AIP: A Graph Representation for Learning and Governing Agent Skills
Pith reviewed 2026-06-28 05:55 UTC · model grok-4.3
The pith
Representing agent skills as directed execution graphs improves task reliability and turns skill editing into precise node-level repairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that modeling a skill as a directed execution graph of discrete steps with explicit typed edges and schema validation delivers ready-to-run units to the agent rather than natural-language instructions, raising performance on real tasks while converting skill creation and repair into a measurable, node-addressable process instead of prose rewriting.
What carries the argument
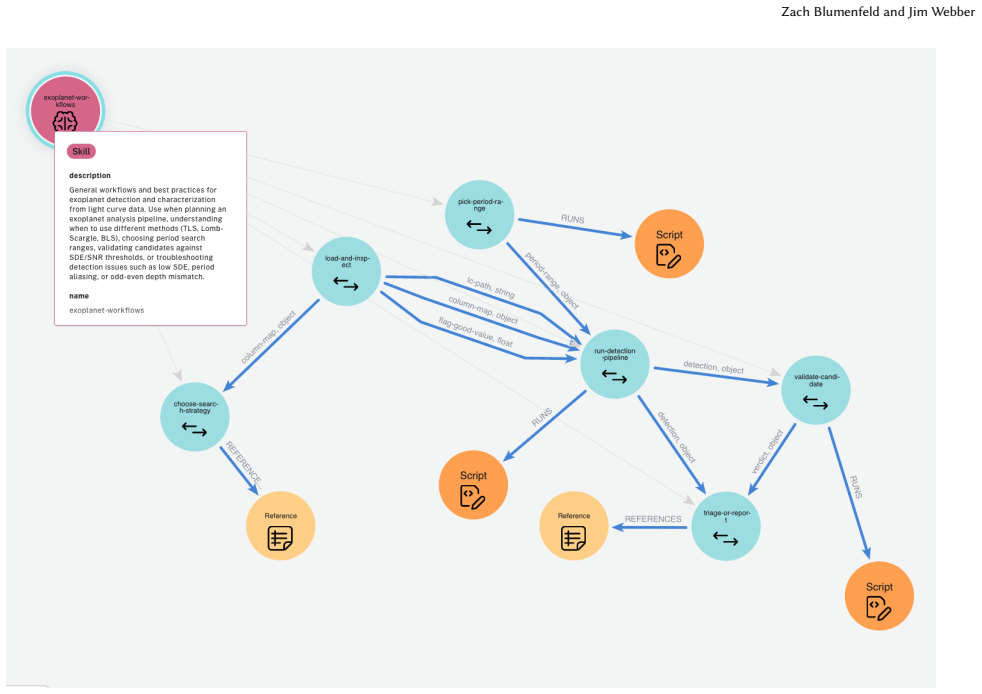
The AIP directed execution graph: nodes as discrete steps backed by scripts or descriptions, connected by explicit typed input/output edges, governed by a schema-validated YAML specification.
If this is right
- Agents receive vetted runnable steps instead of re-deriving code and tool calls from language, producing higher task reward and pass rates.
- Skill failures can be traced to individual nodes or scripts and repaired without introducing regressions elsewhere.
- Schema validation and node-level addressing turn skill improvement into a repeatable tuning loop.
- The graph structure enables corpus-level governance, introspection, and a natural action space for reinforcement learning over skills.
Where Pith is reading between the lines
- If graphs become the standard unit, agents could compose new skills by linking nodes drawn from multiple existing compiled skills.
- The same node-addressable format could support automatic versioning and rollback of skill changes across a shared library.
- Skill graphs might allow measurement of procedural knowledge coverage by counting unique node types across a corpus.
Load-bearing premise
The compiler meta-skill can translate arbitrary human-written prose skills into AIP graphs while preserving all necessary procedural knowledge and without introducing errors that affect execution.
What would settle it
Re-running the 27 SkillsBench tasks with the same skills kept in original prose form and finding no statistically significant difference in reward, pass rate, or repair success compared with the AIP-compiled versions.
Figures


read the original abstract
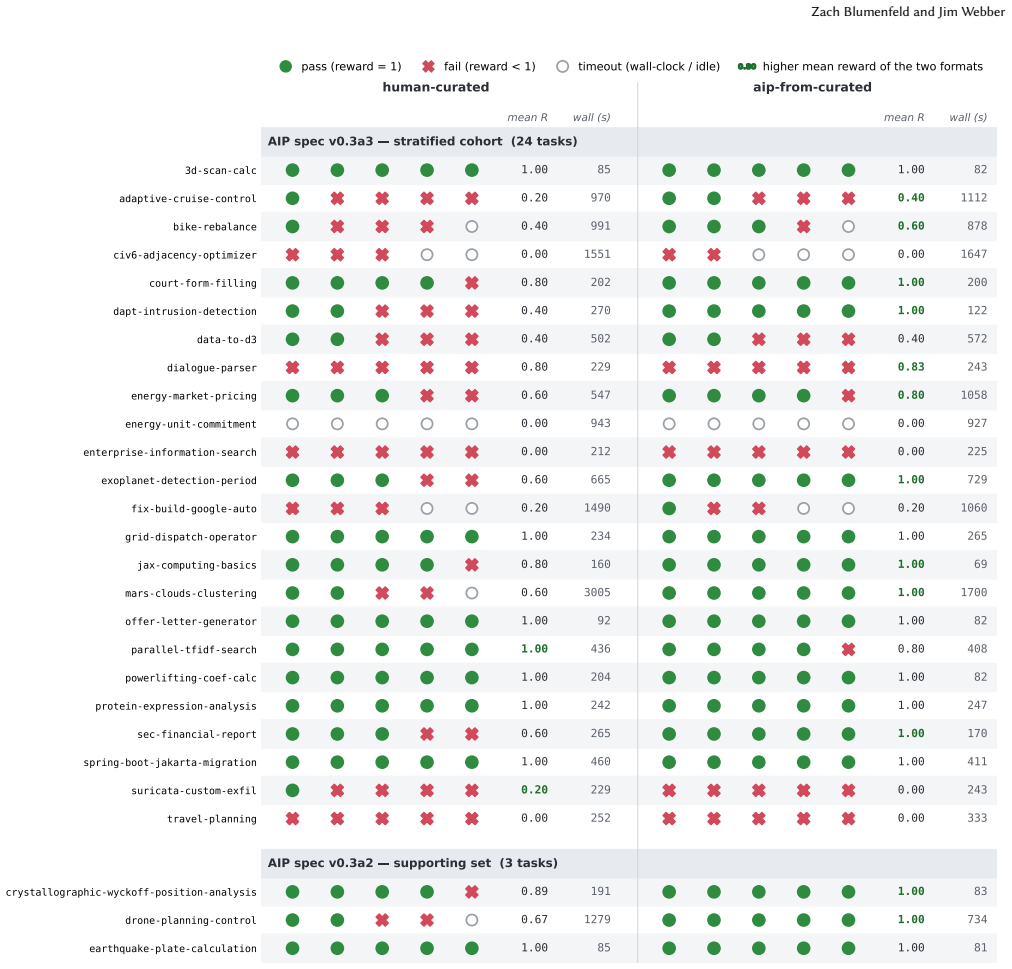
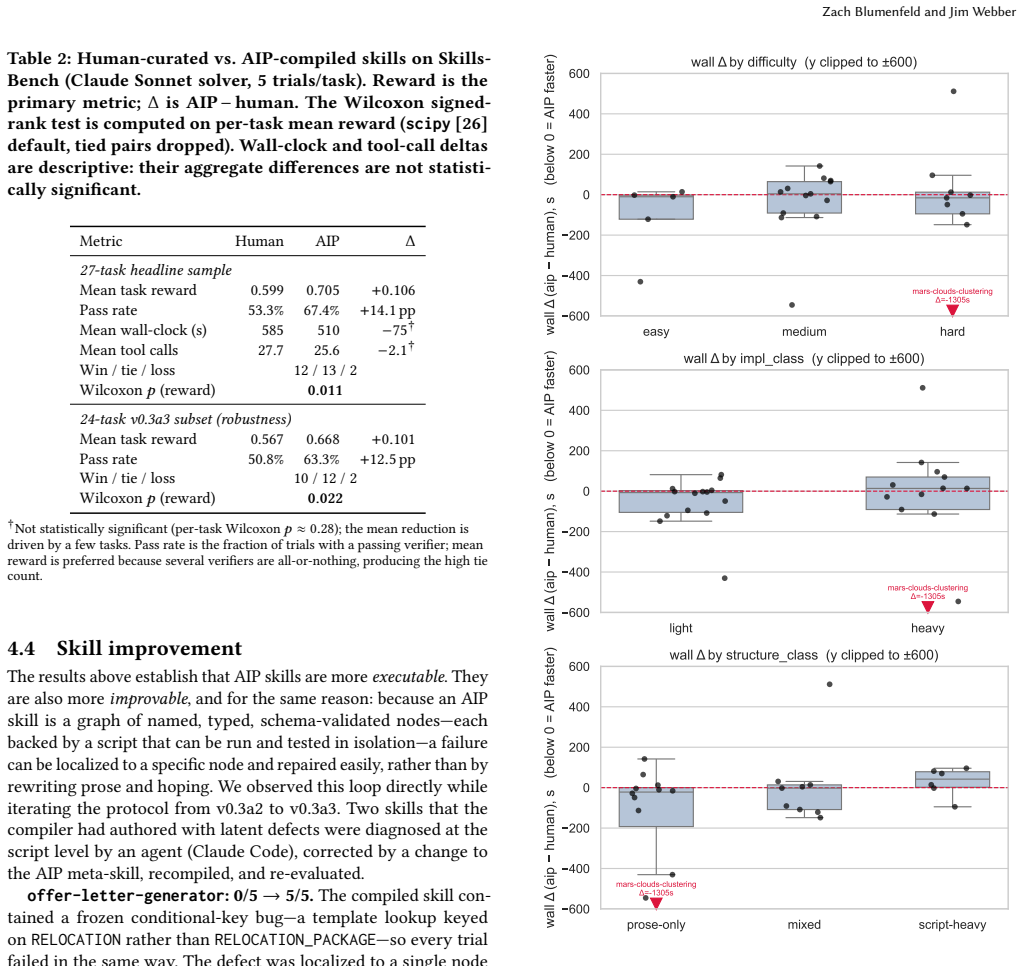
Agent Skills today consist largely of free-form prose requiring the agent to read, interpret, and re-derive how to act in every session. This imposes two compounding costs: reduced reliability on implementation-heavy tasks, and difficulty in skill creation and improvement, since editing prose is a fragile process that both humans and agents struggle with, particularly for domain-specific procedural knowledge underrepresented in model training. The Agent Instruction Protocol (AIP) addresses both by modeling a skill as a directed execution graph: discrete steps as nodes backed by deterministic scripts or natural-language descriptions, connected by explicit typed input/output edges, and governed by a schema-validated YAML specification. A compiler meta-skill translates existing human-written skills into this form. The benefits are twofold. First, compiling human-written skills to AIP raised Claude Sonnet's mean task reward from 0.60 to 0.71 and pass rate from 53% to 67% across 27 real agent tasks from SkillsBench - a statistically significant gain (Wilcoxon signed-rank p = 0.011), winning 12 tasks to 2 with 13 ties - often in less wall-clock time. The graph delivers vetted, runnable units to the agent rather than asking it to re-derive code, commands, and tool calls from natural language. Second, on creation and improvement, because each skill is schema-validated, functionally testable, and addressable node-by-node, failures can be diagnosed and repaired precisely. Two authored-skill failures were traced to the script level. After adjusting the AIP spec and recompiling, both recovered with zero regressions (one task going from 0/5 to 5/5), turning skill improvement into a measurable tuning loop rather than a prose rewrite. That same graph structure supports corpus-level governance and skill introspection, and provides a natural action space for reinforcement learning over skills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Agent Instruction Protocol (AIP), a directed execution graph representation for agent skills in which nodes are discrete steps (backed by deterministic scripts or natural-language descriptions) connected by explicit typed input/output edges and governed by a schema-validated YAML specification. A compiler meta-skill translates existing human-written prose skills into AIP form. The central empirical claim is that this yields performance gains on 27 SkillsBench tasks with Claude Sonnet (mean reward 0.60 o0.71, pass rate 53% o67%, Wilcoxon signed-rank p=0.011, 12 wins vs 2 losses), plus improved skill creation and repair via node-level diagnosis. The graph is also positioned as enabling corpus-level governance and RL over skills.
Significance. If the performance attribution holds after controls, AIP would offer a concrete advance in encoding procedural agent knowledge as addressable, testable units rather than free-form prose, potentially improving reliability on implementation-heavy tasks and turning skill maintenance into a measurable loop. Credit is due for the use of an external benchmark (SkillsBench), before/after comparisons, and a non-parametric statistical test on 27 tasks; these elements provide a falsifiable, reproducible-style foundation for the headline numeric result.
major comments (2)
- [Abstract] Abstract: the claim that gains arise because the graph 'delivers vetted, runnable units rather than asking [the agent] to re-derive code, commands, and tool calls from natural language' is not isolated from compiler effects; the only reported comparison is prose vs. compiler-generated AIP, with no control (human-authored AIP versions, round-trip fidelity metrics, or rephrasing-only baseline) that would separate representation benefits from incidental clarifications or fixes introduced by the meta-skill.
- [Abstract] Abstract (27-task evaluation): task definitions, baseline implementations, potential confounds (e.g., prompt length, tool availability), and the full experimental protocol are not described, preventing verification that the reported 0.11 reward / 14% pass-rate lift is attributable to AIP rather than other factors; this directly bears on the soundness of the central performance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the manuscript could more clearly isolate effects and provide experimental details. We respond to each major comment below and indicate the revisions planned.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that gains arise because the graph 'delivers vetted, runnable units rather than asking [the agent] to re-derive code, commands, and tool calls from natural language' is not isolated from compiler effects; the only reported comparison is prose vs. compiler-generated AIP, with no control (human-authored AIP versions, round-trip fidelity metrics, or rephrasing-only baseline) that would separate representation benefits from incidental clarifications or fixes introduced by the meta-skill.
Authors: We agree that the comparison is between original prose skills and their compiler-generated AIP versions, without controls such as human-authored AIP graphs, round-trip fidelity metrics, or rephrasing baselines. This leaves open the possibility that some gains arise from clarifications during compilation rather than the graph structure alone. The compiler is presented as an integral part of obtaining AIP from existing skills. In the revised manuscript we will add a dedicated limitations paragraph in the abstract and experiments section explicitly noting this and stating that the reported gains are for the compiled AIP representation. revision: partial
-
Referee: [Abstract] Abstract (27-task evaluation): task definitions, baseline implementations, potential confounds (e.g., prompt length, tool availability), and the full experimental protocol are not described, preventing verification that the reported 0.11 reward / 14% pass-rate lift is attributable to AIP rather than other factors; this directly bears on the soundness of the central performance claim.
Authors: Section 4 of the full manuscript describes the 27 SkillsBench tasks, the prose baselines, the AIP compilation procedure, the evaluation protocol with Claude Sonnet, and the Wilcoxon test. However, the abstract is highly condensed and does not enumerate these elements or discuss confounds such as prompt length. We will revise the manuscript to include a concise experimental summary paragraph (or expanded abstract text) that references the full protocol and adds a short confound analysis, thereby making the attribution more verifiable without altering the reported numbers. revision: yes
Circularity Check
No significant circularity; empirical evaluation on external benchmark
full rationale
The paper reports an empirical before/after comparison on the external SkillsBench benchmark (27 tasks, Wilcoxon p=0.011). The central claim is a measured performance lift after compilation to AIP graphs, not a mathematical derivation, fitted parameter renamed as prediction, or result forced by self-citation. No equations, self-definitional steps, or load-bearing citations to prior author work appear in the abstract or described claims. The evaluation is directly falsifiable against the benchmark and does not reduce to quantities internal to the AIP model itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Skills can be decomposed into discrete steps with explicit typed input/output connections without loss of procedural intent
invented entities (1)
-
AIP directed execution graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2025.Agent Skills Specification
Agent Skills. 2025.Agent Skills Specification. Agent Skills. https://agentskills.io/ specification
2025
-
[2]
Huan ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, Hongru Wang, Han Xiao, Yuhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Yixiong Fang, Qiwen Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenhailong Wang, Minda Hu, Huazheng Wang, Qingyun Wu, Heng Ji, and Mengdi Wang. 2025. A Survey...
Pith/arXiv arXiv 2025
-
[3]
2025.Equipping Agents for the Real World with Agent Skills
Anthropic. 2025.Equipping Agents for the Real World with Agent Skills. An- thropic. https://www.anthropic.com/engineering/equipping-agents-for-the- real-world-with-agent-skills Agent Skills open standard and reference SDK at https://agentskills.io
2025
-
[4]
Gal Bakal. 2026. Knowledge Activation: AI Skills as the Institutional Knowledge Primitive for Agentic Software Development. arXiv:2603.14805 [cs.SE] https: //arxiv.org/abs/2603.14805
Pith/arXiv arXiv 2026
-
[5]
2026.BenchFlow: Open-Source Benchmark Hub and Evaluation In- frastructure
BenchFlow. 2026.BenchFlow: Open-Source Benchmark Hub and Evaluation In- frastructure. BenchFlow. https://docs.benchflow.ai/introduction
2026
-
[6]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2023. Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numer- ical Reasoning Tasks. arXiv:2211.12588 [cs.CL] https://arxiv.org/abs/2211.12588
Pith/arXiv arXiv 2023
-
[7]
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. PAL: Program-aided Language Models. arXiv:2211.10435 [cs.CL] https://arxiv.org/abs/2211.10435
Pith/arXiv arXiv 2023
-
[8]
2025.Agent Development Kit (ADK)
Google. 2025.Agent Development Kit (ADK). Google. https://adk.dev/ Open- source framework with sequential, parallel, and loop workflow agents
2025
-
[9]
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. 2024. Large Language Models Cannot Self- Correct Reasoning Yet. arXiv:2310.01798 [cs.CL] https://arxiv.org/abs/2310.01798 ICLR 2024
Pith/arXiv arXiv 2024
-
[10]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770 [cs.CL] https://arxiv.org/abs/2310. 06770
Pith/arXiv arXiv 2024
-
[11]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav San- thanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2023. DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. arXiv:2310.03714 [cs.CL] https://arxiv.org/abs/2310.03714
Pith/arXiv arXiv 2023
-
[12]
2025.LangGraph
LangChain. 2025.LangGraph. LangChain, Inc. https://docs.langchain.com/ langgraph Orchestration framework modeling stateful agent workflows as directed graphs of nodes and edges
2025
-
[13]
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Binxu Li, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, X...
Pith/arXiv arXiv 2026
-
[14]
Qiliang Liang, Hansi Wang, Zhong Liang, and Yang Liu. 2026. From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills. arXiv:2604.24026 [cs.AI] https://arxiv.org/abs/2604.24026
Pith/arXiv arXiv 2026
-
[15]
Licorish, Ansh Bajpai, Chetan Arora, Fanyu Wang, and Kla Tan- tithamthavorn
Sherlock A. Licorish, Ansh Bajpai, Chetan Arora, Fanyu Wang, and Kla Tan- tithamthavorn. 2025. Comparing Human and LLM Generated Code: The Jury is Still Out! arXiv:2501.16857 [cs.SE] https://arxiv.org/abs/2501.16857
arXiv 2025
-
[16]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan AIP: A Graph Representation for Learning and Governing Agent Skills Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. 2025. AgentBench: Evalu...
Pith/arXiv arXiv 2025
-
[17]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schul- man, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Pe- ter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human...
Pith/arXiv arXiv 2022
-
[18]
Maxime Robeyns, Martin Szummer, and Laurence Aitchison. 2025. A Self- Improving Coding Agent. arXiv:2504.15228 [cs.AI] https://arxiv.org/abs/2504. 15228
arXiv 2025
-
[19]
2015.Graph Databases: New Oppor- tunities for Connected Data(2 ed.)
Ian Robinson, Jim Webber, and Emil Eifrem. 2015.Graph Databases: New Oppor- tunities for Connected Data(2 ed.). O’Reilly Media
2015
-
[20]
Sandeep Saini. 2026. Governing the Agentic Enterprise: A New Operat- ing Model for Autonomous AI at Scale.California Management Review (2026). https://cmr.berkeley.edu/2026/03/governing-the-agentic-enterprise-a- new-operating-model-for-autonomous-ai-at-scale/ Published online March 20, 2026
2026
-
[21]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv:2302.04761 [cs.CL] https://arxiv.org/abs/2302.04761
Pith/arXiv arXiv 2023
-
[22]
2024.Building Effective Agents
Erik Schluntz and Barry Zhang. 2024.Building Effective Agents. Anthropic. https://www.anthropic.com/engineering/building-effective-agents
2024
-
[23]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2024. Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I Learned to Start Worrying About Prompt Formatting. arXiv:2310.11324 [cs.CL] https://arxiv.org/abs/2310.11324 ICLR 2024
Pith/arXiv arXiv 2024
-
[24]
Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. 2024. A Long Way to Go: Investigating Length Correlations in RLHF. arXiv:2310.03716 [cs.CL] https://arxiv.org/abs/2310.03716 COLM 2024
arXiv 2024
-
[25]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto. 2018.Reinforcement Learning: An Intro- duction(2 ed.). MIT Press. http://incompleteideas.net/book/the-book-2nd.html
2018
-
[26]
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jar- rod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C.J. Carey, Ilhan Polat, Yu Feng, Eric W....
-
[27]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An Open-Ended Embodied Agent with Large Language Models. arXiv:2305.16291 [cs.AI] https://arxiv.org/ abs/2305.16291
Pith/arXiv arXiv 2023
-
[28]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. 2022. Chain- of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, Vol. 35. 24824– 24837. https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 9d5609613524ecf4f15af0f7b31a...
2022
-
[29]
Ruixuan Xiao, Wentao Ma, Ke Wang, Yuchuan Wu, Junbo Zhao, Haobo Wang, Fei Huang, and Yongbin Li. 2024. FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents. arXiv:2406.14884 [cs.CL] https://arxiv.org/abs/2406.14884
arXiv 2024
-
[30]
Renjun Xu and Yang Yan. 2026. Agent Skills for Large Language Models: Archi- tecture, Acquisition, Security, and the Path Forward. arXiv:2602.12430 [cs.AI] https://arxiv.org/abs/2602.12430
Pith/arXiv arXiv 2026
-
[31]
Wenda Xu, Guanglei Zhu, Xuandong Zhao, Liangming Pan, Lei Li, and William Yang Wang. 2024. Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement. arXiv:2402.11436 [cs.CL] https://arxiv.org/abs/2402.11436
arXiv 2024
-
[32]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL] https://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[33]
Yusen Zhang, Sarkar Snigdha Sarathi Das, and Rui Zhang. 2024. Verbosity ≠ Veracity: Demystify Verbosity Compensation Behavior of Large Language Models. arXiv:2411.07858 [cs.CL] https://arxiv.org/abs/2411.07858
arXiv 2024
-
[34]
Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, and Pulkit Agrawal. 2025. Self-Adapting Language Models. arXiv:2506.10943 [cs.LG] https://arxiv.org/abs/2506.10943 NeurIPS 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.