LifeSide: Benchmarking Agents as Lifelong Digital Companions
Pith reviewed 2026-06-28 06:40 UTC · model grok-4.3
The pith
Even models that saturate current memory benchmarks fail to sustain accurate user understanding and true companionship over long horizons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
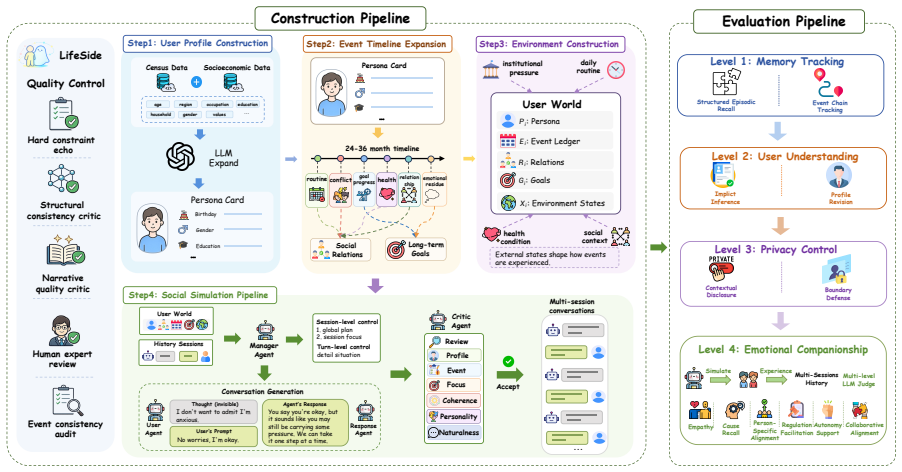
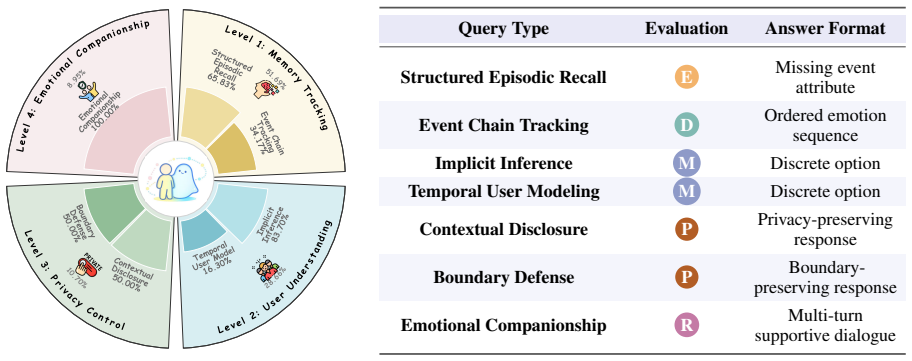
LifeSide models users as persistent worlds with layered profiles and event trajectories. It employs multi-agent simulation to project environmental dynamics into dialogue while preserving the gap between latent thoughts and observable expressions. Across evaluations of memory tracking, user understanding, privacy control, and emotional companionship on 2,000 personas and 111K tasks, the benchmark reveals that models saturating existing memory tests cannot maintain accurate understanding or true companionship over long horizons.
What carries the argument
Multi-agent simulation of Memory-Emotion-Environment loops that projects environmental dynamics into observable dialogue while keeping latent user thoughts separate from expressed behavior, evaluated on 2,000 personas and 111K tasks.
If this is right
- Agents need explicit mechanisms to carry user models across separate sessions rather than relying on short-term context.
- Evaluation of digital companions must include privacy boundary shifts and emotional continuity as joint requirements over extended periods.
- Models that excel only at isolated recall tasks are insufficient for roles demanding persistent personal relationships.
- Benchmark design should prioritize the separation between what users reveal and what they keep private when testing long-horizon performance.
Where Pith is reading between the lines
- Architectures that maintain an internal persistent state for each user might address the gaps the benchmark exposes.
- Deploying the same models in actual chat applications over months could test whether the simulation's projected failures match real outcomes.
- The benchmark's focus on unobserved user thoughts suggests companions may need stronger inference abilities beyond surface-level responses.
- Similar simulation methods could be applied to other long-term agent domains such as personal health assistants.
Load-bearing premise
The multi-agent simulation accurately reflects how real users behave and change over time, and the generated tasks correctly measure what lifelong companionship requires.
What would settle it
A model that scores poorly on the LifeSide tasks but maintains accurate user understanding and companionship across many real multi-session conversations with actual users would challenge whether the benchmark captures the claimed failures.
Figures
















read the original abstract
Lifelong digital companions must integrate cross-session cues, continually update their understanding of users, and adapt to shifting privacy boundaries. Existing evaluations fail to capture this, testing memory recall and short-term empathy in isolation. To bridge this gap, we introduce \benchmark, a benchmark centered on multi-session \textit{Memory-Emotion-Environment} loops. By modeling users as persistent worlds with layered profiles and event trajectories, \benchmark uses multi-agent simulation to project environmental dynamics into dialogue, preserving the critical gap between latent thoughts and observable expressions. Evaluating 2,000 personas and 111K tasks across memory tracking, user understanding, privacy control, and emotional companionship, our experiment results reveal a stark reality: even models that saturate current memory benchmarks fail to sustain accurate user understanding and true companionship over long horizons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LifeSide, a benchmark for lifelong digital companions that employs multi-agent simulation of Memory-Emotion-Environment loops to generate tasks across 2,000 personas and 111K instances. It evaluates models on memory tracking, user understanding, privacy control, and emotional companionship, claiming that even models saturating existing memory benchmarks fail to sustain accurate user understanding and true companionship over long horizons.
Significance. If the simulation framework is shown to faithfully capture latent user states, observable dialogue gaps, and shifting privacy boundaries, the results would establish a meaningful capability gap beyond short-term memory tests and motivate new work on persistent, adaptive agents.
major comments (3)
- [Abstract / Simulation Framework] The central claim that model failures reflect a general gap in lifelong companionship (rather than simulation artifacts) rests on the multi-agent simulation accurately projecting event trajectories while preserving unobservable states. No external validation, human judgment of trajectory realism, or comparison against real user data is described to support this.
- [Evaluation Setup] The construction of the 2,000 personas (layered profiles, event trajectories) and the sampling/generation process yielding exactly 111K tasks is not specified in sufficient detail to evaluate whether the resulting test distribution avoids systematic biases such as overly consistent personas or unrealistic event chaining.
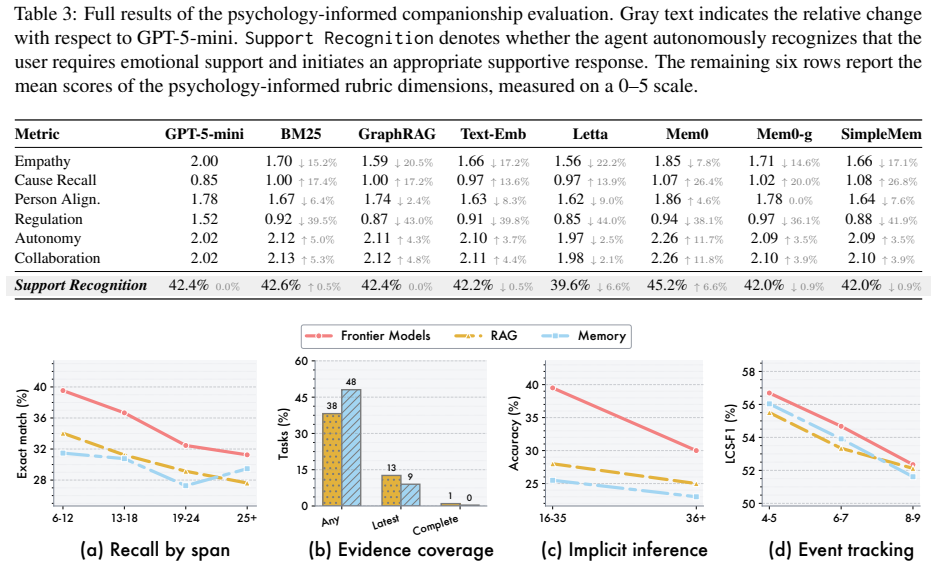
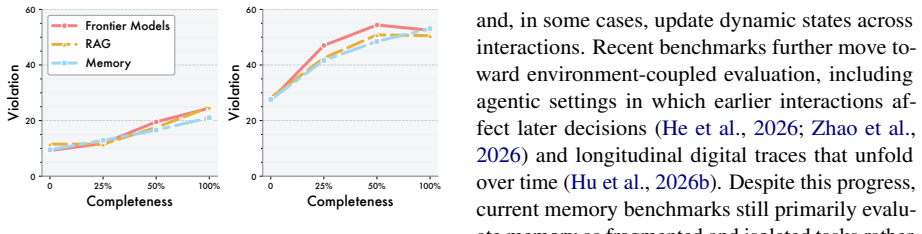
- [Results / Experiments] The paper asserts that the benchmark reveals failures on long-horizon tasks even for models saturating prior memory benchmarks, yet provides no quantitative breakdown (e.g., per-capability scores, horizon-length curves, or statistical significance) that would allow readers to assess the magnitude or robustness of the reported gap.
minor comments (2)
- [Abstract] The placeholder '\benchmark' should be replaced with the actual benchmark name for consistency.
- [Benchmark Design] Clarify the precise definitions and operationalizations of the four evaluation axes (memory tracking, user understanding, privacy control, emotional companionship) with explicit task examples or rubrics.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications grounded in the paper's design choices while committing to revisions that add detail where feasible. Our responses focus on substance and aim to strengthen the presentation of the benchmark without overstating its scope.
read point-by-point responses
-
Referee: [Abstract / Simulation Framework] The central claim that model failures reflect a general gap in lifelong companionship (rather than simulation artifacts) rests on the multi-agent simulation accurately projecting event trajectories while preserving unobservable states. No external validation, human judgment of trajectory realism, or comparison against real user data is described to support this.
Authors: LifeSide is intentionally a controlled synthetic benchmark that separates latent user states from observable dialogue to isolate lifelong companionship capabilities in a reproducible way. The multi-agent simulation draws on established agent-based modeling principles to generate trajectories while enforcing the latent-observable gap; this design enables precise measurement of failures that short-term memory tests miss. We agree that the manuscript would benefit from expanded discussion of these design principles and their limitations. We will add a dedicated subsection on simulation rationale and trade-offs in the revised version, but note that direct real-user validation lies outside the current scope. revision: partial
-
Referee: [Evaluation Setup] The construction of the 2,000 personas (layered profiles, event trajectories) and the sampling/generation process yielding exactly 111K tasks is not specified in sufficient detail to evaluate whether the resulting test distribution avoids systematic biases such as overly consistent personas or unrealistic event chaining.
Authors: Section 3 details the persona generation process, which samples layered attributes (demographics, Big-Five personality, preferences) from empirical distributions and generates event trajectories via a state-conditioned Markov process. The 111K tasks are produced by exhaustive sampling across the four capability axes and controlled horizon lengths. To address concerns about transparency and bias, we will include pseudocode for the generation pipeline, quantitative diversity statistics (attribute entropy, event-chain variability), and bias-mitigation steps in an expanded methods section. revision: yes
-
Referee: [Results / Experiments] The paper asserts that the benchmark reveals failures on long-horizon tasks even for models saturating prior memory benchmarks, yet provides no quantitative breakdown (e.g., per-capability scores, horizon-length curves, or statistical significance) that would allow readers to assess the magnitude or robustness of the reported gap.
Authors: Section 4 reports aggregate scores showing degradation relative to memory-saturating baselines. We concur that finer-grained analysis would improve interpretability and will add per-capability tables, performance curves as a function of session horizon, and statistical tests (ANOVA and post-hoc comparisons) to the results section and appendix in the revision. revision: yes
- External validation of simulation trajectories against real user data or large-scale human realism judgments, which was not performed.
Circularity Check
No circularity: new benchmark defines independent evaluation criteria
full rationale
The paper introduces LifeSide as a novel benchmark constructed via multi-agent simulation of Memory-Emotion-Environment loops across 2000 personas and 111K tasks. No load-bearing steps reduce by construction to fitted parameters, self-citations, or prior results; the central claim (models saturating short-term memory benchmarks fail on long-horizon companionship) is an empirical observation on the newly defined tasks rather than a self-referential derivation. The simulation framework and evaluation dimensions are presented as original contributions without equations or uniqueness theorems that collapse to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-agent simulation can faithfully project environmental dynamics into dialogue while preserving the gap between latent user thoughts and observable expressions.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2602.01885
Es-memeval: Benchmarking conversational agents on personalized long-term emotional support. arXiv preprint arXiv:2602.01885. Yi Cheng, Wenge Liu, Wenjie Li, Jiashuo Wang, Ruihui Zhao, Bang Liu, Xiaodan Liang, and Yefeng Zheng
-
[2]
Improving multi-turn emotional support dia- logue generation with lookahead strategy planning. InProceedings of the 2022 Conference on Empiri- cal Methods in Natural Language Processing, pages 3014–3026. Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building production-ready ai agents with scalable long-term mem...
Pith/arXiv arXiv 2022
-
[3]
Knowledge-enhanced mixed-initiative dia- logue system for emotional support conversations. InProceedings of the 61st annual meeting of the as- sociation for computational linguistics (volume 1: Long papers), pages 4079–4095. Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ne...
Pith/arXiv arXiv 2024
-
[4]
Heart: A unified benchmark for assessing hu- mans and llms in emotional support dialogue.arXiv preprint arXiv:2601.19922. Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, and 1 others. 2025. Personamem-v2: Towards personalized intelligence via learning implicit user personas ...
arXiv 2025
-
[5]
InInternational Conference on Machine Learning
Simplemem: Efficient lifelong memory for llm agents. InInternational Conference on Machine Learning. PMLR. Siyang Liu, Chujie Zheng, Orianna Demasi, Sahand Sabour, Yu Li, Zhou Yu, Yong Jiang, and Minlie Huang. 2021. Towards emotional support dialog systems. InProceedings of the 59th annual meeting of the association for computational linguistics and the 1...
2021
-
[6]
Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. Walter Mischel and Yuichi Shoda. 1995. A cognitive- affective system theory of personality: reconceptual- izing situations, dispositions, dynamics, and invari-...
arXiv 1995
-
[7]
Zhonghua Zheng, Lizi Liao, Yang Deng, Libo Qin, and Liqiang Nie
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Zhonghua Zheng, Lizi Liao, Yang Deng, Libo Qin, and Liqiang Nie. 2024. Self-chats from large language models make small emotional support chatbot better. InProceedings of the 62nd Annual Meeting of the Association for Computational L...
2024
-
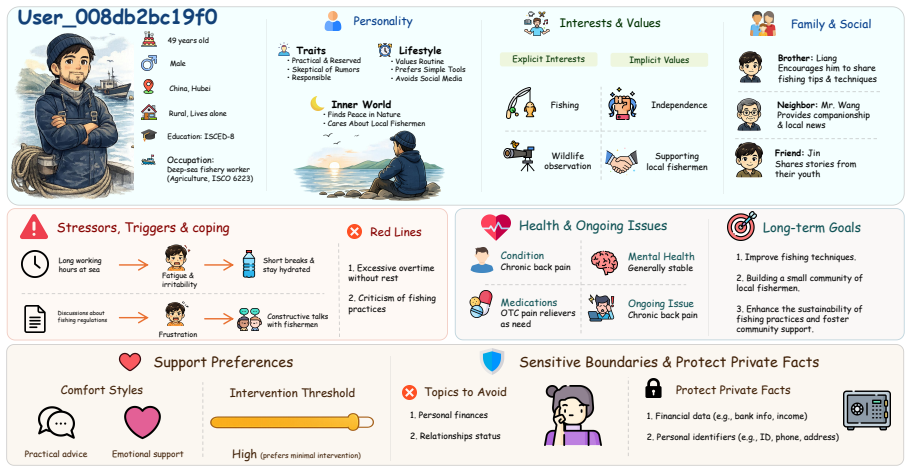
[8]
Excessive overtime without rest
-
[9]
Criticism of fishing practices Health & Ongoing Issues Condition Chronic back pain Medications OTC pain relievers as need Mental Health Generally stable Ongoing Issue Chronic back pain Long-term Goals
-
[10]
Improve fishing techniques
-
[11]
Building a small community of local fishermen
-
[12]
Enhance the sustainability of fishing practices and foster community support. Support Preferences Comfort Styles Practical advice Emotional support Intervention Threshold High (prefers minimal intervention) Sensitive Boundaries & Protect Private Facts Topics to Avoid
-
[13]
Relationships status Protect Private Facts
-
[14]
Financial data (e.g., bank info, income)
-
[15]
I used to spend most nights alone, but lately I think I should try engaging more with neighbors
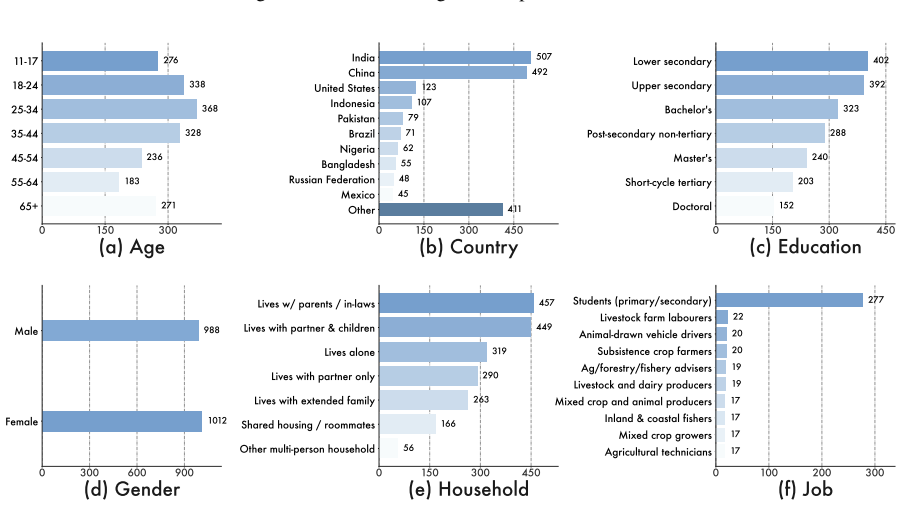
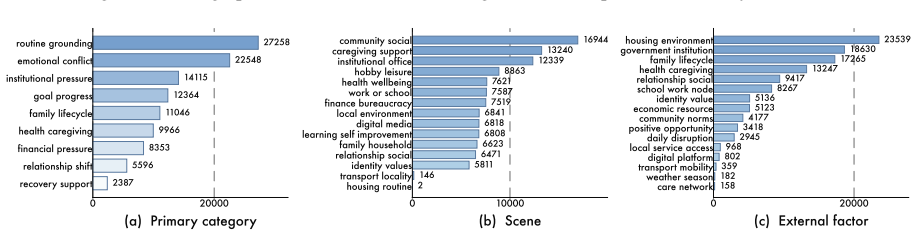
Personal identifiers (e.g., ID, phone, address) Figure 6: Overview of a generated persona structure. 0 150 300 11-17 18-24 25-34 35-44 45-54 55-64 65+ 276 338 368 328 236 183 271 (a) Age 0 150 300 450 India China United States Indonesia Pakistan Brazil Nigeria Bangladesh Russian Federation Mexico Other 507 492 123 107 79 71 62 55 48 45 411 (b) Country 0 1...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.