tactile sensor (VBTS) that combines visual observation with marker-based tactile reconstruction in one device. It embeds UV-reflective markers in a transparent elastomer, employs a lightweight detector for semitransparent marker localization under deformation, and uses a prior-guided Delaunay stereo matching algorithm for sparse triangulation. Reported results include a 21% improvement in correspondence robustness over global assignment baselines, up to 83.3% zero-shot tactile image recognition accuracy (approximately 50 percentage points above opaque baselines), increased class-center embedding similarity from ~0.2 to >0.77, and extended geometric coverage versus RGB-D at close range, all with a ~$70 prototype.
Significance. If the quantitative claims hold with proper validation, the work would enable integrated visuo-tactile sensing that overcomes opacity limitations of standard VBTS while mitigating close-range RGB-D degradation, supporting applications in robotic manipulation requiring both modalities. The low-cost hardware implementation is a practical contribution. No machine-checked proofs, open reproducible code, or parameter-free derivations are described.
major comments (3)
- [Abstract] Abstract: The reported 83.3% zero-shot recognition accuracy and 50-percentage-point improvement over opaque baselines are presented without error bars, dataset sizes, number of classes, or statistical significance tests, rendering the central performance claims difficult to assess.
- [Abstract] Abstract (paragraph on marker detection): The lightweight detector is asserted to enable 'stable localization' of densely distributed semitransparent markers under contact and deformation, yet no quantitative metrics (precision, recall, localization error, or failure rates) are supplied; this assumption is load-bearing for the prior-guided Delaunay matching and the claimed 21% robustness gain.
- [Abstract] Abstract: The embedding similarity increase from ~0.2 to >0.77 and the 21% matching robustness improvement are stated without reference to the exact baselines, number of trials, or variance, preventing evaluation of whether these figures support the cross-modal alignment and triangulation claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and indicate where revisions to the manuscript will be made to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 83.3% zero-shot recognition accuracy and 50-percentage-point improvement over opaque baselines are presented without error bars, dataset sizes, number of classes, or statistical significance tests, rendering the central performance claims difficult to assess.
Authors: The full manuscript provides the dataset details (including number of classes and samples), error bars in the associated figures and tables, and results from multiple trials. We will revise the abstract to include the number of classes, approximate dataset size, and a note that variance and statistical comparisons are reported in the experimental results section. revision: yes
-
Referee: [Abstract] Abstract (paragraph on marker detection): The lightweight detector is asserted to enable 'stable localization' of densely distributed semitransparent markers under contact and deformation, yet no quantitative metrics (precision, recall, localization error, or failure rates) are supplied; this assumption is load-bearing for the prior-guided Delaunay matching and the claimed 21% robustness gain.
Authors: The current manuscript does not supply the requested quantitative metrics for the detector itself. The supporting evidence is the end-to-end 21% robustness improvement and reconstruction accuracy. We will revise the abstract to remove the term 'stable' and qualify the localization claim to avoid implying unprovided per-metric validation. revision: partial
-
Referee: [Abstract] Abstract: The embedding similarity increase from ~0.2 to >0.77 and the 21% matching robustness improvement are stated without reference to the exact baselines, number of trials, or variance, preventing evaluation of whether these figures support the cross-modal alignment and triangulation claims.
Authors: The baselines are the global assignment methods described in the method section; the 21% figure is the average improvement across trials with variance shown in the results. We will revise the abstract to name the baseline methods explicitly and reference the number of trials and observed variance. revision: yes
- Lack of quantitative metrics (precision, recall, localization error, or failure rates) for the lightweight detector
Circularity Check
No significant circularity; derivation relies on standard CV methods and experimental outcomes
full rationale
The abstract and description present TransTac as a hardware+algorithm system using a lightweight detector for UV markers and prior-guided Delaunay stereo matching. These are described as standard computer-vision techniques applied to a new transparent elastomer design. Reported metrics (83.3% accuracy, 21% robustness improvement, embedding similarity) are stated as measured results from experiments, not quantities obtained by fitting parameters to the target metric itself or by self-citation chains. No equations, self-definitional loops, or load-bearing prior-author uniqueness theorems appear in the supplied text. The central claims remain externally falsifiable via replication on the described hardware.
Axiom & Free-Parameter Ledger
invented entities (1)
-
UV-reflective markers embedded in transparent elastomer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jacquard v2: Refining datasets using the human in the loop data correction method,
Q. Li and S. Yuan, “Jacquard v2: Refining datasets using the human in the loop data correction method,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 7932–7938
2024
-
[2]
Gelslim: A high-resolution, compact, robust, and calibrated tactile- sensing finger,
E. Donlon, S. Dong, M. Liu, J. Li, E. Adelson, and A. Rodriguez, “Gelslim: A high-resolution, compact, robust, and calibrated tactile- sensing finger,” in2018 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS). IEEE, 2018, pp. 1927–1934
2018
-
[3]
Mater- obot: Material recognition in wearable robotics for people with visual impairments,
J. Zheng, J. Zhang, K. Yang, K. Peng, and R. Stiefelhagen, “Mater- obot: Material recognition in wearable robotics for people with visual impairments,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 2303–2309
2024
-
[4]
Tirgel: A visuo-tactile sensor with total internal reflection mechanism for external observation and contact detection,
S. Zhang, Y . Sun, J. Shan, Z. Chen, F. Sun, Y . Yang, and B. Fang, “Tirgel: A visuo-tactile sensor with total internal reflection mechanism for external observation and contact detection,”IEEE Robotics and Automation Letters, vol. 8, no. 10, pp. 6307–6314, 2023
2023
-
[5]
Making sense of vision and touch: Learning multimodal representations for contact-rich tasks,
M. A. Lee, Y . Zhu, P. Zachares, M. Tan, K. Srinivasan, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg, “Making sense of vision and touch: Learning multimodal representations for contact-rich tasks,”IEEE Transactions on Robotics, vol. 36, no. 3, pp. 582–596, 2020
2020
-
[6]
Gelsight: High-resolution robot tactile sensors for estimating geometry and force,
W. Yuan, S. Dong, and E. H. Adelson, “Gelsight: High-resolution robot tactile sensors for estimating geometry and force,”Sensors, vol. 17, no. 12, p. 2762, 2017
2017
-
[7]
Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation,
M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V . R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammereret al., “Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation,”IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 3838–3845, 2020
2020
-
[8]
Slip detection with a biomimetic tactile sensor,
J. W. James, N. Pestell, and N. F. Lepora, “Slip detection with a biomimetic tactile sensor,”IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 3340–3346, 2018
2018
-
[9]
Stereotactip: Vision-based tactile sensing with biomimetic skin-marker arrange- ments,
C. Lu, K. Tang, X. Hui, H. Li, S. Nam, and N. F. Lepora, “Stereotactip: Vision-based tactile sensing with biomimetic skin-marker arrange- ments,”IEEE/ASME Transactions on Mechatronics, 2025
2025
-
[10]
Densetact: Optical tactile sensor for dense shape reconstruction,
W. K. Do and M. Kennedy, “Densetact: Optical tactile sensor for dense shape reconstruction,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 6188–6194
2022
-
[11]
Gelslim 3.0: High-resolution measurement of shape, force and slip in a compact tactile-sensing finger,
I. H. Taylor, S. Dong, and A. Rodriguez, “Gelslim 3.0: High-resolution measurement of shape, force and slip in a compact tactile-sensing finger,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 10 781–10 787
2022
-
[12]
C. Lin, Z. Lin, S. Wang, and H. Xu, “Dtact: A vision-based tactile sensor that measures high-resolution 3d geometry directly from dark- ness,”arXiv preprint arXiv:2209.13916, 2022
arXiv 2022
-
[13]
9dtact: A compact vision-based tactile sensor for accurate 3d shape reconstruction and generalizable 6d force estimation,
C. Lin, H. Zhang, J. Xu, L. Wu, and H. Xu, “9dtact: A compact vision-based tactile sensor for accurate 3d shape reconstruction and generalizable 6d force estimation,”IEEE Robotics and Automation Letters, vol. 9, no. 2, pp. 923–930, 2023
2023
-
[14]
Combining finger vision and optical tactile sensing: Reducing and handling errors while cutting vegetables,
A. Yamaguchi and C. G. Atkeson, “Combining finger vision and optical tactile sensing: Reducing and handling errors while cutting vegetables,” in2016 IEEE-RAS 16th international conference on humanoid robots (humanoids). IEEE, 2016, pp. 1045–1051
2016
-
[15]
Fingervision tactile sensor design and slip detection using convolutional lstm network,
Y . Zhang, Z. Kan, Y . A. Tse, Y . Yang, and M. Y . Wang, “Fingervision tactile sensor design and slip detection using convolutional lstm network,”arXiv preprint arXiv:1810.02653, 2018
Pith/arXiv arXiv 2018
-
[16]
The tactip family: Soft optical tactile sensors with 3d-printed biomimetic morphologies,
B. Ward-Cherrier, N. Pestell, L. Cramphorn, B. Winstone, M. E. Giannaccini, J. Rossiter, and N. F. Lepora, “The tactip family: Soft optical tactile sensors with 3d-printed biomimetic morphologies,”Soft robotics, vol. 5, no. 2, pp. 216–227, 2018
2018
-
[17]
Tac2pose: Tactile object pose estimation from the first touch,
M. Bauza, A. Bronars, and A. Rodriguez, “Tac2pose: Tactile object pose estimation from the first touch,”The International Journal of Robotics Research, vol. 42, no. 13, pp. 1185–1209, 2023
2023
-
[18]
Compdvision: Combining near-field 3d visual and tactile sensing using a compact compound-eye imaging system,
L. Luo, B. Zhang, Z. Peng, Y . K. Cheung, G. Zhang, Z. Li, M. Y . Wang, and H. Yu, “Compdvision: Combining near-field 3d visual and tactile sensing using a compact compound-eye imaging system,” in 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 262–268
2024
-
[19]
Real-time and robust feature detection of continuous marker pattern for dense 3-d deformation measurement,
M. Li, Y . H. Zhou, T. Li, and Y . Jiang, “Real-time and robust feature detection of continuous marker pattern for dense 3-d deformation measurement,”Measurement, vol. 221, p. 113479, 2023
2023
-
[20]
Spectac: A visual-tactile dual- modality sensor using uv illumination,
Q. Wang, Y . Du, and M. Y . Wang, “Spectac: A visual-tactile dual- modality sensor using uv illumination,” in2022 international confer- ence on robotics and automation (ICRA). IEEE, 2022, pp. 10 844– 10 850
2022
-
[21]
Efficient large-scale stereo matching,
A. Geiger, M. Roser, and R. Urtasun, “Efficient large-scale stereo matching,” inAsian conference on computer vision. Springer, 2010, pp. 25–38
2010
-
[22]
Metrological characterization and comparison of d415, d455, l515 realsense devices in the close range,
M. Servi, E. Mussi, A. Profili, R. Furferi, Y . V olpe, L. Governi, and F. Buonamici, “Metrological characterization and comparison of d415, d455, l515 realsense devices in the close range,”Sensors, vol. 21, no. 22, p. 7770, 2021
2021
-
[23]
nnwnet: Rethinking the use of transformers in biomedical image segmentation and calling for a unified evaluation benchmark,
Y . Zhou, L. Li, L. Lu, and M. Xu, “nnwnet: Rethinking the use of transformers in biomedical image segmentation and calling for a unified evaluation benchmark,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 20 852–20 862
2025
-
[24]
Center- net: Keypoint triplets for object detection,
K. Duan, S. Bai, L. Xie, H. Qi, Q. Huang, and Q. Tian, “Center- net: Keypoint triplets for object detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6569–6578
2019
-
[25]
Bytetrack: Multi-object tracking by associating every detection box,
Y . Zhang, P. Sun, Y . Jiang, D. Yu, F. Weng, Z. Yuan, P. Luo, W. Liu, and X. Wang, “Bytetrack: Multi-object tracking by associating every detection box,” inEuropean conference on computer vision. Springer, 2022, pp. 1–21
2022
-
[26]
Foundationstereo: Zero-shot stereo matching,
B. Wen, M. Trepte, J. Aribido, J. Kautz, O. Gallo, and S. Birchfield, “Foundationstereo: Zero-shot stereo matching,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5249– 5260
2025
-
[27]
Yolo- world: Real-time open-vocabulary object detection,
T. Cheng, L. Song, Y . Ge, W. Liu, X. Wang, and Y . Shan, “Yolo- world: Real-time open-vocabulary object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 16 901–16 911
2024
-
[28]
Yoloe: Real-time seeing anything,
A. Wang, L. Liu, H. Chen, Z. Lin, J. Han, and G. Ding, “Yoloe: Real-time seeing anything,”arXiv preprint arXiv:2503.07465, 2025
arXiv 2025
-
[29]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdul- mohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafaet al., “Siglip 2: Multilingual vision-language encoders with improved se- mantic understanding, localization, and dense features,”arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[30]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[31]
3d with kinect,
J. Smisek, M. Jancosek, and T. Pajdla, “3d with kinect,” in2011 IEEE international conference on computer vision workshops (ICCV Workshops). IEEE, 2011, pp. 1154–1160
2011
-
[32]
Tactile data generation and applications based on visuo-tactile sensors: A review,
Y . Sun, N. Cheng, S. Zhang, W. Li, L. Yang, S. Cui, H. Liu, F. Sun, J. Zhang, D. Guoet al., “Tactile data generation and applications based on visuo-tactile sensors: A review,”Information Fusion, vol. 121, p. 103162, 2025
2025
-
[33]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5294–5306
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.