Improving the Efficiency and Effectiveness of LLM Knowledge Distillation for Conversational Search
Pith reviewed 2026-06-28 04:10 UTC · model grok-4.3
The pith
Adding contrastive loss and regularization to divergence-based distillation halves FLOPS in conversational search retrievers while keeping recall nearly intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By extending Kullback-Leibler divergence distillation with a contrastive loss and an explicit sparsity regularization term, the resulting model produces more precise rankings and markedly sparser document representations; these changes yield a 2 imes reduction in FLOPS on TopiOCQA while incurring no more than a 2% drop in Recall@100.
What carries the argument
Kullback-Leibler divergence distillation objective augmented by contrastive sampling and a sparsity regularization loss applied to learned sparse conversational retrievers.
If this is right
- Contrastive loss produces clear gains on precision-oriented ranking metrics.
- Contrastive sampling strategies exert a non-trivial effect on the divergence loss and require careful selection.
- Increasing the number of samples used for the divergence estimate yields diminishing returns.
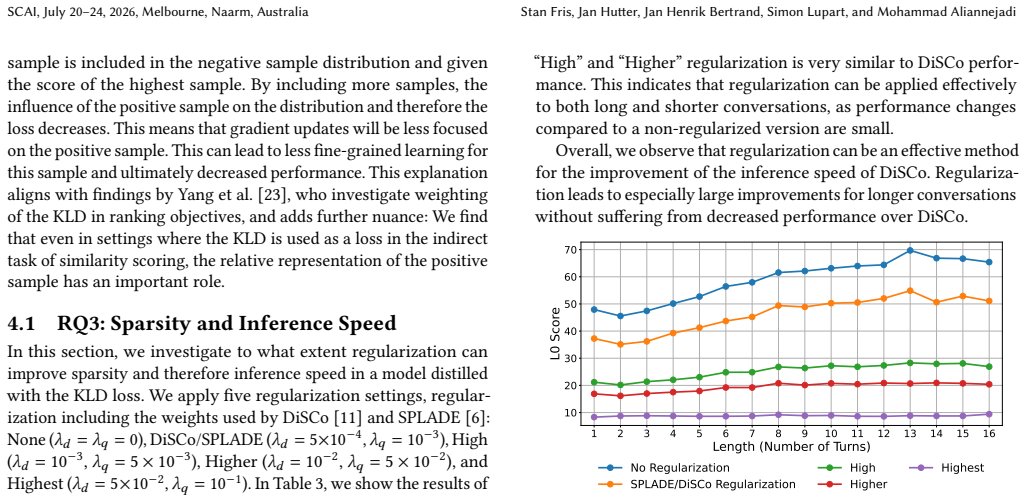
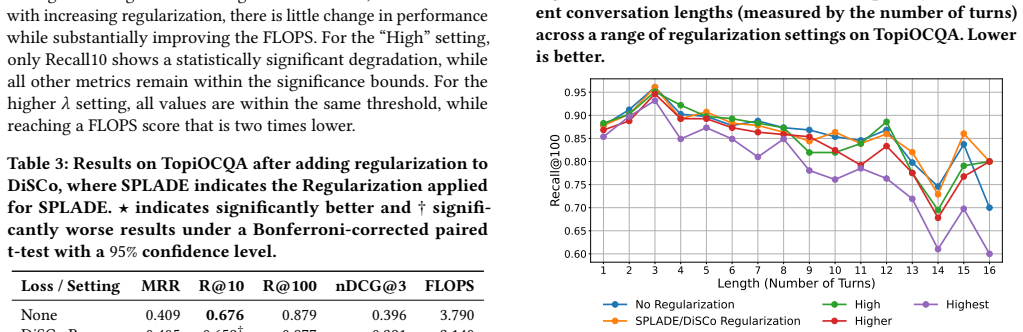
- Regularization restores sparsity in longer conversations and thereby improves inference speed without large effectiveness losses.
- The combined objective supplies practical guidelines for distilling effective and efficient first-stage conversational retrievers.
Where Pith is reading between the lines
- The same regularization approach could be tested on non-conversational retrieval tasks that also suffer from representation density growth.
- Sparser representations might enable faster index updates or lower memory footprints on edge devices.
- The contrastive component may interact differently when the teacher model itself changes size or training data.
- These distillation choices could be combined with post-training quantization to compound the efficiency benefit.
Load-bearing premise
The performance and efficiency gains from the added contrastive loss and regularization term will continue to appear on new datasets and with different hyperparameter settings or conversation lengths.
What would settle it
An experiment on a fresh conversational search collection in which the regularization term produces no measurable sparsity gain or in which the claimed FLOPS reduction is accompanied by more than a 2% drop in Recall@100.
Figures

read the original abstract
Conversational Search (CS) considers retrieval of relevant documents based on conversational context. Large Language Models (LLMs) have significantly enhanced CS by enabling effective query rewriting. However, employing LLMs during inference poses efficiency challenges. A method to balance effectiveness and efficiency is the use of knowledge distillation from LLM-based query rewriting. Recent work applies the Kullback-Leibler Divergence (KLD) for distillation, relaxing the alignment with the teacher signal compared to previous methods. Despite these gains, several aspects of KLD-based distillation for conversational search remain understudied, and we investigate them in this work. Prior work in related fields suggests that adding a contrastive loss to the KLD objective can improve performance; we confirm this and observe significant gains in precision-oriented ranking metrics. We also find that contrastive sampling strategies for the KLD loss have a non-trivial impact and must be chosen carefully. Although theory suggests that more samples improve the KLD estimate, experiments show diminishing returns on the number of used samples. Finally, we address the phenomenon of decreased sparsity in longer conversations, which limits computational efficiency across sparse retrieval methods. We find that the representations from the model distilled with the KLD loss can be strongly regularized with a regularization loss, substantially improving sparsity and inference efficiency without significantly harming retrieval effectiveness. We achieve a $2\times$ decrease in FLOPS on TopiOCQA with negligible loss in effectiveness, corresponding to a $\leq 2%$ drop in Recall@100. Our results provide insights into distillation objectives for learned sparse conversational retrievers and offer practical guidelines for improving effectiveness and efficiency in first-stage retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines KLD-based knowledge distillation from LLMs for query rewriting in conversational search. It reports that adding a contrastive loss yields gains on precision-oriented metrics, that contrastive sampling strategies have non-trivial effects, that additional samples show diminishing returns, and that a regularization loss substantially improves sparsity (yielding a 2× FLOPS reduction on TopiOCQA with ≤2% drop in Recall@100) while preserving effectiveness.
Significance. If the reported deltas hold under controlled conditions, the work supplies concrete, actionable guidelines for balancing effectiveness and efficiency in learned sparse retrievers for conversational search. The regularization result directly addresses the sparsity degradation observed in longer conversations and is therefore of immediate practical value to first-stage retrieval systems.
major comments (2)
- [§5.3, Table 6] §5.3 and Table 6: the 2× FLOPS reduction is presented as the central efficiency outcome, yet the section does not report an ablation on the regularization coefficient λ or a comparison against other sparsity-inducing regularizers (e.g., L1 or entropy-based); without these controls it is unclear whether the gain is attributable to the proposed term or to incidental training differences.
- [§4.2, Eq. (7)] §4.2, Eq. (7): the combined training objective is stated to include both KLD and contrastive terms, but the relative weighting hyper-parameter and its selection procedure are not described; this leaves open whether the reported precision gains are robust or specific to a narrow hyper-parameter regime.
minor comments (3)
- All tables should include standard deviations or confidence intervals across at least three random seeds to allow readers to judge stability of the reported deltas.
- [§3.1] The description of the TopiOCQA and other evaluation sets would benefit from an explicit table listing conversation length statistics and query-rewrite characteristics.
- [§2.2] Notation for the teacher and student output distributions in the KLD term should be introduced once with a single equation rather than repeated inline.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [§5.3, Table 6] §5.3 and Table 6: the 2× FLOPS reduction is presented as the central efficiency outcome, yet the section does not report an ablation on the regularization coefficient λ or a comparison against other sparsity-inducing regularizers (e.g., L1 or entropy-based); without these controls it is unclear whether the gain is attributable to the proposed term or to incidental training differences.
Authors: We agree that an ablation on λ and comparisons to alternatives such as L1 would strengthen the attribution of the sparsity gains. In the revised manuscript we will add both an ablation varying λ and a direct comparison against L1 regularization (and, space permitting, an entropy-based baseline) using the same training protocol to isolate the contribution of the proposed term. revision: yes
-
Referee: [§4.2, Eq. (7)] §4.2, Eq. (7): the combined training objective is stated to include both KLD and contrastive terms, but the relative weighting hyper-parameter and its selection procedure are not described; this leaves open whether the reported precision gains are robust or specific to a narrow hyper-parameter regime.
Authors: We acknowledge the omission. The relative weight between the KLD and contrastive terms was selected via grid search on a validation split of the training data; the chosen value and the search range will be reported in the revised Section 4.2 together with a brief sensitivity plot confirming that the precision gains remain stable across a reasonable interval around the selected weight. revision: yes
Circularity Check
No significant circularity; purely empirical study
full rationale
The paper reports experimental results on KLD-based distillation, contrastive loss additions, sampling strategies, and regularization for sparsity in conversational retrieval. No equations, derivations, or first-principles predictions are present that could reduce to inputs by construction. All performance claims (e.g., 2× FLOPS reduction on TopiOCQA with ≤2% Recall@100 drop) are direct empirical measurements, not fitted parameters renamed as predictions or justified via self-citation chains. The work is self-contained against external benchmarks and datasets.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions in machine learning about loss functions and optimization
Reference graph
Works this paper leans on
-
[1]
[n. d.]. TopiOCQA: Open-domain Conversational Question Answering with Topic Switching | Transactions of the Association for Computational Linguistics | MIT Press. https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00471/110550/ TopiOCQA-Open-domain-Conversational-Question
-
[2]
Negar Arabzadeh, Xinyi Yan, and Charles L. A. Clarke. 2021. Predicting Effi- ciency/Effectiveness Trade-offs for Dense vs. Sparse Retrieval Strategy Selection. doi:10.48550/arXiv.2109.10739 arXiv:2109.10739 [cs]
-
[3]
Ruey-Cheng Chen, Luke Gallagher, Roi Blanco, and J. Shane Culpepper. 2017. Efficient Cost-Aware Cascade Ranking in Multi-Stage Retrieval. InProceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, Shinjuku Tokyo Japan, 445–454. doi:10.1145/ 3077136.3080819
arXiv 2017
-
[5]
arXiv preprint arXiv:2109.10086(2021)
SPLADE v2: Sparse lexical and expansion model for information retrieval. arXiv preprint arXiv:2109.10086(2021)
arXiv 2021
-
[6]
Thibault Formal, Carlos Lassance, Benjamin Piwowarski, and Stéphane Clinchant
-
[7]
From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, Madrid Spain, 2353–2359. doi:10.1145/3477495.3531857
-
[8]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 2288–2292. doi:10.1145/3404835.3463098
-
[9]
Nam Le Hai, Thomas Gerald, Thibault Formal, Jian-Yun Nie, Benjamin Pi- wowarski, and Laure Soulier. 2024. CoSPLADE: Contextualizing SPLADE for Conversational Information Retrieval. doi:10.48550/arXiv.2301.04413 arXiv:2301.04413 [cs]
-
[10]
S. Kullback and R. A. Leibler. 1951. On Information and Sufficiency.The Annals of Mathematical Statistics22, 1 (March 1951), 79–86. doi:10.1214/aoms/1177729694 Publisher: Institute of Mathematical Statistics
-
[11]
Carlos Lassance and Stéphane Clinchant. 2022. An Efficiency Study for SPLADE Models. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, Madrid Spain, 2220–2226. doi:10. 1145/3477495.3531833
arXiv 2022
-
[12]
Carlos Lassance, Hervé Déjean, Thibault Formal, and Stéphane Clinchant. 2024. SPLADE-v3: New baselines for SPLADE.arXiv preprint arXiv:2403.06789(2024)
arXiv 2024
-
[13]
Simon Lupart, Mohammad Aliannejadi, and Evangelos Kanoulas. 2025. DiSCo: LLM Knowledge Distillation for Efficient Sparse Retrieval in Conversational Search. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, Padua Italy, 9–19. doi:10.1145/ 3726302.3729966
arXiv 2025
-
[14]
Kelong Mao, Hongjin Qian, Fengran Mo, Zhicheng Dou, Bang Liu, Xiaohua Cheng, and Zhao Cao. 2023. Learning Denoised and Interpretable Session Representation for Conversational Search. InProceedings of the ACM Web Conference 2023. ACM, Austin TX USA, 3193–3202. doi:10.1145/3543507.3583265
-
[15]
Irina Matveeva, Chris Burges, Timo Burkard, Andy Laucius, and Leon Wong
-
[16]
High accuracy retrieval with multiple nested ranker. InProceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, Seattle Washington USA, 437–444. doi:10.1145/ 1148170.1148246
-
[17]
Fengran Mo, Kelong Mao, Ziliang Zhao, Hongjin Qian, Haonan Chen, Yiruo Cheng, Xiaoxi Li, Yutao Zhu, Zhicheng Dou, and Jian-Yun Nie. 2025. A Survey of Conversational Search.ACM Transactions on Information Systems43, 6 (Nov. 2025), 1–50. doi:10.1145/3759453
-
[18]
Fengran Mo, Chen Qu, Kelong Mao, Yihong Wu, Zhan Su, Kaiyu Huang, and Jian-Yun Nie. 2024. Aligning Query Representation with Rewritten Query and Relevance Judgments in Conversational Search. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM ’24). Association for Computing Machinery, New York, NY, USA, 170...
arXiv 2024
-
[19]
Thong Nguyen, Sean MacAvaney, and Andrew Yates. 2023. A unified framework for learned sparse retrieval. InEuropean Conference on Information Retrieval. Springer, 101–116
2023
-
[20]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748(2018)
Pith/arXiv arXiv 2018
-
[21]
Biswajit Paria, Chih-Kuan Yeh, Ian EH Yen, Ning Xu, Pradeep Ravikumar, and Barnabás Póczos. 2020. Minimizing flops to learn efficient sparse representations. arXiv preprint arXiv:2004.05665(2020)
arXiv 2020
-
[22]
Surya T. Tokdar and Robert E. Kass. 2010. Importance sampling: a review. WIREs Computational Statistics2, 1 (2010), 54–60. doi:10.1002/wics.56 _eprint: https://wires.onlinelibrary.wiley.com/doi/pdf/10.1002/wics.56
-
[23]
Zeqiu Wu, Yi Luan, Hannah Rashkin, David Reitter, Hannaneh Hajishirzi, Mari Ostendorf, and Gaurav Singh Tomar. 2022. CONQRR: Conversational Query Rewriting for Retrieval with Reinforcement Learning. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association ...
-
[24]
Yan Xiao, Yixing Fan, Ruqing Zhang, and Jiafeng Guo. 2023. Beyond Precision: A Study on Recall of Initial Retrieval with Neural Representations. InInformation Retrieval, Yi Chang and Xiaofei Zhu (Eds.). Springer Nature Switzerland, Cham, 76–89. doi:10.1007/978-3-031-24755-2_7
-
[25]
Yingrui Yang, Shanxiu He, Yifan Qiao, Wentai Xie, and Tao Yang. 2023. Balanced Knowledge Distillation with Contrastive Learning for Document Re-ranking. In Proceedings of the 2023 ACM SIGIR International Conference on Theory of Informa- tion Retrieval (ICTIR ’23). Association for Computing Machinery, New York, NY, USA, 247–255. doi:10.1145/3578337.3605120
-
[26]
Yingrui Yang, Shanxiu He, and Tao Yang. 2024. On Adaptive Knowledge Distilla- tion with Generalized KL-Divergence Loss for Ranking Model Refinement. In Proceedings of the 2024 ACM SIGIR International Conference on Theory of Informa- tion Retrieval. ACM, Washington DC USA, 81–90. doi:10.1145/3664190.3672522
-
[27]
Shi Yu, Zhenghao Liu, Chenyan Xiong, Tao Feng, and Zhiyuan Liu. 2021. Few- Shot Conversational Dense Retrieval. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, Virtual Event Canada, 829–838. doi:10.1145/3404835.3462856
-
[28]
Bruce Croft, Erik Learned-Miller, and Jaap Kamps
Hamed Zamani, Mostafa Dehghani, W. Bruce Croft, Erik Learned-Miller, and Jaap Kamps. 2018. From Neural Re-Ranking to Neural Ranking: Learning a Sparse Representation for Inverted Indexing. InProceedings of the 27th ACM International Conference on Information and Knowledge Management(Torino, Italy)(CIKM ’18). Association for Computing Machinery, New York, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.