Physics-Informed Video Generation via Mixture-of-Experts Latent Alignment
Pith reviewed 2026-06-28 07:00 UTC · model grok-4.3
The pith
PILA aligns frozen video model latents to a physics attribute bank via anchored motion estimates and mixture-of-experts routing to raise physical plausibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
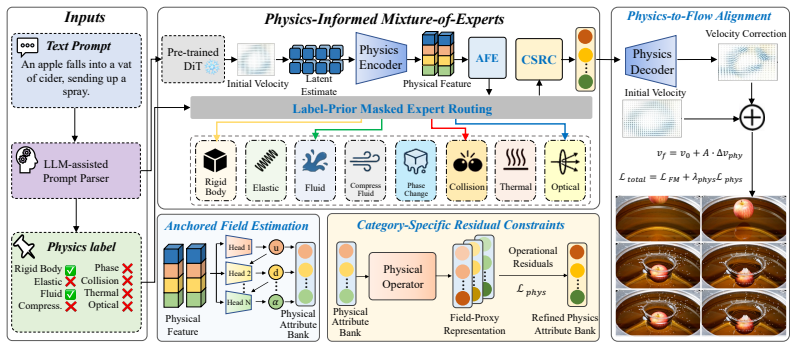
PILA injects physics-structured latent guidance into the frozen flow-matching dynamics of pretrained video models by mapping latents into an operational physical attribute bank through anchored field estimation, applying label-prior masked expert routing over physical categories, and decoding the refined proxies as a correction to the vector field.
What carries the argument
Anchored field estimation that converts frozen-generator latents into a physical attribute bank organized by field-proxy slots, with observable motion serving as the kinematic anchor for constructing the remaining proxies.
If this is right
- Staged adapter training on the 1.3B Wan 2.1 model transfers directly to the 14B Wan 2.2 model without further backbone updates.
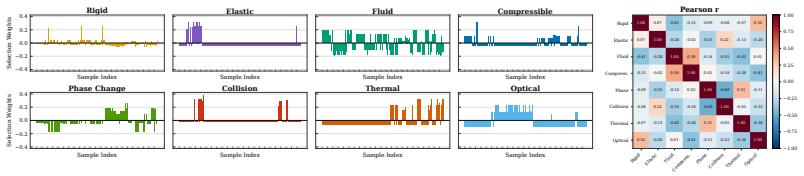
- Label-prior masked expert routing selects category-specific operator experts whose refinements are regularized by operational residuals from physical relations.
- The fused physical attribute bank is decoded into an additive correction to the flow-matching vector field.
- The separation of visual prior and physics correction preserves the pretrained model's semantic and visual capabilities while adding plausibility.
- Benchmark gains appear simultaneously on VBench-2.0 for visual quality and on VideoPhy-2 plus PhyGenBench for physical plausibility.
Where Pith is reading between the lines
- The same latent-to-proxy mapping could be applied to image or 3D generative models where physical consistency is required.
- Expanding the attribute bank to include interaction-level proxies such as contact forces might reduce artifacts in multi-object scenes.
- If the routing remains efficient at larger scale, the approach offers a modular way to update physics knowledge independently of visual training.
- The method's reliance on a fixed set of physical categories suggests testing whether new categories can be added without retraining the entire router.
Load-bearing premise
Observable motion can serve as a reliable kinematic anchor to construct accurate estimates of less directly observed physical proxies that are then organized into a usable attribute bank.
What would settle it
A controlled test set of generated videos where the frequency of physical-law violations (measured by the same PhyGenBench or VideoPhy-2 metrics) is statistically higher with the PILA adapter than without it would falsify the central claim.
Figures


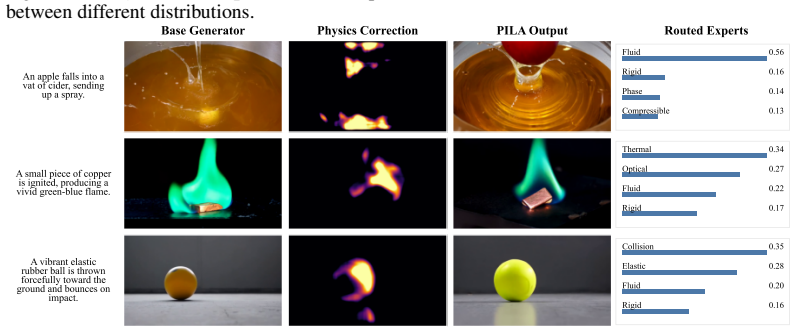






read the original abstract
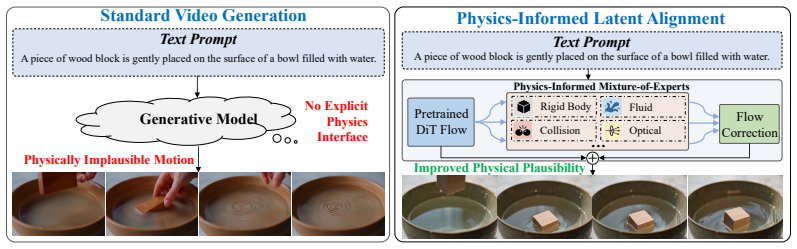
Large-scale video generation models have made remarkable progress in semantic consistency and visual quality, producing videos that are increasingly coherent and visually convincing. Nevertheless, the dynamics induced by pixel-level fitting do not naturally accommodate the regularities that govern real-world motion and interaction, resulting in persistent shortcomings in physical plausibility. To address this limitation, we propose \textbf{PILA} (Physics-Informed Latent Alignment), a framework that injects physics-structured latent guidance into the frozen flow-matching dynamics of pretrained video models. Specifically, PILA first employs anchored field estimation to map frozen-generator latents into an operational physical attribute bank organized by field-proxy slots, using observable motion as a kinematic anchor for constructing less directly observed proxies. To handle the heterogeneity of real-world dynamics, PILA adopts a mixture-of-experts design over physical categories. Label-prior masked expert routing selects category-specific operator experts, whose refinements are regularized by operational residuals abstracted from physical relations. Finally, the refined proxies are fused into the physical attribute bank and decoded into a correction to the flow-matching vector field, injecting physics-aware guidance while preserving the visual prior of the pretrained backbone. With staged adapter training on Wan 2.1-1.3B and direct transfer of the learned adapter to Wan 2.2-14B, PILA achieves state-of-the-art results on VBench-2.0, VideoPhy-2, and PhyGenBench in both visual quality and benchmark-measured physical plausibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PILA, a framework for injecting physics-structured guidance into the frozen flow-matching dynamics of pretrained video generators. It first applies anchored field estimation to map generator latents into a physical attribute bank organized by field-proxy slots, using observable motion as the kinematic anchor for less-observed proxies. A mixture-of-experts architecture with label-prior masked routing then refines category-specific operators, whose outputs are regularized by operational residuals derived from physical relations before being decoded as a correction to the flow-matching vector field. Staged adapter training is performed on Wan 2.1-1.3B with direct transfer to Wan 2.2-14B, yielding claimed state-of-the-art results on VBench-2.0, VideoPhy-2, and PhyGenBench for both visual quality and physical plausibility.
Significance. If the anchored proxies prove accurate and the MoE regularization demonstrably improves physical consistency without harming visual fidelity, the work would offer a scalable route to physics-aware video generation that preserves the visual prior of large backbones. The direct transfer from 1.3B to 14B adapters is a practical strength that could generalize to other generative settings. The absence of any reported validation for the proxy-construction step, however, leaves the claimed benchmark gains dependent on an unverified inverse-problem component.
major comments (2)
- [Abstract] Abstract (anchored field estimation paragraph): observable motion is asserted to serve as a sufficient kinematic anchor for constructing less-observed physical proxies that populate the attribute bank; no quantitative validation, ablation, or error metric on proxy accuracy is supplied, yet every downstream component (label-prior masked routing, operational-residual regularization, and vector-field correction) operates directly on this bank.
- [Abstract] Abstract (results claim): the assertion of SOTA performance on VideoPhy-2 and PhyGenBench after transfer supplies neither ablations, error bars, nor details on how the physical residuals are computed or validated against ground-truth dynamics, rendering the central empirical claim unverifiable from the provided text.
minor comments (1)
- [Abstract] The abstract introduces several compound terms ("operational-residual regularization," "field-proxy slots") without inline mathematical definitions or forward references to the sections where they are formalized.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and commit to revisions that improve the verifiability of the proxy-construction step and the empirical claims without altering the core technical contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract (anchored field estimation paragraph): observable motion is asserted to serve as a sufficient kinematic anchor for constructing less-observed physical proxies that populate the attribute bank; no quantitative validation, ablation, or error metric on proxy accuracy is supplied, yet every downstream component (label-prior masked routing, operational-residual regularization, and vector-field correction) operates directly on this bank.
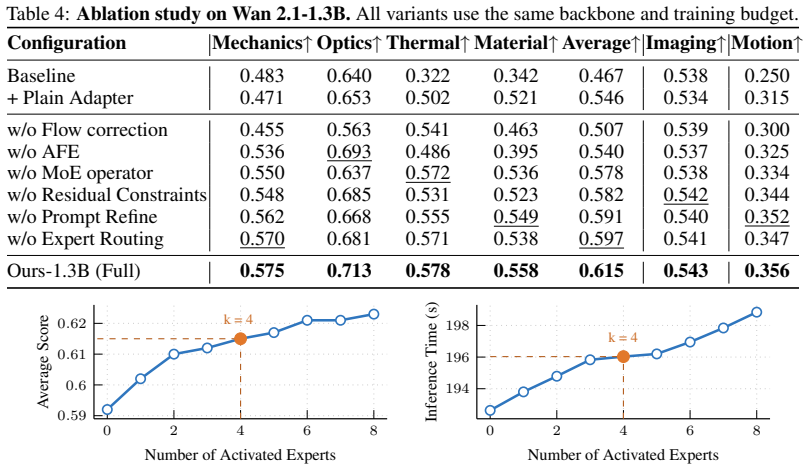
Authors: We agree that the abstract and main text would benefit from explicit quantitative validation of the anchored field estimation. The manuscript demonstrates end-to-end improvements on the target benchmarks, but does not isolate proxy accuracy with dedicated error metrics or ablations against ground-truth kinematics. We will add a new subsection (and corresponding table) reporting proxy reconstruction error, sensitivity to the motion anchor, and an ablation removing the anchor, using available synthetic and real sequences with known physical attributes. This will be placed before the MoE routing experiments. revision: yes
-
Referee: [Abstract] Abstract (results claim): the assertion of SOTA performance on VideoPhy-2 and PhyGenBench after transfer supplies neither ablations, error bars, nor details on how the physical residuals are computed or validated against ground-truth dynamics, rendering the central empirical claim unverifiable from the provided text.
Authors: We acknowledge the concern. The current manuscript reports aggregate benchmark scores and a direct 1.3B-to-14B transfer result, but the abstract and results section lack per-metric error bars, component ablations isolating the operational residuals, and an explicit description of residual computation/validation. We will expand the experiments section with (i) error bars over multiple seeds, (ii) an ablation table removing or replacing the residual regularization, and (iii) a methods paragraph detailing the residual formulation together with a small-scale validation against ground-truth dynamics on controlled sequences. These additions will make the SOTA claims directly verifiable. revision: yes
Circularity Check
No circularity: derivation relies on external physical relations and observable inputs without self-referential reduction
full rationale
The paper's core procedure maps latents via anchored field estimation using observable motion as kinematic anchor, then applies MoE routing and operational-residual regularization drawn from physical relations before decoding a flow-matching correction. No quoted equations, parameter fits, or self-citations reduce any claimed prediction or proxy to a quantity defined solely by the paper's own outputs or prior author work; the attribute bank construction and guidance injection remain independent of the final benchmark scores. The derivation chain is therefore self-contained against external physical priors rather than internally forced.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen flow-matching dynamics of pretrained video models can accept additive corrections derived from external physical relations without destabilizing generation.
invented entities (1)
-
physical attribute bank organized by field-proxy slots
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
2022
-
[2]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[3]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[4]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[5]
Physgaussian: Physics-integrated 3d gaussians for generative dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. Physgaussian: Physics-integrated 3d gaussians for generative dynamics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4389–4398, 2024
2024
-
[6]
Physgen3d: Crafting a miniature interactive world from a single image
Boyuan Chen, Hanxiao Jiang, Shaowei Liu, Saurabh Gupta, Yunzhu Li, Hao Zhao, and Shenlong Wang. Physgen3d: Crafting a miniature interactive world from a single image. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6178–6189, 2025
2025
-
[7]
Physdreamer: Physics-based interaction with 3d objects via video generation
Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T Freeman. Physdreamer: Physics-based interaction with 3d objects via video generation. In European Conference on Computer Vision, pages 388–406, 2024
2024
-
[8]
Zizhang Li, Hong-Xing Yu, Wei Liu, Yin Yang, Charles Herrmann, Gordon Wetzstein, and Jiajun Wu. Won- derplay: Dynamic 3d scene generation from a single image and actions.arXiv preprint arXiv:2505.18151, 2025
arXiv 2025
-
[9]
Phyt2v: Llm-guided iterative self-refinement for physics-grounded text-to-video generation
Qiyao Xue, Xiangyu Yin, Boyuan Yang, and Wei Gao. Phyt2v: Llm-guided iterative self-refinement for physics-grounded text-to-video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18826–18836, 2025
2025
-
[10]
Phyrpr: Training-free physics-constrained video generation.arXiv preprint arXiv:2601.09255, 2026
Yibo Zhao, Hengjia Li, Xiaofei He, and Boxi Wu. Phyrpr: Training-free physics-constrained video generation.arXiv preprint arXiv:2601.09255, 2026
arXiv 2026
-
[11]
Vlipp: Towards physically plausible video generation with vision and language informed physical prior
Xindi Yang, Baolu Li, Yiming Zhang, Zhenfei Yin, Lei Bai, Liqian Ma, Zhiyong Wang, Jianfei Cai, Tien-Tsin Wong, Huchuan Lu, et al. Vlipp: Towards physically plausible video generation with vision and language informed physical prior. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12360–12370, 2025
2025
-
[12]
Jianhao Yuan, Xiaofeng Zhang, Felix Friedrich, Nicolas Beltran-Velez, Melissa Hall, Reyhane Askari- Hemmat, Xiaochuang Han, Nicolas Ballas, Michal Drozdzal, and Adriana Romero-Soriano. Inference-time physics alignment of video generative models with latent world models.arXiv preprint arXiv:2601.10553, 2026
arXiv 2026
-
[13]
Ying Shen, Jerry Xiong, Tianjiao Yu, and Ismini Lourentzou. Phantom: Physics-infused video generation via joint modeling of visual and latent physical dynamics.arXiv preprint arXiv:2604.08503, 2026
Pith/arXiv arXiv 2026
-
[14]
Wisa: World simulator assistant for physics-aware text-to-video generation
Jing Wang, Ao Ma, Ke Cao, Jun Zheng, Zhanjie Zhang, Jiasong Feng, Shanyuan Liu, Yuhang Ma, Bo Cheng, Dawei Leng, et al. Wisa: World simulator assistant for physics-aware text-to-video generation. arXiv preprint arXiv:2503.08153, 2025
arXiv 2025
-
[15]
Zijun Wang, Panwen Hu, Jing Wang, Terry Jingchen Zhang, Yuhao Cheng, Long Chen, Yiqiang Yan, Zutao Jiang, Hanhui Li, and Xiaodan Liang. Prophy: Progressive physical alignment for dynamic world simulation.arXiv preprint arXiv:2512.05564, 2025
Pith/arXiv arXiv 2025
-
[16]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[17]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 10
Pith/arXiv arXiv 2023
-
[18]
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling.arXiv preprint arXiv:2410.05954, 2024
arXiv 2024
-
[19]
Flowvid: Taming imperfect optical flows for consistent video-to-video synthesis
Feng Liang, Bichen Wu, Jialiang Wang, Licheng Yu, Kunpeng Li, Yinan Zhao, Ishan Misra, Jia-Bin Huang, Peizhao Zhang, Peter Vajda, et al. Flowvid: Taming imperfect optical flows for consistent video-to-video synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8207–8216, 2024
2024
-
[20]
Xiaofeng Wang, Zheng Zhu, Guan Huang, Boyuan Wang, Xinze Chen, and Jiwen Lu. Worlddreamer: Towards general world models for video generation via predicting masked tokens.arXiv preprint arXiv:2401.09985, 2024
arXiv 2024
-
[21]
V oyager: Long-range and world-consistent video diffusion for explorable 3d scene generation.ACM Transactions on Graphics (TOG), 44(6):1–15, 2025
Tianyu Huang, Wangguandong Zheng, Tengfei Wang, Yuhao Liu, Zhenwei Wang, Junta Wu, Jie Jiang, Hui Li, Rynson Lau, Wangmeng Zuo, et al. V oyager: Long-range and world-consistent video diffusion for explorable 3d scene generation.ACM Transactions on Graphics (TOG), 44(6):1–15, 2025
2025
-
[22]
Make it move: controllable image-to-video generation with text descriptions
Yaosi Hu, Chong Luo, and Zhenzhong Chen. Make it move: controllable image-to-video generation with text descriptions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18219–18228, 2022
2022
-
[23]
Panacea: Panoramic and controllable video generation for autonomous driving
Yuqing Wen, Yucheng Zhao, Yingfei Liu, Fan Jia, Yanhui Wang, Chong Luo, Chi Zhang, Tiancai Wang, Xiaoyan Sun, and Xiangyu Zhang. Panacea: Panoramic and controllable video generation for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6902–6912, 2024
2024
-
[24]
Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling
Xiaoyu Shi, Zhaoyang Huang, Fu-Yun Wang, Weikang Bian, Dasong Li, Yi Zhang, Manyuan Zhang, Ka Chun Cheung, Simon See, Hongwei Qin, et al. Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[25]
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to-video generation.arXiv preprint arXiv:2407.02371, 2024
Pith/arXiv arXiv 2024
-
[26]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In2012 IEEE conference on computer vision and pattern recognition, pages 3354–3361. IEEE, 2012
2012
-
[27]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
2020
-
[28]
Vidgen-1m: A large-scale dataset for text-to-video generation.arXiv preprint arXiv:2408.02629, 2024
Zhiyu Tan, Xiaomeng Yang, Luozheng Qin, and Hao Li. Vidgen-1m: A large-scale dataset for text-to-video generation.arXiv preprint arXiv:2408.02629, 2024
arXiv 2024
-
[29]
Physgen: Rigid-body physics- grounded image-to-video generation
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang. Physgen: Rigid-body physics- grounded image-to-video generation. InEuropean Conference on Computer Vision, pages 360–378, 2024
2024
-
[30]
Yuchen Lin, Chenguo Lin, Jianjin Xu, and Yadong Mu. Omniphysgs: 3d constitutive gaussians for general physics-based dynamics generation.arXiv preprint arXiv:2501.18982, 2025
arXiv 2025
-
[31]
Minh-Quan Le, Yuanzhi Zhu, Vicky Kalogeiton, and Dimitris Samaras. What about gravity in video generation? post-training newton’s laws with verifiable rewards.arXiv preprint arXiv:2512.00425, 2025
arXiv 2025
-
[32]
Wei Liu, Ziyu Chen, Zizhang Li, Yue Wang, Hong-Xing Yu, and Jiajun Wu. Realwonder: Real-time physical action-conditioned video generation.arXiv preprint arXiv:2603.05449, 2026
arXiv 2026
-
[33]
Neuma: Neural material adaptor for visual grounding of intrinsic dynamics.Advances in Neural Information Processing Systems, 37:65643–65669, 2024
Junyi Cao, Shanyan Guan, Yanhao Ge, Wei Li, Xiaokang Yang, and Chao Ma. Neuma: Neural material adaptor for visual grounding of intrinsic dynamics.Advances in Neural Information Processing Systems, 37:65643–65669, 2024
2024
-
[34]
Yu Yuan, Xijun Wang, Tharindu Wickremasinghe, Zeeshan Nadir, Bole Ma, and Stanley H Chan. Newton- gen: Physics-consistent and controllable text-to-video generation via neural newtonian dynamics.arXiv preprint arXiv:2509.21309, 2025. 11
arXiv 2025
-
[35]
Phys4dgen: Physics- compliant 4d generation with multi-material composition perception
Jiajing Lin, Zhenzhong Wang, Dejun Xu, Shu Jiang, Yunpeng Gong, and Min Jiang. Phys4dgen: Physics- compliant 4d generation with multi-material composition perception. InProceedings of the 33rd ACM International Conference on Multimedia, pages 10398–10407, 2025
2025
-
[36]
Physical simulator in-the-loop video generation.arXiv preprint arXiv:2603.06408, 2026
Lin Geng Foo, Mark He Huang, Alexandros Lattas, Stylianos Moschoglou, Thabo Beeler, and Christian Theobalt. Physical simulator in-the-loop video generation.arXiv preprint arXiv:2603.06408, 2026
arXiv 2026
-
[37]
Cp4d: Composi- tional physics-aware 4d scene generation
Hanxin Zhu, Cong Wang, Tianyu He, Long Chen, Xin Jin, Chen Gao, and Zhibo Chen. Cp4d: Composi- tional physics-aware 4d scene generation
-
[38]
Learning physics-grounded 4d dynamics with neural gaussian force fields
Shiqian Li, Ruihong Shen, Junfeng Ni, Chang Pan, Chi Zhang, and Yixin Zhu. Learning physics-grounded 4d dynamics with neural gaussian force fields. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[39]
Zixuan Wang, Yixin Hu, Haolan Wang, Feng Chen, Yan Liu, Wen Li, and Yinjie Lei. Chain of event-centric causal thought for physically plausible video generation.arXiv preprint arXiv:2603.09094, 2026
arXiv 2026
-
[40]
Videorepa: Learning physics for video generation through relational alignment with foundation models
Xiangdong Zhang, Jiaqi Liao, Shaofeng Zhang, Fanqing Meng, Xiangpeng Wan, Junchi Yan, and Yu Cheng. Videorepa: Learning physics for video generation through relational alignment with foundation models. arXiv preprint arXiv:2505.23656, 2025
arXiv 2025
-
[41]
Yuanhao Cai, Kunpeng Li, Menglin Jia, Jialiang Wang, Junzhe Sun, Feng Liang, Weifeng Chen, Felix Juefei-Xu, Chu Wang, Ali Thabet, et al. Phygdpo: Physics-aware groupwise direct preference optimization for physically consistent text-to-video generation.arXiv preprint arXiv:2512.24551, 2025
Pith/arXiv arXiv 2025
-
[42]
Videophy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520, 2024
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. Videophy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520, 2024
Pith/arXiv arXiv 2024
-
[43]
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation.arXiv preprint arXiv:2503.06800, 2025
arXiv 2025
-
[44]
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
Pith/arXiv arXiv 2025
-
[45]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[46]
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation.arXiv preprint arXiv:2410.05363, 2024
Pith/arXiv arXiv 2024
-
[47]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[48]
refined_prompt
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020. 12 A Additional Method Details A.1 AFE Field Construction This section details how AFE converts th...
2020
-
[49]
The residual ∂tdk −u k comes directly from the displacement–velocity relation ∂td=u
Rigid Body.The rigid-body expert is derived from rigid kinematics rather than from a deformable material model. The residual ∂tdk −u k comes directly from the displacement–velocity relation ∂td=u . A rigid body should have negligible internal strain, so εk acts as a low-strain prior and σk −γ σεk keeps the stress-like proxy compatible with that regime up ...
-
[50]
Elastic.The elastic expert abstracts the small-deformation wave behavior implied by linear elasticity. In a homogeneous medium, the displacement field satisfies a wave-like equation after simplifying the elastodynamic balance; this motivates ∂2 t dk −c 2 d∆dk, and the same propagation bias is applied to the velocity slot through ∂2 t uk −c 2 u∆uk. The ter...
-
[51]
The continuity residual ∂tρk +∇·(ρ kuk) is the conservative form of mass conservation
Fluid.The fluid expert follows the standard mass and momentum balances used in viscous flow. The continuity residual ∂tρk +∇·(ρ kuk) is the conservative form of mass conservation. The momentum residual is a Navier–Stokes-style balance containing temporal acceleration, convective transport, pressure forcing, and viscous diffusion. Since pressure and densit...
-
[52]
The continuity term again comes from ∂tρ+∇ ·(ρu) = 0
Compressible Flow.The compressible-flow expert keeps mass conservation but replaces the incompressible-style momentum emphasis with terms that expose expansion and compression. The continuity term again comes from ∂tρ+∇ ·(ρu) = 0 . The residual ∂t(∇ ·u k)−c p∆pk tracks temporal changes of local compression and couples them to pressure-like variation under...
-
[53]
Phase Change.The phase-change expert is motivated by transported phase indicators and Stefan-style thermal coupling. The phase slot αk is treated as an occupancy/support proxy, so ∂tαk +∇·(α kuk) links support change to local motion, standing in for an advective phase-balance equation with unresolved source terms. The combined thermal term∂tTk +u k·∇T k −...
-
[54]
The kinematic term ∂tdk −u k again enforces the relation between displacement and velocity
Collision.The collision expert encodes impulse-response structure rather than solving comple- mentarity contact conditions. The kinematic term ∂tdk −u k again enforces the relation between displacement and velocity. The impulse term ∂tuk −γ j jk is derived from the impulse-momentum relation m ∂tu≃j after absorbing mass and scale into the latent proxy. The...
-
[55]
The term ∂tTk +∇·(u k ¯Tk)− κ∆Tk combines temporal storage, conservative advection, and diffusion, while ∇Tk limits isolated temperature spikes
Thermal.The thermal expert uses a compact heat-transport proxy. The term ∂tTk +∇·(u k ¯Tk)− κ∆Tk combines temporal storage, conservative advection, and diffusion, while ∇Tk limits isolated temperature spikes. We omit unknown heat sources, material heat capacity, and boundary fluxes, so the resulting residual is a low-frequency thermal prior rather than a ...
-
[56]
w/o Expert Routing
Optical.The optical expert abstracts wave-like propagation into a scalar latent proxy. The residual ∂2 t ψk −c 2 ψ∆ψk follows the scalar wave equation obtained after suppressing constants and polarization details. The support-gating term (1−α k)ψk discourages wave-like activation outside the associated support proxy, while ∆αk smooths that support. These ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.