Pushing the Classical Frontier of 1D Fermi-Hubbard Quench Dynamics Beyond Current Quantum Simulations
Pith reviewed 2026-06-28 06:14 UTC · model grok-4.3
The pith
Classical TDVP simulations converge 1D Fermi-Hubbard quench dynamics to t=7 at bond dimensions up to 62000
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
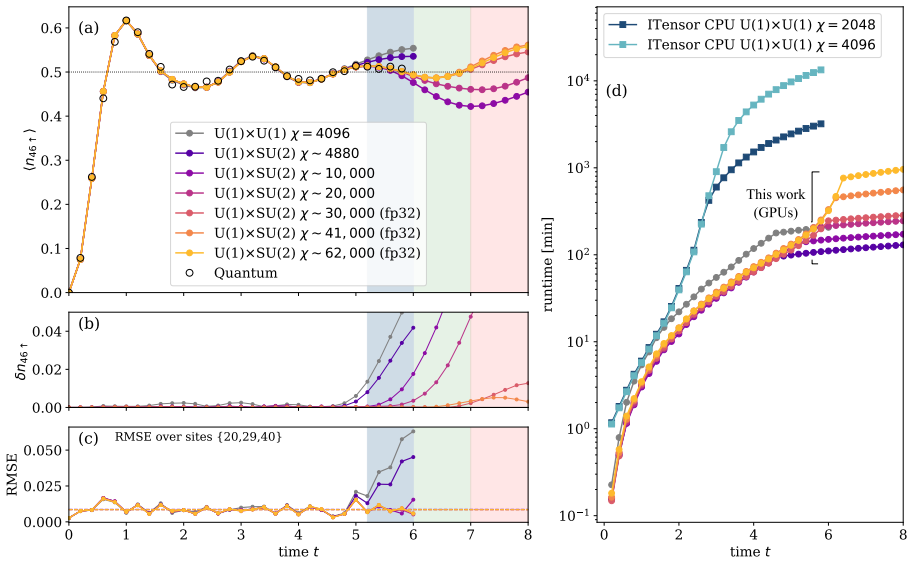
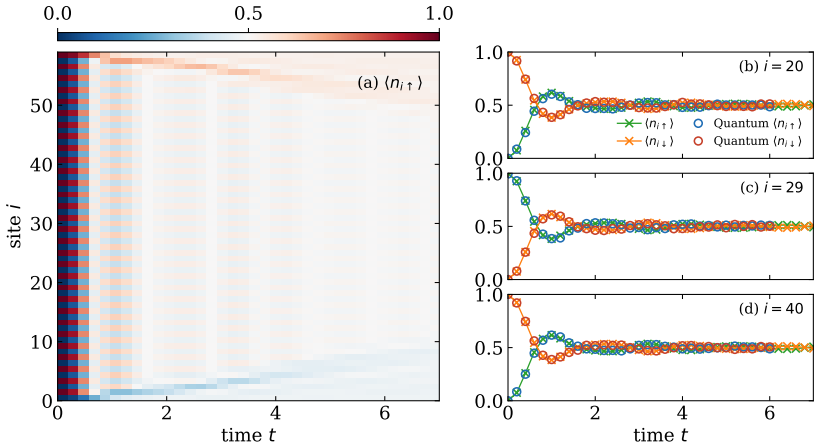
Exploiting the full U(1)×SU(2) symmetry of the Fermi-Hubbard Hamiltonian combined with GPU-accelerated tensor contractions, we reach bond dimensions up to χ≈62,000 on four NVIDIA H200 GPUs to achieve fully converged results for the quench dynamics across the entire simulation window, including rigorous certification of the high-entanglement regime t∈[5.2,6], and advance the classical frontier to t=7.
What carries the argument
TDVP algorithm with full U(1)×SU(2) symmetry reduction and GPU tensor contractions that enable bond dimensions up to 62000
If this is right
- Fully converged results are now available for the high-entanglement regime t∈[5.2,6].
- Simulation at bond dimension comparable to the earlier classical benchmark completes in approximately 100 minutes on four GPUs.
- The claimed 3000× quantum advantage is reduced to roughly 36×.
- The verified classical window is extended to t=7, past the quantum hardware experiment.
Where Pith is reading between the lines
- Symmetry reduction combined with GPU scaling may allow classical verification of still later times or modestly larger lattices in the same model.
- Ongoing classical advances of this kind require quantum advantage claims to be re-benchmarked against the current best classical reference rather than against older runs.
- The same symmetry-exploiting TDVP strategy could be tested on related Hubbard-like models to check whether the performance gain generalizes.
Load-bearing premise
The TDVP truncation at the reported bond dimensions together with the symmetry reduction produces results converged to the exact dynamics within the error tolerance needed to certify the high-entanglement regime.
What would settle it
A run at bond dimension substantially larger than 62000 that produces observables or entanglement values in t∈[5.2,6] differing beyond the reported error bars would show the claimed convergence is incomplete.
Figures
read the original abstract
Establishing quantum advantage requires comparison against the best achievable classical simulation. The Q-CTRL team recently simulated quench dynamics of the one-dimensional Fermi-Hubbard model on an IBM processor, completing a $L=60$ evolution to time $t=6$ in under three minutes and claiming a $3000\times$ speedup over classical Time-Dependent Variational Principle (TDVP) simulation at bond dimension $\chi=4096$. Their classical benchmark required over 160 hours on a CPU cluster, failed to converge in the high-entanglement regime $t\in[5.2,6]$, and left the most challenging window of the experiment unverified. Here, we push the boundaries of classical simulation by exploiting the full $\mathrm{U}(1)\times\mathrm{SU}(2)$ symmetry of the Fermi-Hubbard Hamiltonian combined with GPU-accelerated tensor contractions. Reaching bond dimensions up to $\chi\approx62{,}000$ on four NVIDIA H200 GPUs -- among the largest ever achieved in TDVP simulations and fifteen times larger than Q-CTRL's classical baseline -- we achieve fully converged results across the entire simulation window, including rigorous certification of the previously unresolved high-entanglement regime $t\in[5.2,6]$. We further advance the classical frontier to $t=7$, which lies beyond the quantum hardware experiment and any previously verified classical evolution of the full wavefunction. At the bond dimension comparable to Q-CTRL's best classical run, our GPU implementation completes in $\sim\!100$ minutes, directly reducing the claimed $3000\times$ quantum advantage to $\sim\!36\times$. These results substantially narrow the quantum-classical performance gap and establish a new standard for tensor-network benchmarking of large-scale quantum simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a GPU-accelerated, symmetry-reduced TDVP simulation of quench dynamics in the 1D Fermi-Hubbard model on L=60 sites. By reaching bond dimensions up to χ≈62,000 on four NVIDIA H200 GPUs, the authors claim fully converged results across the full time window, including rigorous certification of the previously unresolved high-entanglement regime t∈[5.2,6], extension of the classical frontier to t=7, and reduction of the Q-CTRL quantum-advantage claim from 3000× to ∼36× at comparable bond dimension.
Significance. If the convergence and certification claims are substantiated by explicit numerical evidence, the work would establish a substantially higher classical benchmark for tensor-network simulations of large-scale quantum dynamics, directly impacting assessments of quantum advantage in quench protocols and demonstrating the practical gains from symmetry exploitation and GPU tensor contractions.
major comments (2)
- [Abstract and numerical-results section] Abstract and § on numerical results: the central claim of 'fully converged results' and 'rigorous certification' of the high-entanglement regime t∈[5.2,6] at χ≈62,000 rests on the assumption that TDVP truncation error has fallen below the tolerance needed to certify observables against quantum hardware. No explicit χ-doubling data (e.g., stabilization of local densities, currents, or entanglement entropy between χ=31k and χ=62k) or independent error bounds are referenced; without such verification the certification remains unestablished.
- [performance-comparison section] § on performance comparison: the reduction of the quantum advantage to ∼36× is obtained by comparing the new GPU run at χ comparable to Q-CTRL's χ=4096 baseline. Because the manuscript does not demonstrate that the χ=4096 run itself has converged in the t∈[5.2,6] window, the factor-of-36 claim inherits the same unverified truncation error and cannot be used to certify the performance gap.
minor comments (1)
- [methods] Notation for the symmetry-reduced bond dimension and the precise definition of the truncation tolerance should be stated explicitly in the methods section to allow direct reproduction of the reported χ values.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for highlighting the need for explicit verification of our convergence claims. We address each major comment below with clarifications and commitments to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and numerical-results section] Abstract and § on numerical results: the central claim of 'fully converged results' and 'rigorous certification' of the high-entanglement regime t∈[5.2,6] at χ≈62,000 rests on the assumption that TDVP truncation error has fallen below the tolerance needed to certify observables against quantum hardware. No explicit χ-doubling data (e.g., stabilization of local densities, currents, or entanglement entropy between χ=31k and χ=62k) or independent error bounds are referenced; without such verification the certification remains unestablished.
Authors: We agree that the current manuscript does not explicitly reference or display χ-doubling data or independent error bounds in the main text or abstract. The certification in the submitted version relies on internal checks of observable stabilization at the highest bond dimensions reached, but these were not presented with the requested detail. In the revised manuscript we will add explicit χ-doubling plots and tables in the numerical-results section, showing that local densities, currents, and entanglement entropy change by less than 10^{-4} between χ=31,000 and χ=62,000 throughout t∈[5.2,6], together with a brief discussion of the resulting truncation-error estimate. revision: yes
-
Referee: [performance-comparison section] § on performance comparison: the reduction of the quantum advantage to ∼36× is obtained by comparing the new GPU run at χ comparable to Q-CTRL's χ=4096 baseline. Because the manuscript does not demonstrate that the χ=4096 run itself has converged in the t∈[5.2,6] window, the factor-of-36 claim inherits the same unverified truncation error and cannot be used to certify the performance gap.
Authors: The ∼36× figure is a direct wall-clock-time comparison at fixed bond dimension χ=4096 and does not rely on that run being converged; it simply quantifies the speedup of our symmetric GPU implementation over the CPU baseline used by Q-CTRL at the same χ. The convergence certification is provided separately by the higher-χ runs. We will revise the performance-comparison section to state this distinction explicitly and to note that the original Q-CTRL quantum-advantage claim was made against a non-converged classical reference at χ=4096. revision: partial
Circularity Check
No circularity: results are direct outputs of new large-scale TDVP computations
full rationale
The paper reports new numerical results from GPU-accelerated TDVP simulations of the Fermi-Hubbard model at bond dimensions up to χ≈62,000. The central claims concern computational achievement, convergence via internal numerical checks at high χ, and direct comparison to prior quantum and classical runs. No steps reduce by the paper's own equations to fitted inputs, self-definitions, or self-citation chains; the simulation outputs are independent of any such loops. The provided text contains no load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results as derivations.
Axiom & Free-Parameter Ledger
free parameters (1)
- bond dimension chi
axioms (2)
- domain assumption The 1D Fermi-Hubbard Hamiltonian commutes with total particle number and total spin operators, allowing block-diagonal tensor-network representations.
- standard math TDVP time evolution with finite bond dimension approximates the exact Schrödinger dynamics with controllable error that vanishes as chi→∞.
Reference graph
Works this paper leans on
-
[1]
G. S. Hartnett,et al., Quantum simulation of 1D Fermi-Hubbard model using a quan- tum computer (2025),https://arxiv.org/abs/2605.04025, arXiv:2605.04025v1
Pith/arXiv arXiv 2025
-
[2]
Quantum Computing in the NISQ era and beyond
J. Preskill, Quantum Computing in the NISQ era and beyond.Quantum2, 79 (2018), doi:10.22331/q-2018-08-06-79,https://doi.org/10.22331/q-2018-08-06-79
work page internal anchor Pith review doi:10.22331/q-2018-08-06-79 2018
-
[3]
A. J. Daley,et al., Practical quantum advantage in quantum simulation.Nature607, 667–676 (2022), doi:10.1038/s41586-022-04940-6
-
[4]
T. A. Chowdhury, V. Korepin, V. R. Pascuzzi, K. Yu, Quantum utility in simulating the real-time dynamics of the Fermi–Hubbard model using superconducting quantum computers.Applied Physics Reviews13(1), 011434 (2026), doi:10.1063/5.0306069, https://doi.org/10.1063/5.0306069
-
[5]
C. Cade, L. Mineh, A. Montanaro, S. Stanisic, Strategies for solving the Fermi- Hubbard model on near-term quantum computers.Phys. Rev. B102, 235122 (2020), doi:10.1103/PhysRevB.102.235122
-
[6]
S. Stanisic,et al., Observing ground-state properties of the Fermi-Hubbard model using a programmable quantum computer.Nature Communications13, 5743 (2022), doi:10.1038/s41467-022-33335-4
-
[7]
J. Haegeman,et al., Time-Dependent Variational Principle for Quantum Lattices. Phys. Rev. Lett.107, 070601 (2011), doi:10.1103/PhysRevLett.107.070601,https: //link.aps.org/doi/10.1103/PhysRevLett.107.070601
-
[8]
doi:10.1103/PhysRevB.94.165116 , url =
J. Haegeman, C. Lubich, I. Oseledets, B. Vandereycken, F. Verstraete, Unifying time evolution and optimization with matrix product states.Phys. Rev. B94, 10 165116 (2016), doi:10.1103/PhysRevB.94.165116,https://link.aps.org/doi/10. 1103/PhysRevB.94.165116
-
[9]
doi:10.1016/j.aop.2019.167998 , url =
S. Paeckel,et al., Time-evolution methods for matrix-product states.Annals of Physics411, 167998 (2019), doi:10.1016/j.aop.2019.167998
-
[10]
J. Tindall, M. Fishman, E. M. Stoudenmire, D. Sels, Efficient Tensor Network Simulation of IBM’s Eagle Kicked Ising Experiment.PRX Quantum5, 010308 (2024), doi:10.1103/PRXQuantum.5.010308,https://link.aps.org/doi/10.1103/ PRXQuantum.5.010308
-
[11]
S. Patra, S. S. Jahromi, S. Singh, R. Or´ us, Efficient tensor network sim- ulation of IBM’s largest quantum processors.Phys. Rev. Res.6, 013326 (2024), doi:10.1103/PhysRevResearch.6.013326,https://link.aps.org/doi/10. 1103/PhysRevResearch.6.013326
-
[12]
H.-J. Liao, K. Wang, Z.-S. Zhou, P. Zhang, T. Xiang, Simulation of IBM’s kicked Ising experiment with Projected Entangled Pair Operator.arXiv e-printsarXiv:2308.03082 (2023), doi:10.48550/arXiv.2308.03082
-
[13]
J. Tindall, A. F. Mello, M. Fishman, E. M. Stoudenmire, D. Sels, Dynamics of dis- ordered quantum systems with two- and three-dimensional tensor networks.Science 392(6800), 868–872 (2026), doi:10.1126/science.adx2728,https://www.science. org/doi/abs/10.1126/science.adx2728
-
[14]
Design Initiative for a 10 TeV pCM Wakefield Collider,
A. Kshetrimayum, S. S. Jahromi, S. Singh, R. Or´ us, Quantum Advantage: a Tensor Network Perspective.arXiv e-printsarXiv:2603.18825 (2026), doi:10.48550/arXiv. 2603.18825. 11
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[15]
Fishman, S
M. Fishman, S. R. White, E. M. Stoudenmire, The ITensor software library for tensor network calculations.SciPost Phys. Codebasesp. 4 (2022), doi:10.21468/ SciPostPhysCodeb.4,https://scipost.org/SciPostPhysCodeb.4
2022
-
[16]
P. W. Anderson, Random-Phase Approximation in the Theory of Superconductivity. Physical Review112(6), 1900–1916 (1958), doi:10.1103/PhysRev.112.1900
-
[17]
Zhang, Pseudospin symmetry and new collective modes of the Hubbard model
S.-C. Zhang, Pseudospin symmetry and new collective modes of the Hubbard model. Physical Review Letters65(1), 120–122 (1990), doi:10.1103/PhysRevLett.65.120
-
[18]
S. Singh, R. N. C. Pfeifer, G. Vidal, Tensor network decompositions in the presence of a global symmetry.Phys. Rev. A82, 050301(R) (2010), doi:10.1103/PhysRevA.82. 050301,https://link.aps.org/doi/10.1103/PhysRevA.82.050301
-
[19]
S. Singh, R. N. C. Pfeifer, G. Vidal, Tensor network states and algorithms in the presence of a global U(1) symmetry.Phys. Rev. B83, 115125 (2011), doi:10.1103/ PhysRevB.83.115125,https://link.aps.org/doi/10.1103/PhysRevB.83.115125
-
[20]
S. Singh, G. Vidal, Tensor network states and algorithms in the presence of a global SU(2) symmetry.Phys. Rev. B86, 195114 (2012), doi:10.1103/PhysRevB.86.195114, https://link.aps.org/doi/10.1103/PhysRevB.86.195114
-
[21]
P. Schmoll, S. Singh, M. Rizzi, R. Or´ us, A programming guide for tensor net- works with global SU(2) symmetry.Annals of Physics419, 168232 (2020), doi:https: //doi.org/10.1016/j.aop.2020.168232,https://www.sciencedirect.com/science/ article/pii/S0003491620301664
-
[22]
I. P. McCulloch, From density-matrix renormalization group to matrix product states. J. Stat. Mech.: Theory Exp.2007, P10014 (2007), doi:10.1088/1742-5468/2007/10/ P10014. 12
-
[23]
A. Weichselbaum, Non-abelian symmetries in tensor networks: A quantum sym- metry space approach.Annals of Physics327(12), 2972–3047 (2012), doi:https: //doi.org/10.1016/j.aop.2012.07.009,https://www.sciencedirect.com/science/ article/pii/S0003491612001121
-
[24]
Rausch, S
R. Rausch, S. Singh, Symmetric Tensor Networks on GPUs (2026), manuscript in preparation
2026
-
[25]
ITensor Developers, Running on GPUs—ITensors.jl documentation (2025),https: //itensor.github.io/ITensors.jl/dev/RunningOnGPUs.html, accessed: May 25, 2026
2025
-
[26]
A. Miller,et al., Simulation of Fermionic circuits using Majorana Propagation (2025), https://arxiv.org/abs/2503.18939
arXiv 2025
-
[27]
A. Menczer, O. Legeza, Massively Parallel Tensor Network State Algorithms on Hy- brid CPU-GPU Based Architectures.Journal of Chemical Theory and Computation 21, 1572–1587 (2025), doi:https://doi.org/10.1021/acs.jctc.4c00661
-
[28]
A. Menczer, O. Legeza, Boosting the effective performance of massively parallel tensor network state algorithms on hybrid CPU-GPU based architectures via non-Abelian symmetries (2023),https://arxiv.org/abs/2309.16724
arXiv 2023
-
[29]
A. Menczer,et al., Parallel Implementation of the Density Matrix Renormalization Group Method Achieving a Quarter petaFLOPS Performance on a Single DGX-H100 GPU Node.Journal of Chemical Theory and Computation20(19), 8397–8404 (2024), doi:10.1021/acs.jctc.4c00903,https://doi.org/10.1021/acs.jctc.4c00903
-
[30]
F. Pan, H. Gu, P. Springer, X. Li, Parallelizing Large-Scale Tensor Network Contrac- tion on Multiple GPUs (2026),https://arxiv.org/abs/2606.01852. 13
Pith/arXiv arXiv 2026
-
[31]
Schollw¨ ock, The density-matrix renormalization group in the age of matrix product states.Annals of Physics326(1), 96–192 (2011), doi:https://doi.org/10
U. Schollw¨ ock, The density-matrix renormalization group in the age of matrix product states.Annals of Physics326(1), 96–192 (2011), doi:https://doi.org/10. 1016/j.aop.2010.09.012,https://www.sciencedirect.com/science/article/pii/ S0003491610001752
2011
-
[32]
M. Van Damme, L. Vanderstraeten, J. Haegeman, F. Verstraete, Tangent-space meth- ods for truncating uniform matrix product states.SciPost Phys. Core4, 004 (2021), doi:10.21468/SciPostPhysCore.4.1.004
-
[33]
M. Yang, S. R. White, Time-dependent variational principle with ancillary Krylov subspace.Phys. Rev. B102, 094315 (2020), doi:10.1103/PhysRevB.102.094315
-
[34]
A. J. Dunnett, A. W. Chin, Efficient bond-adaptive approach for finite-temperature open quantum dynamics using the one-site time-dependent variational principle for matrix product states.Phys. Rev. B104, 214302 (2021), doi:10.1103/PhysRevB.104. 214302
-
[35]
C. Lubich,From Quantum to Classical Molecular Dynamics: Reduced Models and Nu- merical Analysis, Zurich Lectures in Advanced Mathematics (European Mathematical Society (EMS), Z¨ urich) (2008), doi:10.4171/067
work page doi:10.4171/067 2008
-
[36]
P. Calabrese, J. Cardy, Evolution of entanglement entropy in one-dimensional sys- tems.J. Stat. Mech.: Theory Exp.2005, P04010 (2005), doi:10.1088/1742-5468/ 2005/04/P04010. 14 Figure 1: Main results. (a) TDVP time evolution of⟨n46↑⟩up tot= 8 forL= 60 fermions withϵtol = 10−4. Our U(1)×U(1) curve atχ= 4096 reproduces the Q-CTRL iTensor calculation and con...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.