4D Reconstruction from Sparse Dynamic Cameras
Pith reviewed 2026-06-28 06:43 UTC · model grok-4.3
The pith
Sparse dynamic cameras with inter-camera track initialization enable consistent 4D reconstruction where monocular and fixed-camera methods fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
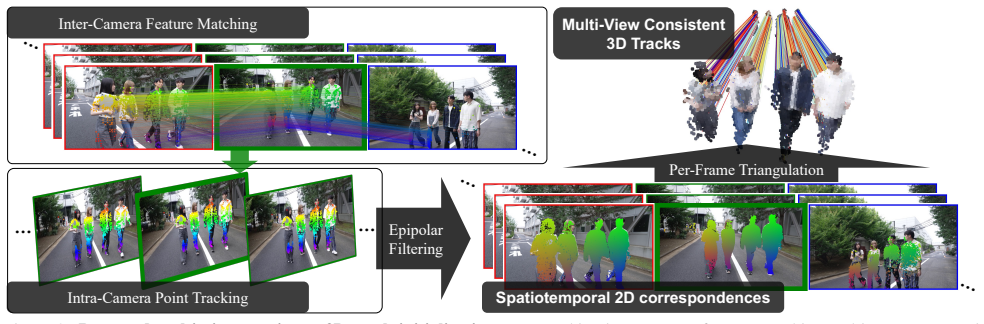
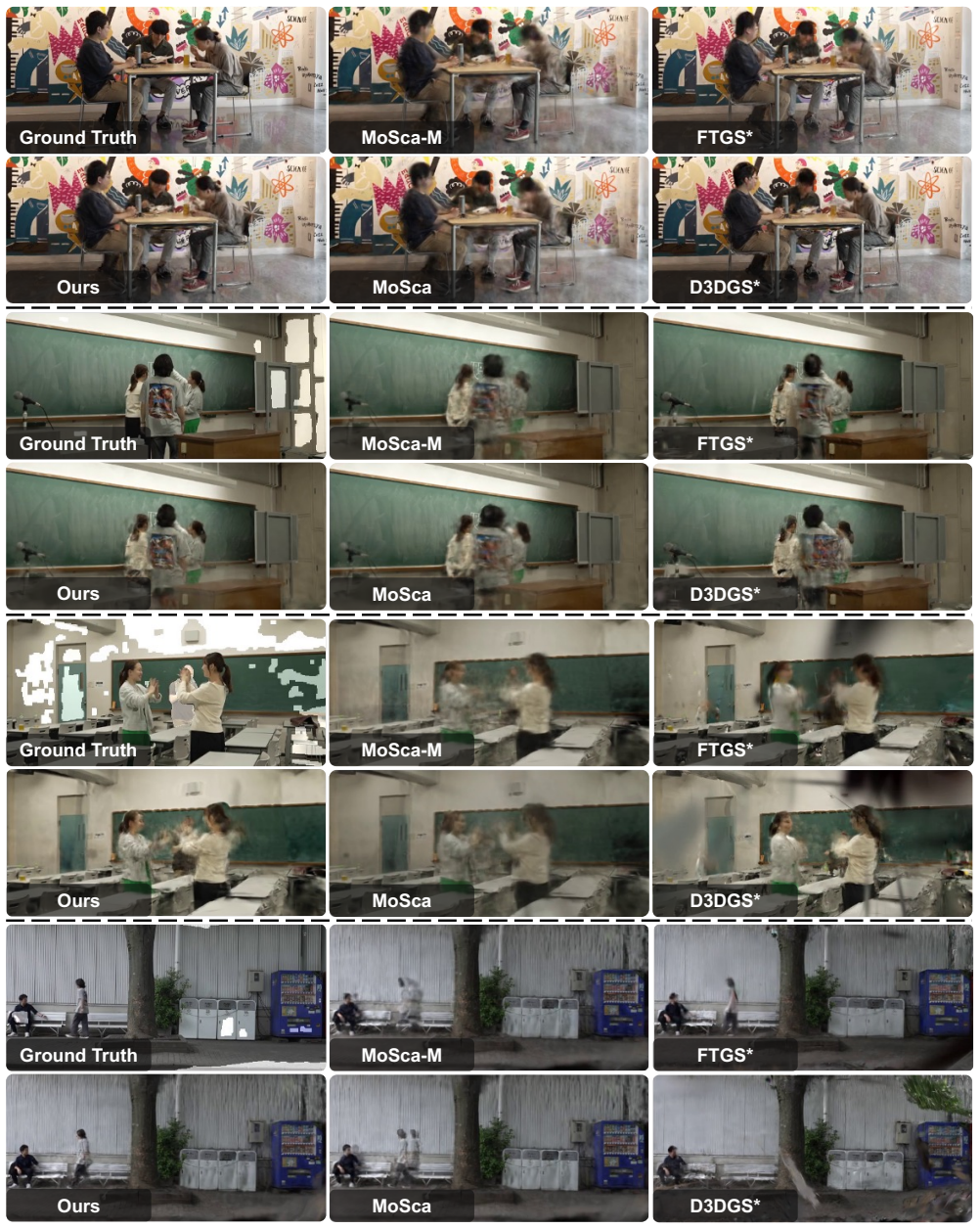
A 3D track initialization procedure that integrates inter-camera feature matching with intra-camera point tracking, combined with a noise-robust depth-ordering regularization loss and spatiotemporally diverse batch sampling, overcomes the spatiotemporal inconsistencies that defeat naive extensions of monocular or dense-fixed-camera methods and thereby improves 4D reconstruction quality in dynamic regions on the LetCamsGo benchmark.
What carries the argument
3D track initialization method that integrates inter-camera feature matching with intra-camera point tracking to enforce spatiotemporal consistency.
If this is right
- Reconstruction quality improves specifically in regions with independent object motion.
- The same capture hardware already used in sports and concert production can support 4D output without added fixed cameras.
- LetCamsGo supplies a public, standardized test set for comparing future sparse-dynamic methods.
- The pipeline remains practical for real-world video workflows that tolerate modest camera motion.
Where Pith is reading between the lines
- The initialization step may generalize to other multi-view dynamic tasks such as non-rigid structure from motion.
- Reducing the number of required moving cameras below three could become feasible once the consistency mechanisms are further tuned.
- The batch-sampling strategy might transfer to other optimization problems that suffer from view-time correlations.
- Combining the approach with existing monocular depth estimators could further lower the minimum number of cameras needed.
Load-bearing premise
That the 3D track initialization, depth-ordering loss, and diverse batch sampling are together necessary and sufficient to resolve the spatiotemporal inconsistencies that arise when cameras move independently.
What would settle it
A controlled ablation on LetCamsGo in which any one of the three proposed components is removed and the remaining system shows no improvement, or a decline, in dynamic-region reconstruction metrics relative to the strongest baseline.
Figures



read the original abstract
Although dynamic 3D (i.e., 4D) reconstruction from a monocular dynamic camera has recently advanced, it remains fundamentally limited by depth ambiguity. In this paper, we focus on an alternative practical way, i.e., sparse dynamic camera setup, where a handful of independently moving cameras capture the same subjects. While keeping capture costs low, this setup introduces multi-view constraints and remains practical for real-world video production such as sports, concerts, and TV shows. Despite its potential, our experiments show that naive extensions of existing monocular or dense-fixed camera-based methods are insufficient since they fail to resolve the complex spatiotemporal inconsistencies across views and time. To fill this gap, we propose a simple yet effective 3D track initialization method designed to ensure spatiotemporal consistency by integrating inter-camera feature matching with intra-camera point tracking. Additionally, we incorporate a noise-robust depth-ordering regularization loss and a spatiotemporally diverse batch sampling strategy to enhance optimization stability and cross-view generalization. Furthermore, to address the lack of standardized benchmarks for this task, we introduce LetCamsGo, a new real-world video dataset with 5 sequences across 4 diverse environments, recorded by three independently moving cameras and one fixed camera. Comprehensive benchmarking on LetCamsGo demonstrated that our proposed framework improves 4D reconstruction quality in dynamic regions compared with baselines, paving the way for a low-cost 4D reconstruction paradigm in the wild.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for 4D reconstruction from sparse dynamic cameras. It introduces a 3D track initialization method integrating inter-camera feature matching with intra-camera point tracking, a noise-robust depth-ordering regularization loss, and a spatiotemporally diverse batch sampling strategy to resolve spatiotemporal inconsistencies that cause naive extensions of monocular or dense-fixed methods to fail. The authors present the LetCamsGo dataset (5 sequences across 4 environments captured by three moving cameras and one fixed camera) and claim that comprehensive benchmarking shows improved 4D reconstruction quality in dynamic regions relative to baselines.
Significance. If the claimed improvements hold under rigorous evaluation, the work could enable practical low-cost 4D capture in dynamic real-world settings such as sports and concerts by exploiting multi-view constraints without requiring dense fixed rigs or accepting monocular depth ambiguity.
major comments (2)
- [Abstract] Abstract: the claim that 'comprehensive benchmarking on LetCamsGo demonstrated that our proposed framework improves 4D reconstruction quality in dynamic regions' is presented without any quantitative metrics, error bars, ablation tables, or dataset statistics, rendering the central empirical claim unverifiable from the supplied evidence.
- [Experiments] Experiments (benchmarking on LetCamsGo): the assertion that the three components (3D track initialization, noise-robust depth-ordering loss, spatiotemporally diverse batch sampling) overcome spatiotemporal inconsistencies rests on end-to-end comparisons but supplies no ablations that isolate the contribution of each component versus hyper-parameter tuning, implementation details of the underlying 4D representation, or dataset-specific biases.
minor comments (1)
- [Methods] Methods section: explicit equations for the depth-ordering loss and the batch-sampling procedure would improve reproducibility and allow readers to assess how they differ from standard regularization terms.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the empirical presentation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'comprehensive benchmarking on LetCamsGo demonstrated that our proposed framework improves 4D reconstruction quality in dynamic regions' is presented without any quantitative metrics, error bars, ablation tables, or dataset statistics, rendering the central empirical claim unverifiable from the supplied evidence.
Authors: We agree that the abstract would be strengthened by including summary quantitative evidence. The full paper contains the detailed metrics, comparisons, and dataset statistics in the Experiments section. We will revise the abstract to report key aggregate improvements (e.g., error reductions in dynamic regions) while remaining within length limits. revision: yes
-
Referee: [Experiments] Experiments (benchmarking on LetCamsGo): the assertion that the three components (3D track initialization, noise-robust depth-ordering loss, spatiotemporally diverse batch sampling) overcome spatiotemporal inconsistencies rests on end-to-end comparisons but supplies no ablations that isolate the contribution of each component versus hyper-parameter tuning, implementation details of the underlying 4D representation, or dataset-specific biases.
Authors: The referee correctly identifies that the current experiments emphasize end-to-end results. To isolate each component's contribution, we will add dedicated ablation studies in the revised manuscript. These will include controlled variants (with/without each module) while holding the 4D representation, hyperparameters, and training protocol fixed, plus discussion of potential dataset biases. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a 4D reconstruction framework using 3D track initialization via inter-camera matching and intra-camera tracking, a noise-robust depth-ordering loss, and spatiotemporally diverse batch sampling, evaluated on the new LetCamsGo dataset. No equations, fitted parameters, or predictions are presented in the provided text that reduce any claimed result to its inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatzes or renamings of known results appear. The central claims rest on empirical benchmarking and adaptation of standard geometric components, which remain independent of the method description itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
UltraSync.https://www.atomos.com/ wireless-sync/, 2025
ATOMOS. UltraSync.https://www.atomos.com/ wireless-sync/, 2025. 5, 1
2025
-
[2]
Per-Gaussian Embedding- Based Deformation for Deformable 3D Gaussian Splatting
Jeongmin Bae, Seoha Kim, Youngsik Yun, Hahyun Lee, Gun Bang, and Youngjung Uh. Per-Gaussian Embedding- Based Deformation for Deformable 3D Gaussian Splatting. InECCV, 2024. 3
2024
-
[3]
Recammaster: Camera-controlled gen- erative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, and Di Zhang. Recammaster: Camera-controlled gen- erative rendering from a single video. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14834–14844, 2025. 3, 1
2025
-
[4]
Immersive light field video with a layered mesh representation, 2020
Michael Broxton, John Flynn, Ryan Overbeck, Daniel Erick- son, Peter Hedman, Matthew Duvall, Jason Dourgarian, Jay Busch, Matt Whalen, and Paul Debevec. Immersive light field video with a layered mesh representation, 2020. 3
2020
-
[5]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InCVPR, 2020. 3, 1
2020
-
[6]
A benchmark dataset and evaluation methodology for video object segmentation
Perazzi Federico, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine- Hornung. A benchmark dataset and evaluation methodology for video object segmentation. InCVPR, 2016. 3
2016
-
[7]
Monocular dynamic view synthesis: A reality check
Hang Gao, Ruilong Li, Shubham Tulsiani, Bryan Russell, and Angjoo Kanazawa. Monocular dynamic view synthesis: A reality check. InNeurIPS, pages 33768–33780, 2022. 3, 6, 1
2022
-
[8]
QUEEN: QUantized efficient ENcoding for streaming free-viewpoint videos
Sharath Girish, Tianye Li, Amrita Mazumdar, Abhinav Shri- vastava, David Luebke, and Shalini De Mello. QUEEN: QUantized efficient ENcoding for streaming free-viewpoint videos. InNeurIPS, 2024. 3
2024
-
[9]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Mar- tin, Tushar Nagarajan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, Chen Zhao, Siddhant Bansal, Dhruv Batra, Vincent Car...
2022
-
[10]
Human Mesh Reconstruction of Sports Players with Multiple Dy- namic Cameras
Yamato Hokari, Ryosuke Hori, and Hideo Saito. Human Mesh Reconstruction of Sports Players with Multiple Dy- namic Cameras. InCVPRW, pages 6039–6049, 2025. 3
2025
-
[11]
4DGC: Rate-Aware 4D Gaussian Compression for Efficient Streamable Free-Viewpoint Video
Qiang Hu, Zihan Zheng, Houqiang Zhong, Sihua Fu, Li Song, Xiaoyun Zhang, Guangtao Zhai, and Yanfeng Wang. 4DGC: Rate-Aware 4D Gaussian Compression for Efficient Streamable Free-Viewpoint Video. InCVPR, pages 875– 885, 2025. 3
2025
-
[12]
Depthcrafter: Generating consistent long depth sequences for open-world videos
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan. Depthcrafter: Generating consistent long depth sequences for open-world videos. InCVPR, 2025. 4
2025
-
[13]
SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes
Yi-Hua Huang, Yang-Tian Sun, Ziyi Yang, Xiaoyang Lyu, Yan-Pei Cao, and Xiaojuan Qi. SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes. InCVPR, pages 4220–4230, 2024. 3
2024
-
[14]
Wil- davatar: Learning in-the-wild 3d avatars from the web
Zihao Huang, Shoukang Hu, Guangcong Wang, Tianqi Liu, Yuhang Zang, Zhiguo Cao, Wei Li, and Ziwei Liu. Wil- davatar: Learning in-the-wild 3d avatars from the web. In CVPR, 2025. 3
2025
-
[15]
Geo4D: Leveraging Video Generators for Geometric 4D Scene Reconstruction
Zeren Jiang, Chuanxia Zheng, Iro Laina, Diane Larlus, and Andrea Vedaldi. Geo4D: Leveraging Video Generators for Geometric 4D Scene Reconstruction. InICCV, pages 20658–20671, 2025. 3
2025
-
[16]
Motion-x: A large- scale 3d expressive whole-body human motion dataset
Lin Jing, Ailing Zeng, Shunlin Lu, Yuanhao Cai, Ruimao Zhang, Haoqian Wang, and Lei Zhang. Motion-x: A large- scale 3d expressive whole-body human motion dataset. In NeurIPS, 2023. 3
2023
-
[17]
Panoptic studio: A massively multiview system for social motion capture
Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, , and Yaser Sheikh. Panoptic studio: A massively multiview system for social motion capture. InICCV, 2015. 3
2015
-
[18]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023. 2, 3, 5, 6
2023
-
[19]
A hierarchical 3d gaussian representation for real-time ren- dering of very large datasets.ACM Transactions on Graph- ics, 43(4), 2024
Bernhard Kerbl, Andreas Meuleman, Georgios Kopanas, Michael Wimmer, Alexandre Lanvin, and George Drettakis. A hierarchical 3d gaussian representation for real-time ren- dering of very large datasets.ACM Transactions on Graph- ics, 43(4), 2024. 1
2024
-
[20]
Mosca: Dynamic gaussian fusion from casual videos via 4d motion scaffolds
Jiahui Lei, Yijia Weng, Adam Harley, Leonidas Guibas, and Kostas Daniilidis. Mosca: Dynamic gaussian fusion from casual videos via 4d motion scaffolds. InCVPR, pages 6165– 6177, 2025. 1, 2, 3, 4, 5, 6
2025
-
[21]
Ground- ing Image Matching in 3D with MASt3R
Vincent Leroy, Yohann Cabon, and Jerome Revaud. Ground- ing Image Matching in 3D with MASt3R. InECCV, 2024. 2, 4
2024
-
[22]
Gifstream: 4d gaussian-based immersive video with feature stream
Hao Li, Sicheng Li, Xiang Gao, Abudouaihati Batuer, Lu Yu, and Yiyi Liao. Gifstream: 4d gaussian-based immersive video with feature stream. InCVPR, pages 21761–21770,
-
[23]
Streaming radiance fields for 3d video synthesis
Lingzhi Li, Zhen Shen, Zhongshu Wang, Li Shen, and Ping Tan. Streaming radiance fields for 3d video synthesis. In NeurIPS, 2022
2022
-
[24]
Neural 3d video synthesis from multi- view video
Tianye Li, Mira Slavcheva, Michael Zollhoefer, Simon Green, Christoph Lassner, Changil Kim, Tanner Schmidt, Steven Lovegrove1 Michael Goesele, Richard Newcombe, and Zhaoyang Lv. Neural 3d video synthesis from multi- view video. InCVPR, 2022. 3, 1
2022
-
[25]
Geometry-consistent 4d gaussian splatting for sparse-input dynamic view synthesis
Yiwei Li, Jiannong Cao, Penghui Ruan, Divya Saxena, Songye Zhu, and Yinfeng Cao. Geometry-consistent 4d gaussian splatting for sparse-input dynamic view synthesis. arXiv preprint arXiv:2511.23044, 2025. 5
arXiv 2025
-
[26]
Neural scene flow fields for space-time view synthesis of dy- namic scenes
Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dy- namic scenes. InCVPR, 2021. 3, 1
2021
-
[27]
Spacetime gaus- sian feature splatting for real-time dynamic view synthesis
Zhan Li, Zhang Chen, Zhong Li, and Yi Xu. Spacetime gaus- sian feature splatting for real-time dynamic view synthesis. InCVPR, pages 8508–8520, 2024. 3
2024
-
[28]
Hanxue Liang, Jiawei Ren, Ashkan Mirzaei, Antonio Tor- ralba, Ziwei Liu, Igor Gilitschenski, Sanja Fidler, Cengiz Oztireli, Huan Ling, Zan Gojcic, and Jiahui Huang. Feed- Forward Bullet-Time Reconstruction of Dynamic Scenes from Monocular Videos.arXiv preprint arXiv:2412.03526,
-
[29]
HiMoR: Monocular deformable gaussian reconstruction with hierar- chical motion representation
Yiming Liang, Tianhan Xu, and Yuta Kikuchi. HiMoR: Monocular deformable gaussian reconstruction with hierar- chical motion representation. InCVPR, 2025. 2, 3, 6
2025
-
[30]
MoVieS: Motion-Aware 4D Dynamic View Synthesis in One Second
Chenguo Lin, Yuchen Lin, Panwang Pan, Yifan Yu, Hon- glei Yan, Katerina Fragkiadaki, and Yadong Mu. MoVieS: Motion-Aware 4D Dynamic View Synthesis in One Second. arXiv preprint arXiv:2507.10065, 2025. 3
arXiv 2025
-
[31]
Efficient neural radiance fields for interactive free-viewpoint video
Haotong Lin, Sida Peng, Zhen Xu, Yunzhi Yan, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Efficient neural radiance fields for interactive free-viewpoint video. InSIGGRAPH Asia, 2022. 3
2022
-
[32]
Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: recovering the visual space from any views. arXiv preprint arXiv:2511.10647, 2025. 2, 3, 4, 5
Pith/arXiv arXiv 2025
-
[33]
Mufan Liu, Qi Yang, Miaoran Zhao, He Huang, Le Yang, Zhu Li, and Yiling Xu. D2GV: Deformable 2D Gaus- sian Splatting for Video Representation in 400FPS.arXiv preprint arXiv:2503.05600, 2025. 3
arXiv 2025
-
[34]
MoDGS: Dy- namic gaussian splatting from casually-captured monocular videos with depth priors
Qingming LIU, Yuan Liu, Jiepeng Wang, Xianqiang Lyu, Peng Wang, Wenping Wang, and Junhui Hou. MoDGS: Dy- namic gaussian splatting from casually-captured monocular videos with depth priors. InThe Thirteenth International Conference on Learning Representations, 2025. 3, 5
2025
-
[35]
3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthe- sis
Zhicheng Lu, Xiang Guo, Le Hui, Tianrui Chen, Ming Yang, Xiao Tang, Feng Zhu, and Yuchao Dai. 3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthe- sis. InCVPR, 2024. 3
2024
-
[36]
Dynamic 3D Gaussians: Tracking by Per- sistent Dynamic View Synthesis
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3D Gaussians: Tracking by Per- sistent Dynamic View Synthesis. In3DV, 2024. 3
2024
-
[37]
4DTAM: Non-Rigid Tracking and Mapping via Dynamic Surface Gaussians
Hidenobu Matsuki, Gwangbin Bae, and Andrew Davison. 4DTAM: Non-Rigid Tracking and Mapping via Dynamic Surface Gaussians. InCVPR, 2025. 3
2025
-
[38]
SplatFields: Neural gaussian splats for sparse 3d and 4d re- construction
Marko Mihajlovic, Sergey Prokudin, Siyu Tang, Robert Maier, Federica Bogo, Tony Tung, and Edmond Boyer. SplatFields: Neural gaussian splats for sparse 3d and 4d re- construction. InECCV. Springer, 2024. 3
2024
-
[39]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis. InECCV, 2020. 2
2020
-
[40]
Mustafa, H
A. Mustafa, H. Kim, J-Y . Guillemaut, and A. Hilton. Tempo- rally coherent 4d reconstruction of complex dynamic scenes. InCVPR, 2016. 3
2016
-
[41]
Nikita Karaev and Iurii Makarov and Jianyuan Wang and Na- talia Neverova and Andrea Vedaldi and Christian Rupprecht. CoTracker3: Simpler and Better Point Tracking by Pseudo- Labelling Real Videos.arXiv preprint arXiv:2410.11831,
-
[42]
UniDepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. UniDepth: Universal monocular metric depth estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 4
2024
-
[43]
Shape of motion: 4d reconstruc- tion from a single video
Wang Qianqian, Vickie Ye, Hang Gao, Jake Austin, Zhengqi Li, and Angjoo Kanazawa. Shape of motion: 4d reconstruc- tion from a single video. InICCV, 2025. 2, 3, 5
2025
-
[44]
Multi-view 3d point tracking
Frano Raji ˇc, Haofei Xu, Marko Mihajlovic, Siyuan Li, Irem Demir, Emircan G¨undo˘gdu, Lei Ke, Sergey Prokudin, Marc Pollefeys, and Siyu Tang. Multi-view 3d point tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 2, 3, 4, 6
2025
-
[45]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. In ICLR, 2025. 2, 5, 1
2025
-
[46]
L4GM: Large 4D Gaussian Reconstruction Model
Jiawei Ren, Kevin Xie, Ashkan Mirzaei, Hanxue Liang, Xi- aohui Zeng, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung Wook Kim, and Huan Ling. L4GM: Large 4D Gaussian Reconstruction Model. InNeurIPS,
-
[47]
Grounded sam: Assembling open-world models for diverse visual tasks,
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kun- chang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for diverse visual tasks,
-
[48]
Fouhey, and Chen-Hsuan Lin
Chris Rockwell, Joseph Tung, Tsung-Yi Lin, Ming-Yu Liu, David F. Fouhey, and Chen-Hsuan Lin. Dynamic camera poses and where to find them. InCVPR, 2025. 3
2025
-
[49]
Dataset and pipeline for multi-view light-field video
Neus Sabater, Guillaume Boisson, Benoit Vandame, Paul Kerbiriou, Frederic Babon, Matthieu Hog, Tristan Langlois, Remy Gendrot, Olivier Bureller, Arno Schubert, and Valerie Allie. Dataset and pipeline for multi-view light-field video. InCVPRW, 2017. 3
2017
-
[50]
Structure-from-motion revisited
Johannes Lutz Sch ¨onberger and Jan-Michael Frahm. Structure-from-motion revisited. InCVPR, pages 4104– 4113, 2016. 5, 1
2016
-
[51]
Gim: Learning generalizable image matcher from internet videos
Xuelun Shen, Zhipeng Cai, Wei Yin, Matthias M ¨uller, Zijun Li, Kaixuan Wang, Xiaozhi Chen, and Cheng Wang. Gim: Learning generalizable image matcher from internet videos. InICLR, 2024. 2, 4
2024
-
[52]
SONY.α7S III.https://www.sony.jp/ichigan/ products/ILCE-7SM3/, 2025. 1
2025
-
[53]
FX3.https://www.sony.jp/pro- cam/ products/ILME-FX3A/, 2025
SONY. FX3.https://www.sony.jp/pro- cam/ products/ILME-FX3A/, 2025. 1
2025
-
[54]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Et- tinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in percepti...
2020
-
[55]
Splatter a Video: Video Gaussian Representation for Versatile Processing
Yang-Tian Sun, Yi-Hua Huang, Lin Ma, Xiaoyang Lyu, Yan- Pei Cao, and Xiaojuan Qi. Splatter a Video: Video Gaussian Representation for Versatile Processing. InNeurIPS, pages 50401–50425, 2024. 3
2024
-
[56]
Recovering accurate 3d human pose in the wild using imus and a moving camera
Timo von Marcard, Roberto Henschel, Michael Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering accurate 3d human pose in the wild using imus and a moving camera. In ECCV, 2018. 3
2018
-
[57]
Freeman: Towards benchmarking 3d human pose estimation under real-world conditions
Jiong Wang, Fengyu Yang, Bingliang Li, Wenbo Gou, Danqi Yan, Ailing Zeng, Yijun Gao, Junle Wang, Yanqing Jing, and Ruimao Zhang. Freeman: Towards benchmarking 3d human pose estimation under real-world conditions. InCVPR, 2024. 3
2024
-
[58]
Yiming Wang, Lucy Chai, Xuan Luo, Michael Niemeyer, Manuel Lagunas, Stephen Lombardi, Siyu Tang, and Tiancheng Sun. SplatV oxel: History-Aware Novel View Streaming without Temporal Training.arXiv preprint arXiv:2503.14698, 2025. 3
arXiv 2025
-
[59]
FreeTimeGS: Free Gaussian Primitives at Anytime Anywhere for Dynamic Scene Reconstruction
Yifan Wang, Peishan Yang, Zhen Xu, Jiaming Sun, Zhan- hua Zhang, Yong Chen, Hujun Bao, Sida Peng, and Xiaowei Zhou. FreeTimeGS: Free Gaussian Primitives at Anytime Anywhere for Dynamic Scene Reconstruction. InCVPR,
-
[60]
Monofusion: Sparse-view 4d reconstruction via monocular fusion
Zihan Wang, Jeff Tan, Tarasha Khurana, Neehar Peri, and Deva Ramanan. Monofusion: Sparse-view 4d reconstruction via monocular fusion. InICCV, 2025. 5
2025
-
[61]
4D-Fly: Fast 4D Recon- struction from a Single Monocular Video
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, Yue Qian, Xi- aohang Zhan, and Yueqi Duan. 4D-Fly: Fast 4D Recon- struction from a Single Monocular Video. InCVPR, pages 16663–16673, 2025. 3
2025
-
[62]
4D Gaussian Splatting for Real-Time Dynamic Scene Ren- dering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4D Gaussian Splatting for Real-Time Dynamic Scene Ren- dering. InCVPR, pages 20310–20320, 2024. 3, 5
2024
-
[63]
Spatialtracker: Tracking any 2d pixels in 3d space
Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, and Xiaowei Zhou. Spatialtracker: Tracking any 2d pixels in 3d space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 4
2024
-
[64]
Mitracker: Multi-view integration for visual object tracking
Mengjie Xu, Yitao Zhu, Haotian Jiang, Jiaming Li, Zhen- rong Shen, Sheng Wang, Haolin Huang, Xinyu Wang, Qing Yang, Han Zhang, and Qian Wang. Mitracker: Multi-view integration for visual object tracking. InCVPR, 2025. 3
2025
-
[65]
Representing long volumet- ric video with temporal gaussian hierarchy.ACM TOG, 43 (6):1–18, 2024
Zhen Xu, Yinghao Xu, Zhiyuan Yu, Sida Peng, Jiaming Sun, Hujun Bao, and Xiaowei Zhou. Representing long volumet- ric video with temporal gaussian hierarchy.ACM TOG, 43 (6):1–18, 2024. 3
2024
-
[66]
In- stant Gaussian Stream: Fast and Generalizable Streaming of Dynamic Scene Reconstruction via Gaussian Splatting
Jinbo Yan, Rui Peng, Zhiyan Wang, Luyang Tang, Jiayu Yang, Jie Liang, Jiahao Wu, and Ronggang Wang. In- stant Gaussian Stream: Fast and Generalizable Streaming of Dynamic Scene Reconstruction via Gaussian Splatting. In CVPR, pages 16520–16531, 2025. 3
2025
-
[67]
Depth any- thing v2.arXiv:2406.09414, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.arXiv:2406.09414, 2024. 4
Pith/arXiv arXiv 2024
-
[68]
Deformable 3d gaussians for high- fidelity monocular dynamic scene reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high- fidelity monocular dynamic scene reconstruction. InCVPR, pages 20331–20341, 2024. 1, 3, 5, 6
2024
-
[69]
4d gaussian splatting: Modeling dynamic scenes with native 4d primitives.arXiv preprint, 2024
Zeyu Yang, Zijie Pan, Xiatian Zhu, Li Zhang, Jianfeng Feng, Yu-Gang Jiang, and Philip HS Torr. 4d gaussian splatting: Modeling dynamic scenes with native 4d primitives.arXiv preprint, 2024. 3
2024
-
[70]
Real- time Photorealistic Dynamic Scene Representation and Ren- dering with 4D Gaussian Splatting
Zeyu Yang, Hongye Yang, Zijie Pan, and Li Zhang. Real- time Photorealistic Dynamic Scene Representation and Ren- dering with 4D Gaussian Splatting. InICLR, 2024. 3
2024
-
[71]
Imvid: Immersive volumetric videos for en- hanced vr engagement
Zhengxian Yang, Shi Pan, Shengqi Wang, Haoxiang Wang, Li Lin, Guanjun Li, Zhengqi Wen, Borong Lin, Jianhua Tao, and Tao Yu. Imvid: Immersive volumetric videos for en- hanced vr engagement. InCVPR, 2025. 3, 1
2025
-
[72]
SplineGS: Learning smooth trajectories in gaussian splatting for dynamic scene reconstruction
Jihwan Yoon, Sangbeom Han, Jaeseok Oh, and Minsik Lee. SplineGS: Learning smooth trajectories in gaussian splatting for dynamic scene reconstruction. InICLR poster, 2025. 3
2025
-
[73]
Chao Zhang, Yifeng Zhou, Shuheng Wang, Wenfa Li, Degang Wang, Yi Xu, and Shaohui Jiao. EvolvingGS: High-Fidelity Streamable V olumetric Video via Evolving 3D Gaussian Representation.arXiv preprint arXiv:2503.05162,
-
[74]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. 6
2018
-
[75]
Zetong Zhang, Manuel Kaufmann, Lixin Xue, Jie Song, and Martin R. Oswald. ODHSR: Online Dense 3D Reconstruc- tion of Humans and Scenes from Monocular Videos. In CVPR, pages 21824–21835, 2025. 3
2025
-
[76]
GauSTAR: Gaussian Surface Tracking and Reconstruction
Chengwei Zheng, Lixin Xue, Juan Zarate, and Jie Song. GauSTAR: Gaussian Surface Tracking and Reconstruction. InCVPR, pages 16543–16553, 2025. 3
2025
-
[77]
GPS- Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis
Shunyuan Zheng, Boyao Zhou, Ruizhi Shao, Boning Liu, Shengping Zhang, Liqiang Nie, and Yebin Liu. GPS- Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis. InCVPR, 2024. 3 4D Reconstruction from Sparse Dynamic Cameras Supplementary Material
2024
-
[78]
Details of LetCamsGo 8.1. Data Acquisition LetCamsGo is captured using three independently moving cameras that follow the subjects during recording, mim- icking realistic handheld or operator-driven capture scenar- ios. We use two Sony FX3 cameras [53] and two Sony α7S III cameras [52], where three cameras act as dynamic cameras and oneα7S III serves as a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.