DuDi: Dual-Signal Distillation with Cross-Lingual Verbalizer
Pith reviewed 2026-06-28 06:30 UTC · model grok-4.3
The pith
DuDi combines sequence-level and token-level signals plus a cross-lingual verbalizer to improve distillation of multilingual capabilities into small language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
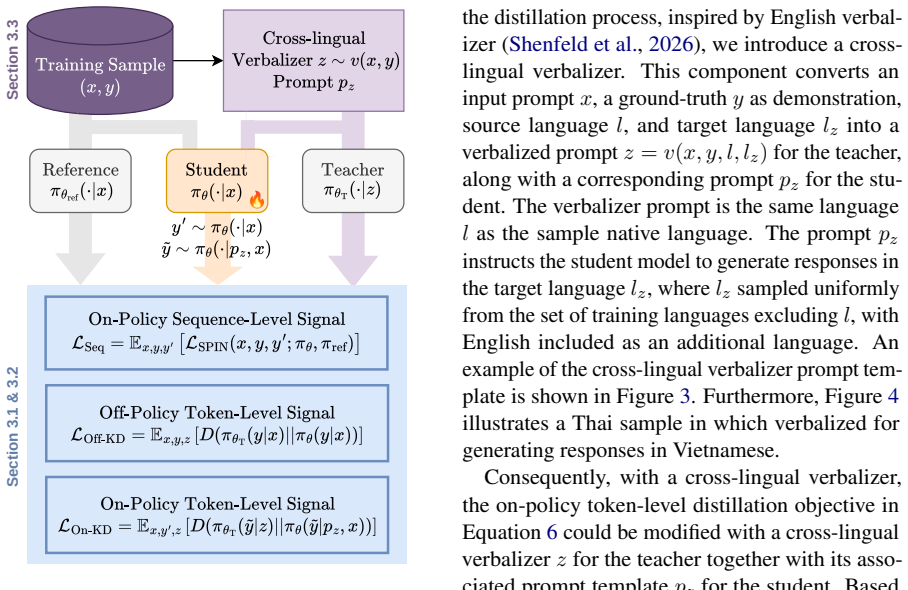
DuDi is a dual-signal multilingual distillation framework that integrates online sequence-level supervision with off-policy and on-policy token-level supervision and applies a cross-lingual verbalizer to refine teacher feedback, thereby improving teacher-student transferability for sub-billion-parameter models on Southeast Asian languages.
What carries the argument
DuDi dual-signal distillation framework: the mechanism that merges sequence-level and token-level signals while routing teacher feedback through a cross-lingual verbalizer to produce more transferable training targets.
If this is right
- Multilingual small language models can retain higher SEA-language accuracy after distillation when both sequence-level and token-level signals are used together.
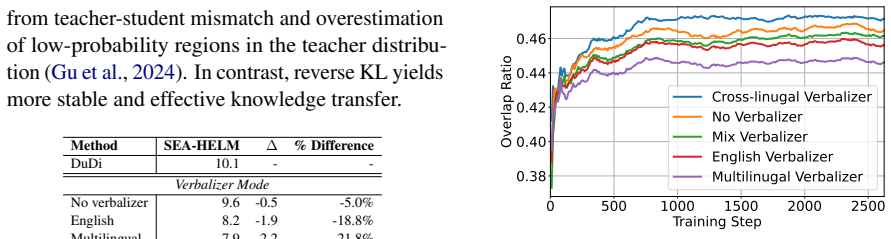
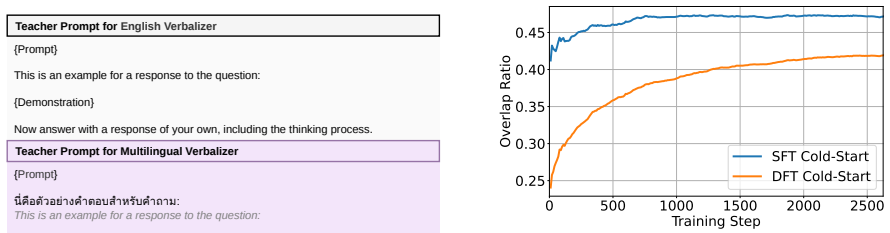
- Cross-lingual verbalization reduces the mismatch between teacher outputs and student language distributions.
- Ablation results indicate that removing any one of the three signals degrades performance relative to the full DuDi combination.
- The method scales across different model families and teacher-student size ratios.
Where Pith is reading between the lines
- The same dual-signal pattern could be tested on other low-resource language families beyond Southeast Asia.
- If the verbalizer is language-pair specific, its construction cost may limit application to very large numbers of languages.
- Token-level signals might be replaced by cheaper synthetic data sources while preserving most of the reported gain.
- Sequence-level optimization may interact with reinforcement-learning-style objectives that are already common in post-training.
Load-bearing premise
That sequence-level optimization, token-level supervision, and cross-lingual verbalization supply complementary and transferable learning signals for multilingual small language models.
What would settle it
Run the same teacher-student pairs on SEA-HELM with and without the cross-lingual verbalizer component; if the version lacking the verbalizer matches or exceeds DuDi performance, the claim that the three signals are complementary collapses.
Figures



read the original abstract
Small language models (SLMs) are efficient and scalable, but their multilingual capabilities degrade severely at sub-billion scales, especially for Southeast Asian (SEA) languages. We introduce DuDi, a dual-signal multilingual distillation framework that combines an online sequence-level signal with off-policy and on-policy token-level signals. DuDi further uses a cross-lingual verbalizer to refine teacher feedback and improve teacher-student transferability in multilingual settings. Experiments on SEA-HELM across multiple model families, scales, and teacher-student settings show that DuDi consistently outperforms competitive distillation baselines. Ablations and analyses confirm that sequence-level optimization, token-level supervision, and cross-lingual verbalization provide complementary and transferable learning signals for multilingual SLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DuDi, a dual-signal multilingual distillation framework for small language models that combines an online sequence-level signal with off-policy and on-policy token-level signals, plus a cross-lingual verbalizer to refine teacher feedback. It claims consistent outperformance over competitive distillation baselines on SEA-HELM across model families, scales, and teacher-student settings, with ablations confirming that sequence-level optimization, token-level supervision, and cross-lingual verbalization provide complementary and transferable signals.
Significance. If the empirical results hold with proper controls and statistical support, the work could meaningfully advance distillation techniques for improving multilingual performance of sub-billion SLMs on underrepresented SEA languages, where degradation is severe. The multi-signal approach, if shown to be additive, offers a practical direction for low-resource transfer.
major comments (1)
- Abstract: the claim that DuDi 'consistently outperforms competitive distillation baselines' and that the three signals 'provide complementary and transferable learning signals' is asserted without any quantitative results, error bars, baseline details, or statistical tests, so the central empirical claim cannot be evaluated.
Simulated Author's Rebuttal
Thank you for the detailed review. We address the major comment on the abstract below.
read point-by-point responses
-
Referee: Abstract: the claim that DuDi 'consistently outperforms competitive distillation baselines' and that the three signals 'provide complementary and transferable learning signals' is asserted without any quantitative results, error bars, baseline details, or statistical tests, so the central empirical claim cannot be evaluated.
Authors: Abstracts are intentionally concise high-level summaries and standard practice omits detailed metrics, error bars, and tests (which appear in the full paper). Section 4 presents SEA-HELM results across model families/scales/settings with tables comparing DuDi to baselines; Section 5 contains ablations confirming complementary signals; the experimental protocol and baseline descriptions are in Sections 3.2 and 4.1. We will revise the abstract to incorporate a small number of key quantitative highlights (e.g., average gains) while remaining within length limits. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical distillation framework (DuDi) combining sequence-level optimization, token-level signals, and a cross-lingual verbalizer, with performance claims resting entirely on experiments across SEA-HELM benchmarks, multiple model families, and ablations. No derivation chain, equations, fitted parameters, or first-principles results are presented that could reduce to inputs by construction. The abstract and high-level description contain no self-definitional steps, fitted-input predictions, or load-bearing self-citations; the complementarity conclusion is framed as an empirical finding from ablations rather than a logical necessity. This is a standard empirical methods paper whose central claims are externally falsifiable via replication on the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
von Werra, Leandro and Belkada, Younes and Tunstall, Lewis and Beeching, Edward and Thrush, Tristan and Lambert, Nathan and Huang, Shengyi and Rasul, Kashif and Gallouédec, Quentin , license =
-
[2]
The 1st Workshop on Scaling Post-training for LLMs , year=
Reinforcement Learning via Self-Distillation , author=. The 1st Workshop on Scaling Post-training for LLMs , year=
-
[3]
ML Evaluation Standards Workshop at the Tenth International Conference on Learning Representations , year=
deep-significance: Easy and Meaningful Signifcance Testing in the Age of Neural Networks , author=. ML Evaluation Standards Workshop at the Tenth International Conference on Learning Representations , year=
-
[4]
Deep Dominance - How to Properly Compare Deep Neural Models , booktitle =
Rotem Dror and Segev Shlomov and Roi Reichart , editor =. Deep Dominance - How to Properly Compare Deep Neural Models , booktitle =. 2019 , url =. doi:10.18653/v1/p19-1266 , timestamp =
-
[5]
The Mathematics of the Uncertain , pages=
An optimal transportation approach for assessing almost stochastic order , author=. The Mathematics of the Uncertain , pages=. 2018 , publisher=
2018
-
[6]
Silver, David and Schrittwieser, Julian and Simonyan, Karen and Antonoglou, Ioannis and Huang, Aja and Guez, Arthur and Hubert, Thomas and Baker, Lucas and Lai, Matthew and Bolton, Adrian and Chen, Yutian and Lillicrap, Timothy and Hui, Fan and Sifre, Laurent and van den Driessche, George and Graepel, Thore and Hassabis, Demis , title=. Nature , year=. do...
-
[7]
Tesauro, Gerald , title =. Commun. ACM , month = mar, pages =. 1995 , issue_date =. doi:10.1145/203330.203343 , abstract =
-
[8]
2026 , eprint=
Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models , author=. 2026 , eprint=
2026
-
[9]
arXiv preprint arXiv:2604.13016 , year=
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author=. arXiv preprint arXiv:2604.13016 , year=
-
[10]
Zhang, Yuanchi and Wang, Yile and Liu, Zijun and Wang, Shuo and Wang, Xiaolong and Li, Peng and Sun, Maosong and Liu, Yang. Enhancing Multilingual Capabilities of Large Language Models through Self-Distillation from Resource-Rich Languages. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 202...
-
[11]
Libo Qin and Qiguang Chen and Yuhang Zhou and Zhi Chen and Yinghui Li and Lizi Liao and Min Li and Wanxiang Che and Philip S. Yu , keywords =. A survey of multilingual large language models , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.patter.2024.101118 , url =
-
[12]
Chen, Xiao and Ma, Changyi and Fan, Wenqi and Zhang, Zhaoxiang and Qing, Li. C 2 KD : Cross-layer and Cross-head Knowledge Distillation for Small Language Model-based Recommendation. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.917
-
[13]
MMLU - P ro X : A Multilingual Benchmark for Advanced Large Language Model Evaluation
Xuan, Weihao and Yang, Rui and Qi, Heli and Zeng, Qingcheng and Xiao, Yunze and Feng, Aosong and Liu, Dairui and Xing, Yun and Wang, Junjue and Gao, Fan and Lu, Jinghui and Jiang, Yuang and Li, Huitao and Li, Xin and Yu, Kunyu and Dong, Ruihai and Gu, Shangding and Li, Yuekang and Xie, Xiaofei and Juefei-Xu, Felix and Khomh, Foutse and Yoshie, Osamu and C...
-
[14]
Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning
Yang, Zhaorui and Pang, Tianyu and Feng, Haozhe and Wang, Han and Chen, Wei and Zhu, Minfeng and Liu, Qian. Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.58
-
[15]
Pham, Thang M. and Nguyen, Phat T. and Yoon, Seunghyun and Lai, Viet Dac and Dernoncourt, Franck and Bui, Trung. S lim LM : An Efficient Small Language Model for On-Device Document Assistance. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). 2025. doi:10.18653/v1/2025.acl-demo.42
-
[16]
Shengding Hu and Yuge Tu and Xu Han and Ganqu Cui and Chaoqun He and Weilin Zhao and Xiang Long and Zhi Zheng and Yewei Fang and Yuxiang Huang and Xinrong Zhang and Zhen Leng Thai and Chongyi Wang and Yuan Yao and Chenyang Zhao and Jie Zhou and Jie Cai and Zhongwu Zhai and Ning Ding and Chao Jia and Guoyang Zeng and dahai li and Zhiyuan Liu and Maosong Su...
2024
-
[17]
Zechun Liu and Changsheng Zhao and Forrest Iandola and Chen Lai and Yuandong Tian and Igor Fedorov and Yunyang Xiong and Ernie Chang and Yangyang Shi and Raghuraman Krishnamoorthi and Liangzhen Lai and Vikas Chandra , booktitle=. Mobile. 2024 , url=
2024
-
[18]
SEA - HELM : S outheast A sian Holistic Evaluation of Language Models
Susanto, Yosephine and Hulagadri, Adithya Venkatadri and Montalan, Jann Railey and Ngui, Jian Gang and Yong, Xianbin and Leong, Wei Qi and Rengarajan, Hamsawardhini and Limkonchotiwat, Peerat and Mai, Yifan and Tjhi, William Chandra. SEA - HELM : S outheast A sian Holistic Evaluation of Language Models. Findings of the Association for Computational Lingui...
-
[19]
2026 , eprint=
TIP: Token Importance in On-Policy Distillation , author=. 2026 , eprint=
2026
-
[20]
Jongwoo Ko and Tianyi Chen and Sungnyun Kim and Tianyu Ding and Luming Liang and Ilya Zharkov and Se-Young Yun , booktitle=. Disti. 2025 , url=
2025
-
[21]
The Thirteenth International Conference on Learning Representations , year=
Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling , author=. The Thirteenth International Conference on Learning Representations , year=
-
[22]
Jongwoo Ko and Sungnyun Kim and Tianyi Chen and Se-Young Yun , booktitle=. Disti. 2024 , url=
2024
-
[23]
Yuxian Gu and Li Dong and Furu Wei and Minlie Huang , booktitle=. Mini. 2024 , url=
2024
-
[24]
Autoregressive Knowledge Distillation through Imitation Learning
Lin, Alexander and Wohlwend, Jeremy and Chen, Howard and Lei, Tao. Autoregressive Knowledge Distillation through Imitation Learning. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.494
-
[25]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
How do Large Language Models Handle Multilingualism? , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[26]
L ang B ridge: Multilingual Reasoning Without Multilingual Supervision
Yoon, Dongkeun and Jang, Joel and Kim, Sungdong and Kim, Seungone and Shafayat, Sheikh and Seo, Minjoon. L ang B ridge: Multilingual Reasoning Without Multilingual Supervision. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.405
-
[27]
Breaking Language Barriers in Multilingual Mathematical Reasoning: Insights and Observations
Chen, Nuo and Zheng, Zinan and Wu, Ning and Gong, Ming and Zhang, Dongmei and Li, Jia. Breaking Language Barriers in Multilingual Mathematical Reasoning: Insights and Observations. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.411
-
[28]
An Empirical Study of Multilingual Reasoning Distillation for Question Answering
Payoungkhamdee, Patomporn and Limkonchotiwat, Peerat and Baek, Jinheon and Manakul, Potsawee and Udomcharoenchaikit, Can and Chuangsuwanich, Ekapol and Nutanong, Sarana. An Empirical Study of Multilingual Reasoning Distillation for Question Answering. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.1865...
-
[29]
When Less Language is More: Language-Reasoning Disentanglement Makes
Weixiang Zhao and Jiahe Guo and Yang Deng and Tongtong Wu and Wenxuan Zhang and Yulin Hu and Xingyu Sui and Yanyan Zhao and Wanxiang Che and Bing Qin and Tat-Seng Chua and Ting Liu , booktitle=. When Less Language is More: Language-Reasoning Disentanglement Makes. 2026 , url=
2026
-
[30]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[32]
2026 , eprint=
Qwen3.5-Omni Technical Report , author=. 2026 , eprint=
2026
-
[33]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Chen, Zixiang and Deng, Yihe and Yuan, Huizhuo and Ji, Kaixuan and Gu, Quanquan , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[34]
and Vinyals, Oriol and Dean, Jeffrey , biburl =
Hinton, Geoffrey E. and Vinyals, Oriol and Dean, Jeffrey , biburl =. Distilling the Knowledge in a Neural Network. , url =. CoRR , keywords =
-
[35]
Sequence-Level Knowledge Distillation
Kim, Yoon and Rush, Alexander M. Sequence-Level Knowledge Distillation. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1139
-
[36]
The Twelfth International Conference on Learning Representations , year=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. The Twelfth International Conference on Learning Representations , year=
-
[37]
On the Generalization of
Yongliang Wu and Yizhou Zhou and Zhou Ziheng and Yingzhe Peng and Xinyu Ye and Xinting Hu and Wenbo Zhu and Lu Qi and Ming-Hsuan Yang and Xu Yang , booktitle=. On the Generalization of. 2026 , url=
2026
-
[38]
ICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving , year=
Self-Distillation Enables Continual Learning , author=. ICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving , year=
2026
-
[39]
2025 , eprint=
Small Language Models: Architectures, Techniques, Evaluation, Problems and Future Adaptation , author=. 2025 , eprint=
2025
-
[40]
2024 , eprint=
A Survey of Small Language Models , author=. 2024 , eprint=
2024
-
[41]
2025 , eprint=
Small Language Models (SLMs) Can Still Pack a Punch: A survey , author=. 2025 , eprint=
2025
-
[42]
2024 , eprint=
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness , author=. 2024 , eprint=
2024
-
[43]
2026 , eprint=
The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.